
 起点课堂会员权益
起点课堂会员权益AI 大模型训练全攻略:5 步打造你的 ‘ 超级学霸 ‘AI
如何通过五个简单步骤,打造出属于你的“超级学霸”AI?这篇文章将为你揭示大模型训练的全攻略,助你轻松掌握核心技术,开启AI创新之旅。
大模型训练就是先让 AI 掌握海量知识,再通过 “超级大脑” 处理复杂任务,最后针对具体工作进行优化的过程。大模型训练流程是连接理论与实践的桥梁,无论你想短期跃迁职业竞争力,成为稀缺的复合型人才,还是想长期立志深耕 AI 领域,了解大模型训练的过程都是必须跨越的认知鸿沟。我会用通俗易懂的语言为您详细拆解大模型训练的核心流程,就像组装一台超级计算机一样,我们一步步来:
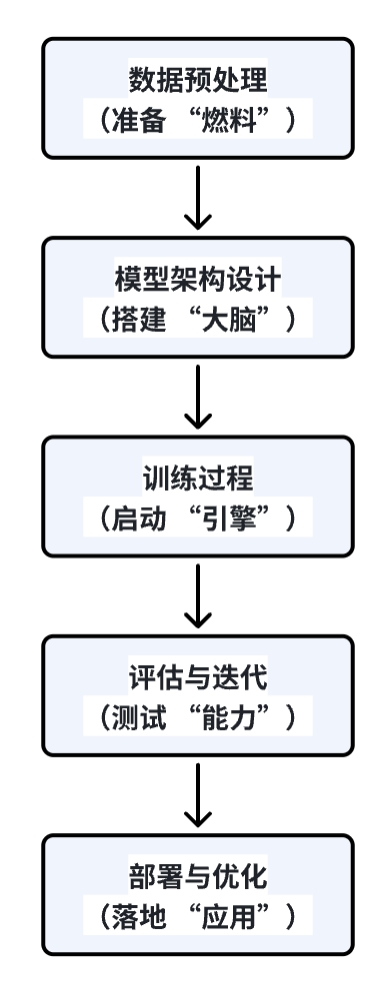
一、准备 “燃料”:数据预处理
1、数据收集
模型需要海量数据(如文本、图像、语音),例如训练对话模型需要收集网络对话、书籍、文章等。这些数据的质量直接影响模型能力,垃圾数据会导致模型 “胡言乱语”。就像厨师需要食材,食材好坏也会影响最终的菜。
2、数据清洗
过滤重复、错误、敏感内容(比如脏话、过时信息)。比如:数据中有 “2020 年美国总统是奥巴马”,需要修正为 “拜登”。
3、数据标注
给数据打标签(如 “这张图是猫”“这句话表达愤怒”)。对于复杂任务(如阅读理解)需要人工标注,成本很高哟。
4、数据增强
用技术 “变出” 更多数据。对于文本进行同义词替换、句子重组(如 “我吃饭”→“饭被我吃”)。对于图像进行旋转、裁剪、添加噪声。
二、搭建 “大脑”:模型架构设计
1、选择基础架构
目前主流是Transformer,这个在上一章节中有详细介绍。
2、参数规模
参数数量 = 模型复杂度。小模型有几百万参数,而大模型则有千亿参数。比如:GPT-3 有 1750 亿参数,相当于每个字都有一个 “小专家” 在处理。
3、预训练 vs 微调
预训练是用海量通用数据(如全网文本)学习基础知识(类似上学),让其撑握语言规律、常识、逻辑。微调则是用特定任务数据(如医疗对话)优化模型(类似职业培训),让其专精某个领域。预训练模型像 “百科全书”,微调模型像 “专业词典”,微调后模型在特定领域准确率可提升 20%-50%。
Transformer 架构是大模型的 “骨骼”,参数是 “血肉”。没有架构的支撑,参数无法有效存储和利用;没有参数的填充,架构只是空壳。二者的协同进化推动了 AI 从 “玩具模型” 到 “通用智能” 的飞跃。
海量通用数据是大模型的 “知识原材料”,参数是 “知识存储器”。预训练通过让模型分析数据自学规律,将数据转化为参数中的知识。未来,随着数据效率提升和架构优化,模型可能用更少数据和参数实现更强能力,但当前阶段,数据与参数的协同仍是大模型发展的核心驱动力。
微调是大模型从 “通用能力” 到 “实际应用” 的关键桥梁。通过特定任务数据和参数优化策略,模型能在保留通用知识的同时,精准解决细分领域问题。未来,随着参数高效微调技术(如 LoRA、QLoRA)的普及,微调将变得更高效、低成本,推动大模型在垂直领域的落地。
三、启动 “引擎”:训练过程
1、分布式训练
用多台服务器(甚至成百上千台)同时计算,类似 “多人接力跑”。但服务器之间同步数据耗时,所以要注意优化通信效率。
2、梯度下降优化
梯度下降优化的目的是为了找到模型参数的最优解(类似下山找最低点)。可以通过学习率调整(类似开始大步下山,接近山脚时小步调整)和混合精度训练(用半精度浮点数减少计算量,速度提升 2-3 倍)技术手段来实现。
3、防止过拟合
过拟合是指模型死记硬背训练数据,无法泛化(类似 “高分低能”)。可以通过随机关闭部分神经元,强迫模型学习更通用的规律和给参数增加惩罚项,避免参数过大来解决。
四、测试 “能力”:评估与迭代
1、内部验证
内部验证是用训练数据的子集(如 10%)测试,检查模型是否 “记住” 了数据。
2、外部测试
外部测试是用从未见过的数据评估,确保模型能 “举一反三”。评估的指标有准确率、损失值(数值越小越好)、BLEU 分数(机器翻译评估)等。
3、人工反馈优化
人工反馈优化是让人类标注员给模型回答打分,用强化学习调整参数(如 GPT-4 的 RLHF 技术)。
五、落地 “应用”:部署与优化
1、模型压缩
模型压缩指用更低精度的数字存储参数(如用 8 位整数代替 32 位浮点数)和去掉冗余参数(类似修剪枝叶)把千亿参数模型 “瘦身” 到手机端。
2、推理加速
推理加速指用专用芯片(如 NVIDIA A100)或框架(TensorRT)优化模型运行速度。比如:手机上的语音助手每秒处理数万次推理。
3、场景适配
根据需求调整模型,比如需要增加上下文理解能力的对话系统,强化视觉细节的图像生成。
总结
大模型训练就像培养一个超级大脑,需要海量数据喂养、巧妙的架构设计、高效的训练方法,最后通过持续优化让它适应各种任务。对于普通人来说,现在可以通过云平台(如 Google Colab)体验小规模训练,未来随着技术发展,门槛会越来越低!
本文由 @产品老林 原创发布于人人都是产品经理,未经许可,禁止转载
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。


![[万字思考]ChatGPT+时代,我们的工作和生活方式均将会彻底发生改变](https://image.woshipm.com/wp-files/2023/04/aJlBrI8FRQUBHOXXB6DH.jpg!/both/120x80)



- 目前还没评论,等你发挥!


