
 起点课堂会员权益
起点课堂会员权益
企业要接入 DeepSeek 等大模型,应当注意哪些风控问题?
 B端产品经理需要更多地进行深入的用户访谈、调研、分析,而C端产品经理需要更多地快速的用户测试、反馈、迭代
B端产品经理需要更多地进行深入的用户访谈、调研、分析,而C端产品经理需要更多地快速的用户测试、反馈、迭代随着AI大模型如DeepSeek的兴起,越来越多的企业希望接入这些技术以提升效率和产品体验。然而,企业使用大模型并非简单的技术接入,还涉及诸多风险控制问题。本文从经营和业务视角出发,详细梳理了企业在接入大模型时可能面临的风控挑战,并提出了针对性的解决方案,供大家参考。

DeepSeek 的热潮,从春节一直持续到现在,一浪接一浪。最开始是科技媒体和自媒体,对于 DeepSeek 展开讨论,而现在凑风口的,则是众多企业,纷纷宣布接入了 DeepSeek,就连国民级应用微信,以及竞争对手文心一言和腾讯元宝,也纷纷宣布在自家大模型的软件里,接入了 DeepSeek 。
AI 的发展势不可挡,AI 革命正在如火如荼,很多企业都有接入大模型产品,提升内部效率或者产品体验的意愿和需求。但是,企业使用大模型不同于个人,要考虑商业机密、业务安全等等诸多问题。
本文,我们就彻底厘清楚,企业要接入大模型,应当注意哪些风控问题。这不是一篇技术文章,而是更多的从经营和业务视角,用相对通俗的语言,识别出企业在实际落地 AI 过程中,不可忽视的 AI 风险。
01 接入大模型,会面临哪些潜在风险
在研究大模型的风控问题前,我们首先要明确,企业接入大模型,都有哪几种方式。
我在《业务中“接入大模型”,到底有哪几种接入方法?》一文中专门写过,不论是 DeepSeek,还是其他大模型,企业能够接入的方式,一般就是以下 5 种,这张表格总结了各种方式的优劣势。
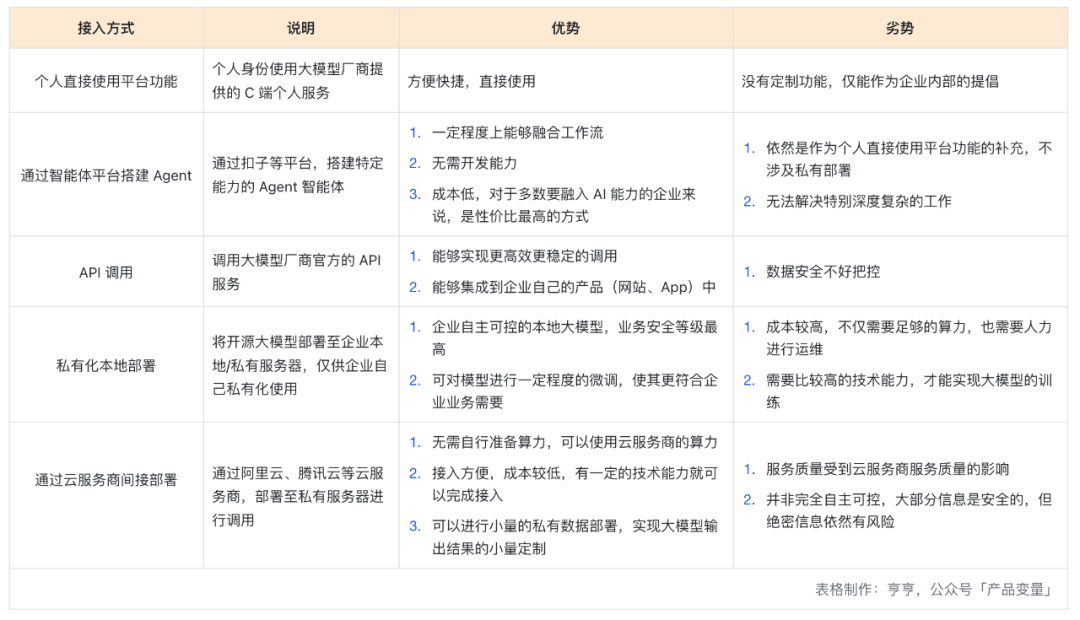
在不同的接入方式里,由于部署方法和使用方式的不同,所包含的风控点也不同。
个人直接使用平台功能,和通过智能体平台搭建 Agent,这两种方式,由于是公用平台,因此数据保密等级最低,作为个人工作的 Copilot(副驾驶、助理),没太多问题,但如果要把企业的机密信息传入,就容易产生信息泄漏。

API 调用、私有化本地部署、通过云服务商间接部署,这三种方式,一方面涉及到对大模型的调整和训练,另一方面也涉及到模型输出内容会公开,所以涉及到比较多的风险,比如训练数据合规、权限控制、输出内容审查等。
具体的风险类型和处理方法,我们在下文详细展开。
02 如何进行 AI 大模型的企业风控
根据 AI 的使用者与 AI 大模型产生交互的时机,我们把企业接入大模型的风险,分成三个阶段:传入模型时风控、模型处理中风控、模型输出时风控。
传入模型时风控
这一阶段,是信息进入大模型的入口阶段,日常的 AI 问答不会有问题,最大的风险,就是业务敏感信息泄漏和数据合规。
风险点一:数据安全风险(保密数据、隐私数据)。
在实际工作中,会因为业务需要,把实际业务的真实数据、或者重要的商业机密发送给 AI,在这个过程中,很容易将公司的核心机密流传出去。
例如 AI 能力的提供方(不一定是大模型的研发公司,也有可能是提供 AI 服务的第三方等)可以查看到用户与 AI 对话的内容;或者 AI 在接收到信息后,内化于自己的数据库,在与另外的用户对话时,将信息泄漏;又或者“伪本地化”部署方案中,若接口加密不完善,攻击者可通过逆向工程窃取传输中的业务数据。
解决方法就在于对于数据安全的重视,主要是 2 个:
1. 针对保密数据和隐私数据,在底层的表结构上,就做好权限控制。基本原则是「最小权限原则」,即限制数据可访问的范围和保密等级,例如一些敏感数据,只有达到一定权限的人才能增删查改,其他人不能访问,从数据获取的源头上,就做好把关。
2. 加强公司成员保密意识,在使用 AI 时,对敏感数据进行脱敏处理。AI 的运行过程中,如果必须使用某些数据,那么就应当对数据进行脱敏,比如 AI 大模型在调用用户数据表时,提前将用户的身份证号和手机号,进行模糊化处理。
风险点二:训练数据合规风险
除了数据保密的风险,企业还得多关注训练数据的合规性。什么意思呢?就是拿来训练大模型的数据,必须得合法合规,不能踩法律的红线。尤其是隐私保护和知识产权,稍微不注意,就可能让公司在法律框架内触及红线。如果某些数据只是拿来训练,不会对外提供服务,那么训练过程中,要做好数据生命周期的管理工作,及时销毁使用完的数据。
同时,数据的质量把控也得过硬,这是为了大模型的品质考虑,这很好理解,如果数据质量过差,大模型的水平自然也不会好。
模型处理中风控
模型处理中的风控问题较多,某种程度上,也不仅仅是技术上的风控问题,也是企业内控的一些要求。在这个阶段,需要关注的风控问题主要有 5 个。
风险点一:模型伦理风控
因为 AI 训练的过程,大多是黑盒,很多时候,我们并不知道 AI 在处理信息时,究竟是怎么一个“脑回路”,所以大模型往往会搞出一些科技伦理问题。模型伦理这块儿,主要是别让 AI“学坏了”。
比如招聘场景下,AI 可能因为历史数据男性偏多,因此在进行处理时,形成对女性的偏见;或者由于网络上对于某个人群的过度歧视,导致 AI 进一步加强这种歧视。

所以在模型训练中,企业必须得用多样化的数据,把偏见扳回来,还需要在产品研发流程上,增加一些伦理审核流程,别让模型做出违背道德伦理和科技伦理的行为。毕竟,谁也不想自家 AI 变成“道德滑坡”的典型吧……
风险点二:模型可解释性
模型可解释性,通俗点讲,就是得搞清楚模型为什么这么决定。
大模型的训练与使用过程,我们已经非常熟悉:将问题和需求告知 AI,AI 自行处理后返回结果,这个结果可能是符合常理的,也有可能是完全意想不到的。这种不可控性,对于大多数场景而言,都是无害的,甚至能通过天马行空的想象,挖掘出不一样的灵感。
但是,有一些场景,AI 的不可控性,反而会成为掣肘,如果让模型黑盒跑,谁也不知道它怎么想的,那出了错,都没法向用户解释,严重一点,监管也会找上门。
而且,光和 AI 聊天,还只是算是初步应用,要想让 AI 能够大规模释放生产力,还是得让 AI 进入到工作流程中。比如金融方案、医疗推荐,AI 产生一个答案,那产出的过程中,因为什么?参考了什么?逻辑是什么?理由是什么?怎么推理出这个答案?这些问题,都需要能够有理有据的择出来,也就是大模型的推理结果,要有「可解释性」。
可解释性的保障,不仅仅要在模型严谨程度的参数上做调整,也要在产品流程上进行介入。例如在产品流程上,强制性让 AI 处理过程分为几个步骤,并每个步骤强制性索引所有引用到的材料,或者在每个步骤,都设置监控工具,确保出了问题,能查到根源。
风险点三:行业合规要求
主要是特定行业和特定区域的合规要求,比如医疗行业的临床要求、欧盟国家的 GDPR(欧盟跨境数据法规)等。
风险点四:算力、成本、运维的内控问题
尤其是私有部署的方案中,企业内部能够形成“成本陷阱”的地方特别多,因此,企业在内部制度上,要做好企业内控和技术方案的选择。
大模型的训练,所需要的算力,是非常大的成本,即使是采用公有云的部署方案,花费也不低。因此,选择怎样的技术实现方案,性价比更高?哪个云服务的配套,更有优势?算力是否有闲置,算力采购过程中是否有舞弊?这些都能看作是大模型部署的内控关注点,不要稀里糊涂的把钱烧出去。
风险点五:模型失效与性能退化
是的,模型也是会退化的。
大模型部署完成后,并非一劳永逸,即使不考虑新模型对旧模型的超越,单就同一个模型来看,也存在性能退化的问题,时间长了可能就“老化”了。
这种老化,一般是由于数据分布漂移、数据循环污染等原因造成。数据分布漂移就是,现实世界的情况会随着时间变化,但模型中的数据不会,就会产生偏差(比如 20 世纪的某些政策并不能套用到 21 世纪)。数据循环污染是大模型与大量用户对话后,被拉低了数据质量,导致模型的茧房加剧,偏差加大。
所以在应对模型失效与退化上,监控和预警机制、数据更新和再训练的策略、数据容灾与回滚机制等措施,都很重要。同时,在组织与流程上的保障也是要考虑的,比如专门的团队和 SOP,来对模型的实际表现,进行定量和定性的监控。
模型输出时风控
这个过程比较容易理解,就是对于模型输出的内容,本身也需要进行一定的筛选和过滤,以便符合内容合规的要求。这部分的内容风控,本质上与社交媒体发布信息时间的风控,是类似的。
输出阶段,传统的信息合规要注意:
- 政策层面的内容合规,要符合监管的要求。
- 社区氛围的良性导向,如谩骂、隐私等。
- 社区用户安全的保证。
这部分现有的解法都非常成熟,机器学习+人工审核的配套方案,基本上不会出现问题。
AI 场景中,还需要额外注意一个“AI 幻觉”的问题。目前的大模型,或多或少都有这个毛病,爱“胡说八道”,比如编个不存在的事实,或者胡扯一个数据来源。所以在某些严肃场景下的业务,企业要在输出检查上,多做几道验证。
03 风控是为了更好的创新
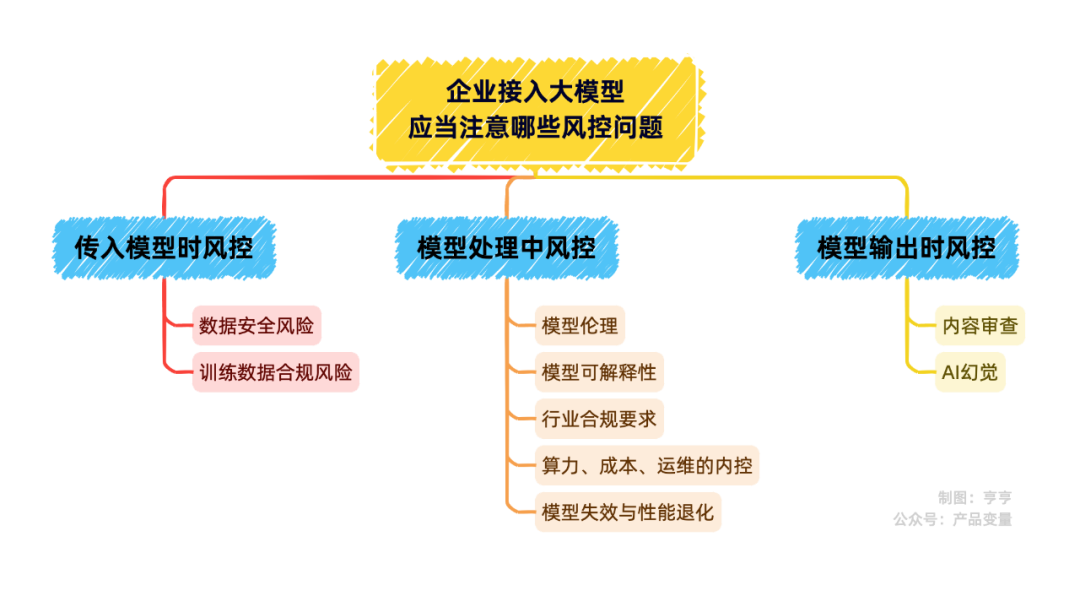
接入大模型,能给企业带来效率和创新,但风险也不少。从传入模型时的数据保密和合规,到处理中的可解释性、伦理、行业标准、成本控制和性能维护,再到输出时的内容审查和减少幻觉,企业得全盘考虑,步步为营。
怎么管好这些风险?需要有一个完整的 AI 治理框架,数据得管严、合规得做足、模型得选对、部署得合理,并且随时优化。只要把这些风控点掐住了,企业才能放心用 AI,既安全又高效。
作者:亨哼;公众号:产品变量(ID:hengpaper)
本文由 @亨哼 原创发布于人人都是产品经理,未经许可,禁止转载
题图由作者提供
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。







- 目前还没评论,等你发挥!









