
 起点课堂会员权益
起点课堂会员权益言变图的“LLM时刻”,还有AI全家桶,Google杀疯了
在生成式AI快速崛起的浪潮中,Google以全新的产品矩阵和技术升级迎来属于它的“LLM时刻”。从文本到图像,从工具到生态,AI全家桶的发布让人们看到技术无边的可能性。本文将带你深入解读这些突破背后的技术逻辑与市场策略,探讨Google如何在AI竞赛中拔得头筹,并展望行业未来的新格局。

对于Google来说,作为Transformer等核心技术的发明者,在“AI 4巨头”的讨论中没有它,是一件很尴尬的事情。
这让其一直憋着一口气,决心证明自己。最近Google的系列更新就颇具看点:
发布开源模型 Gemma 3,性能超越DeepSeek V3、o3mini为全球第二强开源模型,但是模型大小仅为7B。发布Gemini 2.0 Flash Experimental,动动嘴就能PS的AI文生图产品。不仅如此,对指令理解也相当到位,能连续生成一致性图片,并评为AI生图的GPT时刻,这几天在X传疯了。Deep Research开放免费使用,背后是2.0 Flash Thinking Experimental 提升推理能力并扩展上下文窗口。还有新一代 机器人 AI 模型Gemini Robotics ,对物理世界更懂了。
国外有网友评价Google这次更新,是几乎每项到了最佳:

到底有没有这么强呢,鲸哥认为是大差不差,有惊喜,也有吹嘘。
先说这次最被热议的更新—Gemini 2.0 Flash Experimental。 原生图像生成功能上线,说话就能PS照片的梦想实现。通过聊天任意编辑图像的局部或者全部,有点类似Adobefirefly版本。
我们用英伟达CEO黄仁勋此前发布会的图片,来试试是否可以随意PS。

我们先要求换背景,让黄仁勋在直播间中带货。这个难度不大,是不是抠图也不好说。

“321上链接”,5090显卡刀法精准,直接卖爆了,我们让黄仁勋开心地笑起来。看得出来表情有些崩,但整体还是做到了AI改变人物表情。

再要求把脸从黄仁勋换成马斯克,这个挺顺畅完成了,马斯克的脸部还挺逼真,表情也比较自然。一个小细节,摄像机上手机屏幕中的人物也跟着换成了马斯克。

还有一个这两天大家很爱玩的功能,就是这个合成图片的功能,熊的视角略微有一些转向,但是合成图片中还原的还不错。

很多人会质疑这个功能有什么用,国外有小伙,利用gemini-2.0 新推出的图片编辑 API,连夜肝了个工具,实现白底图到产品实拍图的批量自动化生成。
他是这样评价这个产品:“效果炸裂,特别是对产品的特征保留的很好,相比 ComfyUI 工作流调个半死,这不强多了。”
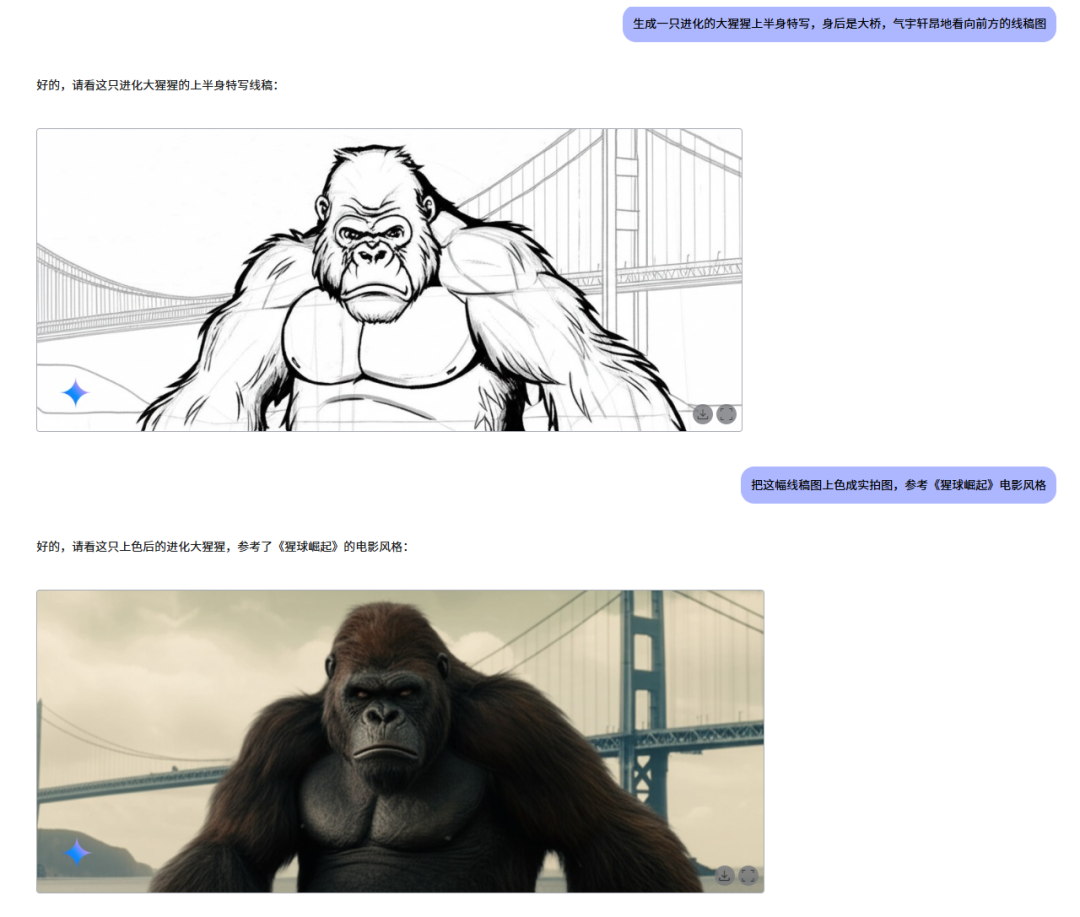
当然它还能给线稿上色,鲸哥生成了“猿力崛起”类似的图片。生成效果确实还没有Midjourney强,但是能力很连贯,这是生成式AI的体现,这是预言挑战画家的颠覆性一步。
Gemini-2.0不仅改图能力强,还能生成连续性的图片故事集,效果也不错。以下是鲸哥测试的成果。
“生成一个关于爆炒羊杂教程系列图片。对于每个场景,生成一个图像和一段介绍文字。”Google生成的教程显示有点长,我在排版时用SVG动画显示了,大家点击下方即可查看。
羊杂切碎,调好备料最关键是羊杂焯水



羊杂切碎,调好备料最关键是羊杂焯水
放油,先炒调料再加入羊杂爆炒·



放油,先炒调料再加入羊杂爆炒
放入蔬菜,炒至断生加入勾芡,炒熟装盘·



放入蔬菜,炒至断生加入勾芡,炒熟装盘
感谢Google,终于知道中午做的爆炒羊杂为啥不好吃了,原来没有先把羊杂焯水(直男落泪)。
此前的 2 月,Google Veo 2 已通过 Freepik 发布了图像转视频功能,现在与2.0 Flash有很好的结合了。
这个视频是JP博主制作,用一张AI生成的美女和商品图结合,先是生成了带货图片,然后转成了视频,神奇的是视频中饮料的商标都没有变,目前在X上很火。
最后再讲一个很有用的东西,应该比以上视觉工具更加落地。
是不是大家仍没有Manus邀请码,感觉也不用苦苦等待了。Google deep Research 现在可以免费使用,由 2.0 Flash Thinking模型提供支持,而且可以展示研究过程(chain of research),甚至支持链接你的搜索记录对 Gemini 进行个性化设置。
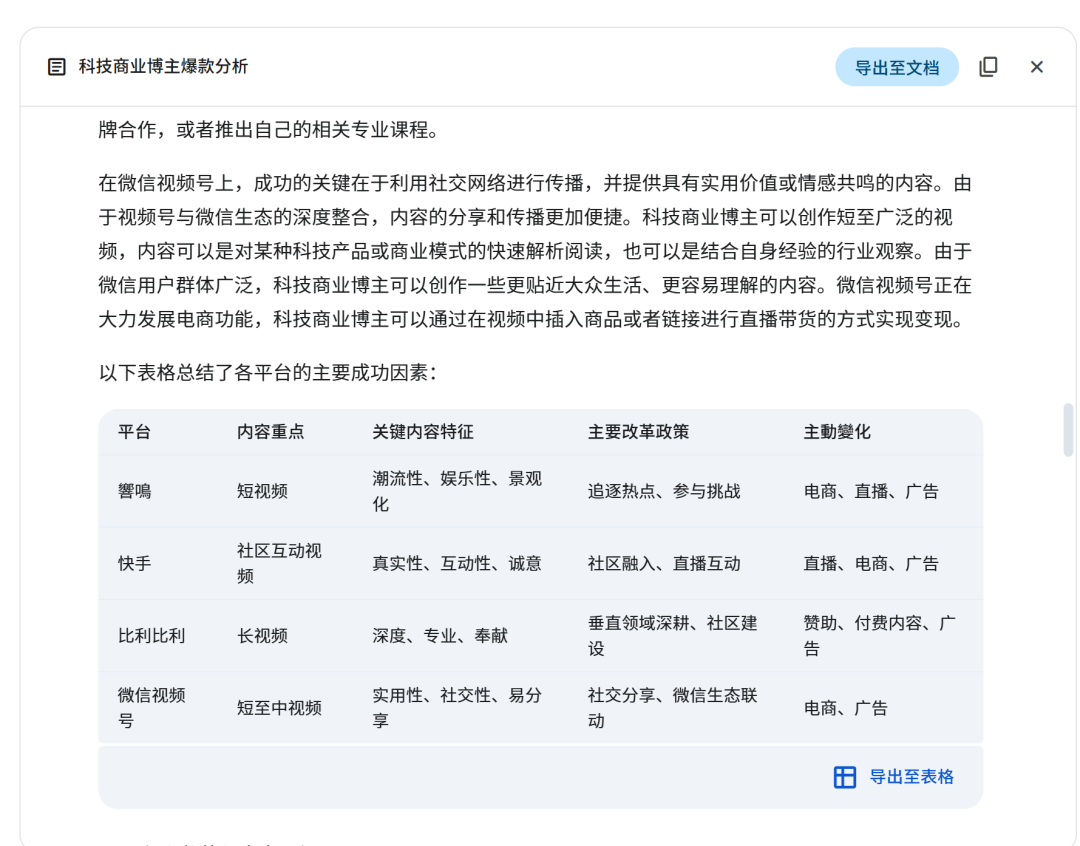
这是我做的“中国视频类科技商业博主起号及爆款”研究专题,要求生成30页以内的PPT报告。
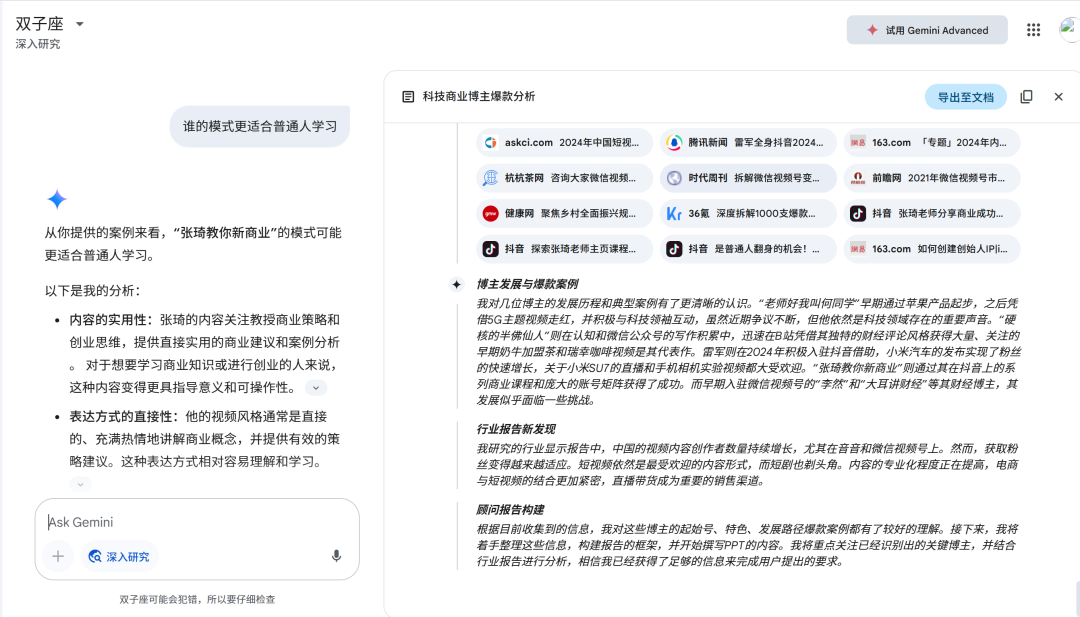
还能根据这份报告继续提问,我问了下最适合普通人学习的博主是谁,回答结果如下,额,不知道大家怎么看这个结果。
Deep Research能罗列Researching websites,这样你可以清楚看到引用的哪些网站内容,靠不靠谱。同时这也是Google deep Research 的优势,搜索内容的广度上要比OpenAI 大很多,甚至能索引 YouTube 内容。
最重要的是,它输入框底下有行字,“Gemini can make mistakes, so double-check it”,避免出错进行了双倍检查。这就极大避免了幻觉率,确保提供的信息,一定范围内的准确性。
当然问题也有,就是这个产品不太Agent,让生成PPT最终没有生成,估计是因为调用不了其他工具。我体验导出报告,调用Chrome文档也不流畅。以后使用MCP协议估计效果会更好。
在基础语言模型方面,最大的更新是发布最新开源模型 Gemma 3 。
最大仅为27B,性能超越DeepSeek V3、o3mini,为全球第二强开源模型,仅次于DeepSeek R1,但是模型小很多,达到差不多的性能。
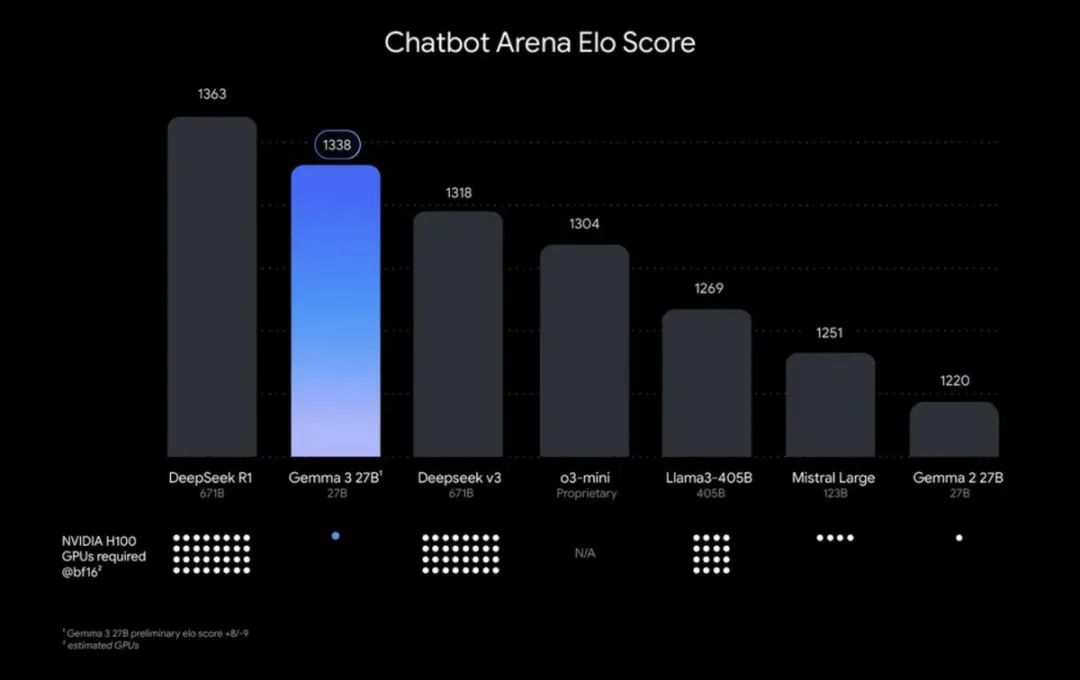
其他几个模型分别为 1B、4B、12B 和 27B,微型模型意味着可在手机、电脑上跑。
虽然模型小,但是各方面能力都具备。比如增强文本和视觉能力,可理解文本、图片、短视频。支持128K上下文窗口 ,支持函数调用,支持AI 代理开发,自动执行任务。
不仅是通用LLM模型更新,Google还在具身智能领域做了很大的改进。
Google DeepMind 推出基于 Gemini 2.0 研发的新一代 机器人 AI 模型Gemini Robotics 。
首先是具备泛化能力:Gemini Robotics利用Gemini 2.0的世界理解能力,机器人能够处理未见过的新物体、新指令和新环境,甚至完成训练中未见过的新任务。
在综合泛化基准测试中,Gemini Robotics的性能比其他最先进的VLA模型高出一倍以上。
例如,它能完成未训练过的任务,如扣篮一个新篮球。-
其次是交互性:它能理解日常语言指令(包括不同语言),并快速响应环境或指令的变化。例如,当物体被移动时,它能迅速重新规划行动路径,无需额外输入即可继续任务。
然后还具有灵活性与灵巧性:通过多模态推理(结合视觉、语言和动作),机器人能精确操控物体,完成多步骤任务。支持执行需要精细动作的复杂任务,如折叠纸鹤、将零食装进拉链袋或轻柔放置眼镜。
要知道,一开始,Google在大模型这波生成式AI浪潮中确实落后了。通过这两年的蛰伏,Google还是证明了其技术储备,完成了一场AI逆袭。
作者丨鲸哥
本文由人人都是产品经理作者【AI鲸选社】,微信公众号:【鲸选AI】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。






- 目前还没评论,等你发挥!


