
 起点课堂会员权益
起点课堂会员权益OpenAI和Google同日地震级更新:人间一夜,AGI 临近!
今天凌晨2点,Google 和 OpenAI 在同一天发布了重大更新,引发了全球 AI 社区的强烈反响。Google 推出了 Gemini 2.5 Pro,一款能够进行复杂推理的混合大模型,而 OpenAI 则发布了 GPT-4o image generation,一款具有革命性的图像生成技术。这两个模型的发布不仅展示了两家公司在 AI 领域的最新成就,也标志着人类在通往通用人工智能(AGI)的道路上又迈出了重要一步。

谁是明日AI之星?
2024年,Google想夺回AI场子,但总是被OpenAI搅局。
每次一宣布某日要开发布会,OpenAI就会提前发布实力更强的产品。导致每次Google的AI产品发布会都特别尴尬。
2025年的Google学聪明了,发布AI产品不再大张旗鼓,而是偷偷滴直接上线。这次今晚又没任何预热,Google直接上线了Gemini 2.5 Pro模型。
这是一款会推理的混合大模型,实力超越GPT4.5和Grok3 ,最大特点是能够模仿人类快慢思考,这不是堪比GPT-5前奏吗?而它就这么不声不响上线了。
就在大家以为盛誉会属于Google时,OpenAI又在推特上宣布:
太平洋时间上午11点直播。
最终OpenAI发布了GPT-4o image generation,图像生成技术模型。
具有媲美人类摄影的出图质量,随心所欲的构图以及细节处理,超乎寻常的图文理解,以及任意的图中文字和LOGO生成的特性,也是在X上引起一片欢呼。
深夜2点多,鲸哥还没睡觉,看到朋友圈很多人发北京地震了。于是我写下如此朋友圈:
并没有感受到北京地震,但此刻,正在被Google和OpenAI天雷勾地火的竞争震撼。熟睡中的普罗大众,并不知道在这一夜中,在通往AGI 之路上,人类又跃进了一大步!
无心睡眠,向AGI前进一大步
Gemini 2.5炸裂出场,首个类人大模型
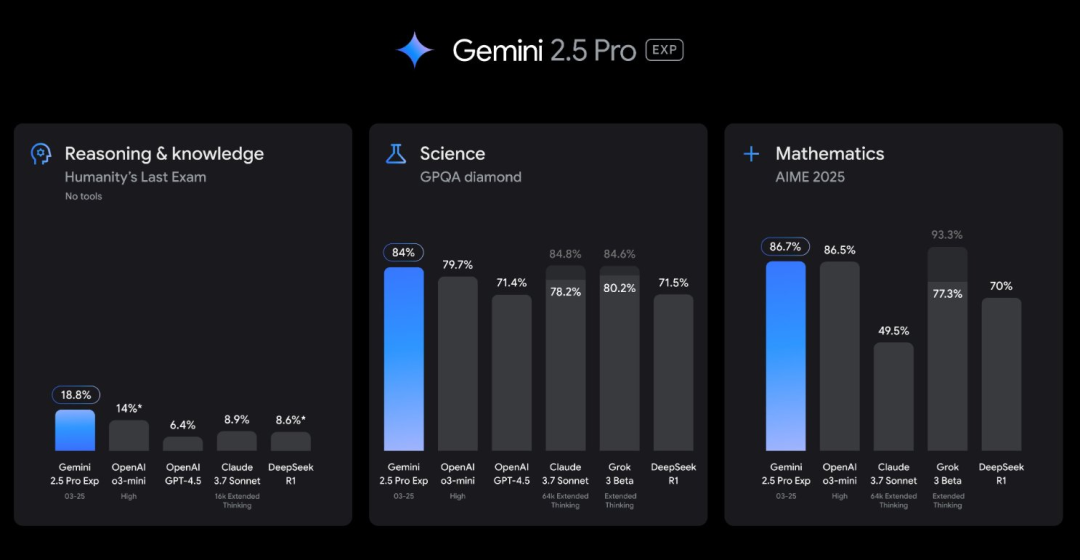
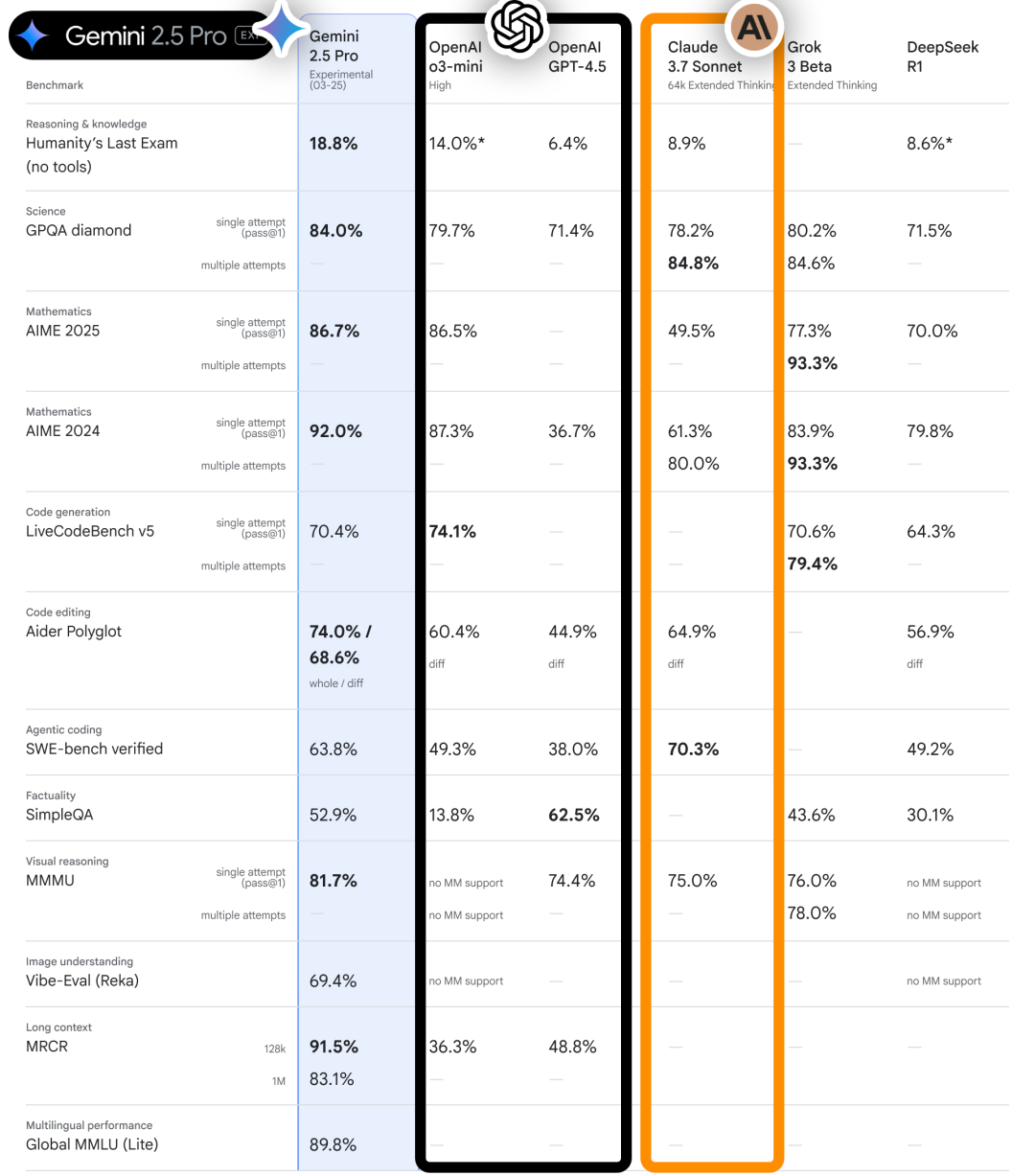
Gemini 2.5 Pro 实验版这次很炸裂,Gemini 2.5 号称可以处理更复杂的编程、科学和数学问题,并支持更具有情境感知能力的智能体。
这个新的“思考模型”在 LMArena 上以显著优势领先,并在数学、科学和编码基准测试中击败了 DeepSeek-R1、Grok 3 和 Claude 3.7。也几乎全面优于OPenAI家的两款模型—o3-mini和GPT4.5。
Gemini 2.5 Pro 现在在竞技排行榜上位居第一——这是有史以来最大的分数跳跃(比 Grok-3/GPT-4.5 高出 40 分)。
配备100 万 token 的上下文(即将推出 200 万),能够处理多模态数据,并且经过 vibe coding 认证,可以仅通过一个提示构建整个游戏。这是Gemini 2.5 的神奇之处。
更重要的是,当你向 Gemini 2.5 提问时,它会在回答之前通过思考进行推理,模仿人类处理思想的方式—逐步接近问题,细化潜在解决方案,并选择最佳方案。
鲸哥测试生成“近3年国内直播带货KOL的动态演示页面”,2.5 Pro飞速生成了相关代码。
这里就需要提到Google AI的亮眼好处,就是他可以调用之前的 Flash 2.0 就已经融合的Google系工具,比如分析YouTube视频、输出内容到Docs。这波代码演示,生成后也直接调用Colab演示。
以下是2.5 Pro 生成的主播热度动态演示效果,侧重是代码到生成的过程,至于内容准确性并没有体现,但整体还可以参考。毕竟2023年的小杨哥还没出事,还是直播带货领域的绝对一哥。
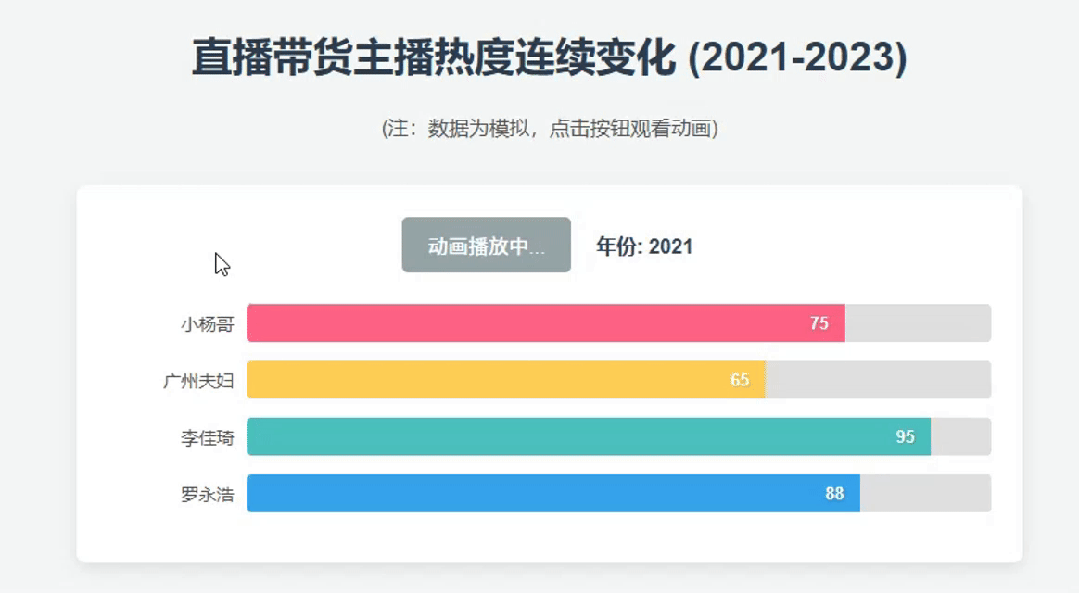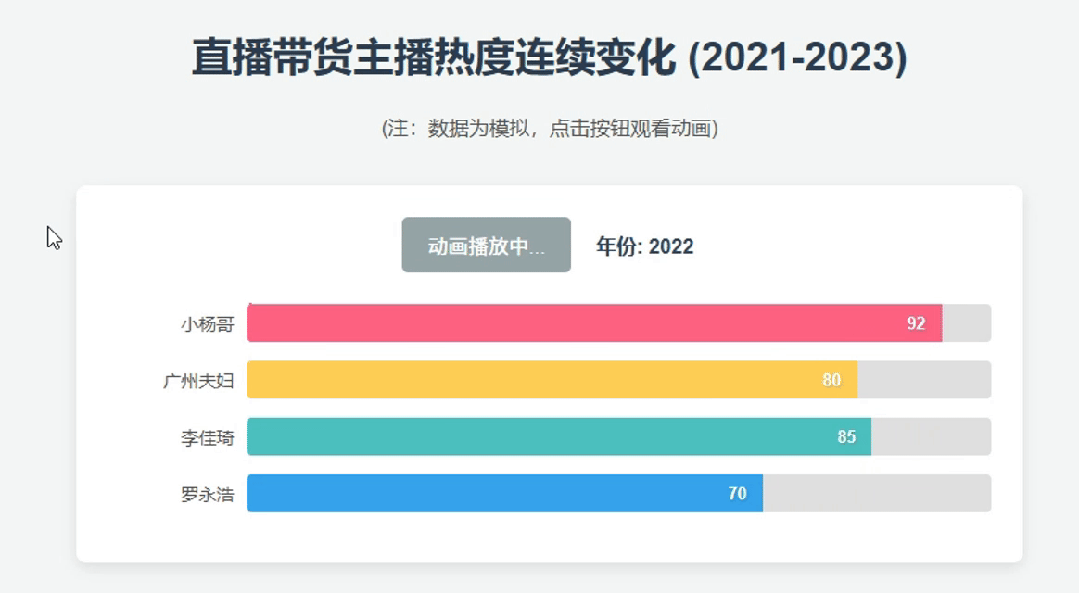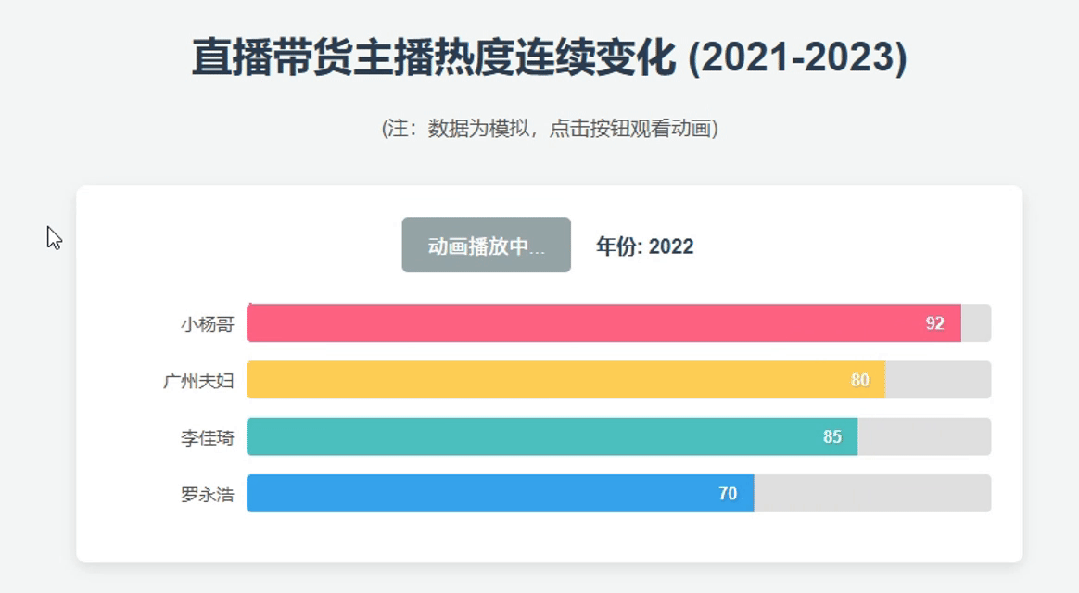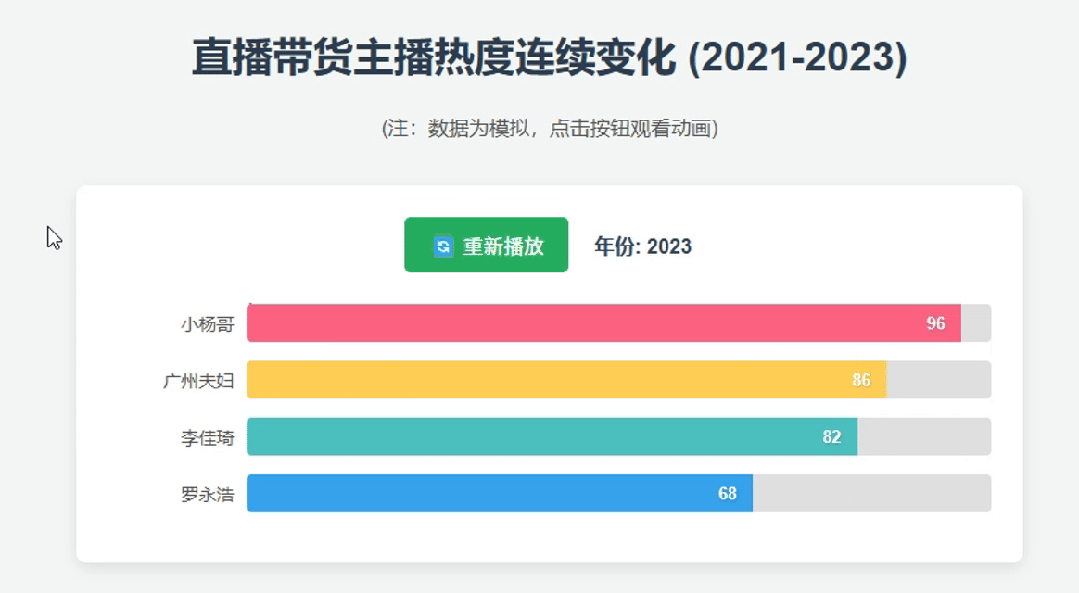
同时,我们测试了2.5 Pro的深度推理能力,要求其生成一份具身智能报告。这份报告不是那种很虚、不能用的内容,而是具有一定的可读性。

OpenAI杀死摄影师
在OpenAI展示的官方案例AI生图中,第一个图就足够震撼。

如果不明说,恐怕任何人都猜不到,这张图是AI生成的。毕竟反射画面和密密麻麻们的文字,都在说AI不可能这么神奇!但实际上,这就是4o生成的AI图片,OpenAI放出它的提示词如下。
这是用手机拍摄的玻璃白板的广角图像,拍摄地点是一间俯瞰海湾大桥的房间。视野中可以看到一位女士正在写字,她身穿一件印有大型 OpenAI 标志的 T 恤。笔迹看起来很自然,但有点凌乱,我们可以看到摄影师的倒影。
更神奇的是第二张图片转了人物朝向,生成的图像还是毫无破绽,也放出来震撼下大家。

如果你没有GPT Plus,那么用GPT免费的图片生成功能,其实已经能秒杀大部分文生图产品了。这是鲸哥直接用上面同款提示词生成的图片。

同时,鲸哥也用Google 2.0 Flash模型,同款提示词生成了同样的图。可以看到Google不太有审美,手部细节也崩了。
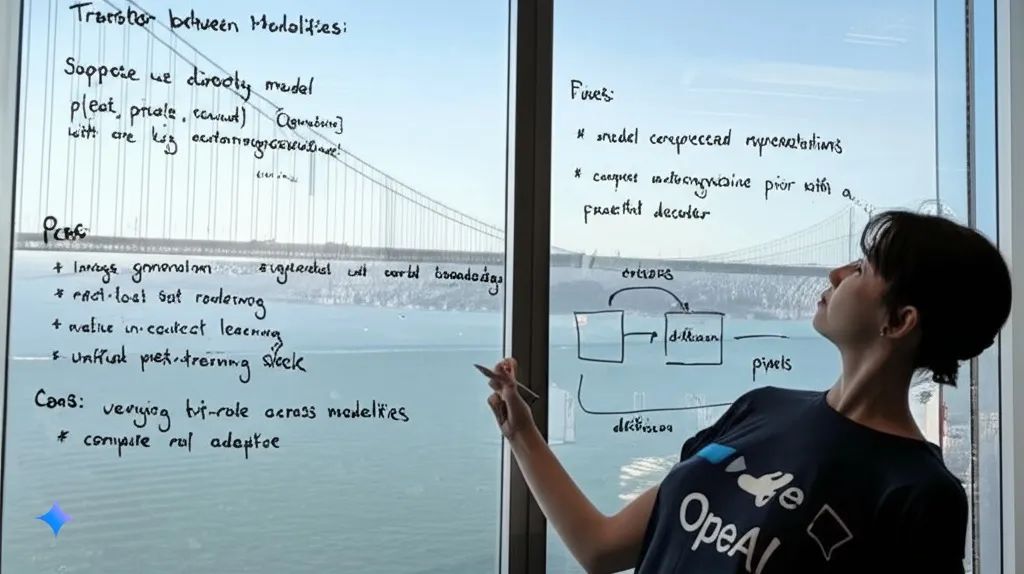
但OpenAI是不是为了官网案例特调,还需要以后全量上线模型,大家长期测试。
另外,4o的图像生成指令也足够强大,很多系统在处理约 5-8 个对象时会遇到困难,而 GPT‑4o 可以处理多达 10-20 个不同的对象。
下图就是4o在同一张图上,生成了16个物体,每个都准确生成了用户表达的内容,Amazing!

当然,对于类似Google 2.0 Flash的图片编辑能力,4o也是不在话下。可谓精准狙击了Google刚火出圈的图片编辑能力。

我们即将接近AGI了吗?
OpenAI同时宣布,从今天起,ChatGPT 和 Sora 的所有 Plus、Pro、Team 和 Free 用户都可以开始使用4o 图像功能。
山姆奥特曼则表示,“ChatGPT 中图像的新版本仍在推出中,所以如果今天没有获得很好的图像,请稍后再试 ”。应该预示着将继续整合多模态模型,以及产品端的融合。
有网友评论,4o图像功能超越了数百家AI图像公司。委实,甚至一些摄像和设计师等影像工作的饭碗,也将不保。
而对于Google来说,Gemini席卷的各种基准测试,在证明他的强大。
实际体验中,应该快速回答的问题很快回答,需要深度推理的问题也非常快速执行,一份报告、一份游戏生成基本都在60秒以内。
鲸哥惊艳于它的速度,更惊讶这种融合模型带来的体验。不会再出现问个简单问题,AI也去深度推理了。当然,2.5还不能生成图片,也许下一步3.0,就会带来这一能力。
Google这波拉响了硅谷的AI军备竞赛,此前Anthropic CEO称,还有更强的大模型没有放出,预计也会近期推出,防止Claude 3.7无法维持领先。
而OpenAI在GPT 4.5发布会中,山姆奥特曼都没有出现,也许意味着新的模型也会近期发布。
在这场OpenAI和Google对决的主角戏中,没想到最着急的是埃隆马斯克,他在X上发了多条内容,表明Grok是更好的那一个模型。
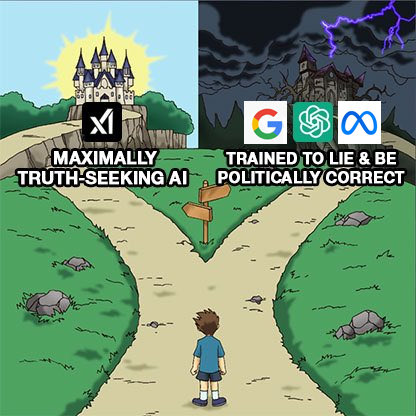
马斯克发布这张图时说道:这是很重要的区别,嘲讽其他家模型撒谎和追求政治正确,而Grok则追求真理。 马斯克的出现,为今晚这场竞争增添了趣味因素。
就在DeepSeek V3刚刚拿回的头牌中,Google和OpenAI展示了强大的竞争实力,而大家在你追我赶中,进一步拉近了AGI的梦想。
也许就在不远的某个夜晚中,AGI就会突然降临!
本文由人人都是产品经理作者【鲸选AI】,微信公众号:【鲸选AI】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图由作者提供






- 目前还没评论,等你发挥!


