
 起点课堂会员权益
起点课堂会员权益AI大模型实战篇:AI Agent设计模式 – LLM Compiler
通过构建有向无环图DAG来表示任务之间的依赖关系,LLM Compiler能够实现任务的并行执行,从而大幅降低总执行时间。本文将详细介绍LLM Compiler的原理、实现过程以及其在实际应用中的优势。

在上篇文章《AI大模型实战篇:AI Agent设计模式 – Plan & Execute》中,风叔结合原理和具体源代码,详细介绍了AI Agent设计模式中的Plan-and-Execute。但是Plan-and-execute的局限性在于,每个任务是按顺序执行的,这可能会导致总执行时间的增加。
一种有效改进的办法是将每个任务表示为有向无环图DAG,这样可以让多个任务并行执行,大幅降低执行总时间。
这就是本篇文章风叔将为大家介绍的AI Agent设计模式,LLM Compiler。
01 LLM Compiler的概念
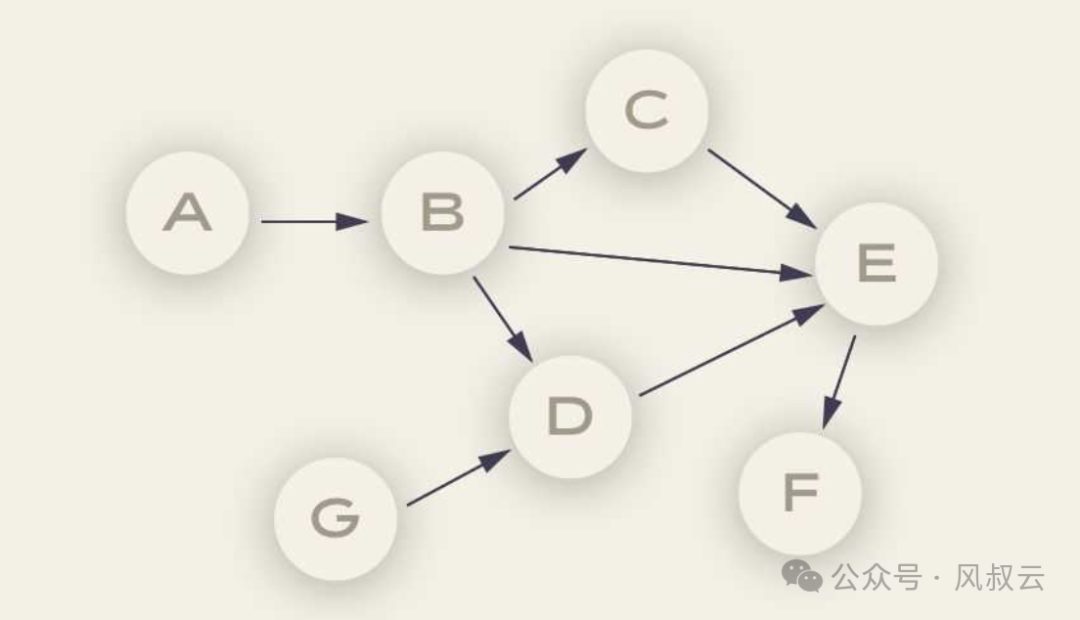
LLM Compiler是伯克利大学的SqueezeAILab于2023年12月提出的新项目。这个项目在ReWOO引入的变量分配的基础上,进一步训练大语言模型生成一个有向无环图(Directed Acyclic Graph,DAG,如下图所示)类的规划。DAG可以明确各步骤任务之间的依赖关系,从而并行执行任务,实现类似处理器“乱序执行”的效果,可以大幅加速AI Agent完成任务的速度。
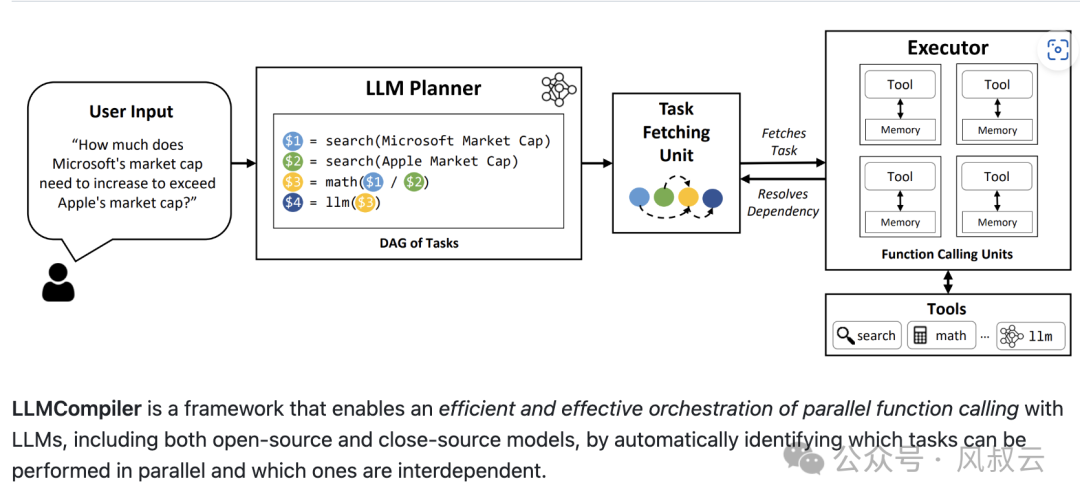
比如下图的例子,向Agent提问“微软的市值需要增加多少才能超过苹果的市值?”,Planner并行搜索微软的市值和苹果的市值,然后进行合并计算。
1. LLM Compiler设计模式主要有以下组件:
- Planner:输出流式传输任务的DAG,每个任务都包含一个工具、参数和依赖项列表。相比ReWOO的Planner,依赖项列表是最大的不同。
- Task Fetching Unit:调度并执行任务,一旦满足任务的依赖性,该单元就会安排任务。由于许多工具涉及对搜索引擎或LLM的其他调用,因此额外的并行性可以显著提高速度。
- Joiner:由LLM根据整个历史记录(包括任务执行结果),决定是否响应最终答案或是否将进度重新传递回Planner。
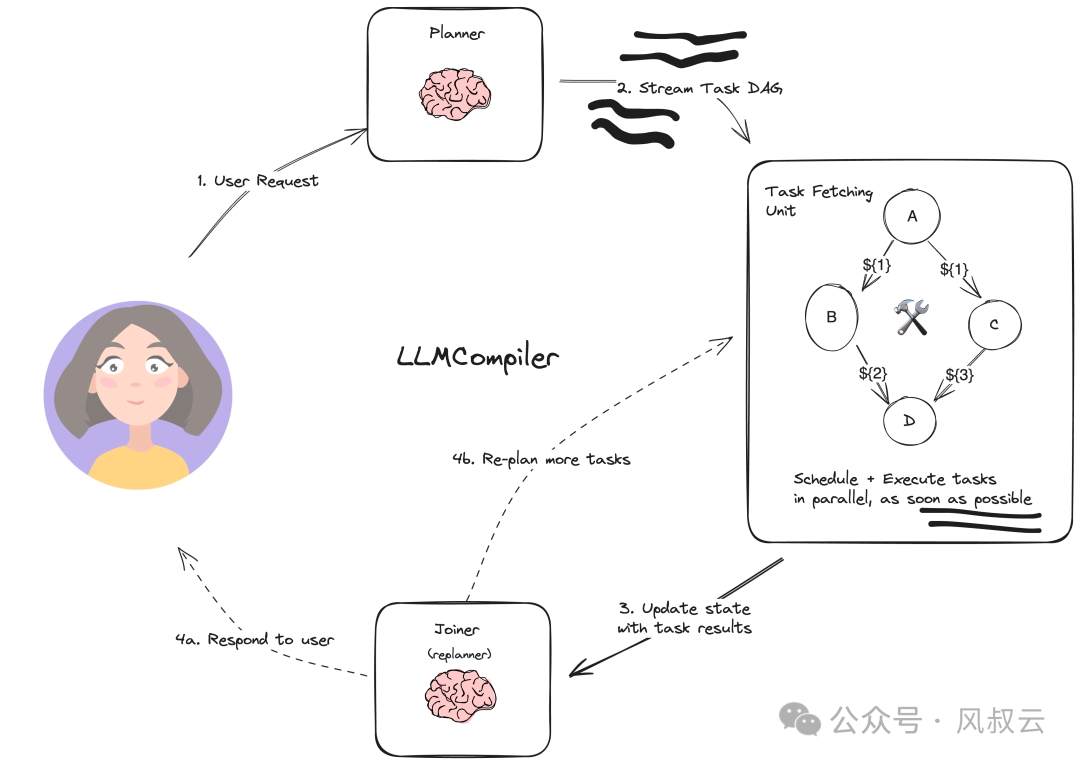
2. 下图是LLM Compiler的原理:
- Planner接收来自用户的输入,输出流式传输任务的DAG
- Task Fetching Unit从式传输任务DAG中读取任务,通过处理工具并行执行
- Task Fetching Unit将状态和结果传递给Joiner(或Replanner),Joiner来决定是将结果输出给用户,还是增加更多任务交由Task Fetching Unit处理
02 LLM Compiler的实现过程
下面,风叔通过实际的源码,详细介绍LLM Compiler模式的实现方法。大家可以关注风叔,回复关键词【LLMC源码】,获取LLM Compiler设计模式的完整源代码。
第一步 构建工具Tools
首先,我们要定义Agent需要使用的工具。在这个例子中,我们将使用搜索引擎 + 计算器这两个工具。
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain_openai import ChatOpenAI
from math_tools import get_math_tool_get_pass(“TAVILY_API_KEY”)
calculate = get_math_tool(ChatOpenAI(model=”gpt-4-turbo-preview”))
search = TavilySearchResults(
max_results=1,
description=’tavily_search_results_json(query=”the search query”) – a search engine.’,
)tools = [search, calculate]
第二步 构建Planner
Planner接收用户输入,并生成一个待执行的任务清单的DAG。
以下代码构建了Planner的提示模板,并将其与 LLM 和输出解析器组合在一起,输出解析器处理以下形式的任务列表。在Planner中,我们同时定义了replanner的Prompt,这个prompt提出了三项核心的约束
- 启动当前计划时,应该从概述下一个计划策略的“Thought”开始
- 在当前计划中,绝不应该重复上一个计划中已经执行的操作
- 必须从上一个任务索引的末尾继续任务索引,不要重复任务索引
def create_planner(
llm: BaseChatModel, tools: Sequence[BaseTool], base_prompt: ChatPromptTemplate
):
tool_descriptions = “n”.join(
f”{i+1}. {tool.description}n”
for i, tool in enumerate(
tools
) # +1 to offset the 0 starting index, we want it count normally from 1.
)
planner_prompt = base_prompt.partial(
replan=””,
num_tools=len(tools)
+ 1, # Add one because we’re adding the join() tool at the end.
tool_descriptions=tool_descriptions,
)
replanner_prompt = base_prompt.partial(
replan=’ – You are given “Previous Plan” which is the plan that the previous agent created along with the execution results ‘
“(given as Observation) of each plan and a general thought (given as Thought) about the executed results.”
‘You MUST use these information to create the next plan under “Current Plan”.n’
‘ – When starting the Current Plan, you should start with “Thought” that outlines the strategy for the next plan.n’
” – In the Current Plan, you should NEVER repeat the actions that are already executed in the Previous Plan.n”
” – You must continue the task index from the end of the previous one. Do not repeat task indices.”,
num_tools=len(tools) + 1,
tool_descriptions=tool_descriptions,
)def should_replan(state: list):
# Context is passed as a system message
return isinstance(state[-1], SystemMessage)def wrap_messages(state: list):
return {“messages”: state}def wrap_and_get_last_index(state: list):
next_task = 0
for message in state[::-1]:
if isinstance(message, FunctionMessage):
next_task = message.additional_kwargs[“idx”] + 1
break
state[-1].content = state[-1].content + f” – Begin counting at : {next_task}”
return {“messages”: state}return (
RunnableBranch(
(should_replan, wrap_and_get_last_index | replanner_prompt),
wrap_messages | planner_prompt,
)
| llm
| LLMCompilerPlanParser(tools=tools)
)
llm = ChatOpenAI(model=”gpt-4-turbo-preview”)
planner = create_planner(llm, tools, prompt)
第三步 构建Task Fetching Unit
这个部分负责安排任务,它接收以下格式的数据流。
tool:BaseTool,
dependencies:number[]
其核心思想是,一旦满足依赖关系,就开始执行工具,可以通过多线程实现。下面这段代码的关键就在于schedule_tasks,会将所有任务处理成有向无环图。在当前任务存在尚未完成的依赖关系时,放入pending task;在当前任务所有依赖关系都已完成时,执行任务。
@as_runnable
def schedule_task(task_inputs, config):
task: Task = task_inputs[“task”]
observations: Dict[int, Any] = task_inputs[“observations”]
try:
observation = _execute_task(task, observations, config)
except Exception:
import tracebackobservation = traceback.format_exception() # repr(e) +
observations[task[“idx”]] = observation
def schedule_pending_task(task: Task, observations: Dict[int, Any], retry_after: float = 0.2):
while True:
deps = task[“dependencies”]
if deps and (any([dep not in observations for dep in deps])):
# Dependencies not yet satisfied
time.sleep(retry_after)
continue
schedule_task.invoke({“task”: task, “observations”: observations})
break@as_runnable
def schedule_tasks(scheduler_input: SchedulerInput) -> List[FunctionMessage]:
“””Group the tasks into a DAG schedule.”””
tasks = scheduler_input[“tasks”]
args_for_tasks = {}
messages = scheduler_input[“messages”]observations = _get_observations(messages)
task_names = {}
originals = set(observations)futures = []
retry_after = 0.25 # Retry every quarter second
with ThreadPoolExecutor() as executor:
for task in tasks:
deps = task[“dependencies”]
task_names[task[“idx”]] = (
task[“tool”] if isinstance(task[“tool”], str) else task[“tool”].name
)
args_for_tasks[task[“idx”]] = task[“args”]
if (
# Depends on other tasks
deps
and (any([dep not in observations for dep in deps]))
):
futures.append(
executor.submit(
schedule_pending_task, task, observations, retry_after
)
)
else:
# No deps or all deps satisfied,can schedule now
schedule_task.invoke(dict(task=task, observations=observations))
# futures.append(executor.submit(schedule_task.invoke dict(task=task, observations=observations)))# All tasks have been submitted or enqueued
# Wait for them to complete
wait(futures)
# Convert observations to new tool messages to add to the state
new_observations = {
k: (task_names[k], args_for_tasks[k], observations[k])
for k in sorted(observations.keys() – originals)
}tool_messages = [
FunctionMessage(
name=name, content=str(obs), additional_kwargs={“idx”: k, “args”: task_args}
)
for k, (name, task_args, obs) in new_observations.items()
]return tool_messages
import itertools
@as_runnable
def plan_and_schedule(state):
messages = state[“messages”]
tasks = planner.stream(messages)
# Begin executing the planner immediately
try:
tasks = itertools.chain([next(tasks)], tasks)
except StopIteration:
# Handle the case where tasks is empty.
tasks = iter([])
scheduled_tasks = schedule_tasks.invoke(
{
“messages”: messages,
“tasks”: tasks,
}
)
return {“messages”: [scheduled_tasks]}
第四步 构建Joiner
前面我们构建了Planner和Task Fetching Unit,下一步我们需要构建Joiner来处理工具的输出,以及决定是否需要使用新的计划并开启新的循环。
class FinalResponse(BaseModel):
“””The final response/answer.”””
response: strclass Replan(BaseModel):
feedback: str = Field(
description=”Analysis of the previous attempts and recommendations on what needs to be fixed.”
)class JoinOutputs(BaseModel):
“””Decide whether to replan or whether you can return the final response.”””
thought: str = Field(
description=”The chain of thought reasoning for the selected action”
)
action: Union[FinalResponse, Replan]joiner_prompt = hub.pull(“wfh/llm-compiler-joiner”).partial(
examples=””
) # You can optionally add examplesllm = ChatOpenAI(model=”gpt-4-turbo-preview”)
runnable = create_structured_output_runnable(JoinOutputs, llm, joiner_prompt)
如果Agent需要继续循环,我们需要选择状态机内的最新消息,并按照Planner的要求输出相应的格式。
def _parse_joiner_output(decision: JoinOutputs) -> List[BaseMessage]:
response = [AIMessage(content=f”Thought: {decision.thought}”)]
if isinstance(decision.action, Replan):
return response + [
SystemMessage(
content=f”Context from last attempt: {decision.action.feedback}”
)
]
else:return {“messages”: response + [AIMessage(content=decision.action.response)]}
def select_recent_messages(state) -> dict:
messages = state[“messages”]
selected = []
for msg in messages[::-1]:
selected.append(msg)
if isinstance(msg, HumanMessage):
breakreturn {“messages”: selected[::-1]}
joiner = select_recent_messages | runnable | _parse_joiner_output
input_messages = [HumanMessage(content=example_question)] + tool_messages
joiner.invoke(input_messages)
第五步 构建流程图
下面,我们构建流程图,将Planner、Task Fetching Unit、Joiner等节点添加进来,循环执行并输出结果。
from langgraph.graph import END, StateGraph, START
from langgraph.graph.message import add_messages
from typing import Annotatedclass State(TypedDict):
messages: Annotated[list, add_messages]graph_builder = StateGraph(State)
graph_builder.add_node(“plan_and_schedule”, plan_and_schedule)
graph_builder.add_node(“join”, joiner)
graph_builder.add_edge(“plan_and_schedule”, “join”)def should_continue(state):
messages = state[“messages”]
if isinstance(messages[-1], AIMessage):
return END
return “plan_and_schedule”graph_builder.add_conditional_edges(
start_key=”join”,
# Next, we pass in the function that will determine which node is called next.
condition=should_continue,
)graph_builder.add_edge(START, “plan_and_schedule”)
chain = graph_builder.compile()
总结
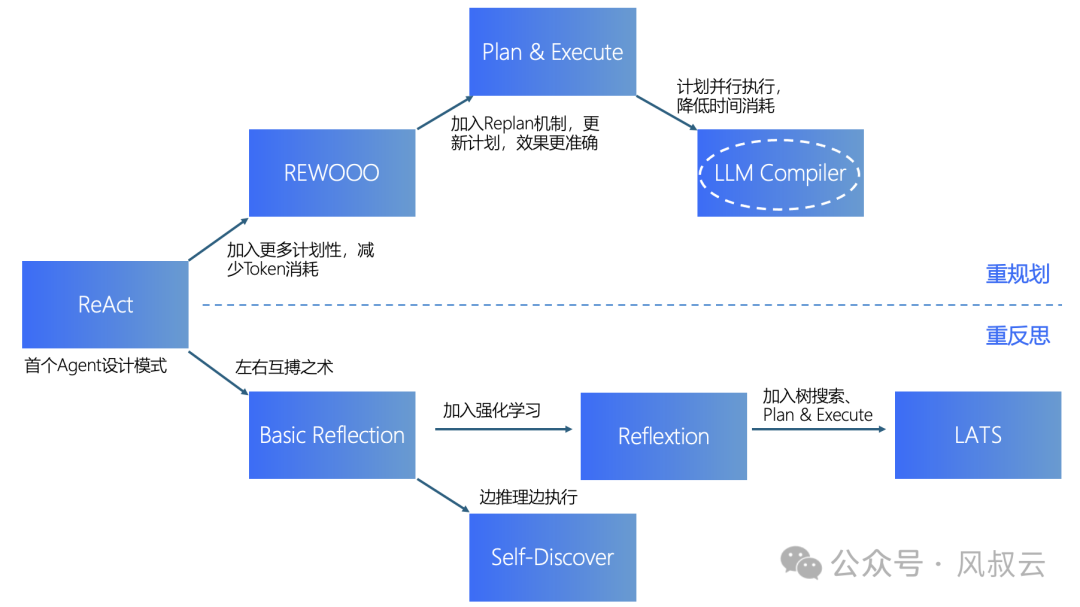
通过前面三篇文章,按照递进关系,风叔依次介绍了REWOO、Plan-and-Execute和LLM Compiler三种更侧重规划能力的AI Agent设计模式。从最初的ReAct模式出发,加入规划能力即演变成REWOO;再加上Replan能力即演变成Plan-and-Execute;最后再加上DAG和并行处理能力,即演变成LLM Compiler。
在后续的文章中,风叔将转向另外几种侧重反思的AI Agent模式。下一篇文章,风叔将介绍Agent左右互搏之术,Basic Reflection。
本文由人人都是产品经理作者【风叔】,微信公众号:【风叔云】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。






- 目前还没评论,等你发挥!


