
 起点课堂会员权益
起点课堂会员权益业务中“接入大模型”,到底有哪几种接入方法?
随着AI大模型技术的飞速发展,越来越多的企业开始探索如何将其融入自身业务,以提升效率、优化用户体验并创造新的价值。本文将详细梳理接入大模型的五种常见方式,帮助大家全面了解不同接入方式的适用场景、成本考量以及技术门槛。

DeepSeek 带来的国民级热度,很大程度上,是让整个社会都意识到,AI 大模型对于生产力提效的巨大价值,同时也带来了 AI 的洪流势不可挡、不拥抱就落伍的危机感。今年以来,很多公司都在积极拥抱 AI 实践,希望通过 AI,一方面提升自己企业、自己业务的效率,另一方面也希望为自己的用户提供 AI 的能力。
我们在新闻通稿中,会看到很多公司,都使用了“接入 DeepSeek”的说法,那么,所谓的“接入 DeepSeek 等大模型”,究竟都有哪几种形式?
其实不论是 DeepSeek,还是其他大模型,企业能够接入的方式,一般就是以下 5 种:
1. 个人直接使用平台功能
2.通过智能体平台搭建 Agent
3.API 调用
4.私有化本地部署
5.通过云服务商间接部署
01 个人直接使用平台功能
个人直接使用平台功能,就是以个人身份,直接使用大模型官方的 C 端的服务,比如直接登录 ChatGPT 官网、DeepSeek 官网使用,或者通过一些集成产品使用,但都是以个人身份使用通用的大模型产品。
这种方式对于小公司来说,实际落地的方式也就是作为内部的提倡,鼓励员工使用,或者公司出钱,买几个 ChatGPT 账号。比如我已知的几家大厂,程序员编程已经大规模使用 Cursor(一款 AI 编程软件),代码写得又快又好。
这种方式轻量简便,好处是能最快感受 AI 带来的工作变化,劣势是仅能作为个人工作提效的辅助,没有定制功能,数据安全也有风险。
02 通过智能体平台搭建 Agent
如果只是在官网中与 AI 进行简单的对话,AI 能够进行工作,也很有限,AI 的产出物也不太可控。实际工作当中,任何工作都有一个流程和标准的限制,才能让产出的结果,达到预定的标准。
比如「小红书运营」这项工作,如果让 AI 直接进行工作,是没有办法完成的,因为小红书运营包含着多种不同的工种环节。我们拆解一下,「小红书运营」这项工作,其实包含以下步骤:
选题-撰写文案-配图-发布-数据分析
这种把工作拆解成标准执行动作的过程,就是一个工作流,在工作流中,我们分别识别出 AI 可以应用的点,然后调用不同的 AI,帮助我们完成一长串的工作。
就好像有好几个“AI 员工”相互配合,最终做出一个成品。
比如以上的「小红书运营」工作流,AI 介入后,就可以:
- 通过可联网的大模型收集今日热点新闻
- 通过大模型分析有哪些选题
- AI 为选题生成文案
- 通过大模型为文案的配图,创作一个生图的 Prompt
- 调用文生图的大模型,使用 Prompt,生成配图
- 【人工】将文案和图片手动发布至小红书(实际上,这一步通过 RPA 也能自动发布,但不可控因素比较多,亨亨 V:xiaozidaheng 建议手动发布)
- 通过发布的笔记链接,抓取点赞收藏评论数据,进行数据分析
在每个环节,AI 都只解决一个具体的问题,然后把许多个 AI 的工作串起来,就成为了 AI 工作流(如下图)。
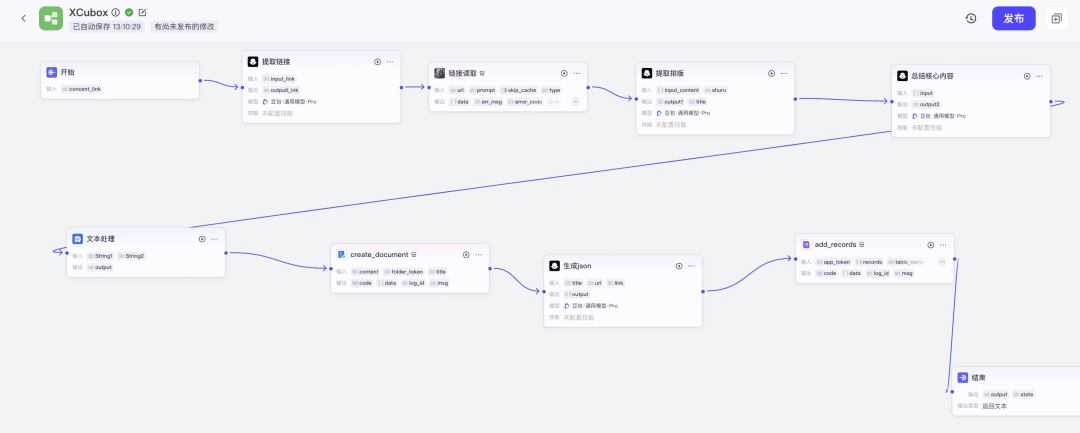
这种串联起来的工作流,就被称作 Agent 或者智能体,通过智能体搭建平台,可以方便的搭建出适合自己业务的智能体,并可以将智能体发布到企业内部的飞书、微信等平台,解决各种各样实际的问题。
智能体搭建平台,国内做得比较好的是扣子,集成了多种大模型。通过智能体平台,在企业内部部署 AI 的方式,好处很明显,就是能够低成本的将 AI 融合进企业的工作流当中,解决企业的实际问题,并且也不用开发,对于大多数不涉密的工作,这是性价比非常高的一种方式。缺点依然是使用公共的能力,不涉及私有部署,并且对于一些深度复杂的工作,还是没办法做好。

03 通过 API 调用
API 调用本质上也是在访问大模型厂商的能力,只不过无需去官网的对话框发消息,而是直接通过技术接口,将数据传递给大模型,大模型处理完成后,再通过 API 接口将处理结果返回。
调用 API 的好处是,能够将 AI 与自己的产品相结合,而无需跳转到 AI 大模型的网站。
04 私有化本地部署
DeepSeek R1 能够掀起 AI 应用的大浪潮,一方面是模型实力顶尖,另一方面是模型开源(DeepSeek 使用 MIT 协议开源)。开源就意味着,任何企业,都能够将 DeepSeek R1 部署到自己的服务器当中,并且可以通过微调,拥有一个属于自己的大模型。
目前宣布接入 DeepSeek 的企业中,几家大厂基本上都是采用私有部署的方式,为用户提供 DeepSeek 的能力。
私有部署的优势和劣势都很明显,适合有技术实力的公司。
优势:
1.企业自主可控的本地大模型,业务安全等级最高;
2.可对模型进行一定程度的微调,使其更符合企业业务需要。
劣势:
1.成本较高,不仅需要足够的算力,也需要人力进行运维;
2.需要比较高的技术能力,才能实现大模型的训练。
05 通过云服务商间接部署
DeepSeek 火爆之后,阿里云、腾讯云等云服务厂商,也第一时间推出了部署能力。这个过程,本质上是云服务厂商进行了私有部署,然后帮助使用云服务的企业,快速获得私有部署的能力。
这种部署方式,算是完全本地私有部署的优化版,牺牲一部分自主性,获得更方便的部署能力。
优势:
1.无需自行准备算力,可以使用云服务商的算力;
2.接入方便,成本较低,有一定的技术能力就可以完成接入;
3.可以进行小量的私有数据部署,实现大模型输出结果的小量定制。
劣势:
1.服务质量受到云服务商服务质量的影响;
2.并非完全自主可控,大部分信息是安全的,但绝密信息依然有风险。
06 总结
基本上,企业内部接入大模型的方式,就是以上 5 种。企业可以根据不同的情况和需要,选择合适的方式,进行部署。
我做了一张表,一目了然。
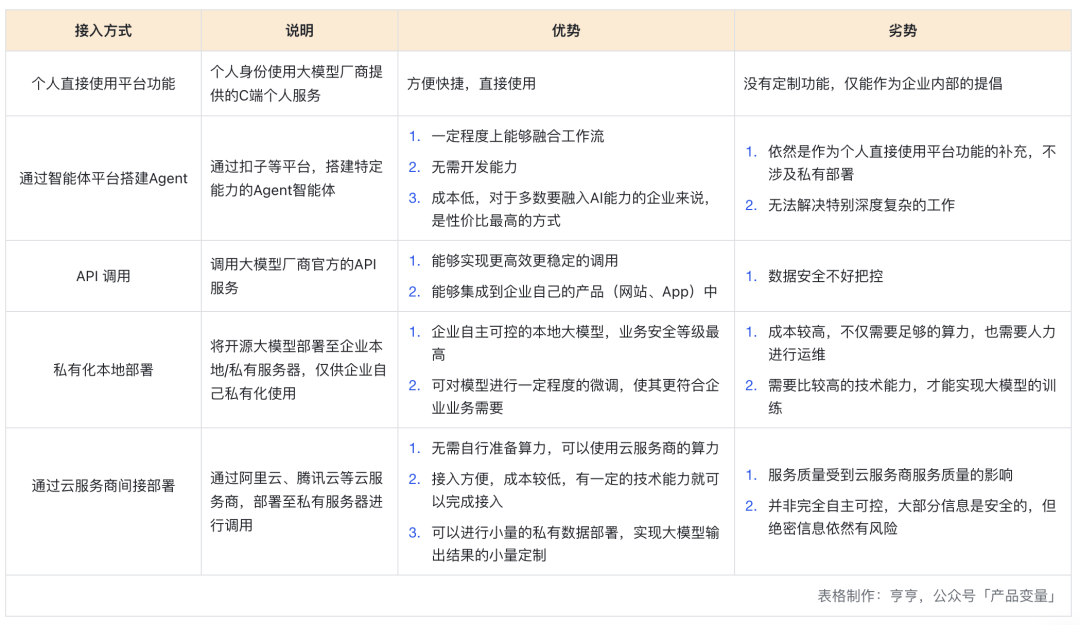
作者:亨哼;公众号:产品变量(ID:hengpaper)
本文由 @亨哼 原创发布于人人都是产品经理,未经许可,禁止转载
题图来自 Unsplash,基于 CC0 协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。






- 目前还没评论,等你发挥!


