
 起点课堂会员权益
起点课堂会员权益Physical Intelligence 创始人:人形机器人被高估了
在人工智能和机器人技术飞速发展的今天,人形机器人成为了科技界的热门话题。然而,Physical Intelligence(PI)的创始人Chelsea Finn却认为,人形机器人目前被高估了。本文通过与Chelsea Finn的对话,深入探讨了机器人领域的最新进展、泛化能力的重要性、数据多样性的关键作用,以及PI公司的发展方向。

AI Robotics 是我们长期关注的赛道之一,通用机器人是 AGI 从数字世界走向物理世界的重要路径,而 robot foundation model 要做的就是给机器人构建一个大脑,从软件角度实现机器人的通用能力。在 AI robotcis 的主题下,Physical Intelligence 是我们最为关注的公司之一。
PI 被视为是机器人领域的 OpenAI,是所有机器人公司中 research 水平和人才密度最高的团队,团队的核心目标是开发通用机器人的 foundation model,今年 2 月,PI 开源了通用模型 π0 的代码和权重,2 月 26 日,PI 又推出了 Hi Robot,能够将 π0 等VLA 模型纳入一个分层推理过程。
本篇内容是我们对 PI 核心创始人 Chelsea Finn 最新观点的编译理解。围绕 π0 和 Hi Robot,Chelsea Finn 分享了机器人是如何实现泛化?她认为,数据人就是关键中的关键,并且一定要获取更多样化的机器人数据,而不仅仅只关注数据的质量,最终的目标是扩大真实机器人数据的规模。
同时,Chelsea Finn 也理性地认为,虽然人形机器人这个形态很酷,但当下,人形机器人被高估了。要实现机器人领域的 AGI,物理智能才是核心,未来一定会有各种各样的机器人形态,PI 内部将机器人的 AGI 时刻定义为“寒武纪大爆发”。
💡 目录 💡
01 Chelsea Finn 机器研究的开端
02 PI 的研究进展和发展03 机器人怎么实现 AGI?
04 Hi Robot
05 机器人需要哪些感官?
06 自动驾驶 VS 机器人领域
07 对训练数据和硬件的看法
01. Chelsea Finn 是如何进入机器人领域的?
Elad:你是如何进入机器人领域的,最初是什么吸引了你?
Chelsea Finn:一开始,我对机器人可能带来的影响感到非常兴奋。与此同时,我也对发展感知和智能的问题非常着迷,机器人体现了这一切。有时候这个领域涉及到一些有趣的数学问题,能让大脑保持活跃,不断思考。这些都是从事这个领域很有趣的地方。
我真正开始认真研究机器人大概是在 10 多年前,当时我刚开始在伯克利攻读博士。我们当时在做神经网络控制,试图训练神经网络,使得图像像素可以直接映射到机器人手臂的扭矩。在当时,这种方法还不太流行。但如今,这个方向已经取得了巨大进展,在机器人领域受到了更多认可,也让越来越多的人感到兴奋。
从那个时候开始,我就很清楚,我们可以训练机器人完成一些很酷的任务。但真正的挑战在于,如何让机器人在不同环境、面对不同物体时都能完成这些任务。10 年前,我们训练机器人去拧紧瓶盖、用铲子把物体放进碗里、精准地插入物体,或者把衣架挂到衣架杆上。这些任务本身已经很酷了,但让机器人在不同环境、面对不同物体时都能执行这些任务,才是真正的难点。
因此,我一直在思考如何构建更广泛的数据集,如何基于这些数据集进行训练,以及有哪些不同的学习方法,比如强化学习、视频预测、模仿学习等。我在博士期间和加入斯坦福之前,曾在 Google Brain 工作了一段时间。后来,我成为了斯坦福大学的教授,在那里建立了自己的实验室,并在这些方向上做了大量研究。
大约一年前,我与合伙人们共同创立了 Physical Intelligence,希望能够真正实现我们的愿景。我为此离开了斯坦福大学,但我仍然在斯坦福指导学生。

02.PI 的研究进展和发展路径:泛化和开源
Elad:Physical Intelligence 目前的研究方向是什么?
Chelsea Finn:我们的目标是构建一个大型神经网络模型,最终让它能够控制任何机器人,在任何场景下执行任何任务。
我们的愿景与传统机器人研究有很大不同。过去,机器人研究往往是深入专注于某一个特定的应用场景,比如开发一个机器人来执行单一任务。然而,这种方法往往会让研究局限在特定应用里,一旦机器人被优化到擅长某个特定任务,就很难再扩展到其他任务。
我们想要解决的是更广泛的物理智能问题,并且我们是以长期视角来看待这个问题。我们特别关注泛化能力和通用机器人。
与其他机器人公司不同,我们认为充分利用所有可能的数据是非常重要的。这不仅限于某一种特定的机器人数据,而是要汇总来自各种不同机器人平台的数据,比如六轴机器人、七轴机器人、单臂机器人、双臂机器人等。已经有很多证据表明,不同机器人之间可以共享大量丰富的信息,能让数据的价值最大化。

在这种情况下,如果对机器人硬件进行迭代升级,就不需要完全舍弃旧版本的数据。在过去,有一个痛点在于当机器人升级换代时,原本的策略就无法适配,需要重新训练模型,这个过程既费时又费力。而 Physical Intelligence 的目标是打造通用机器人,并开发 foundation models,让它们成为下一代机器人在现实世界中的智能驱动力。
Elad:这在某种程度上与 LLM 有些相似。在 LLM,深度学习、Transformer 架构以及规模化训练的结合,已经证明了可以实现真正的通用性,并能够在不同领域之间进行不同形式的迁移。你们所采用的架构或方法具体是什么?
Chelsea Finn:一开始,我们主要是想扩展数据收集规模。与语言领域不同的是,机器人领域并没有类似维基百科或者涵盖机器人运动的“互联网”可供利用。因此,我们对在真实环境下收集真实机器人的数据感到非常兴奋。这种真实数据一直以来都是推动机器学习进步的重要因素。而一个关键点是,我们需要自己去收集这些数据。这意味着我们需要在物理世界中进行机器人操作。虽然我们也在探索其他扩展数据的方法,但核心仍然是扩大真实机器人数据的规模。
去年十月底,我们发布了一些初步成果,展示了我们在数据扩展方面的努力,以及如何让机器人学习非常复杂的任务,比如折叠衣物、清理桌面、搭建纸板箱等。
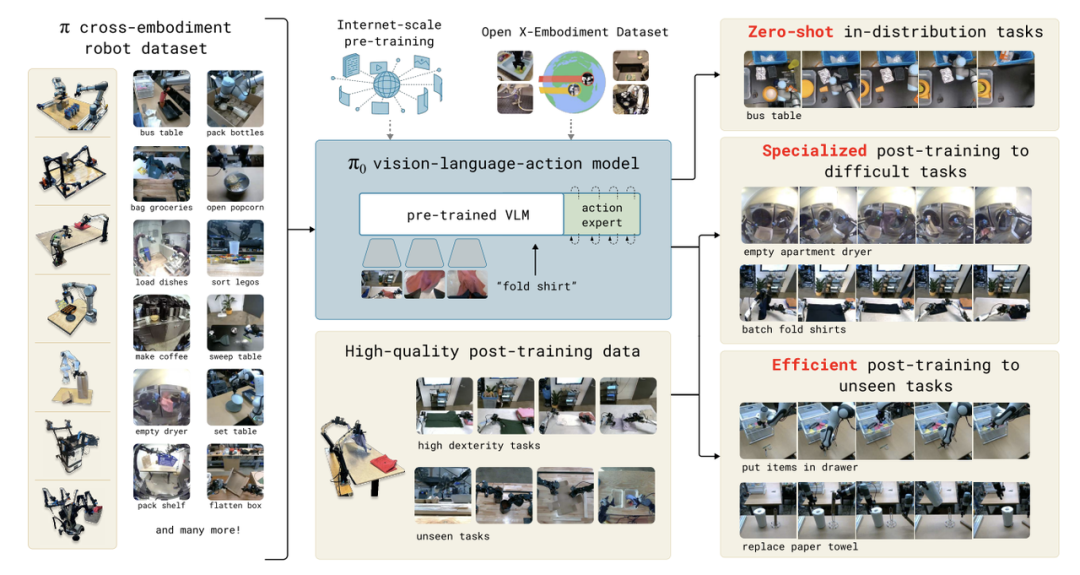

目前,我们思考的重点是如何让机器人能够进行语言交互,并在不同环境中具备泛化能力。在去年十月的演示中,我们展示的机器人是在一个特定的环境中训练的,数据也是来自那个环境。虽然它能够在一定程度上泛化,例如折叠它以前从未见过的短裤,但这种泛化能力仍然非常有限。
此外,用户也无法与它进行交互,除了训练数据中已有的一些基本指令外,无法让它执行新的任务。因此,我们目前的一个重要目标是让机器人能够处理更多样化的指令,并适应更多不同的环境。
在架构方面,我们采用了 Transformer,并且使用了 pre training 模型,特别是预训练的 Vision-Language Model,这使我们能够利用互联网中丰富的信息。几年前,我们有一个研究结果表明,如果利用 Vision-Language Model,机器人可以执行训练数据中从未包含过的任务,但这些任务涉及的概念是存在于互联网的数据中。
一个著名的例子是,你可以给机器人展示 Taylor Swift 的照片。虽然机器人从未在现实中“见过” Taylor Swift,但由于互联网中有大量 Taylor Swift 的图片,它可以利用这些信息以及 pre training 模型的权重来实现知识迁移,让机器人执行相应的任务。
因此,我们并不是从零开始,而是依托这些已有的知识进行提升,这对整个研究有很大的帮助。
Elad:实现泛化的关键是什么?
Chelsea Finn:我认为最重要的一点是获取更多样化的机器人数据。比如,在去年十月底的那个发布中,我们的数据是在三座建筑中收集的。而相比之下,互联网上的语言模型和视觉模型所依赖的数据来源要广泛得多,因为网络上的图片是由许多人拍摄的,文本是由许多人撰写的。因此,我们需要在更多不同的环境中采集数据,涉及更多物体、更多任务。
扩展数据的多样性,而不仅仅是数据的数量,这是至关重要的。我们目前的重点工作之一就是让我们的机器人进入更多不同的场景,并在这些环境中采集数据。与此同时,这也会带来一个非常有价值的副产品——我们可以学习到如何让机器人在各种不同环境中真正运行并发挥作用。如果我们想要让机器人在现实世界中真正使用,这一点至关重要。
除此之外,我们也在探索其他方向,比如利用人类的视频数据、从网络中获取数据、使用 pre training 模型,并思考推理能力的应用,尽管目前更多是一些基础的推理。
• 比如把一件脏衣服放进洗衣篮,机器人需要能够识别衣服和洗衣篮在哪里,以及完成这个任务需要执行的操作。
• 比如要制作一个三明治,而用户对腌黄瓜过敏,那么机器人应该能够推理出不应该在三明治里放腌黄瓜。
总的来说,最重要的仍然是获取更丰富多样的机器人数据。
Elad:开源会是 PI 的长期发展路径吗?
Chelsea Finn:我们一直非常开放,开源是我们有意识的选择。我们不仅开源了一些模型的权重,还发布了技术细节和论文,甚至还与硬件公司合作,向它们提供机器人设计。
首先,我们认为这个领域还处于起步阶段,这些模型在未来 1-3 年内会变得更加强大,机器人也会变得更加强大。我们希望支持研究发展,支持社区,支持机器人技术,这样当我们最终开发出通用模型技术时,整个世界会更好地为它做好准备,届时会有更强大的机器人能够利用这些模型,也会有更多具备相关专业知识的人理解如何使用这些模型。
其次,我们拥有一支非常优秀的研究人员和工程师团队,而顶尖的研究人员和工程师更希望加入开放的公司,尤其是研究人员,他们希望自己的研究成果能够得到认可,并且能够分享和讨论他们的想法。吸引最优秀的研究人员和工程师是解决机器人问题的关键。
最后,选择开源的最大风险在于可能无法成功。我并不担心竞争对手,我更担心的是最终没有人能解决机器人问题。
机器人技术非常困难,过去也有很多失败的案例。与在图像中识别物体不同,机器人操作几乎没有容错空间。比如,机器人与物体的接触距离非常小的时候,一点点差距可能就会对结果产生巨大影响,会决定机器人能否成功操作这个物体。收集数据的挑战也是如此,任何涉及硬件的事情都很困难。
03.机器人怎么实现 AGI?
Elad:物理智能会在哪些领域产生最直接的影响,这些新方法什么时候能够真正实现突破?
Chelsea Finn:Physical Intelligence 非常关注机器人的长期问题,而不是某一个特定的应用,专注于单一应用可能会带来很多失败的风险。我不确定物理智能的第一个应用场景会在哪里。
在机器学习领域,有很多成功的应用,比如推荐系统、语言模型、图像检测等,模型的输出最终会被人类使用,人类可以进行检验,因为人类通常是擅长检验的。很多机器人非常自然的应用场景是机器人独立自主地做某些事情,而不是接收人类给出的指令,比如给定手臂的目标位置,之后人类再进行检验。因此,我们需要思考一些新的方法来应对允许错误的场景,或者是人类和机器人可以合作的场景。
这是一个大挑战。Physical Intelligence 一直在尝试部署这些机器人技术,我们做的语言交互工作其实就是受到这个挑战的推动。人类能够提供输入是非常重要的,比如人类希望机器人如何表现、希望机器人做什么、希望机器人如何帮助完成某件事。
Elad:如何看待人形机器人与非人形机器人之间的差异?
Chelsea Finn:人形机器人真的很酷,但有些被高估了。从实际角度来看,我们现在在数据方面确实有瓶颈。一些人认为人形机器人可能更容易收集数据,因为它们符合人类的形态,可能会更容易模仿人类。但如果你曾经尝试过远程操作人形机器人,你会发现操作人形机器人比操作一个静态操控器或者一个带轮子的移动操控器要困难得多。
优化数据收集非常重要,如果能达到一个超过需求的数据量程度,那么剩下的就只是研究、计算和评估的问题了。我们正在优化这个方向,这也是我们目前优化的目标之一。我们使用便宜的机器人,使用我们能够非常轻松地开发远程操作接口的机器人,这样就可以快速进行远程操作,并收集多样化的大量数据。
Elad:怎么看待具身智能模型的开发与非具身智能模型开发之间的区别?
Chelsea Finn:人们低估了运动控制中所包含的智能。我们能够像现在这样使用双手,是经过了多年的进化。而有许多动物,即便经历了如此长时间的进化,也无法做到这一点。因此,能够做一些非常基础的事情,比如做一碗麦片或者倒一杯水,实际上蕴含着极大的复杂性和智能。所以,从某种程度上来说,具身智能或物理智能是智能的核心。
Elad:在过去两三年里,哪些研究促使人们觉得机器人到了一个转折点?
Chelsea Finn:有几个因素让我们觉得这个领域的进展比之前更快了。
第一个是 SayCan,可以利用语言模型对高层部分进行规划,再与低层模型结合,以便让机器人完成长时间的任务。
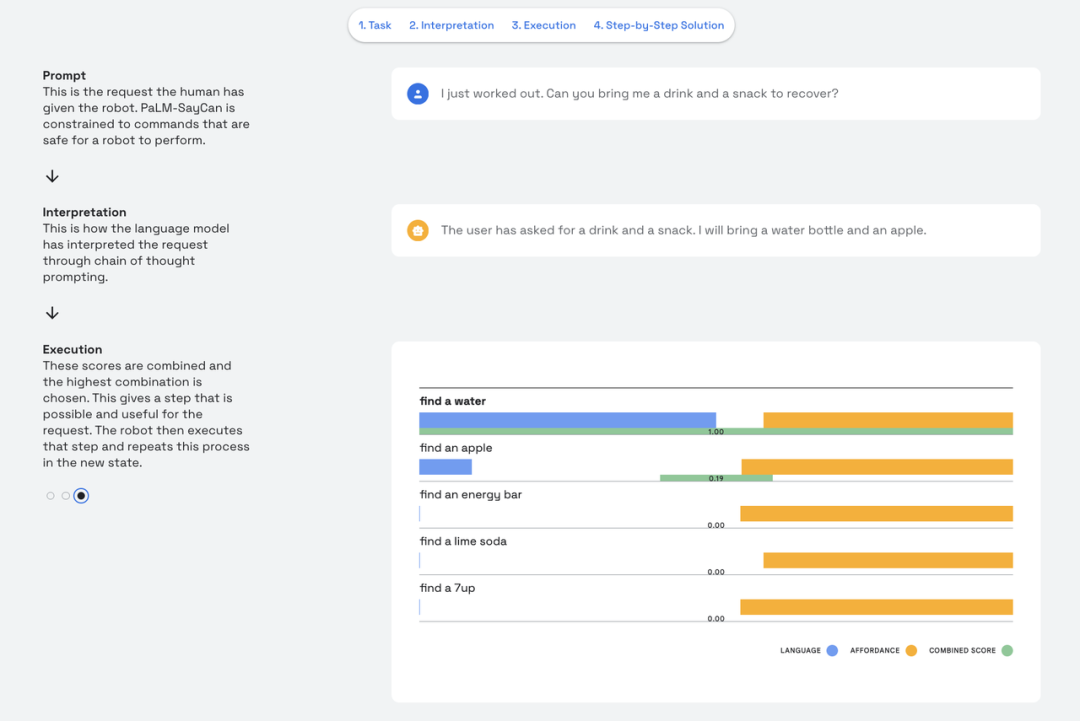
第二个是 RG2,能够实现前文所说的 Taylor Swift 的例子,RG2 能够将大量的网页数据集成进来,从而提高机器人的泛化能力。
第三个是 RT-X,能够跨不同的机器人形态训练模型。重要的是,我们可以将各个研究实验室的数据整合到一个通用格式,并在此基础上进行训练。
在训练时,我们发现可以将一个模型的 checkpoint 发送到另一个实验室,即使距离很远,那个实验室的研究生也可以在机器人上运行这个 checkpoint,且大多数情况下,结果比他们自己在实验室里单独迭代出的模型要好。这是一个重要的标志,说明这些技术开始真正起作用,通过汇总来自不同机器人的数据,的确能够带来益处。
checkpoint 是指在模型训练过程中保存模型当前状态的快照,通常包含模型的权重、优化器的状态以及其他训练相关的参数。
还有 Aloha 和 Mobile ALOHA,实现了远程操作来训练模型,使机器人完成相对复杂的精巧操作任务。我们还做了一个后续的关于系鞋带的项目。
当我们启动 PI 时,也是对其他人发出了信号——如果专家们真的愿意在这个领域下注,那也许真的会有一些变化。
04.Hi Robot 是什么?
Elad:PI 最近推出了分层交互机器人,即 Hi Robot,这是怎么考虑的?
Chelsea Finn:我们试图关注两个方面。第一,如果一个任务需要较长时间才能完成,即可能需要花费几分钟,那么仅依赖单一策略,即从图像直接输出动作,可能并不高效。比如在制作三明治的过程中,如果策略只是逐步输出下一个运动指令,而不考虑整个任务的整体规划,那么效果可能不如通过真正推理和规划来完成所有步骤来得更好。
第二,我们希望机器人不仅仅能执行基本指令,比如折叠衣服、拿起杯子,而是能够与人类互动。例如人类可以告诉机器人自己是一个素食主义者,要求机器人做一个三明治,不要加泡菜,或者中途要求机器人暂停放番茄。处理这些类型的提示、进行现场调整等,和仅仅执行基本指令之间有很大的差距。
因此,我们开发了一个系统,有一个模型来接收提示并进行推理,能够输出机器人应该执行的下一步,比如告诉机器人下一步去“拿起番茄”,然后有一个低层次的模型,将“拿起番茄”作为输入,输出下一个半秒内的命令。
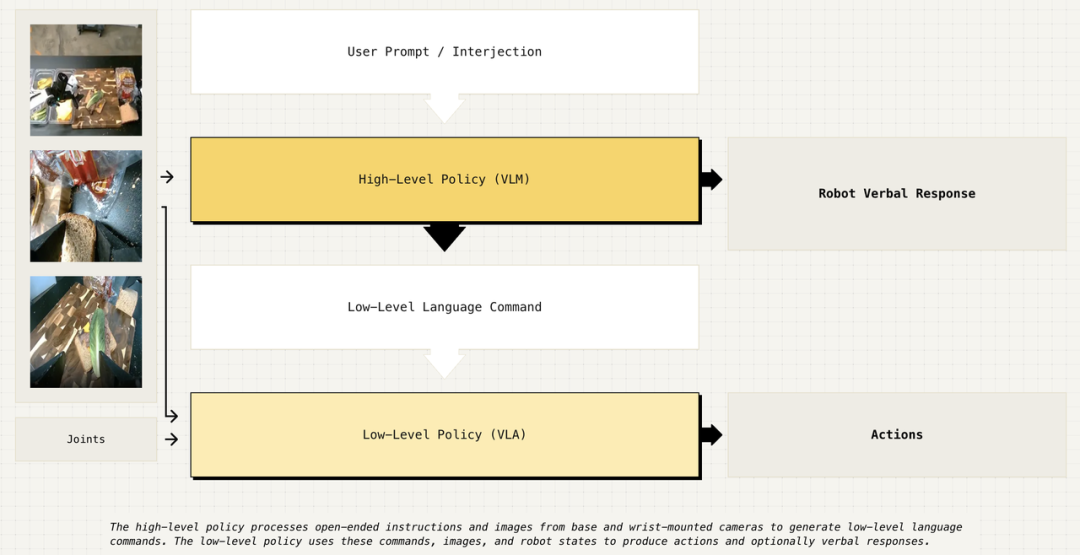
这个项目非常有趣,我们让机器人做了一个三明治,还做了购物和清理桌子。我最初对它感到兴奋,是因为看到机器人能够响应不同的提示并完成这些具有挑战性的任务,而且, 它似乎是一种正确的方法。
05.机器人需要哪些感官?
Elad:机器人的传感器现在处于什么阶段?
Chelsea Finn:如果仅仅依靠视觉,甚至仅使用 RGB 图像,我们已经走得很远了。我们通常会有一个或多个外部的基础摄像头来观察场景,并且还会在机器人的每个手腕上安装摄像头。我们可以通过这些设备取得很好的效果。
如果我们能给机器人装上“皮肤”就更好了,但目前市面上的触觉传感器要么不如皮肤那么耐用,要么成本过高,或者分辨率非常低。所以,在硬件方面有很多挑战。实际上将 RGB 摄像头安装在手腕上非常有帮助,可能能提供与触觉传感器相似的很多信息。
Elad:在机器人领域,需要多少传感器?哪些是必要的,哪些可能不需要?
Chelsea Finn:比如做三明治,你可能希望机器人能够“品尝”一下三明治,看看是不是好吃,或者至少能闻到味道。我过去曾多次向 Sergey Levine 提出过“嗅觉”这个观点,因为嗅觉确实有很多好处。
从某种角度来看,传感器有冗余性是很好的。比如音频,当人类听到某个意外的声音时,实际上可以在许多情况下提醒你注意到某些事情,尽管你可能已经通过其他传感器看到了某个物体掉落。这样的冗余性可以增强系统的鲁棒性。
但对我们来说,现在并不是优先考虑这些传感器的时机,因为当前的瓶颈并不在于传感器,而是在数据处理,尤其是在架构等方面。
目前我们的机器人策略没有记忆,机器人只看当前的图像,甚至无法记住半秒钟前发生的事情。所以,我宁愿先在我们的模型中加入记忆功能,而不是添加其他传感器。在没有其他传感器的情况下,我们也能够为许多应用场景开发出商业可行的机器人。
06.类比自动驾驶,机器人和机器人公司会如何发展?
Elad:和自动驾驶相比,机器人未来发展的时间线大概是怎么样的?
Chelsea Finn:我不知道。自动驾驶和机器人技术各有难易之处。一方面,机器人更难,因为是一个更高维度的空间,即使是静态机器人也有 14 个维度,每只手臂有 7 个维度。在很多情况下,需要比自动驾驶有更高的精确度。我们也没有一开始就拥有那么多的数据。
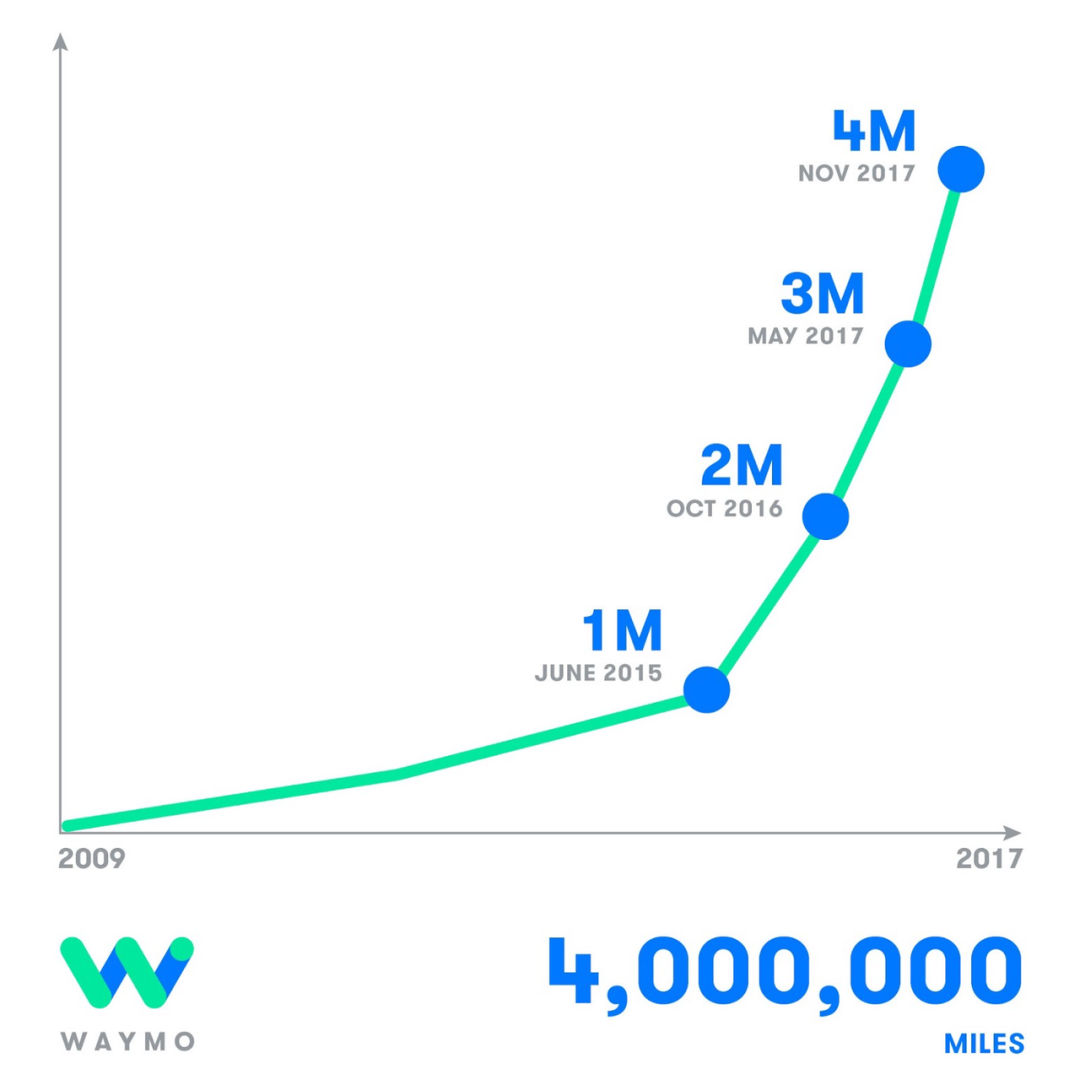
另一方面,自动驾驶必须解决整个分布问题,才能让任何技术具备可行性,必须能够处理任何时间段的交叉路口、各种行人情景以及其他车辆等。而在机器人技术中,有很多商业应用场景不需要处理这么大的分布问题,也没有那么大的安全风险,而且自动驾驶领域的结果非常令人鼓舞,尤其是旧金山 Waymo 车辆数量的增加。
Elad:类比自动驾驶的发展,现在的机器人公司会如何发展?大公司做机器人是否有优势呢?
Chelsea Finn:最近有很多新玩家进入机器人领域。
10 年前,做自动驾驶可能为时过早,但自那时以来,深度学习取得了很大的进展。机器人领域也是如此,如果是在 10 年前,甚至 5 年前,我觉得也太早,当时的技术并不成熟,或许现在仍然有些早。
自动驾驶的难度已经证明了在物理世界中构建智能是多么困难。
我非常喜欢初创公司的环境,我在 Google 遇到过非常困难的事情,比如考虑到代码安全,带着机器人离开校园几乎是完全不可行的。但如果想收集多样化的数据,把机器人带出校园是很有价值的。而在初创公司中,你可以更快地行动,因为你没有那些限制和繁琐的程序。大公司虽然有大量资本,可以支撑得更久,但行动会更慢。
对于初创公司的创始人而言,快速部署、快速学习和快速迭代可能是最重要的,而且要尽量去开发,真正让机器人走到市场上, 并从中学习。
07.对训练数据和硬件的看法
Elad:怎么看待将人的观察数据作为机器人训练集的一部分,这些数据可能来自 YouTube,或者是专门录制的内容。
Chelsea Finn:这些数据确实有很大价值,但仅凭这些数据并不能走得太远。
例如,你观看奥运游泳运动员比赛,即使你有运动员的体力,但运动员训练自己的肌肉来完成动作的经验也是至关重要的。
例如,你试图学习如何打好网球,但仅仅通过观看专业选手,是无法学会的。
人类在低级别的运动控制方面已经是专家,但机器人并不是这样。机器人实际上需要从自身的身体经验中来学习。所以,能够利用这种数据形式,尤其是扩展机器人自己的经验,是非常有前景的。但要真正取得进展,关键还是要有来自机器人本身的数据。
Elad:这些数据是你为机器人生成的通用数据,还是你让机器人模仿某些活动?
Chelsea Finn:当我们收集数据时,机器人有点像牵线木偶,我们可以记录机器人实际的运动指令和传感器数据,比如摄像头图像,这就是机器人的“经验”。
自动化经验将发挥巨大作用,就像在语言模型中那样。得到一个初步的语言模型后,如果能通过强化学习让机器人基于自己的经验自我启动,那将是非常有价值的。
Elad:哪些数据是可泛化的?
Chelsea Finn:数据是否可泛化关键在于分布广度(the breadth of the distribution)。
虽然很难量化或衡量机器人的经验有多广泛,也没有办法将任务的广度进行分类,比如一个任务与另一个任务有多大不同,一个厨房与另一个厨房有多大差异之类的,但至少可以通过观察建筑物数量或场景数量等因素,粗略了解这种广度。
Elad:随着机器人技术的发展,未来机器人是会有一个单一的形式,还是会有几个不同的形式,从而形成一个丰富的生态系统?
Chelsea Finn:我的猜测是会有很多不同的机器人平台,各种各样的机器人硬件类型会涌现出来,我和 Sergey Levine 将其称为“寒武纪大爆发”。只要我们拥有可以支持这些不同机器人的技术和智能,就像厨房里有各种不同的设备,各自能做不同的事情,而不是只有一个设备能做所有事情。
可以想象一个这样的世界:有一种机器人手臂可以在厨房里做事,它的硬件专门针对厨房工作进行了优化,并且可能还会优化成对于这个特定用途而言更便宜,还有其他硬件可能设计用于折叠衣物、洗碗等。
Elad:在 The Diamond Age 这本书中,呈现了一种观点:物质通过管道进入家庭,家庭用 3D 打印机来制作一切,比如你下载图纸,然后 3D 打印出物品。还有一些人可能会修改设计,选择性优化某些功能来改进产品。这样的未来有可能实现吗?

Chelsea Finn:这样的世界是非常可能的。如果针对某个特定的使用场景来优化硬件,是可以制造出更便宜的硬件的。而且这样的硬件可能也会更快、效率更高等。但实际实现起来是非常困难的。
Elad:预测未来趋势确实非常困难。我之所以认为硬件平台的数量会减少,其中一个原因就是供应链问题。大规模生产硬件组件可以降低成本,因此最终市场上的硬件平台可能会收缩,变成更少但更具规模效应的选择。
除非某些硬件平台在成本上有显著的优势,否则企业更倾向于生产更少种类的硬件,因为这样更容易扩展、复制,并且制造成本更低。从硬件行业的角度来看,这是一个常见的逻辑。因此,在“多样化硬件平台”与“规模化、低成本生产”之间的权衡,是一个值得思考的问题。
Chelsea Finn:我们可能会有机器人出现在供应链中,能够制造任何想要的定制设备。
Elad:未来,机器人将无处不在。
编译:haozhen 编辑:Siqi
本文由人人都是产品经理作者【海外独角兽】,微信公众号:【海外独角兽】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。






- 目前还没评论,等你发挥!


