
 起点课堂会员权益
起点课堂会员权益当做应用成为共识,大模型公司拿出了更多弹药
“大模型应用时代,新品竞争开启。” 在人工智能发展的浪潮中,大模型公司纷纷推出新成果。这些新品将如何改变 AI 应用的格局?又会给我们的生活和工作带来哪些影响?

过去的一周,就像是对明年AI应用领域的激烈竞争进行了一波预演。
OpenAI连续12个工作日的直播继续进行,完全版的o1,跳票很久的Sora和GPT-4o的高级语音模式,最新的ChatGPT Projects功能纷纷上线,其中还夹杂着一些关于AGI的符号性植入,仿佛在暗示这场马拉松式新品发布的压轴大戏会与AGI密切相关。
Google也选择在这周发布了自己的最新大模型Gemini 2.0,不但可以进行多模态的内容输入和输出,还支持对Google搜索、代码执行等工具的使用。同时发布的智能体Project Mariner,实现了此前Google尝试研发的代替用户在浏览器内执行任务的功能。
此外,阶跃星辰发布了Step-1o 千亿参数端到端语音大模型,支持语音、文本等混合形式的输入和输出,可以实现语音理解和生成的一体化。Midjourney推出了Patchwork,帮助用户构建更加清晰的故事,并支持与他人进行协作。人们也可以每月支付500美元,雇佣Devin完成从网站到应用程序的构建与部署。
与去年这时候各家大模型厂商重点比拼参数和基础性能相比,今年的厂商们迫切地想要让用户把大模型用起来。
iPhone上的ChatGPT
多模态能力、操作界面和代理执行是这一轮发布的三个重点方向。OpenAI和Google都在这三个方向上推销着自己的技术能力,同时,国内的豆包、智谱、Kimi、通义等大模型也在朝着这些方向努力。
大模型转向应用背后,技术路线也在发生调整。前OpenAI联合创始人Ilya Sutskever本周在神经信息处理系统会议(NeurIPS)上发言指出,尽管存量数据仍能进一步推动人工智能的发展,但互联网上的数据和石油一样是有限的,行业正在放弃使用新数据进行大模型的预训练,这将迫使人们改变今天训练大模型的方式。
Google在Gemini 2.0发布会上透露的信息显示,其在大模型技术发展上正在尝试两条腿走路:一方面,继续扩大模型规模,提升基础性能;另一方面,加强后期训练优化和推理技术的改进,尤其关注多模态能力的提升,希望让AI能更好地理解和处理各类信息。
当知识性或事实性数据一时间难以大规模产生,实现「推理—应用」的闭环,能为大模型的能力进化提供一个基于应用数据的稳定训练环境,继续能力提升的尝试。当然,这需要大模型的能力渗透进更多应用场景中,被更大规模的用户更频繁地使用。
OpenAI们正在为AI应用的普及提供更多弹药。
一、多模态带来更拟人的硬件
OpenAI和Google的发布内容中,多模态都是一个重要的组成部分。即便不从AGI的角度去理解,一个具备看、听、说等多种感知能力的大模型,也能被看作具备了更接近人的自然交互习惯的能力,就像人形机器人被认为是能够最大程度适应人类社会的工作环境一样。
O1大模型引入多模态处理能力的同时,OpenAI终于发布了GPT-4o的高级语音模式。在这个模式下,一场更顺畅自然的人机互动成为了现实。在高级语音模式下,四位OpenAI的工作人员流畅地与AI交谈,AI能够通过摄像头分辨出他们中谁戴着圣诞帽,并一边「看」,一边指导其中一位员工做手冲咖啡。
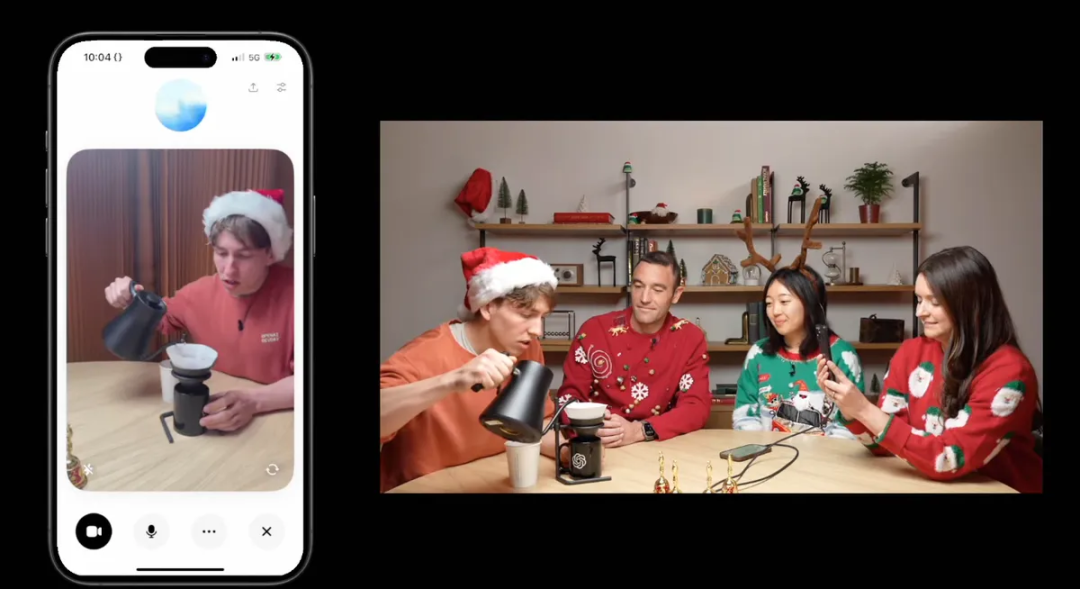
ChatGPT指导制作手冲咖啡
Google发布的Gemini 2.0也增强了其智能体Project Astra的多模态交互能力。Google在今年5月举办的I/O大会上推出了Project Astra,能够借助手机摄像头观察理解现实环境,解答用户的相关问题。这次升级之后,Project Astra可以在多种语言之间进行自然对话,并拥有图形记忆能力和对话记忆能力。
其中,图形记忆能力可以让其记住最近10分钟内看到的图像,对话记忆能力则可以储存和调用60段历史对话。在一个演示中,一名Google员工让Project Astra看到一辆驶过的公交车,并向它询问这辆公交车能否带自己去往唐人街附近。当然也有展示Project Astra对不同口音和生僻词汇的理解能力。
当我们看到这些能力演示的时候,一定能够想到如果智能眼镜上有了这种能力,是否会带来更棒的使用体验?
如果说多模态大模型最终指向的是一个类人的、无处不在的精明助理,那AI硬件一定会是它的核心载体。大模型多模态能力的提升,有可能会让拥有看、听、说能力的智能眼镜站上更大的风口。
作为AI硬件的主要品类,我们在国内已经看到了众多智能眼镜产品的诞生,包括百度推出了小度AI眼镜,Rokid与BOLON推出了Rokid glasses,李未可的Meta Lens Chat,蜂巢科技的界环AI音频眼镜,以及被认为会做智能眼镜的字节、小米、华为等大厂。
虽然不清楚OpenAI的想法,但从Ray-Ban Meta已经搭载AI能力,和Google的一些表态上,可以看到大模型与AI硬件更深度融合的时间点正在到来。Google的工作人员表示,「一小部分人将通过原型眼镜测试 Project Astra,我们认为这是体验此类 AI 最强大、最直观的方式之一。」
在国内,大模型与硬件的结合也已经成为一门显学。致力于端侧AI发展的面壁智能在上周完成了新一轮数亿元融资,其CEO李大海在内部信中表示:「因为端侧智能发展的深刻影响,主流消费电子和新兴硬件正演变成一个个在不同场景、执行特定任务的超级智能体,成为新一轮科技创业大风口。」
二、执行能力提升催化智能体
执行能力的提升则是这一波大模型产品能力提升的另一个方向。大模型向应用方向进行拓展,必然需要具备打通不同场景、终端和应用的执行能力。而智能体则是目前公认的能够实现这种打通的理想载体。
在这周的大模型产品发布中,我们明显能够感觉到,OpenAI和Google正在给智能体生态打造更多建设工具。
OpenAI在GPT-4o的高级语音模式中展示了一项屏幕共享能力。在开启屏幕共享之后,ChatGPT能够浏览用户的短信,并给出回复建议。这很难不让人联想到智谱和Anthropic推出的AutoGLM和computer use能力。观看和理解屏幕上显示的内容,是让大模型学会操作App的基础。
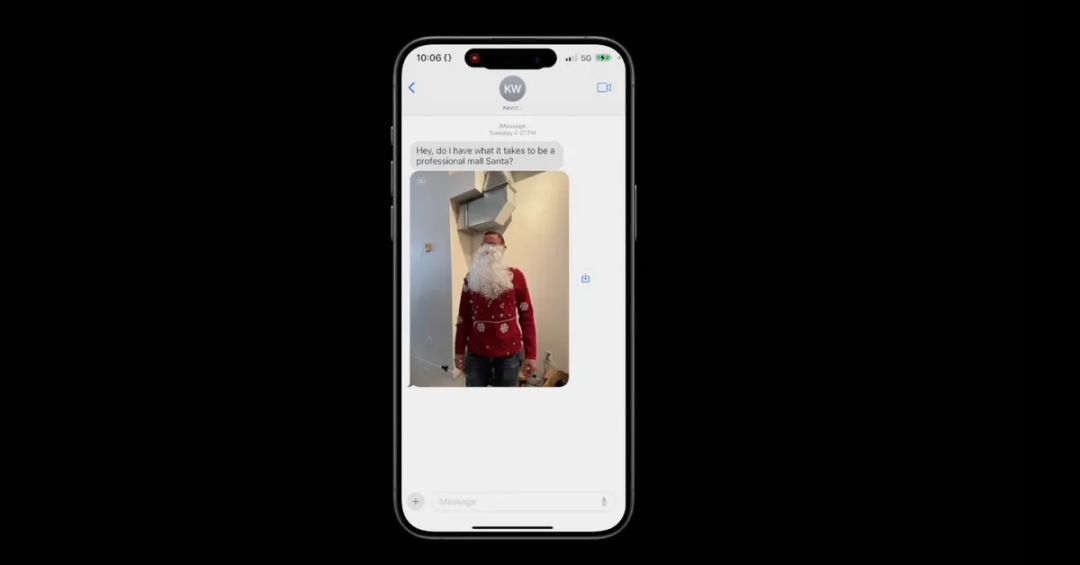
ChatGPT浏览短信
也是在上周,ChatGPT正式接入到苹果的系统中。特定英语地区的苹果用户已经可以在iPhone、iPad和MAC上直接体验ChatGPT的功能。这是一种混合方案,当Siri觉得用户提出的问题更适合让ChatGPT来回答时,系统会请求用户同意访问OpenAI服务。未来,OpenAI未尝不会与Apple Intelligence做更深度的融合。
Google则直接将Gemini 2.0定义成一个面向智能体时代的AI模型,其多模态能力和调用工具的能力都能够支撑构建AI智能体。在Google展示的一些智能体中,有的可以根据屏幕上的画面,实时分析游戏情况,并向用户提出操作建议,还有的能进行深度研究和论文撰写。
Project Mariner也是基于Gemini 2.0的能力实现的。这也是之前大家所传的与AutoGLM和computer use类似的产品。在Google的介绍中,这个产品能理解网页上的复杂信息,并调用Chrome浏览器的扩展程序,帮助用户完成复杂任务。与AutoGLM和computer use一样,该产品也能帮助用户执行键入、单击等动作。
OpenAI与Google之外,亚马逊也在这周宣布建立了自己的Amazon AGI SF Lab。据介绍,这个实验室由AI初创公司Adept联合创始人David Luan领导,其核心目标直指打造能在数字和物理世界中「采取行动」的AI智能体,并能处理跨越计算机、网络浏览器和代码解释器的复杂工作流程。
很明显,对于大模型厂商来说,明年的大模型产品一定会在标配多模态能力的基础上,让自己拥有更多可影响物理世界的执行能力。而这些执行能力的推出,一方面会继续带动手机、PC、汽车等传统硬件领域的AI化探索,另一方面,也有可能让更多大厂和开发者找到新的思路,对原有产品的体验进行自动化的局部改造和升级探索。
三、AI原生的操作界面正在诞生
本周大模型产品发布的第三个变化是AI原生的操作界面正在初露端倪。特别是在OpenAI已经进行的发布中,Sora和Canvas两天的发布给人印象最深刻的都是对AI原生操作界面的探索。一定会有人从中得到启发,去思考应该用一种什么样的操作界面,来实现原有体验的AI化。
这会是未来一段时间内的探索方向。就像智能手机出现之后,游戏厂商如何去探索一个更适合触摸屏交互的操作界面一样,在大模型越来越深度地介入应用场景之后,需要有一个围绕自然语言搭建的操作界面。我们目前看到的在生成视频时进行的参数选择,并不是面向未来的操作界面。
对话窗口可能是一种形态,但不足以支撑多元的信息形态。这也是为什么,OpenAI会推出Canvas作为对话窗口的补充。Canvas事实上提供了一个人与AI交流的「桌面」,大家在聊天的同时,可以把自己手头的文字、视频、数据放在桌面上,一同观看和处理。

Canvas界面
OpenAI在11月推出的ChatGPT桌面应用能够在MAC上实现与第三方应用的协作,将第三方应用中的内容引入到用户与ChatGPT的对话中。有科技博主利用这个功能,让ChatGPT「看」到了Terminal中打开的字幕文件,并生成了能够将其转换为纯文本文件的命令。
这种协作,形象点说,就是在将Terminal等软件中的数据、信息摆放到桌面上,让AI也能看到。然后AI能够根据自己看到的200行信息,更精准地理解用户在对话中表述的意图。当然,Canvas的预览功能,也是对这种桌面能力的补充,相当于把一个木制的桌面,变成了一个智能的显示屏。
OpenAI在第七天发布的Projects功能,则是为桌面打造的文件柜,可以将同一个项目的聊天记录、文件和自定义指令集中在一起,实现更精细化的资料管理。Projects让用户能够更轻松在ChatGPT上打造自己的工作台。甚至,这个Projects未来可能会集成更多人和智能体,成为一个协作空间。
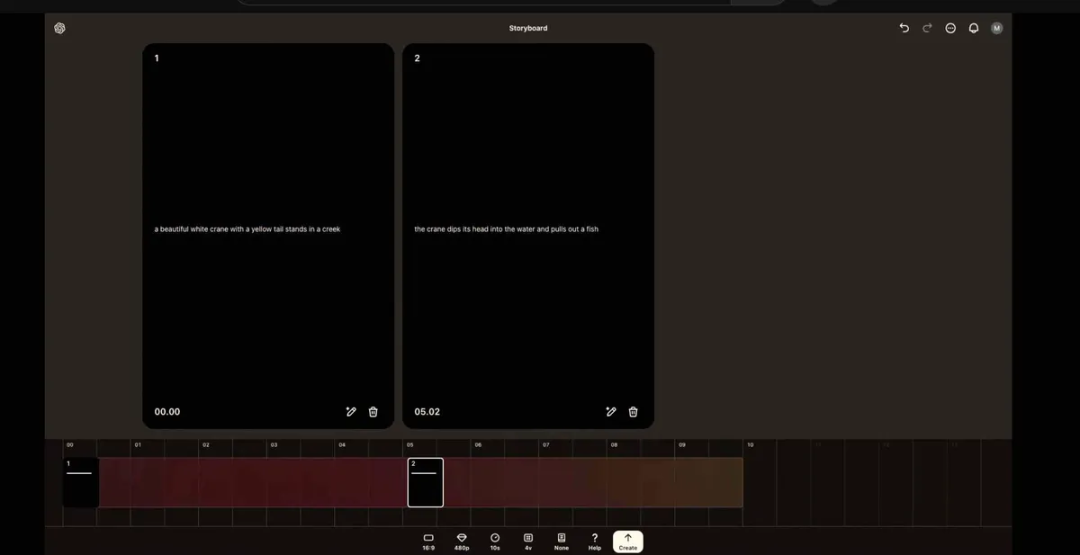
Storyboard
同理,尽管大家对Sora的视频生成能力褒贬不一,但对Sora展示出的AI视频操作界面都给出了比较高的评价。Sora既提供了一些模版化的工具插件,比如可以替换视频元素的Remix工具,可以拓展最佳帧的Re-cut工具,可以生成重复视频的Loop工具;又推出了Storyboard,一个拥有时间轴的视频编辑工具。
未来一年我们应该能看到更多类似的AI原生操作界面的尝试。这是一种从AI生成能力向AI创作能力延伸的必然。从更大的视角来看,大模型也到了让更多场景、更多行业、更多人感知到和使用起来的阶段了。只有这样,才能维持住大家对大模型的信心,让大模型发挥应有的价值,抵消一部分质疑的声音。
作者 | 李威
本文由人人都是产品经理作者【李威】,微信公众号:【窄播】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。






- 目前还没评论,等你发挥!


