
 起点课堂会员权益
起点课堂会员权益GPT-4o深度体验后发现,可能comfyUI工作流真不用学了
本文深入体验了GPT-4o图像生成模型,发现其在多种设计场景中表现出色,甚至可能让comfyUI工作流的学习变得不再必要。
上周我介绍了gemini生图模型,我觉得已经算是实用性很强了,但紧接着Open AI就卷起来了,也更新了一波图像生成模型,然后迅速在全网刷屏。那它的效果到底好不好用呢?是不是被吹的很厉害?我很好奇啊,所以周末赶紧深度实测了一波,先说结论:生成的图确实比Gemini的更好,但也并不完美。
我用GPT-4o深度测评了2天,当它真的可以指哪打哪后,我实在是不知道怎么形容。这篇文章我先跟大家总结10个最好用的使用示例,向你证明它确实是太好用了!
先说明一下,有些人可能会发现不充会员也能用GTP-4o,但出来的图效果完全不行。这是因为免费用户是用不了新的图像生成模型的,每天送的那5次用的其实是Dall-E模型,不是真正的新绘图模型。
充值后,选择更多中的“创建图片”用的才是全新的GTP-4o画图模型。
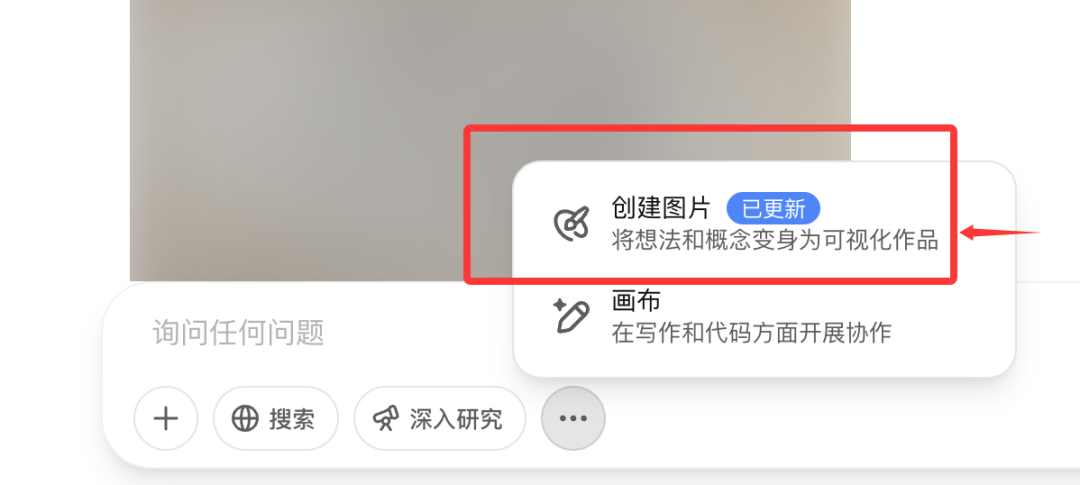
所以,我周末花费巨资,先是买了一张虚拟信用卡,然后又再充值了一个plus会员,很顺利的就用上了。注意咱们只需要花$20买plus会员就够了,不用去买那个$200每个月的,太浪费了。 从我使用的情况来看,plus会员就能一直生图,我用了2天,没出现限制的情况。
到这里估计就有朋友会问了,到底怎么充值啊?在chatGPT官网充值不支持国内信用卡,找淘宝代充不放心,跟别人合租使用又觉得不方便,办海外卡又没有途径,怎么办?
如何用上chatGPT-4o?
我自己试了一圈下来,最终总结还是在网上办一张虚拟信用卡最方便,又快又省心。我用的虚拟卡网址是 WildCard (https://bewildcard.com ) ,步骤很简单,注册会员然后开卡就行。在开卡的时候用我的邀请码:BJRGRQI4 ,可以减免1美元年费,不收月费,挺划算的。
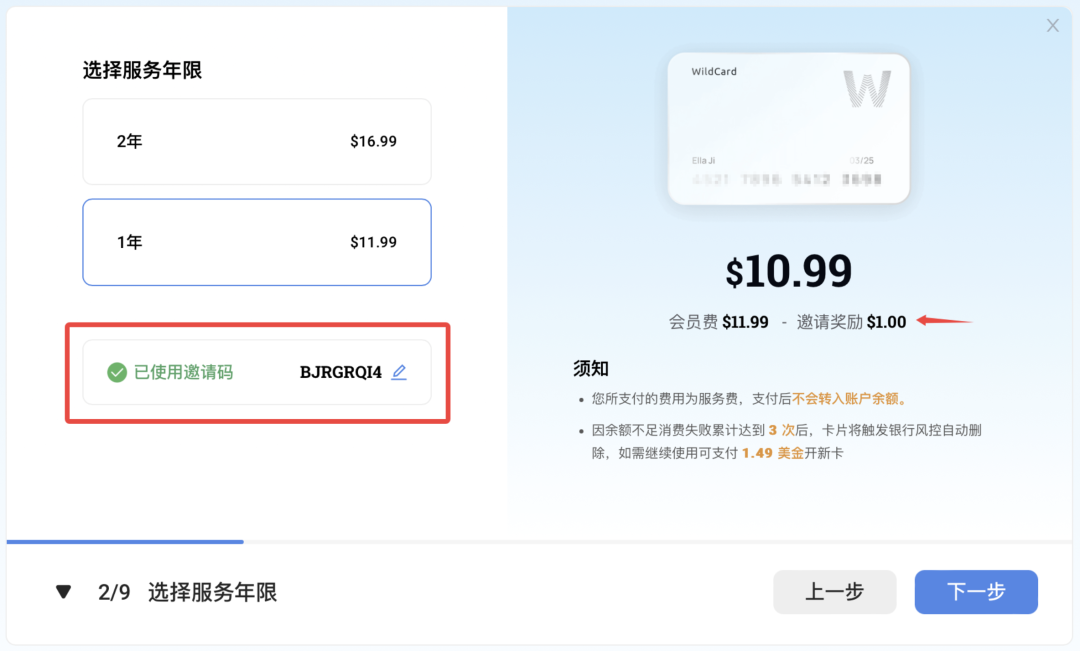
然后再往这张卡里充值20美元(用支付宝就能充),就可以买GPT-4o plus了,一个月20美元也可以用上最新的画图功能。
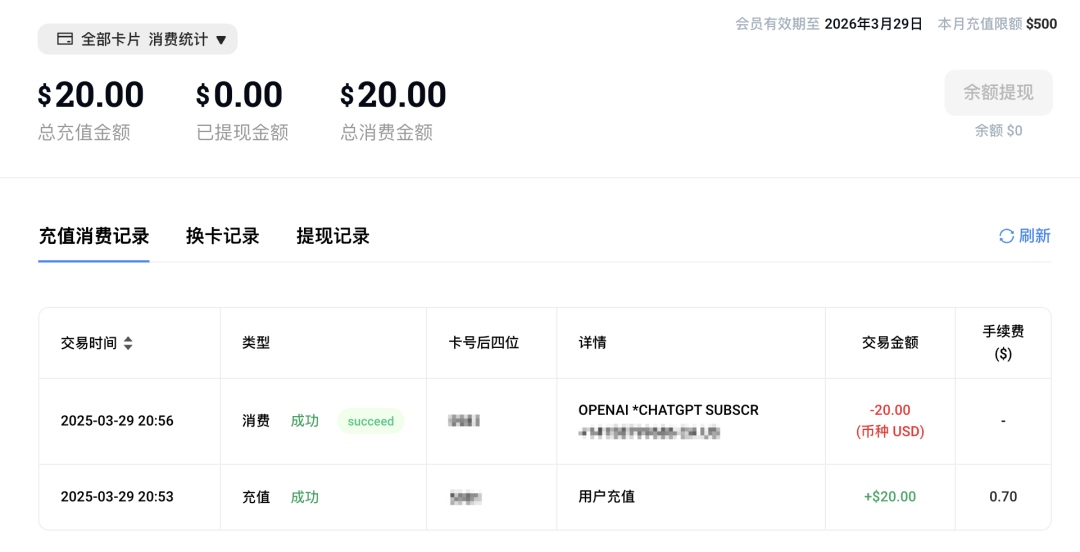
我自己的充值消费记录

好了,到这里相信大家已经解决了充值问题,也成了chatGPT尊贵的会员了,可以开始愉快的生图了。那有哪些有意思的应用场景可以让我们快速玩出花来呢?
我测试了以下10种场景,各个都非常惊艳!
注意:用的时候,记得先点更多,选择创建图片后再输出提示词,在提示词前面会有蓝色的“创建图片”,确保使用新模型且生效。
10个最常用的使用场景案例
1)生成组图
我测试的第一个生成图片,就是直接挑战高难度,让它在一个画面中同时生成一批带有对应特征的内容。这在目前其他AI生图能力上基本都超纲了,咱们直接上强度,看看它到底行不行?
提示词:一张正方形图片,包含一个4行4列的网格,网格上有16个图形,背景为白色,从左到右,从上到下。图形的风格请保持和参考图一致,列表如下:1、一块橙色的面包2、一个白色的星巴克杯子3、一个草莓蛋糕4、一瓶牛奶5、一瓶汽水6、一杯奶茶7、一张桌子8、便利店9、一只戴着帽子的狗10、一辆红色的小汽车11、一束玫瑰花12、一把黑色雨伞13、一双红色高跟鞋14、几个包子15、用草书写的“caiyun”16、办公楼

效果出来了,16个元素,位置、内容完全正确,风格和细节程度还做到了统一,非常棒!

接着,我想把它的风格按我提供的参考图重新设计下,毕竟在实际项目里,需要的风格比较确定,风格要做到一致性。
提示词:参考这张图,把上面的图风格改成和参考图一致

这是生成后的效果,开始有一些错误了。所以,我不满足,让它继续改。

有一些修正,但也还是会有问题,所以我想把它改回来,看看有没有修正回来的可能性,就和在实际工作中指导实习生的感觉。
提示词:再仔细对照最初的参考图和设计要求,颜色没有这么多,有几个地方的内容出错了,第2个,第7个,第10个

最终改了几轮后,有些改回来了,但又出了新的错误,我打算就此打住。

虽然它的效果还不是很完美,但总体上拿来稍微改改其实就能用了,已经给了我不小的惊喜,因为我也同时把这个提示词问了谷歌gemini,出来的图是这样的。

只能说,没有对比就没有伤害。
2)风格转换
GPT-4o有类似comfy UI中的ControlNet的功能,可以完全复刻参考图中的人物姿势,或根据线稿生成指定风格的图像。
给大家看下我当时测试的一个例子。

提示词:把上图中的画面转换为3D风格

转换后的图,已经非常像了有没有,这还学啥建模啊?质量也太高了。

眼尖的你可能会发现,生成后的图和原图稍微会有点区别,但这其实是官方刻意为之,不是做不到。因为当我要求它跟原图一样时,就违反规定了。

可能大家在操作的时候,经常会出现一个限制提示,说你违反了他们的规定。OpenAI 的内容政策特别严格地限制“高度拟真人物”的图像生成,尤其是当提示词中涉及“肖像还原”“外貌匹配”等字样时,哪怕是你自己的照片,模型出于防止误用(例如深度伪造)的政策,也有可能拒绝生成。
所以当出现人物相关需求时,可以用回comfyUI或Gemini,能解决问题。
此时,我已经不满足于把带人物的插画转成照片,我想把我觉得很美的插图壁纸也都转成照片了,那会是什么样的美景呢?咱们试试效果。
提示词:把这个场景变成一张写实照片

这是它生成出来的效果。

当我看到它生成出来的效果时,我真的是被惊艳到了,这效果还原的确实是有点太好了。
我在出这张图的时候已经是晚上12点多了,但我已经没了睡意,想赶紧多试试,这钱没白花呀。

我又找了另外一张我很喜欢的风景插图转换成了真实美景。

除了转成通用的卡通风格,还可以在提示词中加入指定的漫画家风格,使其更有对应风格的特点。比如我把上一篇文章中生成的美女图换成海贼王风格会是什么样的?

提示词:将参考图变成海贼王的画风

再转成乐高风格,提示词:将参考图变成乐高的画风

我还想把哪吒的3D图改为哆啦A梦的风格。
提示词:将参考图变成藤子不二雄风格

风格转换后,有点大雄的感觉啊,哈哈。

3)生成海报
它能根据自身的知识库,生成符合用户意图的配图。
比如我希望它帮我生成一张宇宙百科示意图。
提示词:我需要给百科全书画一张插图,请帮我用矢量插图风格生成一张不同类型的星球插图,需要有对应星球的名字,一句话介绍,背景为白色

这是生成出来的效果,质量很高啊,文字也都是对的。这在之前的生图模型中,其实很难做到,现在居然这么准确了。

英文没问题,那中文如何呢?我又试了下
提示词:把图中的英文改成中文

发现基本都能对上,不过也有一些小瑕疵,比如错别字,笔画粗细之类的细节还有提升空间,不过基本上稍微改改就能用了。
然后我又觉得太背景太干,适当加多一些细节。
提示词:背景上需要加多一些设计感,能用在书籍的宣传插图

背景加的还可以,还能继续微调,就像在指导一位设计实习生一般,没有脾气,不会疲劳,可以一直改,就问老板们喜不喜欢?设计师们怕不怕!4)虚拟试穿
GPT-4o能把提供的衣服、模特素材,直接合成想要的画面,完成电商里面经常用到的试穿效果图。这个能力其实在comfyUI和Gemini中都能做到,但我发现GPT-4o出来的效果似乎会更好。

提示词:把裤子,帽子,衣服穿到模特身上,并且走在街道上

出来的效果非常好,除了帽子logo那稍微有点瑕疵,其他几乎完全被复刻了过来。瞬间感觉用comfyUI搭建的工作流已经失去了意义。

5)动漫设计
它可以一次性上传多个角色设定,然后要求GPT-4o转换视角和场景,生成全新的漫画设定,同时保留漫画角色特征。

提示词:让鸣人和路飞这2个角色在中忍考试的场景中激烈的战斗,画面中有相应角色的技能特效

直接这样会提示违规,猜测可能是有版权的问题。按它提示继续操作就可以了,依然能保持参考图的特征,绕过限制。

但在出来的图片这里,手臂是有点问题的,我们也可以用它的局部修改功能。怎么操作呢?
点击图片放大,然后点右上角有一个编辑图标

点完之后,可以看到一只画笔,然后把想修改的地方圈出来,写上提示词就可以了。
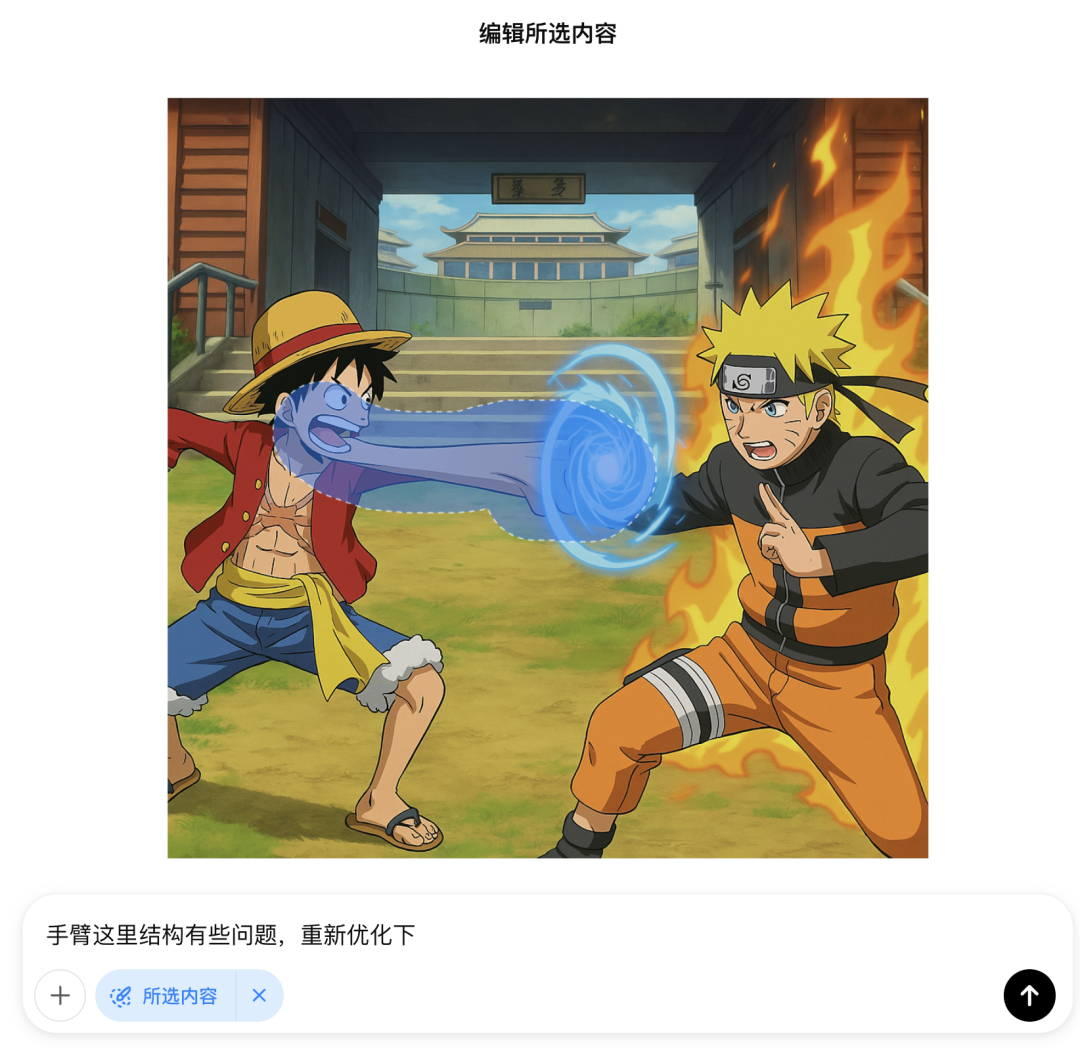
这是优化之后的,能看到还是有一些瑕疵,还可以继续优化,我这里就不演示了。

6)改图标风格
在UI 领域,也可以让它根据一种风格生成对应的图标。咱们设计师经常找参考图,做情绪版,不就是为了做好风格设计吗?这下GPT-4o也能搞了,而且还挺精细。
比如让它按找到的设计参考图,重新设计图标。
提示词:按照第1个风格图标重新设计第2张图中的图标

最后生成的效果,虽然图片还存在一定的瑕疵,比如透视关系不大对,但这个效果还是非常不错的。

一整套图标时也可以出效果
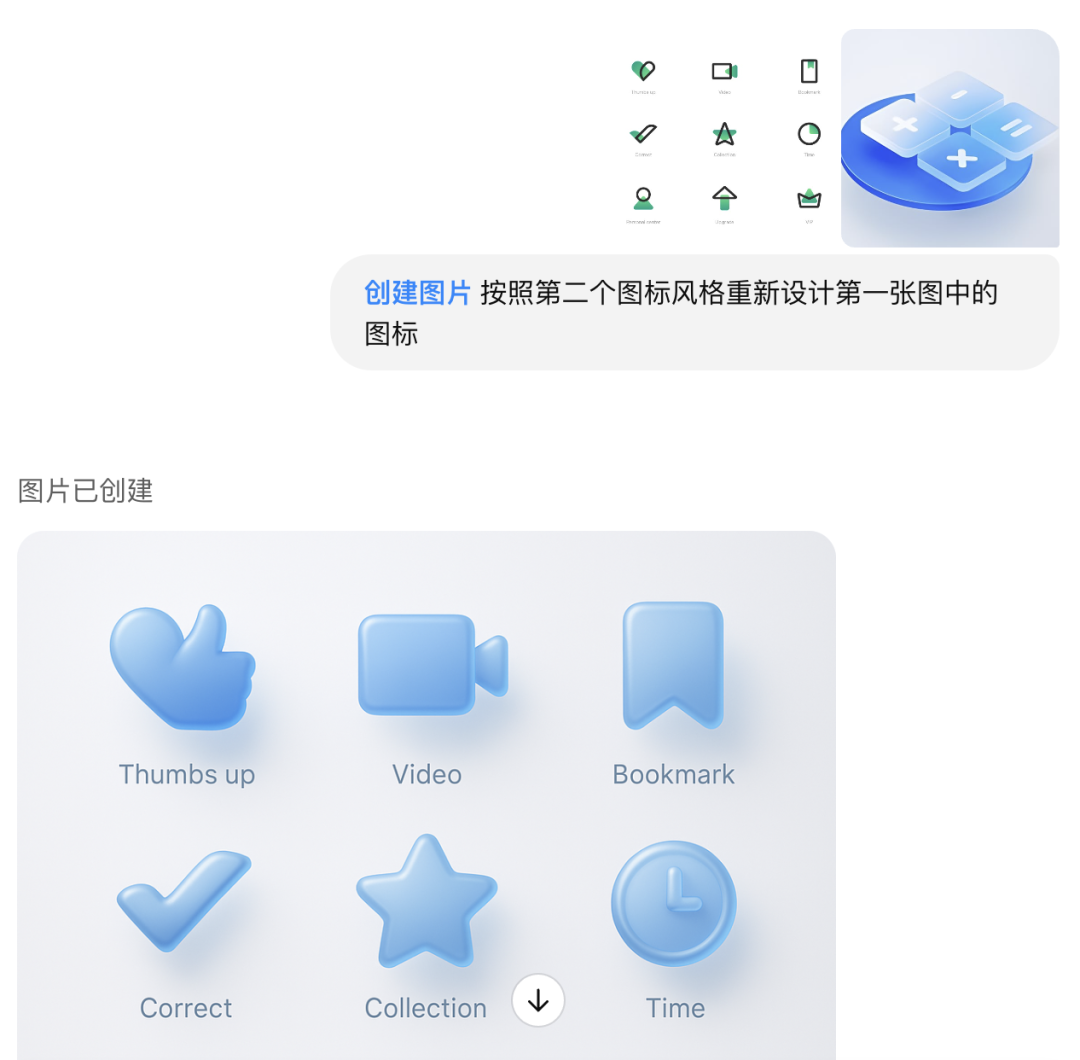
最后的效果也还不错,除了第一个图标有瑕疵。

7)图像提取
GPT-4o可以从图像中抠图,它还不是一种简单的抠图,而是扣出画面内容,然后帮你做高清修复。
比如我找到了这张图,水中的海豚其实已经很不清晰了,整个图片也不到700px,要想抠出来完整细节挺不容易的。

提示词:帮我把画面中的海豚提取出来
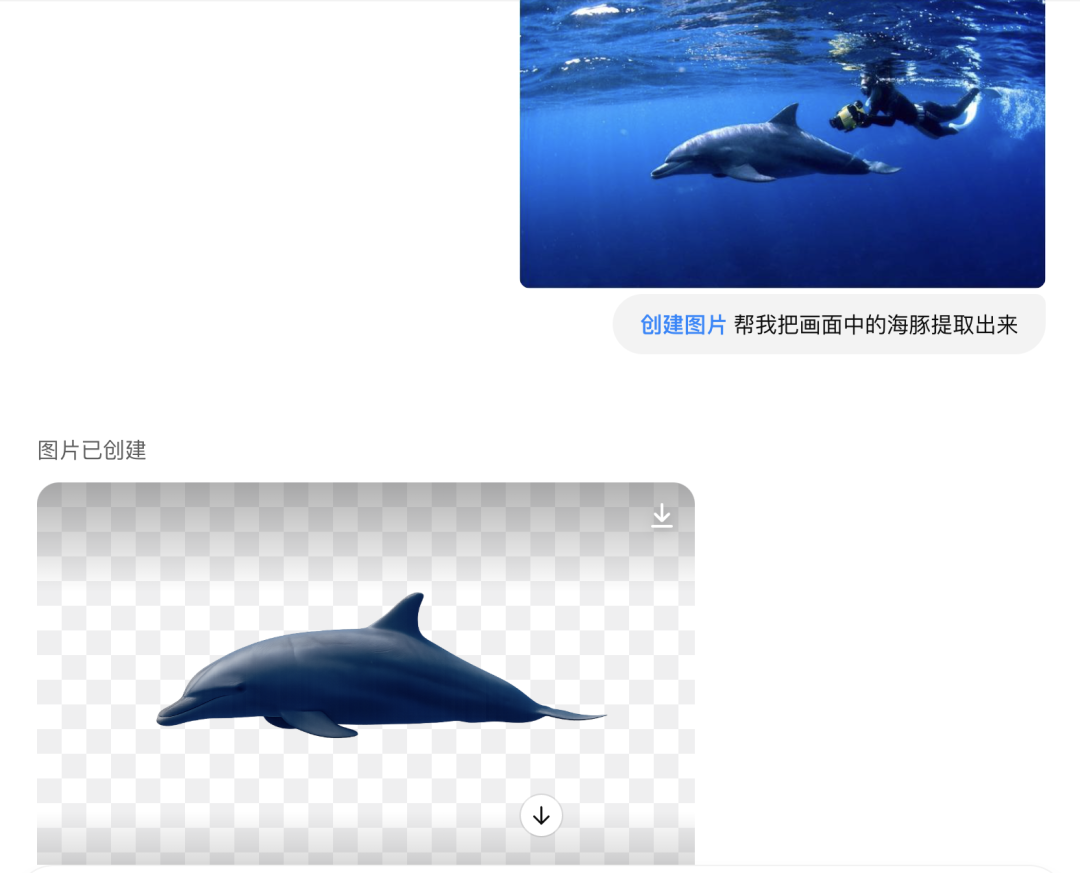
看到了吗?它不是简单的抠图,而是把需要抠图的海豚完整的抠出,而且还自带了修复,并且还给了一张透明格式的图片!
 8)AI找图
8)AI找图
它不仅能按提示词出图,还能根据它自己的知识库,根据我的一句话描述,直接把我想要的图“找”出来。
提示词:找一张火影里面的小樱的图
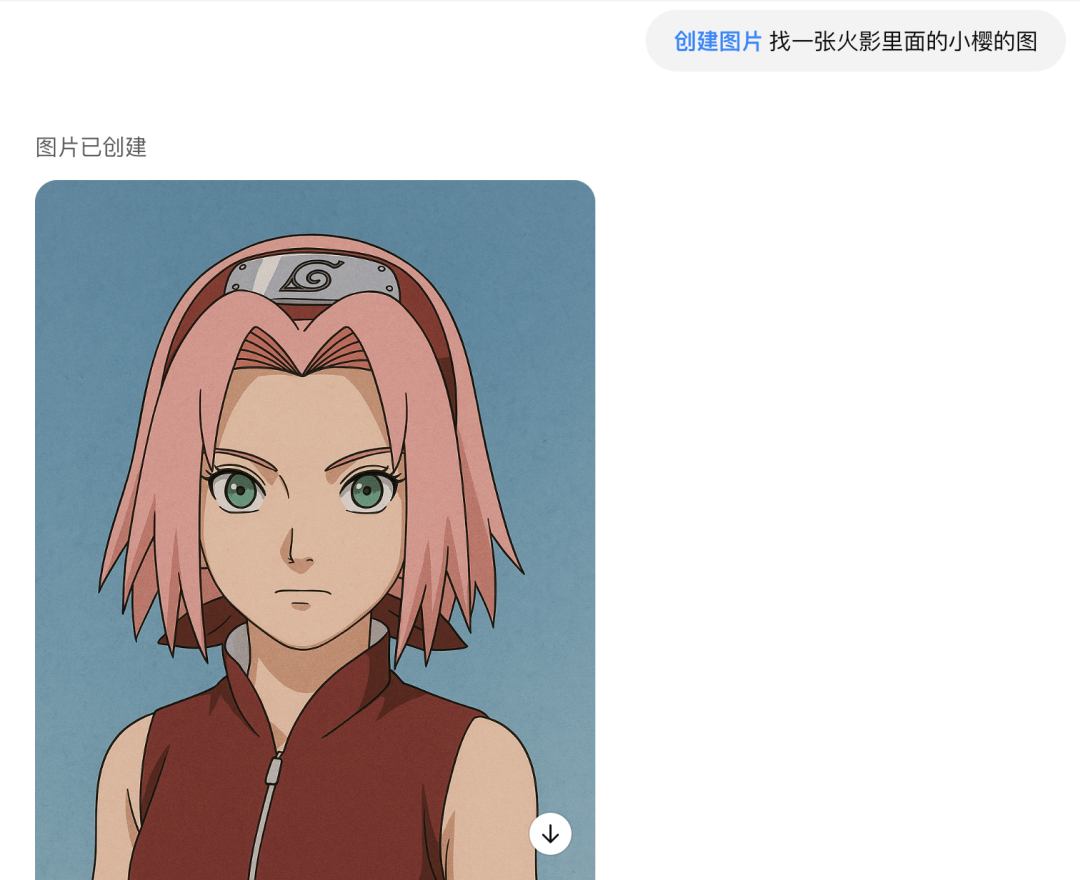
这是帮我找出来的图,质量非常高,几乎没有啥瑕疵。

9)老旧照片上色
这个功能其实其他AI也有,只是我觉得GPT-4o出来的图更好,尤其是在那些细节还原度上,甚至景深那些都能比较好的复原。
比如我从网上找到这样一张照片,我觉得挺有质感的,咱们来实验一波。

提示词:为这个老照片变为彩色

这是修复后的照片,细节还原度拉满。

10)一键修图
它的修图能力,感觉比PS还要强,一键就把画面中的人物全干没了。

提示词:修改图片,要求移除画面中所有人,完全保留画面中的其他实景细节

这是修完之后的效果,除了细微处还有点瑕疵外,乍一看,几乎挑不出毛病。

好了,以上就是我自己在测试中觉得最实用的10个使用场景,它还有更多其他用法等待大家去发现,留言区期待你的发现和分享。
当前这个模型也不是完美的,它也有一些做的没那么好的地方。比如对中文的生成还没那么好,对一些细节做迁移的时候会有一些瑕疵,限制比较多,出图速度上也比较慢,而且动不动还限速,挺麻烦的,然后它在一些出图的美感上也有点不太足,和Midjourney稍差一些。但我觉得,这些问题很快就会被迭代解决,毕竟AI领域的更新节奏实在是太快了。
从各家大模型卷的方向来看,都是先保实用性,再提升美感。这和咱们平时做产品的思路一样,先保证可用,再做到好看。
从天马行空的惊喜到精准可控的生成,这就是这次升级中最核心的升级内容。
最后说点心里话。
从最初Midjourney刚出的时候,就有一种声音在说设计师要下岗了,不再需要设计师了。但后面这种声音也随着实际项目中的应用情况而逐渐回归理性,设计师还是没法被取代。而到近期GPT-4o出来时,大家更能感觉到工具的好用,设计师下岗论似乎更加强烈。
但我觉得此时如果真的被取代的不是设计师,而是只会画图的美工,进而会进一步拉大初级和资深设计师之间的鸿沟。画图在实际项目中,只是设计师日程工作中的一部分,项目前期的需求沟通、概念策划、后期与开发的对接、还原走查、用户反馈后的分析、策略调整都是工作,而这个链路暂时都需要设计师的介入,没法完全实现AI代办。
虽然我觉得设计师完全被取代不大可能,但我隐约看到一种趋势:距离直接画图越近的设计师,越容易被取代。而在项目中做设计项目管理,做概念策划的人,负责节点较多的人会比较难被取代。原因是流程多,组织团队复杂,需要人的介入就更多,越不容易被AI自动化。
所以,苦心钻研技术可能并不会有出路,关键还是策略的思考。如果你想依赖学习到的技术做为壁垒,当你苦心学习了很多年的各种技能,结果被给AI说的一句话就打败了,想想还是有点悲哀的吧。
本文由人人都是产品经理作者【彩云sky】,微信公众号:【彩云译设计】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。









AI当然会在持续的发展,所以以前未具备的能力,现在会有将来也会有新的能力