
 起点课堂会员权益
起点课堂会员权益除了烧钱,互联网留给大模型挥霍的“家底”不多了
互联网行业在经历了一段相对平静的时期后,大模型技术的出现似乎为行业注入了新的活力。然而,尽管大模型在应用层面逐渐渗透,其对互联网创新的推动作用和商业价值仍然存在争议。本文将探讨大模型技术在互联网领域的应用现状、面临的挑战以及未来的发展前景。

在新一轮互联网创新历程中,大模型有幸成了下一个赛点,这次不再像之前的元宇宙一样稍纵即逝,而是真的在逐渐往应用层面渗透。
《2024年中国移动互联网半年报告》发布,报告显示,2024年6月,AIGC类APP的月活跃用户规模达6170万,同比增长653%。从去年开始,大模型就再次掀起互联网混战,全球科技大厂生怕错过一次重要的时代转折,无论是做游戏的、电商的、还是社交玩家,都在倾尽全力跟进大模型时代。
有机构曾预测过,未来到2025年,全球 AI 市场规模将超过6万亿美元,2017年-2025年复合增长率达30%。
诚然,互联网世界已经安静了许多年,赖以大模型,总算又热闹了一回。淘宝、支付宝、抖音等国内流量规模前20的超级APP,基本都在发力内嵌式AI应用,智能助理、智能搜索、智能导购……各类新玩法层出不穷。
在全球互联网领域失去创新能力之后,大模型真的能给予互联网新的生命力吗?这个问题值得认真思考。
一、创新认知正在降级,产品研发故步自封
在大模型出现之前,互联网巨头为什么迟迟没有孵化出新的创新产品?
实际上,全球科技企业都在被这个问题残忍逼问。去年1月份,英国杂志《自然》刊登了一篇论文,文中基于4500万份手稿与390万项专利发现,全球范围内的颠覆性技术都在下降。
从企业角度来看,这些年来,互联网市场从未停止过研发进度,甚至还在不断加强。只不过,大厂的研发似乎都失去了意义,长远的投入与回收不成正比,严重消耗了资本的创新热情。
这不是空穴来风。根据上海证券交易所报告,仅在2021年,国内以寒武纪为代表的一众科创板块企业的投入研发成本就高达167亿,可惜,累计亏损远远超过了这个数。统计局数据显示,从2000年到2019年,企业的投入已经超出国内研发总投入的76%,年增速度达到10%。
即便是在这几年外部环境不利好的情况下,国内企业的研发增速依旧能保持在18%以上。但研发难以增收也是不争的事实,此前,百度的李彦宏公开表示,百度研发工程师超过万人,投入一度是收入的20%,但换来的实际业绩却不理想。
如此一来,巨头公司宁愿去投资现有项目,以腾讯为例,数据显示,腾讯目前总投资企业超过800家,其中有160家为估值超过10亿美金的独角兽企业。为此,外界甚至曾流传过一种说法,巨头的投资与干预使行业内部的创新力被压缩了。
除此之外,研发换不来可观的回收,也让大厂不再一味盲目开发新产品。
这些年,小程序成品的涌现频率要高出独立APP许多,此前,阿里、腾讯、字节、百度、快手、美团、京东……陆续开发小程序,而独立APP为了节约试错成本大面积关停。统计显示,腾讯曾一年关掉了40多个项目,字节也下架了派对岛,截止目前为止,仅互联网大厂这几年关停的独立产品就高达70多款。
而这背后与整个互联网行业的盈利状态息息相关,工信部数据显示,今年第一季度,我国规模以上互联网企业营业成本同比增长5.1%,实现利润总额278.9亿元,但同比下降15.3%,利润总额增速由正转负。
大模型的出现,算是一缕照进互联网世界的曙光,苦于固步自封的大厂们一涌而上,从研发方向也能看出,大模型的确激发了巨头们的研发信心。然而,大模型所带来的创新能维持多久?
有一点需要注意,时至今日,创新疲软的互联网领域很难再出现一个现象级产品,或者领头式技术。毕竟走过微信、抖音年代,任何一点风吹草动都能引发行业内卷,正如当下,自研芯片、大数据、云计算、人工智能等技术成了所有巨头,乃至科技创业的重头戏。
同质化的戏码,从未在互联网界消失,当AI玩法在任何一个APP上都能见到,这样的创新也就不再是“创新”。
另外,虽然大模型热多少激起了一些水花,但互联网巨头曾经最担心的研发与营收不成正比的问题更为严重了。全球科技发力AI,所造就的资本支出也就越来越多。这段时间,海外巨头的财报把大模型烧钱的本质展现得淋漓尽致。
有机构分析,到了2025年和2026年,大模型训练成本会接近50-100亿美元,其中,Meta、谷歌、微软可能计划将大模型研发成本提高到500亿美元。
种种迹象显示,互联网或许从未停止创新,只是对于创新的认知下降了。
二、大模型应用的威力,并没预想中的强
不同于过去的几次革新,这一次互联网集体向用户提供的大模型应用,面世没多久就遇到了一些麻烦:用户需要大模型的几率大吗?就目前一系列数据来看,答案或许是比预期的要悲观一些。
红杉资本数据显示,即便是全球大模型的头部ChatGPT,其首月用户留存率也只有56%,有大约一半的用户用不到一个月就将其“搁置”了。同样的,《2024年中国移动互联网半年报告》也显示,国内AIGC用户不稳定,AIGC行业人均使用时长同比下滑了23.5%。
说到底,人工智能渗入现实生活还只是资本的“幻想”。
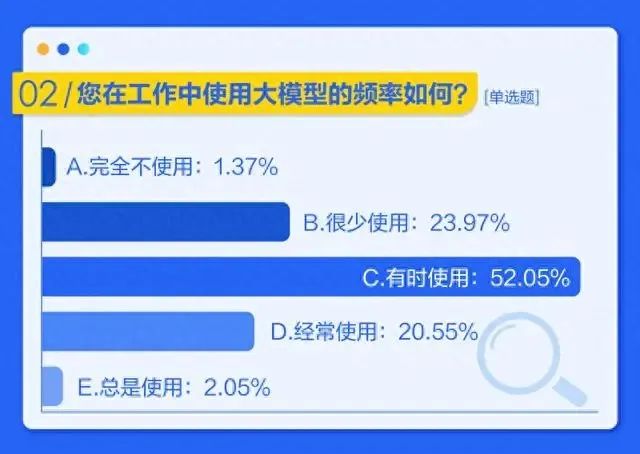
从用户层面来看,几乎所有主流APP上的AIGC应用的用户留存率低于传统应用,参与度也较低。7月份,贝壳财经发布了一项调查,52.05%的受访者在工作中有时使用大模型,23.97%很少使用,经常使用的受访者占20.55%,总是使用的人仅占2.05%。
从企业层面来看,华为有一组预测数据,到2026年,人工智能对企业的渗透率也只能达到20%。
为什么会出现这种情况?技术、成本、实用性、安全性其实都是原因。
以AI落地应用最广泛的文娱行业为例,前段时间,成龙新片《传说》上映,在该片上映之前,AI技术一直是影片宣传的最大噱头。据悉,博纳影业在电影里用AI还原了27岁的成龙,但买账的观众却寥寥无几。
数据显示,当前《传说》豆瓣评分5.4分,上映十几天也只有7000多万的票房。
在另外一大应用领域“广告界”的使用口碑也褒贬不一。艾瑞咨询显示,已有约半数广告主企业在线上营销活动中应用AIGC技术,其中超9成用于内容及创意场景,当前大部分互联网在自身产品里引入大模型,也是为了拉动每况愈下的广告收入。
然而,AIGC短板也开始浮出水面:例如生产素材过于公式化、AI效果令用户审美疲劳、以及众所周知的AI抄袭问题……之前,“我用 AI 五分钟生成一个广告 ,却花了五个小时去 AI 味”的文章在社交平台上产生热议。
如果大模型无法像社交通讯、短视频娱乐那样,在用户的网络生活中产生刚需效应,那大模型之于互联网进程,也就没太大的推进作用。当前,互联网领域最大的重心就是要提升AI落地的应用效率。
而资本也意识到了这一点,投资流向正从研发赛道流向应用赛道。海通国际研报称,2024年有望成为国产大模型全面商业落地的元年。
数据显示,在今年近120起全球大模型投资事件里,大模型应用企业占69%,占比超过一半,而AI Infra、通用大模型分别只占16%、11%,大模型数据服务甚至只剩下了3%。细看大模型应用领域,AI医疗健康、视觉/视频生成领域、办公助手和编程助手获得融资的企业最为密集,分别占比为15%、15%、13%、11%。
总而言之,资本正在现实世界中加速普及大模型,技术和业务需求如何匹配是大模型企业迫在眉睫的问题。也只有这样,互联网才有被“拯救”的可能,反之,失去创新力的互联网还要继续迷茫。
三、互联网留给大模型吃老本的“家底”不多了
有一个问题需要注意,互联网走到大模型阶段,大多数的玩法还与从前一样,要么持续打价格战,要么回身吃本身的流量“老本”。
从本质上讲,大模型的落地与古早互联网时期“圈地跑马”没什么区别。
今年5月份,国内一众大模型玩家开始官宣降价,阿里的通义千问主力大模型Qwen-Long的API价格直降97%后,文心大模型两大主力模型ERNIE Speed和ERNIE Lite全面免费,随后,科大讯飞也宣布,讯飞星火API能力免费开放。
而字节跳动这边,豆包从发布到冲上第一只用了30天的时间,据悉,豆包之所以能短时间内成为大模型“顶流”,不仅因为月活7.94亿人的抖音为其助力,新一轮的烧钱金额也达到了1.24亿元。
遥想当年,国内互联网大厂最屡试不爽的招数就是砸钱。时至今日,“圈地”的打法还适用吗?
首先,大模型在当前只能砸钱换流量的关键在于技术趋同,最终影响用户留存的也会是回归于技术,单纯降低应用成本从短期角度来看的确能增加曝光、争抢用户,但长久来看,AI技术服务不是外卖、更不是短视频,依靠烧钱无法带来良好的使用体验。
其次,大模型发展本身就是个成本巨大的资金型工程,或许对于现金流富裕的大厂而言,价格战打得起,但当前大模型盈利遥遥无期,小型企业入局的风险不可小觑,这必然会进一步降低整个行业的创新力和创造力。
事实上,大模型价格战是从海外先开始的,彼时,OpenAI和谷歌最先宣布降价。但在海外,云厂商正在脱离传统服务模式,转用其他方式来填空这一成本,以英伟达为例,5月份,英伟达公布了2025财年的第一季度数据。
英伟达方面表示,在英伟达CUDA上训练和推理AI可以推动云租赁收入的增长,每1美元的英伟达AI基础设施支出让云服务提供商有机会在四年里获得5美元的GPU即时托管收入。国内能否快速跟进这一步计划,其实还有待商榷。
当然,除了能够继续“传承”的打法,互联网这些年给大模型留下的“家底”也不多了,即便是从全球范围内来看,资金之外,大模型最需要的信息数据已出现短缺。
Similarweb的数据显示,自2023年5月ChatGPT全球访问量达到18亿次的巅峰后,其流量增长开始逐渐放缓。对此,OpenAI决定放宽对ChatGPT的限制,用户一度无需注册就能使用。
没办法,这也是当前大模型发展的困境之一:现有的互联网信息量难以支撑如此之多大模型训练。
这段时间,字节跟一众在线办公企业“喂养”大模型的事引发不少用户不满。公开资料显示,GPT-4训练涉及的数据量高达12万亿tokens,未来像GPT-5,可能需要60万亿到100万亿tokens。
根据Epoch研究所预测,到2024年年中,大模型对高质量数据的需求超过供给的可能性为50%,到2026年发生这种情况的可能性为90%,而这种数据短缺风险将延迟至2028年。
至于如何弥补这一巨大的数据缺口,渗透率逐渐触到天花板的互联网,一时间也找不到更好的办法。
本文由人人都是产品经理作者【道总有理】,微信公众号:【道总有理】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Pixabay,基于 CC0 协议。








说得好有道理!如果大模型无法像社交通讯、短视频娱乐那样,在用户的网络生活中产生刚需效应,那大模型之于互联网进程,也就真的没太大的推进作用了。
互联网走到大模型阶段,大多数玩法仍与从前一样,依靠价格战和流量优势。然而,这种策略在大模型时代是否仍然有效,值得好好思考一番。