
 起点课堂会员权益
起点课堂会员权益KnowHow与RAG:你的工作数据正在训练替代你的AI
在人工智能飞速发展的当下,AI正在深刻改变我们的工作方式,甚至有可能替代部分人类的工作。然而,AI的训练和发展并非孤立存在,它背后依赖的是大量的行业知识(KnowHow)和数据。本文将深入探讨如何通过RAG(Retrieval-Augmented Generation,检索增强生成)技术,将行业经验与AI相结合,实现知识的可信化和结构化沉淀。

对AI项目有理解的同学会有深刻认知,当前AI应用的核心其实全部在围绕幻觉与模型增强两点做展开。
而这在积累层面的核心是行业KnowHow,其最终体现为公司的结构化数据;在技术方面以RAG与模型训练为主。
并且公司会“乐此不疲”的做这方面的调优,因为从模型层面来说,这些工程应用的细节,基座模型很难兼顾处理。
而数据一块非一朝一夕之事,所以很多公司的关注点全部放在了RAG技术的平台化或者做延伸,阿里的KAG框架就是这类产物。
后续我们会持续讨论类似这种RAG框架,包括DeepSearch、LazyGraphRAG等。而今天我们先来说说think的问题。
一、think变成习惯
由于实际效果或者行业教育,人们已经习惯看到界面中出现长篇大论的“思考内容了”,甚至他们会主动去学习这个内容,觉得是一种进步或享受。
之前AI聚会明叔就一再强调think是非常好的创新,但宜博会站在技术实现角度认为他是一种工程优化或者工程创新,真实情况也如宜博所述,DeepSeek与4o的例子:
请按以下格式回答问题:
##思考过程##
1. 分析需求:首先我会理解用户的核心诉求是…(拆解隐藏需求)
2. 知识检索:关于这个问题,我需要调用的知识包括…(列出相关领域)
3. 逻辑推演:可能的解决路径有: – 方案A(优势/劣势) – 方案B(适用条件分析)
4. 风险评估:特别注意…可能存在…认知偏差
5. 自我验证:通过…方法可以验证结论的可靠性
##最终答案##
(经过上述思考后的最佳方案)
问题:管理的本质是什么

从大模型特性来说,通过提示词的方式虽然能达成目的,但没有大量高质量数据微调后达成的效果(主要体现在泛化与学习这个维度)。
二、RAG的切入
当然以上仅仅是非常浅显的描述,实际在使用过程中,差距很大,比如我这里给出一段法律用于强化学习的片段:

为什么会着重介绍这些内容呢,因为无论是对大模型直接的使用还是微调都是无法溯源的,而无法溯源的东西,都会被怀疑成不可信,于是RAG的含金量还在上升,特别在think里面具备溯源的信息,表明对哪些信息的引用。
比如以下文字就特别让人安心:
根据《劳动合同法》第三十条规定,“用人单位未按照约定支付劳动报酬,劳动者可以解除劳动合同。” 同时,根据最高人民法院的相关判例[2020]XX法判字第999号案件,法院认定雇员在工资未按时支付的情况下有权解除合同,并获得补偿。 因此,依据这些法律条文和相关司法解释,雇员可以依法解除劳动合同,并要求支付相应的补偿。
在推理大模型的框架下,R1越发期待用户提示词的手法能像描述需求一样,不仅举报指令,还有完整的上下文,不仅提供问题还要提供问题的背景信息,这个拆解过程与5W2H很是类似,如果再加上权威引用,那就更妙了!

三、RAG本质:可信化解构
逻辑上以下四个问题,模型都无法解决,越是大的模型越难解决:
- 领域内部知识库,比如公司、医院内部知识库如何AI化;
- 信息过时,虽然模型信息更新迅速,但其信息依旧有一些滞后性,这对于被抖音教育的各位,显然是不够的。虽然有网页搜索功能但其成本和质量还需要做技术突破;
- 幻觉,这应该是模型最难的问题,特别是参数量大的问题,在不同领域之间源数据就可能产生逻辑层面的冲突,暂时看来能避免、难以根治,比如领域知识的模糊泛化(法律条文误读风险达37%)、决策过程的不可追溯(医疗诊断错误无法溯源);
- 安全,因为模型海量数据来源于网络,那一定会有倾向性,比如R1模型在男性倾向性上就很大,如果做心理类咨询,多半是不能直接使用的;
RAG通过动态知识注入+向量检索+溯源标记构建三重防线以解决上述问题,其目的只有一个:用用户相信我的回答,并且让自己相信产品的回答!以法律场景为例:
A[用户提问] –> B(法条向量库)
B –> C{相似度阈值>0.82}
C –>|是| D[返回民法典第1073条]
C –>|否| E[触发人工审核]
D –> F[生成带条款编号的解析]
而RAG技术在每个公司都有一个持续增进的过程,大概是这样的:
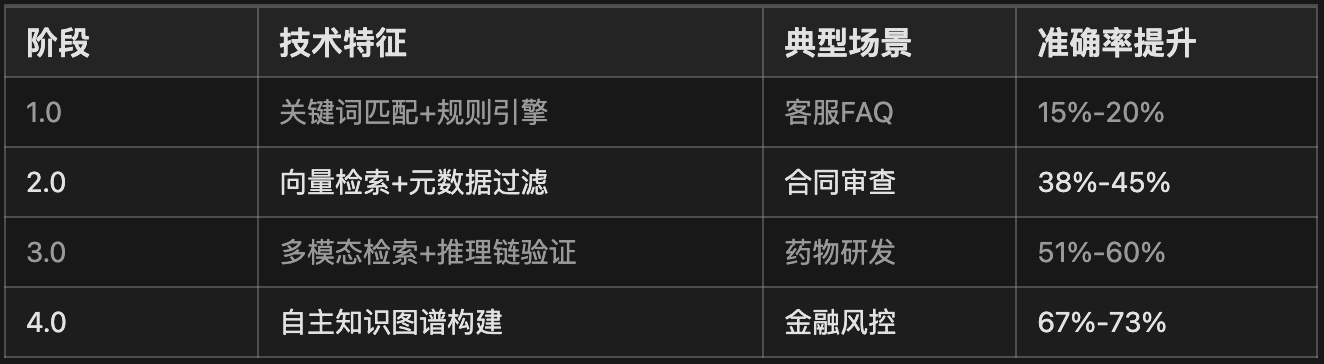
以下是传统提示词工程 与 结构化Think框架的一些对比:
# 传统方式
prompt = f”请详细解释管理的本质,需要包含经典理论案例”# Think框架
think_template = {
“分析需求”: “识别用户的知识层级(学生/管理者)”,
“知识图谱”: [
“德鲁克MBO理论”,
“明茨伯格管理角色”,
“华为铁三角案例”
],
“推理约束”: “避免混淆领导与管理的区别”,
“溯源要求”: “标注理论出处与案例来源年份”
}
其实所谓可信度也就是一个感觉罢了,不过是一个评价指标,我随便都可以胡诌几个玄的:
- 时空锚点:法律条文需标注”2023年修订版《民事诉讼法》第58条”;
- 置信度标注:医疗建议注明”基于2024年NEJM论文,置信度89.7%”;
- 反事实校验:”如果采用泰勒科学管理理论,可能产生哪些现代管理冲突?”;
这里的核心依旧是行业KnowHow的数字化沉淀。
四、数字化沉淀
其实所有的RAG本质都是结构化的数据库,只不过这个库能到什么程度端看行业认知以及持续建设情况,一般来说有四个评价维度:
1. 基础图谱
比如医疗领域基于ICD所做的疾病关系,很多CDSS的底层就是图谱;
金融领域也有FIN-NLP金融术语体系;
2. 流程规则
与其说流程规则不如说SOP,比如:化疗方案决策树、信贷审批流程图等。
逻辑上,只要能SOP就能数字化,能够数字化就一定能够AI化。
3. 数据更新
基础图谱只是第一步,更重要的是持续的更新,比如如何用专家会诊记录、操盘手交易日志分析等数据去持续自动化更新基础库,这是关键。
4. 异常处理
一定会有跳出图谱框架、SOP框架的行为,我们这里称之为AI意图溢出Case,这种Case要有专业的预案,要么放给大模型处理,严谨点就不处理。
其本质是黑天鹅事件,这种Case是系统升级的关键。
为了帮助各位理解,这里做更深入点的介绍:
5. 基础库案例
比如常见CDSS案例:ICD-11疾病分类本体
# ICD-11本体片段示例
class 疾病实体: def __init__(self):
self.名称 = “冠状动脉粥样硬化性心脏病”
self.编码 = “BA41.0”
self.父节点 = [
“心血管疾病”,
“慢性病”
]
self.关联症状 = [
“胸痛”,
“呼吸困难”
]
self.诊断标准 = {
“必要条件”: [
“心电图ST段改变”,
“心肌酶升高”
],
“排除条件”: [
“应激性心肌病”
]
}
这种是最理想的RAG数据源,比如:当AI处理”患者主诉胸痛”时,能自动关联到冠心病诊断路径,而非停留在字面理解。
再列举个金融案例,FIN-NLP金融术语体系,会有很多黑话:
- 银行语境:收益互换 = 利率风险管理工具;
- 投行语境:收益互换 = 结构化衍生品;
- 监管文件:收益互换 = 需备案的场外交易;
其底层依旧是数据库的结构化和后续的检索。
6. 流程规则
医疗案例:化疗方案决策树
传统依赖大模型跟医生靠自觉没什么两样,但如果遵循一套SOP,其下限就能得到充分保障:
graph TD A[患者特征] –> B{癌症类型}
B –>|乳腺癌| C[检测HER2表达]
C –>|阳性| D[曲妥珠单抗方案]
C –>|阴性| E[评估化疗敏感性]
E –>|敏感| F[AC-T方案]
E –>|耐药| G[基因检测驱动]
这里的SOP还能多样化,可以是协和医院顶级专家的决策模式、也可以是华西的决策逻辑,其本质都是可复用的算法。
信贷审批流程图也是同样,其规则是很简单的:
- 1.0时代:收入证明 > 2万 → 通过;
- 2.0时代:多头借贷数据 + 手机行为分析 → 风险评分;
- 3.0时代:供应链数据交叉验证 + 工商信息动态监控;
我的一个咨询客户通过分析企业主抖音账号经营数据(非结构化→结构化),发现隐性经营能力证据。
7. 飞轮系统的雏形
AI产品在使用过程中会产生各种数据,而这些数据都应该反哺系统本身。
比如传统专家的会诊意见以自由文本形式散落在病历系统中,我们应该将其结构化:
{
“病例ID”: “C202405001”,
“争议点”: “肺部结节性质判定”,
“张院士意见”: {
“观察维度”: [
“CT值变化曲线”,
“血管穿透特征”
],
“推理逻辑”: “虽体积<1cm但分叶征明显→建议PET-CT”,
“反共识说明”: “不同于指南但符合个人200例类似病例经验”
},
“知识标签”: [
“影像学特征”,
“诊断决策边界”
]
}
类似这种数据如果有个1000份,便会有巨大意义,李飞飞的1000个微调数据样本,其实也是精挑细选出来的。
再比如快递员配送日志分析:

# 数据库原始字段
delivery_log = {
“运单号”: “SF123456”,
“配送员”: “王师傅”,
“派件时间”: “2024-03-15 14:30”,
“包裹重量”: 3.2, # 公斤
“签收状态”: “已签收”
}备注文本 = “客户电话要求放菜鸟驿站,因家中老人住院需陪护”
# NLP解析结果
deep_info = {
“需求类型”: “变更收货地址”,
“原因分类”: “家庭突发事件”,
“客户画像标签”: [
“家有老人”,
“医疗相关”
]
}def 挖掘暗模式(配送记录):
# 关联外部数据源
天气数据 = 查询气象局API(配送记录[“时间”])
交通数据 = 获取交警事故通报(配送区域)
社区公告 = 爬取街道办公众号(日期)# 构建关联模型
if 天气数据[“降雨量”] > 50mm:
return “极端天气影响系数”
elif “道路施工” in 社区公告:
return “基础设施变更预警”
elif 配送延迟 and 交通数据[“事故数”]激增:
return “突发交通事件响应”# 输出示例 暗知识标签 = “03-15暴雨红色预警期间,绕行导致平均配送时长增加22分钟”
最终业务场景应用:
A[新订单] –> B{解析地址}
B –> C[历史配送记录]
C –> D[天气预警数据]
D –> E{生成策略}
E –>|晴天| F[常规路线]
E –>|暴雨| G[自动切换防涝路线]
E –>|社区施工| H[推送物业联络人电话]
这个案例通过层级化数据分析,结合天气、交通等外部因素,优化配送路径、提升客户体验和资源调度,能有效降低延误风险和提高服务效率。
总之,可以看出,所有的这些都是业务的规则理解后的实践,都是工程层面的优化,其本质是行业KnowHow。
最后是超出AI试图识别的其他处理,大家自己思考吧…
五、结语
AI项目,本质是一场对抗幻觉/输出增强的持久战。当前这场战役的主战场,正从“大模型军备竞赛”转向“行业KnowHow的数字化深潜”。
谁能将行业经验编码为可检索的知识图谱,比如将法律条文的微妙解释转化为可溯源的推理链条,谁就能在AI落地的“百团大战”中抢占先机。
RAG的技术其实很简单,其意义在于打开AI黑盒,让知识可以溯源。
比如当《劳动合同法》第三十条与字节跳动的OKR系统在同一向量空间出现,当德鲁克的管理智慧通过Think框架的推演不停的以分身的形式出现,其意义可不仅是技术迭代,他带来的可能是认知范式的升维!
随着RAG类技术在各行各业中的应用加深,我们正在见证从“泛化的模型”向“行业定制化模型”转型的过程。
从医疗领域的个性化诊疗方案,到金融领域的风险控制决策,再到法律行业中对条文的精准解读,AI在行业中的应用将不再是单一的信息处理工具,而是深入行业骨髓,成为决策支持的核心动力。
但技术的背后,依然是行业KnowHow的深度挖掘与沉淀。如何将行业的精髓转化为可持续发展的数字资产?如何构建起具备自我迭代能力的知识图谱,并确保其随着行业发展不断更新和完善?这些问题不仅挑战着技术的实现,也考验着行业参与者的眼光与耐心……
本文由人人都是产品经理作者【叶小钗】,微信公众号:【叶小钗】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。





- 目前还没评论,等你发挥!


