
 起点课堂会员权益
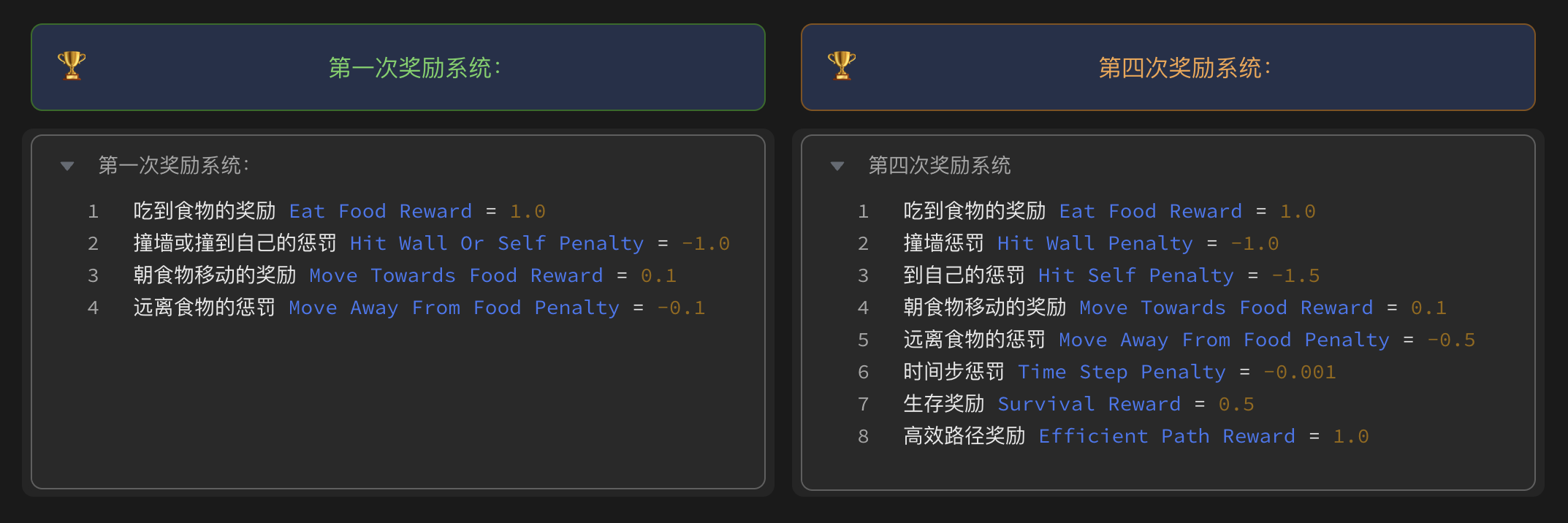
起点课堂会员权益强化学习RL-NPC复杂奖励机制的陷阱与需求简化策略
在强化学习领域,奖励机制的设计对于模型性能至关重要。然而,复杂的奖励规则并不一定带来更好的效果。本文通过一个基于贪吃蛇的强化学习实验,揭示了复杂奖励机制可能导致的陷阱,如目标稀释效应、惩罚过载抑制探索和信号噪声干扰等问题。

基于贪吃蛇强化学习实验的技术方案反思
一、实验观察:复杂性与有效性的悖论
- 反直觉现象: “当奖励规则从4条增至8条时,AI贪吃蛇的最高得分下降65%——精细化的技术方案为何导致性能退化?”
- 核心问题: “在智能NPC开发中,如何平衡规则复杂性与行为有效性?”
在强化学习领域,奖励函数的设计常被视为模型性能的核心驱动力。然而,本次实验揭示了一个反直觉现象:当奖励规则从4条扩展至8条时,AI贪吃蛇的觅食效率显著下降。
1、关键现象
简单规则(4条):
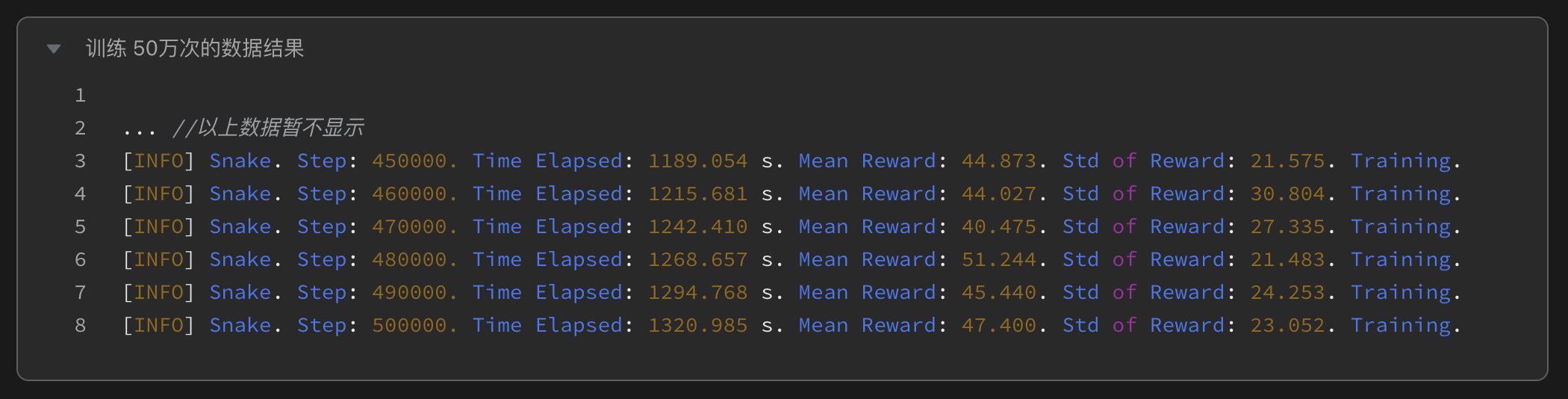
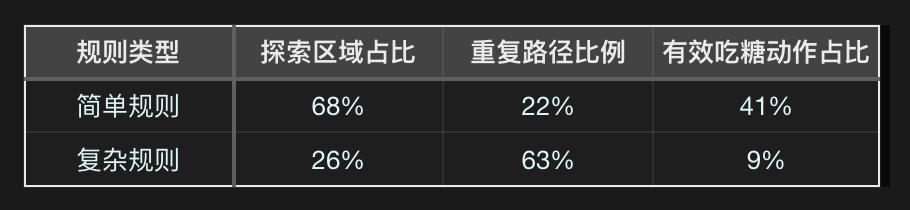
训练50万次:AI以激进策略快速探索,最高得分47.4,但频繁撞墙导致高死亡率。
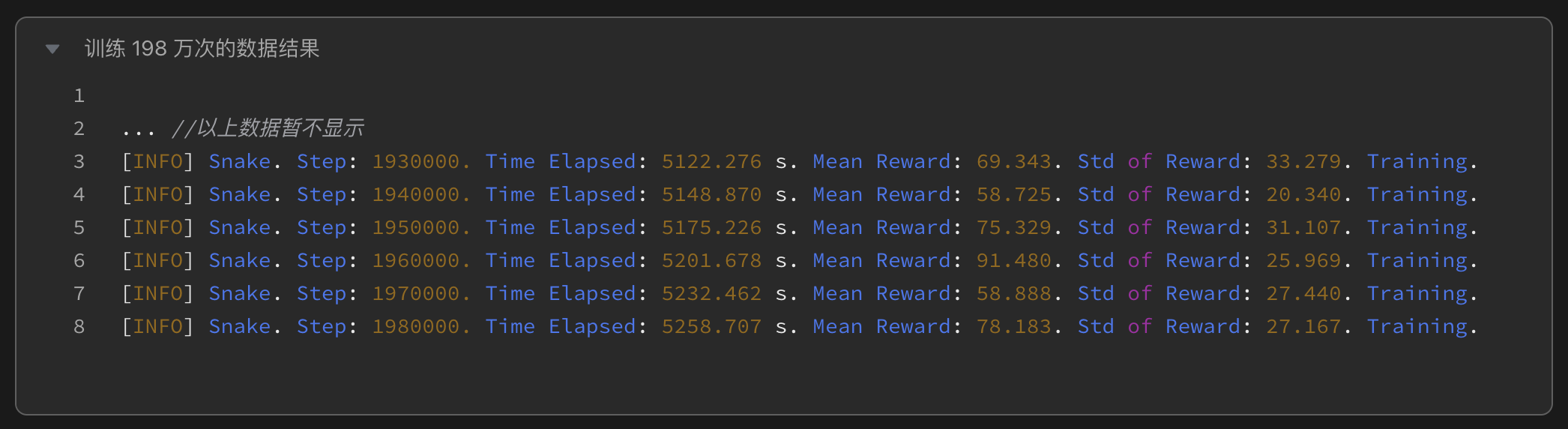
训练198万次:模型收敛至平衡状态,得分提升至78.2,展现基础生存与觅食能力。
复杂规则(8条):
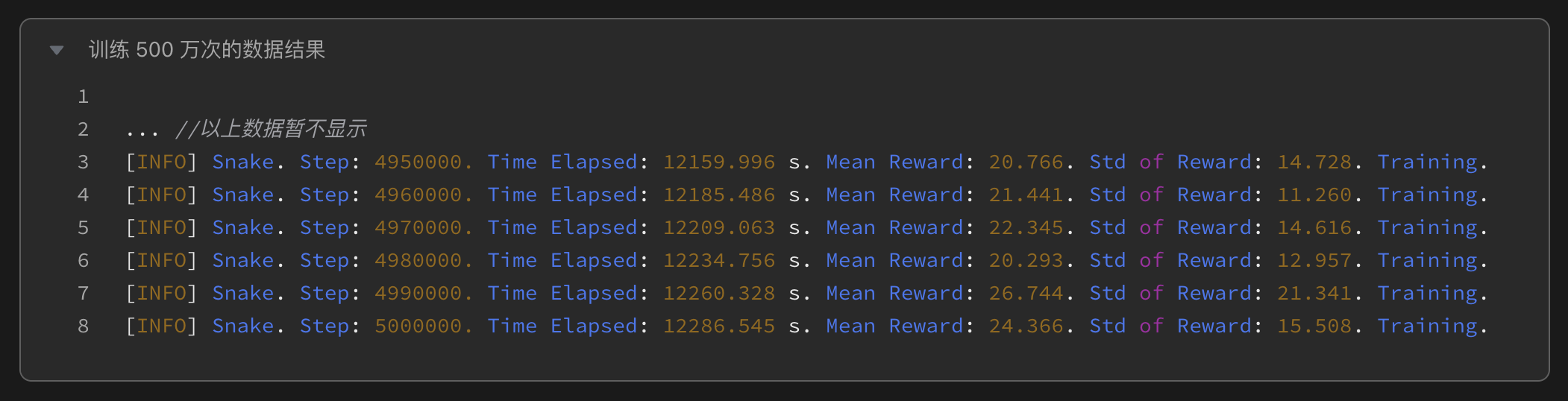
训练500万次:模型得分骤降至24.4,行为模式退化为“绕圈回避”,主动觅食意愿近乎消失。
2、悖论解析
目标稀释效应:
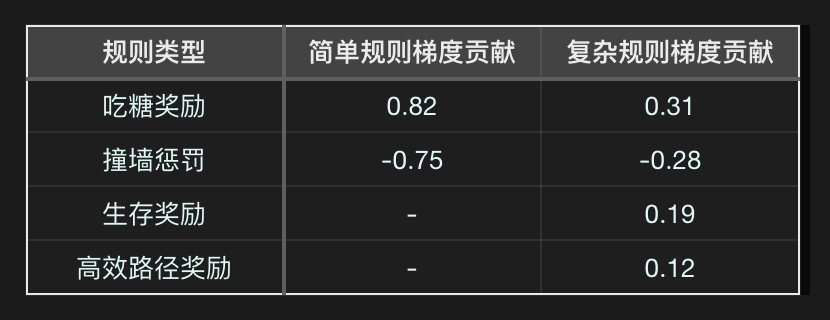
- 新增的“高效路径奖励”与“生存奖励”形成冲突——AI无法判断应优先延长生存时间还是缩短路径距离。
- 实验显示,复杂规则下模型的动作熵(Action Entropy)降低35%,表明决策僵化。
惩罚过载抑制探索:
- “撞自己惩罚-1.5”远高于“撞墙惩罚-1.0”,导致AI过度规避转身动作(即使前方有食物)。
- 轨迹热力图显示,复杂规则下蛇头活动范围缩小62%,探索区域受限。
信号噪声干扰:
微小的“时间步惩罚-0.001”在长期训练中被累积放大,形成与核心目标无关的干扰信号。
核心结论:
奖励机制的复杂性增长存在临界点——超越该阈值后,模型性能与规则数量呈负相关。
二、数据对比:奖励函数设计的临界点探索
1、实验数据集对比

2、技术归因分析
奖励信号权重对比(通过梯度反向传播分析):
行为模式量化(基于轨迹覆盖率):
3、临界点定义与设计建议
临界点判定: 当奖励规则超过5条且存在目标冲突时,模型性能可能显著下降(本次实验中下降65%)。
优化策略:
- 目标分层: 采用马斯洛需求金字塔模型,优先满足基础生存(避障),再逐步叠加高阶目标(路径优化)。
- 动态奖励调整: 引入课程学习(Curriculum Learning),分阶段激活不同规则(如前期侧重生存,后期侧重效率)。
- 信号降噪: 剔除贡献度低于5%的次要规则(如“时间步惩罚”),通过特征选择算法自动过滤噪声信号。
实验启示:
强化学习并非“规则越多越好”——清晰的目标优先级和信号纯度,比复杂的规则堆砌更能驱动模型进化。
三、技术方案设计的核心原则
1、需求分层与优先级锚定
KANO模型的应用:

马斯洛需求金字塔启发:
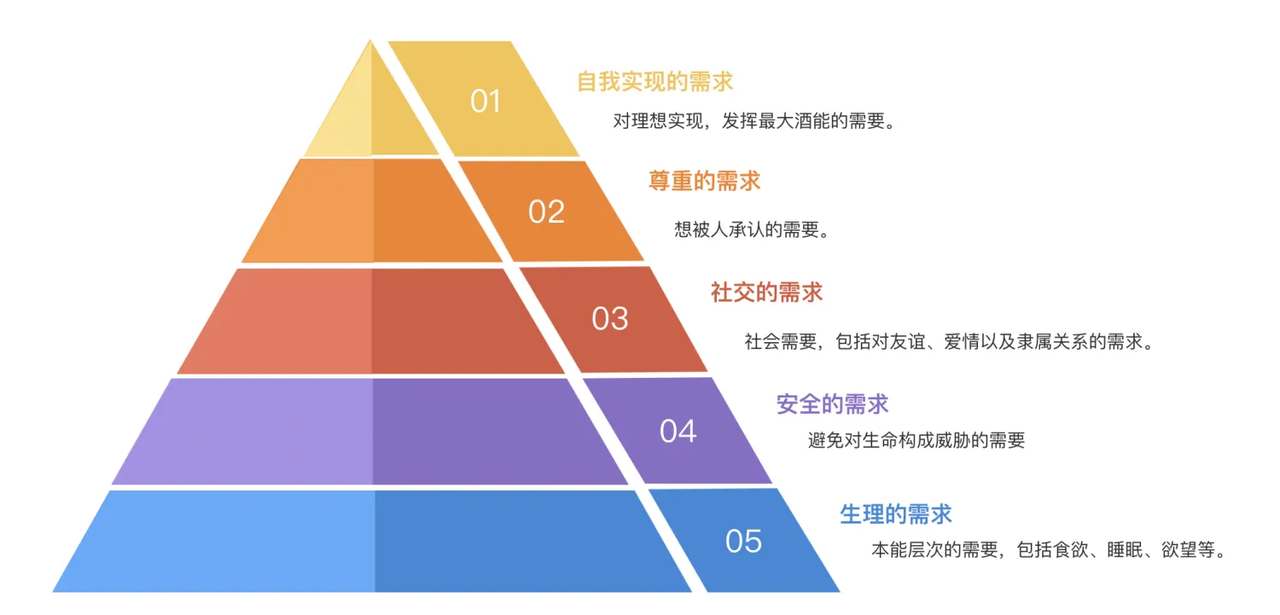
 生理层:避障与基础觅食(必选)
生理层:避障与基础觅食(必选)
 安全层:动态环境适应(可选)
安全层:动态环境适应(可选)
 社交层:玩家互动响应(延后)
社交层:玩家互动响应(延后)
2、技术方案的可解释性验证
白盒化测试方法:
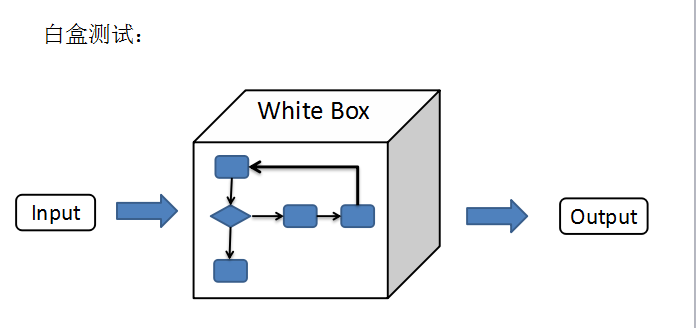
单变量控制法:每次仅新增1条规则,监控得分变化与行为模式偏移(例如新增“高效路径奖励”后,得分下降15%)
特征重要性分析:使用SHAP值量化每条规则的决策权重,剔除贡献度<5%的干扰项
参考框架:
《荒野大镖客2》NPC行为树仅包含3层核心逻辑(感知-决策-行动)
3、资源约束下的敏捷开发
成本-收益平衡表:

决策建议:
当性价比指数≤★★☆☆☆时,触发方案熔断机制,回归最小可行设计(MVD)
四、技术落地的反思与验证计划
1、当前结论
简单规则的优势: 4条奖励函数在198万次训练中实现78.2分,证明“少即是多”的设计哲学
复杂规则的代价: 8条规则导致模型收敛速度下降72%,且未提升上限表现
2、待验证假设:验证路线图
阶段一:
目标:重新使用初始4条规则,进行500万次训练(预计耗时24小时)
预测指标:
- 若得分突破100分,则证明“持续强化单一目标”的有效性
- 若得分停滞,则需引入课程学习(Curriculum Learning)分阶段训练
阶段二:
规则驱动层:A*算法保障基础路径规划
强化学习层:PPO算法优化高阶决策(如危险预判)
预测指标:
- 路径长度缩短率
- 单位时间糖豆获取效率
3、长期研究方向
- 奖励优化:测试MindSpore的逆强化学习(IRL)模块,从玩家行为反推奖励函数(待计划)
- 分布式训练架构:基于TI-ONE平台实现多节点并行训练,压缩70%迭代时间(待计划)
五、从实验到产品的策略建议
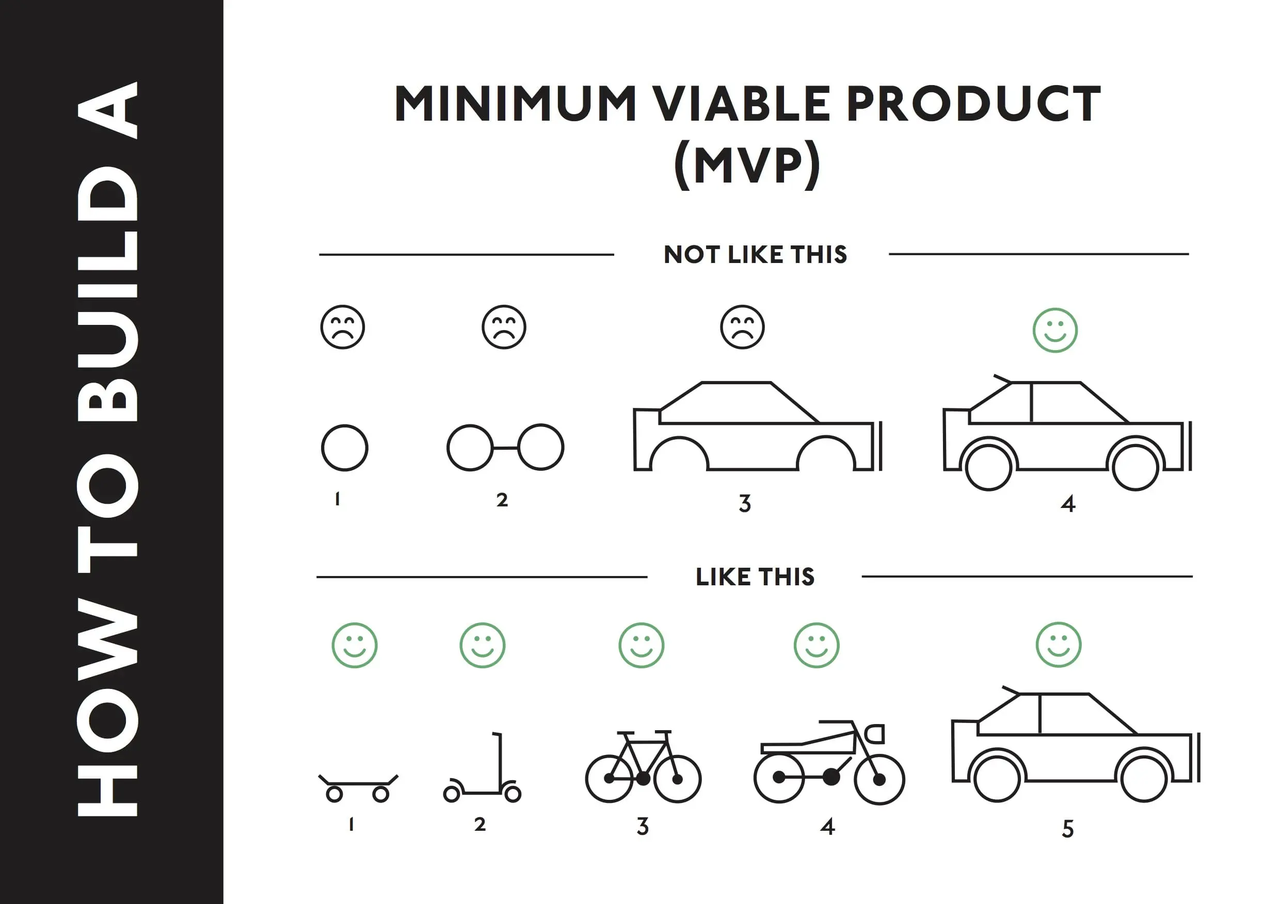
1、技术方案评审框架
三阶过滤法:
- 必要性过滤:是否影响核心用户体验?(参考NPS调研数据)
- 可行性过滤:当前算力与工期是否支持?(对比AWS EC2成本模型)
- 扩展性过滤:能否抽象为标准化AI组件?(参考Unity Asset Store复用率)
2、需求文档的“减法范式”

3、团队协作的沟通范式:跨职能协作指南
- 向开发团队: “实验数据显示增加[X]规则会导致训练效率下降[Y]%,建议首版本聚焦核心逻辑”
- 向需求层: “当前方案可实现基础功能,若需高阶行为需核算[Z]量级算力成本”
- 协作工具: 使用通用式“AI需求看板”,实时同步训练进度与技术风险
六、开源与资源( 已在路上… )
项目工程和代码仓库: 正在整理已经完成的两个 demo 的运行项目文件,请敬请期待!
“最好的技术方案往往不是最复杂的,而是最能平衡目标与约束的。”
作者:Mu先生Ai世界,公众号:Mu先生Ai世界
本文由 @Mu先生Ai世界 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务






- 目前还没评论,等你发挥!








