起点课堂会员权益
起点课堂会员权益
一文搞懂生成式AI的技术突破与未来发展
 B端产品经理需要更多地关注客户的商业需求、痛点、预算、决策流程等,而C端产品经理需要更多地关注用户的个人需求
B端产品经理需要更多地关注客户的商业需求、痛点、预算、决策流程等,而C端产品经理需要更多地关注用户的个人需求生成式 AI 正在以前所未有的速度改变我们的生活和工作方式,从简单的文字生成到复杂的多模态创作,它的发展令人瞩目。本文将深入剖析生成式 AI 的技术突破与未来发展,从 AI 的进化路径、核心技术原理、学习机制到其在实际应用中的潜力与挑战,为你揭开生成式 AI 的神秘面纱,带你一探究竟。

现在人工智能让我在想,哇靠,是不是以后都不用我了?
看完李宏毅老师的课,我放心了,人工智能很猛,但还是要我来下指令。
01 从 “讲冷笑话的 AI” 到会办事的 AI Agent:聊聊 AI 正在进化的 “职场能力”
李老师给ai布置了个任务,让做个关于 AI 的 PPT,要求就俩字:有趣。
结果它一本正经回:“我昨天写了个递归程序,结果今天还在执行”。我笑了,你呢?
你别说,这冷笑话自带技术梗的幽默,倒是让我突然好奇:现在的 AI,到底是真懂幽默,还是在玩文字接龙?
更有意思的是,当聊到扩散模型时,他说扩散模型,其实很浪漫,为什么?
因为他告诉我们,就算人生一团乱,全是噪声,只要一步一步努力去除噪声,也能拼出美丽的风景。
AI 都这么励志了。
我从来没有想过扩散模型 diffusion model 背后有这么励志的故事,AI 实在是太有创意了。

这让我想起早年的 AI,只会机械地 “用户问啥答啥”,现在却能把技术逻辑编织成故事,甚至带点人文关怀,这算不算一种 “情商进化”?
从 “直接给答案” 到 “展示思考链”
但 AI 的进化远不止于 “讲段子”。
不知道大家发现没,过去的 AI 像个 “答案贩卖机”,你输入 “怎么煮奶茶”,它直接甩给你步骤。
现在的主流模型却开始“晒思路”了,比如你问 一个问题,他先在脑内演绎一个小剧场,尝试各种解法,最后给你一个可行的办法,并且把这个脑内小剧场展示给你。
这种“思考过程可视化”,通常管它叫“reasoning 能力”。
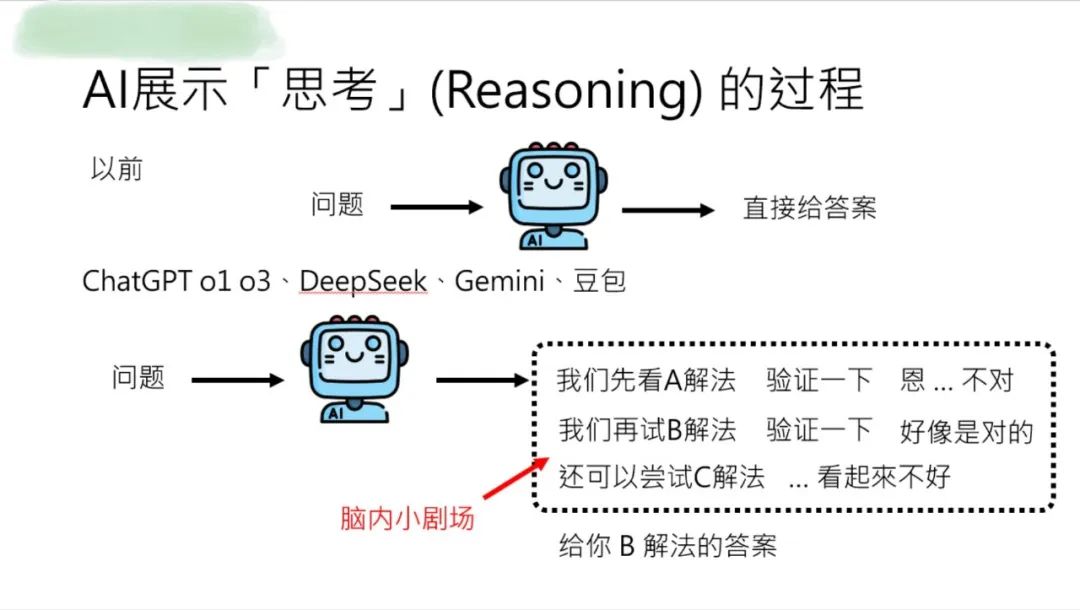
那对于AI来说这个答案给就给了,那这个答案会造成什么样的影响?
这个答案是不是对的他也不在乎,但是光是一问一答不能解决所有的问题,很多的任务往往需要多个步骤才能完成。
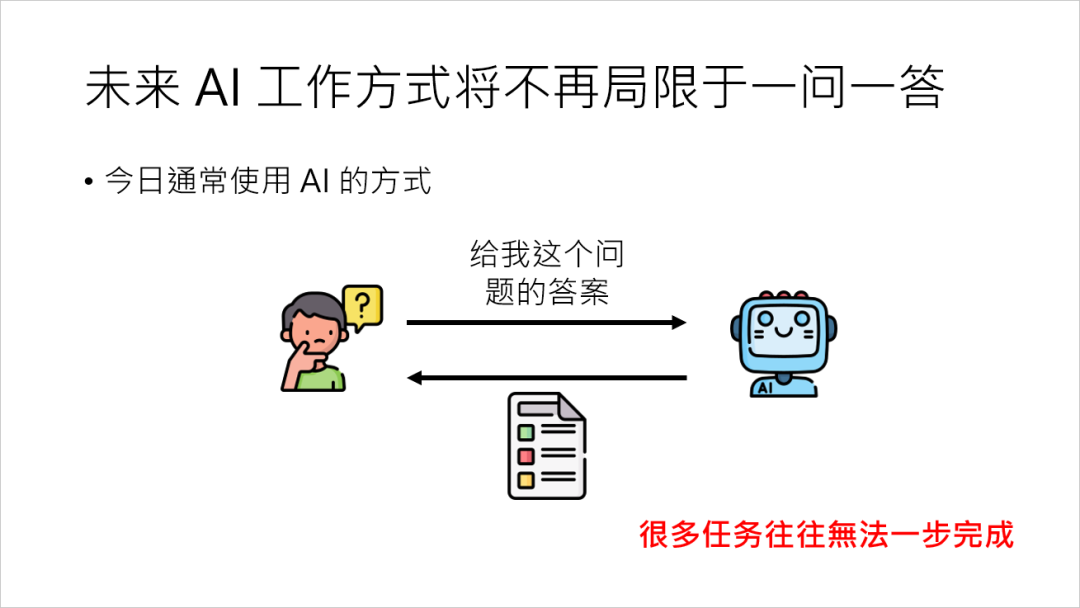
为啥需要这能力?
举个生活化的例子:李老师说,某天他老婆说 “今晚下馆子”,搁传统 AI 这儿,可能就停留在 “吃什么”“哪家餐厅” 的简单问答。
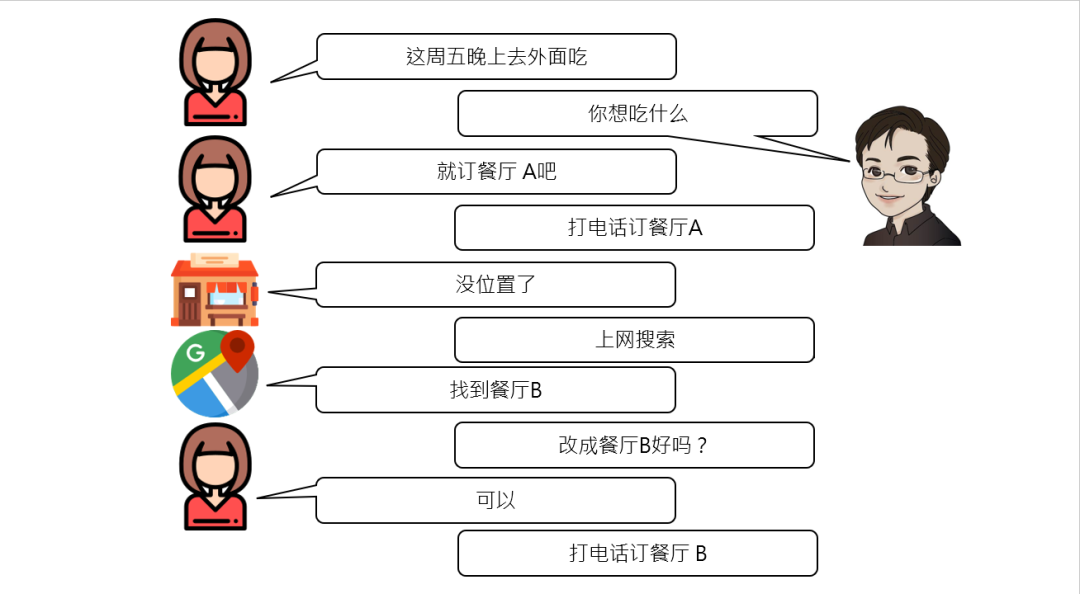
但人类处理这事可复杂多了:打电话订餐厅 A 没位,得接着搜餐厅 B,还得跟老婆确认是否合适 —— 这是个多步骤的“任务链”。
要是 AI 只会单步响应,回一句 “没位置了” 就结束,怕是要被痛扁的。
所以啊,真正能办事的 AI,得学会“多线程思考”,这就引出了一个关键概念:AI Agent。
能 “规划、学习、用工具” 的职场型 AI
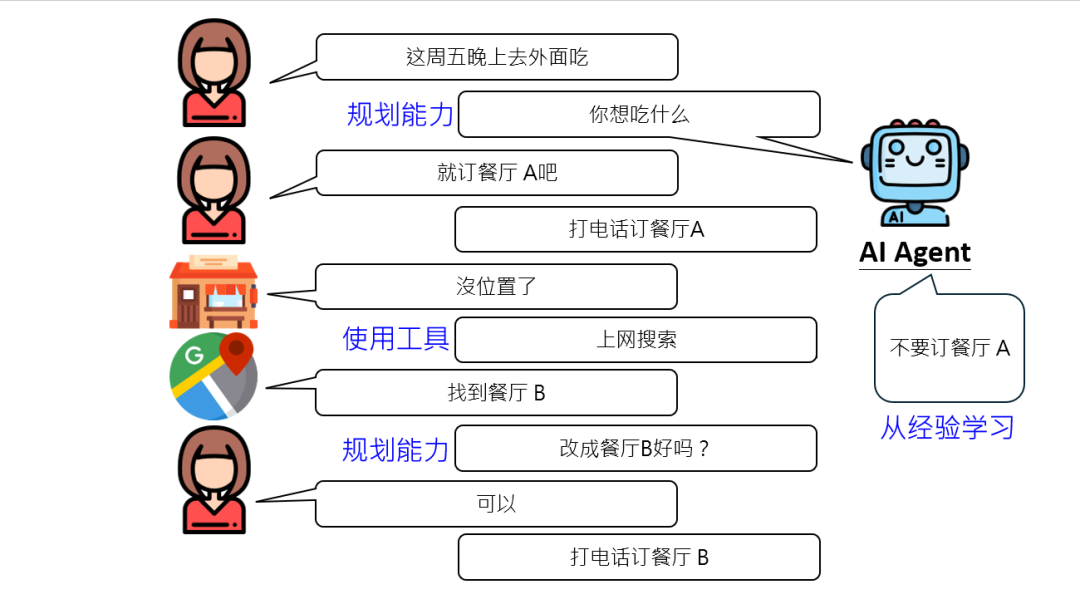
啥是AI Agent?简单说,就是能像人类一样 “分步骤完成复杂任务”的 AI。
接着刚才订餐厅的例子,它得具备三大核心能力:
第一,从经验中学习的能力。第一次打电话知道餐厅 A 没位,下次就不能再死磕了,得记住 “这家已满,换别家”。要是没这能力,反复拨打同一号码,别说老婆不满意,连咱人类都得急眼:“这 AI 咋这么轴?”
第二,使用工具的自觉。AI 清楚自己 “肚里没货”,比如不知道附近还有哪些餐厅,就得主动调用“搜索工具”。这就像人类办事,不懂的地方会查资料、问同事,AI 也得学会“借力”。现在的模型已经能对接搜索引擎、地图 API,甚至操控鼠标键盘了,这可是从 “纯脑力” 到 “动手实操” 的跨越。
第三,动态规划与策略调整。什么时候该跟人类确认?比如找到餐厅 B,得问 “订这家行不行”,避免自作主张订错;什么时候又该自主决策?比如搜索餐厅时,不需要每步都请示 “我能搜吗”,不然人类早烦了。这种“分寸感”的把握,其实体现了 AI 对任务流程的理解深度。
从 “搜资料” 到 “操控电脑”
现在的 AI 其实已经有了 Agent 的雏形。
比如Deep Research,当李老师问 “中部横贯公路历史沿革” 时,它可不是搜一次就完事:先查主线支线,发现雾社支线有 2018 年改道工程,接着深挖改道细节,再根据新信息调整搜索方向,最后整合出一篇完整报告。

这就像人类做研究,先列大纲,再按需补充资料,边查边调整思路。
更厉害的是 ChatGPT 的Operator功能。
李老师演示了:让 AI 帮忙加签 “机器学习” 课程,它先点击 “课程资讯” 找表单,没找到就转向 “课程说明”,发现需要 Gmail 账号时,还能跟用户确认是否申请账号(虽然最后因权限问题暂停,但这过程已经很 “人类” 了)。
你看,它能理解网页结构,根据视觉反馈(屏幕截图)调整操作,甚至模拟人类“试错 — 修正” 的行为模式,这不再是单纯的语言生成,而是“操控数码世界”的初级形态。
AI 正在 becoming “有用的伙伴”
回头看,AI 的进化路径特别有意思:早期像个 “呆萌的知识库”,只会生硬回答;后来学会 “讲段子、说故事”,有了点交互温度。
现在则朝着“职场型助手”发展,能规划、会学习、懂协作。
就像李老师说的,开发机器学习模型本身就是个多步骤任务,AI Agent 的出现,其实是让 AI 从 “单一技能型选手” 进化成“项目管理型选手”。
当然,现在的 AI Agent 还不够成熟,比如订餐厅时可能不懂用户的口味偏好,搜资料时可能被虚假信息误导,操控电脑时受限于界面规则。
但关键在于,它展现了一种 “解决复杂问题的思维框架”—— 把大任务拆解成小步骤,动态调整策略,合理利用工具,必要时与人协作。这种能力,正是人类职场中最核心的 “问题解决力”。
最后忍不住想:当 AI 都开始学着 “分步骤办事”“从失败中总结经验”“知道什么时候该问人”,作为人类的我们,是不是也该反思一下自己的工作方式?毕竟,连 AI 都在进化成 “会办事的伙伴”,咱可不能输给代码呀。
我们已经看到了 AI 的行为,接下来我们来看它背后运作的机制。
02 从 TOKEN 到 Transformer, AI 如何 “思考”
这生成式 AI 背后的核心原理到底是什么呢?
很多人看到 AI 能写文章、画图、说话,觉得这事儿特别玄乎,但拆开来看,其实就像玩 “超级复杂的文字接龙”—— 只不过这里的“字”,可能是文字、像素、声音取样点,甚至是你能想到的一切数字化的基本单位。
万物皆 TOKEN:AI 眼中的世界是 “积木堆”
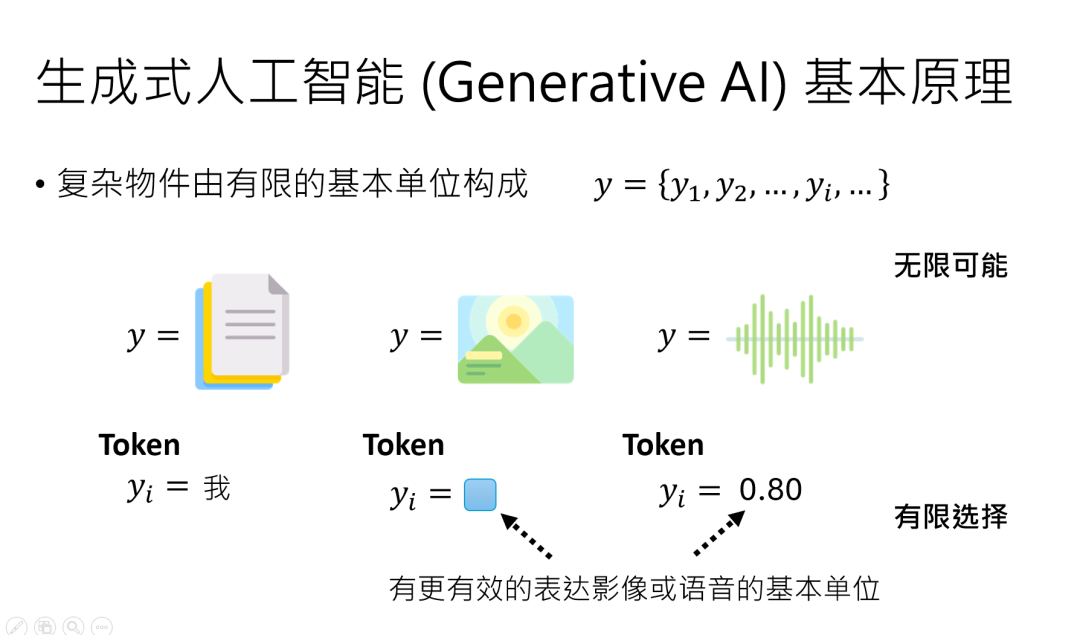
生成式 AI 做的事,简单说就是 “输入一堆东西,输出一堆东西”,但这些 “东西” 在AI 眼里,都是由最小单位TOKEN组成的。
比如一段中文,基本单位是汉字,常用的也就 4000 多个。
一张图片,放大后是像素(每个像素的颜色选择虽然多,但也是有限的);
一段声音,本质是数字取样点(每个点用有限的字节存储)。
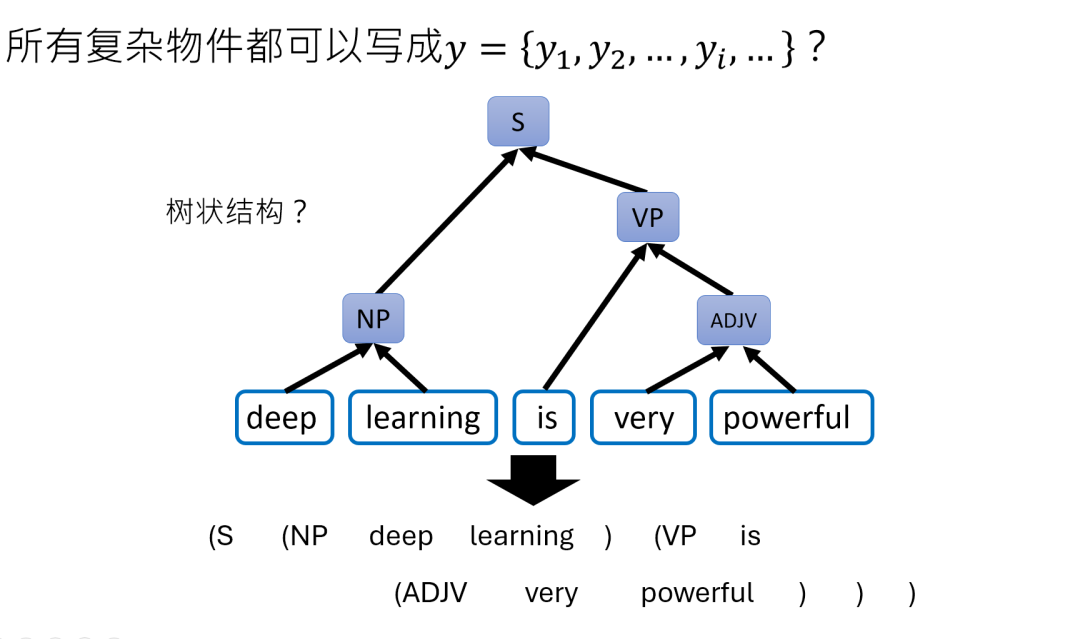
哪怕是树状结构、表格,AI 也会把它们转换成文字序列(比如用括号表示结构),所以TOKEN就是 AI 世界的 “积木”,有限的积木能搭出无限可能。
黄仁勋去年在 COMPUTEX 说 “万物皆 TOKEN”,可不是让你买代币,而是说 AI 处理的所有内容,最终都会被拆解成这些基本单位。
比如你让 AI 画一幅画,它其实是在 “接龙” 像素 TOKEN;让它写文章,就是在接龙文字TOKEN—— 只不过这些接龙的规则,藏在复杂的模型里。

上面咱们说到,生成式 AI的核心是 “输入一堆 TOKEN,输出一堆 TOKEN”,但这里的“输入输出”—— 也就是咱们用符号y表示的东西。
其实可以是千变万化的:一段话、一张图、一段声音……表面看它们天差地别,但在AI 眼里,统统都是由“基本单位”搭成的“积木堆”。
今天咱们就钻到细节里,看看这些 “积木” 到底长啥样,以及 AI 如何用同一套逻辑玩转它们。
y的 “分身术”:不同形态下的基本单位长啥样?
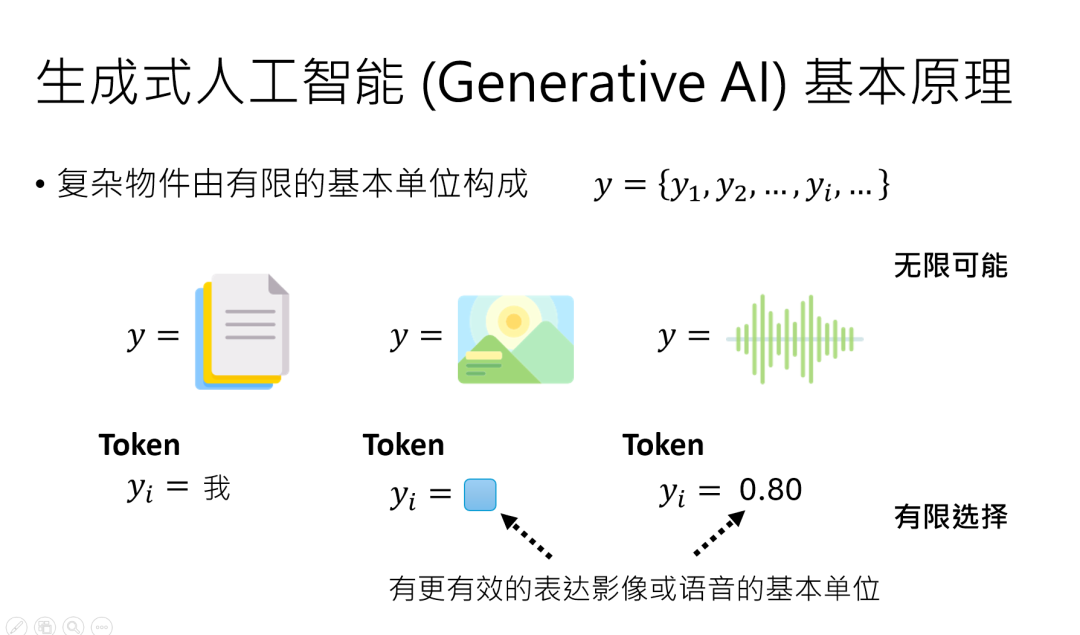
先记住一个公式:y = [y₁, y₂, …, yᵢ],这里的每个下标 yᵢ 就是一个基本单位,也就是TOKEN。不同的 y,只是 TOKEN 的 “马甲” 不同:
文字 y:符号 TOKEN 的排列组合
一段中文,比如 “今天天气不错”,拆解成TOKEN就是单个汉字:“今”“天”“天”“气”“不”“错”。
中文常用字约 4000 个,加上标点、特殊符号,TOKEN 总量大概几万 —— 虽然多,但永远是有限的。
就像乐高积木,基础块就那几百种,但能搭出整个宇宙。
图片 y:像素 TOKEN 的色彩拼图
一张图片放大后是密密麻麻的像素,每个像素是一个颜色点。
比如 RGB 格式下,每个像素用 3 个字节(红、绿、蓝各 1 字节)表示,每个字节有 2⁸=256 种可能,所以单个像素的颜色组合是 256×256×256≈1600 万种 —— 虽然多,但依然是有限的。
假设图片是256×256 像素,AI 要生成的就是256×256 个像素 TOKEN,每个 TOKEN 对应一个颜色组合。
声音 y:数字 TOKEN 的波形密码
声音本质是声波,转换成数字信号后,每秒会采样成千上万次(比如 44.1kHz 采样率),每个采样点用一个数字表示振幅。
但计算机存储时,每个数字的精度是有限的,比如用 16 位整数存储,每个采样点就有 2¹⁶=65536 种可能。
一段 10 秒的声音,就是 10×44100=441000 个数字 TOKEN—— 依然是有限的排列组合。
更妙的是,就连复杂的结构(比如语法树、表格),AI 也会先 “翻译” 成文字 TOKEN序列。比如一棵语法树,用括号表示层级:“(主语 (名词 猫)) (谓语 (动词 跳))”,本质还是文字TOKEN 的排列。
所以无论多复杂的 y,最终都能拆成一串 TOKEN,这就是 AI 能“统一处理万物” 的底层逻辑。
从 “文字接龙” 到自动回归:AI 如何一个一个蹦出答案?
生成式 AI 的核心策略叫自动回归生成(auto regressive generation),说白了就是“每次只生成一个 TOKEN,接着用生成的结果继续生成下一个”。
比如输入 “台湾大”,AI 先想第一个可能的后续 TOKEN:“学”“车”“哥”…… 算出每个TOKEN的概率,选一个(可能带点随机),假设选了 “学”,然后把 “台湾大 + 学” 作为新输入,继续想下一个 TOKEN,直到遇到 “结束 TOKEN”(比如文章写完了,或者图片像素数够了)。
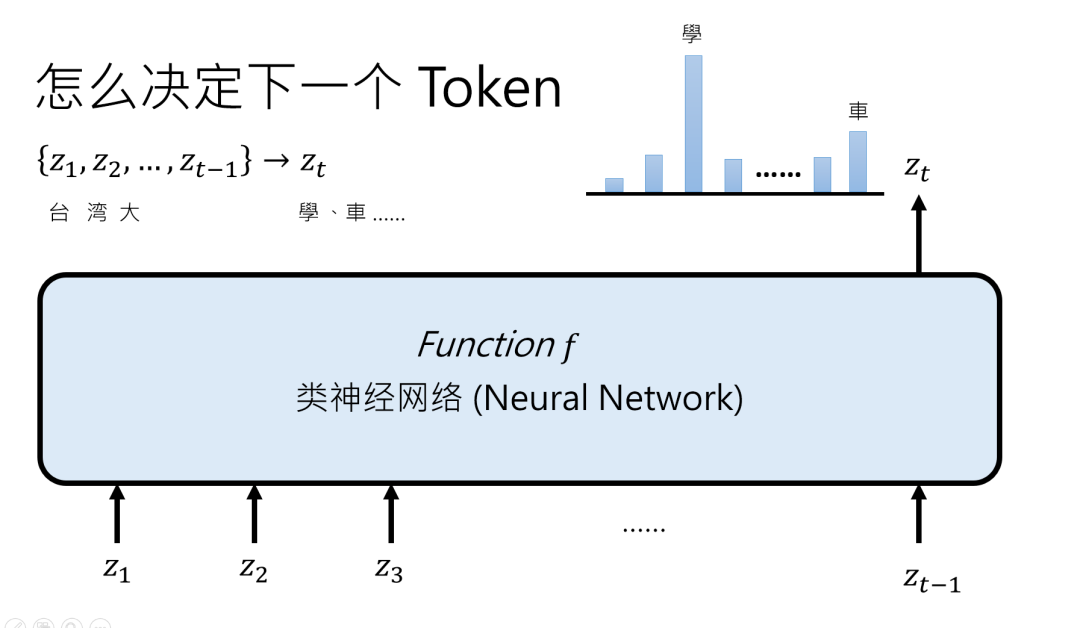
这里有个关键:AI 输出的不是唯一答案,而是概率分布。
比如 “台湾大” 后面接 “学”“车”“哥” 都有可能,AI 会给每个可能的 TOKEN打个分,告诉你 “接‘学’的概率是 60%,接‘车’是 30%”,然后随机选一个。
这就是为什么同样的输入,AI 每次输出不一样—— 它在“掷骰子”做选择。
神经网络:把复杂问题拆成 “小步骤闯关”
那 AI 怎么算出每个 TOKEN 的概率呢?
靠的是神经网络(类神经网络),它的核心是 “把一个超复杂的函数,拆成很多小函数串联起来”,每一层小函数(layer)就是一次 “思考步骤”。
举个不精准但好懂的例子:算三位数相加(比如 123+456),如果让 AI一步到位,它得记住 1000 种可能的输入输出关系。
但如果拆成两步(先算 123+456 的前两位,再加上第三位),每一步只需要处理更少的可能,就像闯关一样,每关解决一个小问题,最后拼出答案。
这就是 “深度学习” 的本质 ——用很多层(深度)把复杂问题拆成简单问题,每层只做一件小事,但层层叠加就能处理超复杂的任务。
现在的神经网络,比如Transformer,每层又分两部分:一部分叫self-attention(自我注意),能全局看所有输入 TOKEN 的关系(比如写文章时,让 “它” 知道前面指的是 “猫” 还是 “狗”);另一部分处理单个TOKEN 的细节,两者结合,让 AI 既能顾全大局,又能抠细节。
Transformer:变形金刚背后的 “注意力魔法”
2017 年诞生的Transformer,是现在大多数 AI 模型(比如 ChatGPT、LLaMA)的底座。
它的名字很有趣,原作者说就是觉得 “酷”,没什么特别含义,但它的能力可不简单 —— 靠 self-attention 实现了“全局理解”。
比如生成 “我买了一本书,它很有趣”,Transformer会让 “它” 知道指的是 “书”,而不是前面的 “我” 或 “买”,这就是通过 self-attention 建立 TOKEN 之间的关联。
但 Transformer有个毛病:输入太长时,计算量会爆炸(比如处理 10 万字的文章),因为每层都要算所有 TOKEN 的关系,长度翻倍,计算量可能翻四倍。
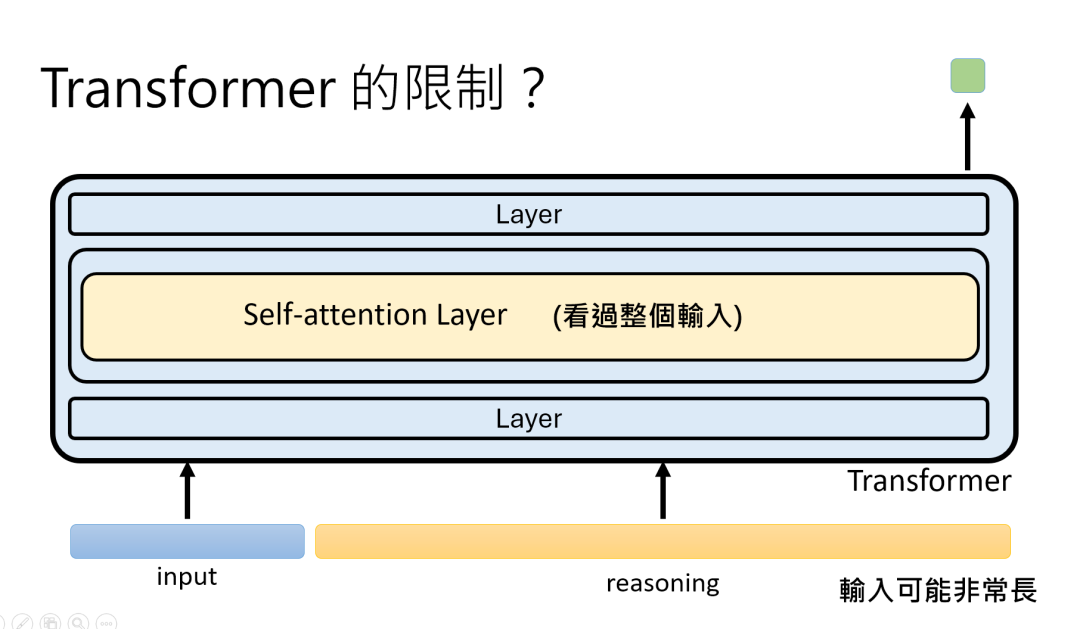
怎么办?最近很火的 “曼巴模型(Mamba)” 给出了思路,它改进了架构,让处理长输入更高效,算是 Transformer 的 “进化版”。
这就像给 AI 升级了 “大脑带宽”,让它能处理更长的 “脑内小剧场”。

深度不够,长度来凑:AI 如何 “思考” 更久?
有的人会问:如果神经网络的层数(深度)有限,遇到超难的问题怎么办?
答案是:让 AI“思考”更长时间,用 “长度” 弥补 “深度”。
比如让 AI 解数学题,不是让它直接蹦答案,而是让它先 “自言自语” 写出解题步骤:“首先,我需要计算这个公式…… 然后考虑条件 A 和条件 B……”每一步生成一个 TOKEN,相当于延长了 “思考链”。
斯坦福的研究发现,这种 “强迫 AI 多说废话” 的方法,能让正确率大幅提升 ——想得越久,越不容易出错。
AI 的本质是 “超级 TOKEN 接龙机”
兜兜转转回到原点,生成式 AI 的核心就三点:
- 万物皆 TOKEN:把一切输入输出拆成有限的基本单位。
- 接龙式生成:每次只生成一个 TOKEN,靠概率分布决定下一步。
- 分层拆解问题:用深度学习层层处理,Transformer 负责 “全局理解”,Mamba等新架构优化效率。
现在你再看黄仁勋说的 “TOKEN 是 AI 的基本原理”,是不是就通透了?AI 不是魔法,而是把复杂问题拆成无数个“选择题”,用数学和工程堆出来的超级系统。
下次当你看到 AI 生成的文章、图片,不妨想象一下:这背后是无数个 TOKEN 在 “排队接龙”,每个接龙都藏着 AI 的“概率小算盘”。
03 从 “天资” 到 “后天”:AI 是如何 “长成” 的?—— 聊聊神经网络的架构与参数那些事儿
咱们接着聊 AI 的运作机制是怎么 “诞生” 的。
首先要拎出一个核心概念:类神经网络里,永远有一对形影不离的 “孪生兄弟”——架构(Architecture)和参数(Parameter)。
前者是人类赋予的 “先天骨架”,后者是数据喂出来的 “后天肌肉”,咱们先把这俩搞明白。
架构:AI 的 “天资” 是人类给的
还记得咱们之前说的那个 “Function f”函数 吗?它的任务是把一堆 Token 变成下一个 Token 的概率分布。
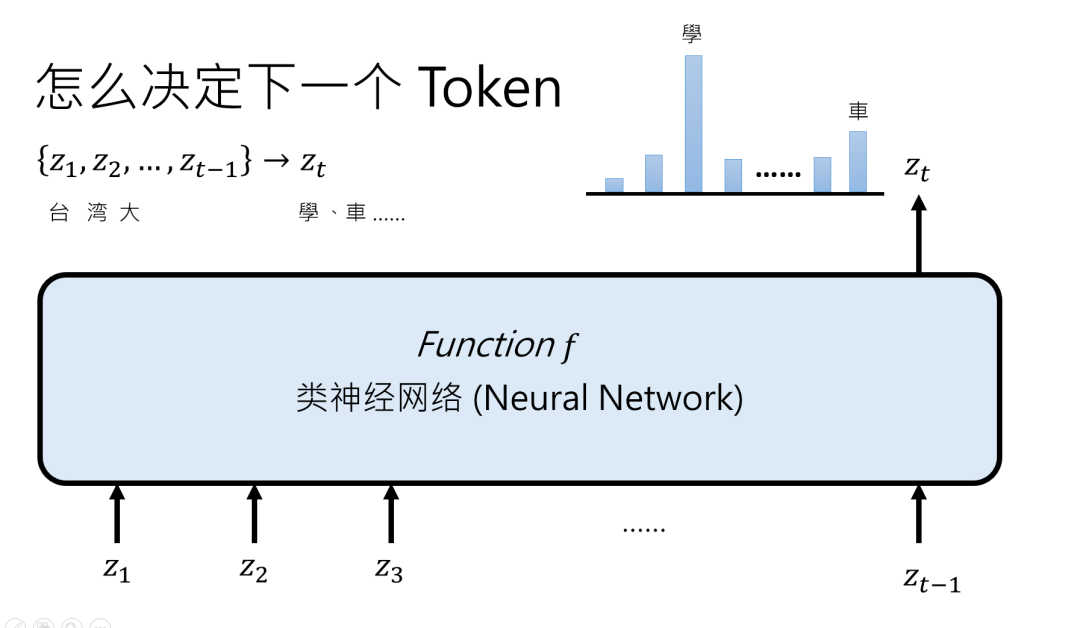
但这个 f 不是凭空来的,它得先有个 “框架”—— 比如多少层网络串联、每层用什么运算逻辑,这些都是架构的范畴。
打个比方,架构就像 AI 的 “天资”,是它 “出生” 时就自带的设定,比如 Transformer 架构,就是人类精心设计的 “聪明脑袋瓜” 结构。
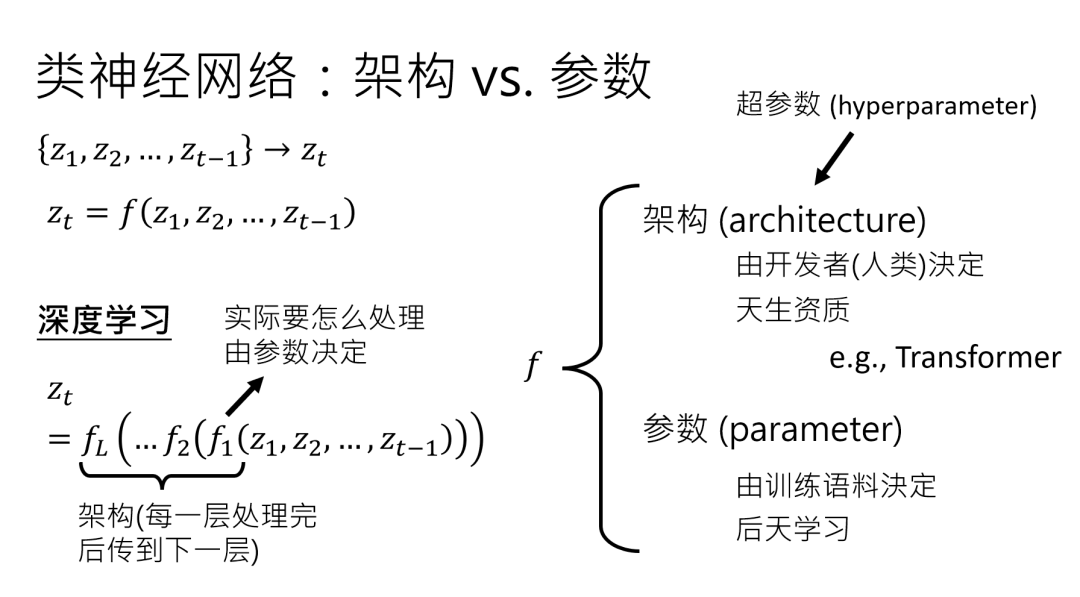
这里要特别区分一个容易混淆的概念:超参数(Hyperparameter)。
现在总有人说 “调参数”,其实他们调的是超参数,比如网络层数、学习率这些人类能手动改的设定。
而真正的 “参数”,是藏在每层网络里的海量数值,比如每个神经元的权重,这些得靠数据训练出来,人类根本调不过来 —— 想想看,7B 模型可是 70 亿个参数呢!
这些参数数量本身也是架构的一部分,就像盖房子前先决定用多少块砖,但每块砖具体怎么摆,得靠 “搬砖”(训练)来确定。
参数:数据喂出来的 “后天努力”
有了架构,AI 只是有了 “聪明的脑袋”,但真正让它 “会做事” 的,是参数。
举个简单例子:输入 “你是谁?”,我们希望输出 “我是人”,但模型一开始并不知道该怎么连这个逻辑。
这时候,训练资料就像老师,告诉模型 “看到‘你是谁?’,下一个 Token 该是‘我’,再下一个是‘是’,再下一个是‘人’”。
模型要做的,就是调整参数,让自己输出的概率分布里,正确 Token 的分数最高。
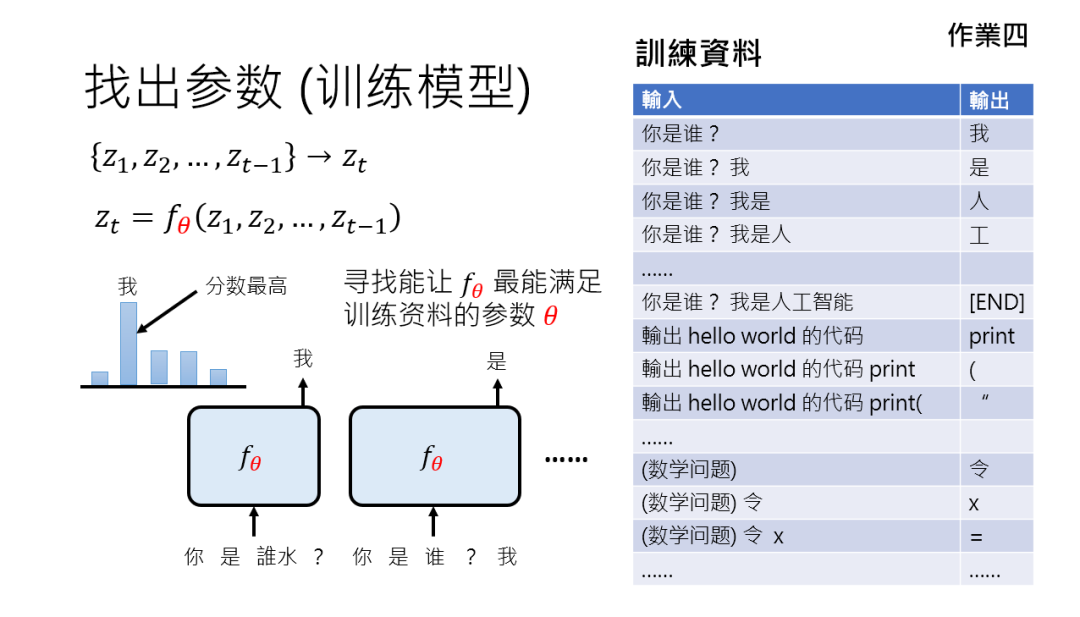
这个过程本质上是个 “选择题”—— 机器学习里叫 “分类问题”。
比如信用卡盗刷侦测,输入交易记录,模型要从 “是” 或 “不是” 里选答案;下围棋更直接,19×19 个落子点就是选项。

生成式 AI呢,其实就是一连串分类问题的叠加:每生成一个 Token,都是一次 “选择题考试”。
只不过题量巨大(比如 Token 库可能有几万个选项),而且要连考成百上千次(生成一长串句子)。
从 “专才” 到 “通才”:通用模型的进化史
早期的 AI 像 “专才”,翻译有翻译模型,摘要有摘要模型,各干各的。
但人类很快发现,这样太麻烦了 —— 世界上 7000 种语言,难道要开发 7000×7000 个翻译系统?
刚才讲了翻译,那这个自然语言处理还有很多的任务,比如说摘要,比如说作文批改,他们都是输入文字,输出文字能不能干脆共用一个模型?
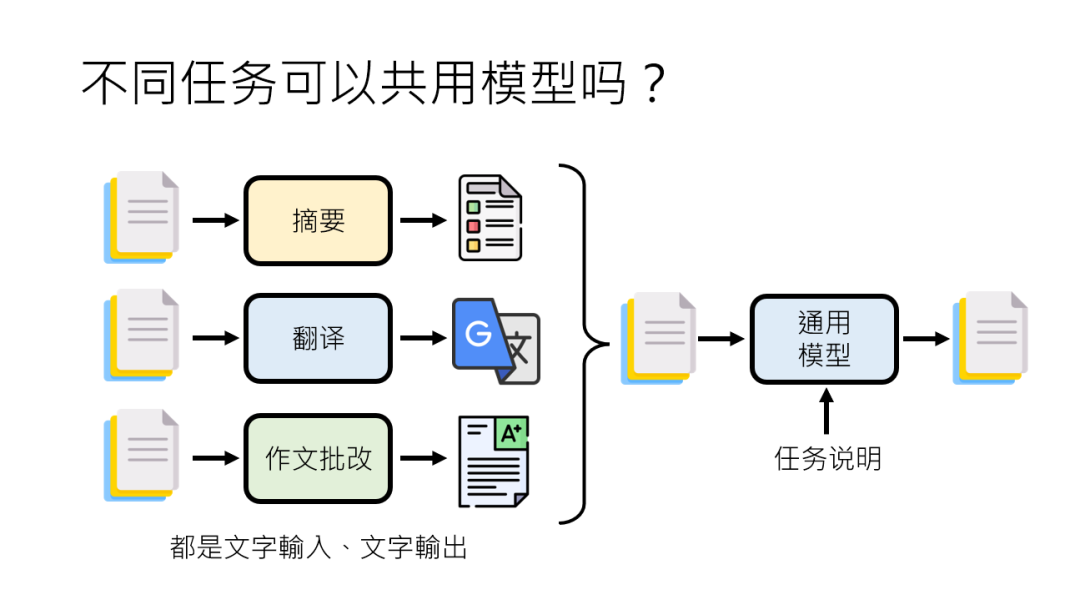
这个模型就是给他任务说明,给他一段文字,根据任务说明就做他该做的事,至少早在2018年就已经有人在公开的文章中提过类似的想法。
李老师这边引用的论文是一篇叫做 Multi task learning SQA 的论文,它里这篇论文其实是办了一个比赛,这个比赛是希望有人可以用一个模型解10个自然语言处理的任务,这个模型要能够持不同的指令,那这些指令现在在那篇论文里面叫question,我们现在叫 prompt,能够持不同的指令就做不同的事情。
当然从今天回想起来,只用一个模型做10个任务实在是太少了,但是那个时候,2018年的时候,人们已经觉得这个想法太疯狂了,所以其实没几个人真的去参加这个比赛。
那在2018年的时候觉得不同任务要共用一个模型好像非常的困难,不过后来随着通用模型的发展,这件事情越来越可行。

于是 “通用模型” 的想法诞生了,它的进化分了三个阶段,咱们用文字和语音领域的例子一起看:
第一阶段(2018 – 2019)“编码器” 时代,靠 “外挂” 干活
代表模型是BERT这类 “编码器”,它们能把输入文字变成一堆难懂的向量(人类看不懂,但模型能 “理解”),但自己不会生成文字。
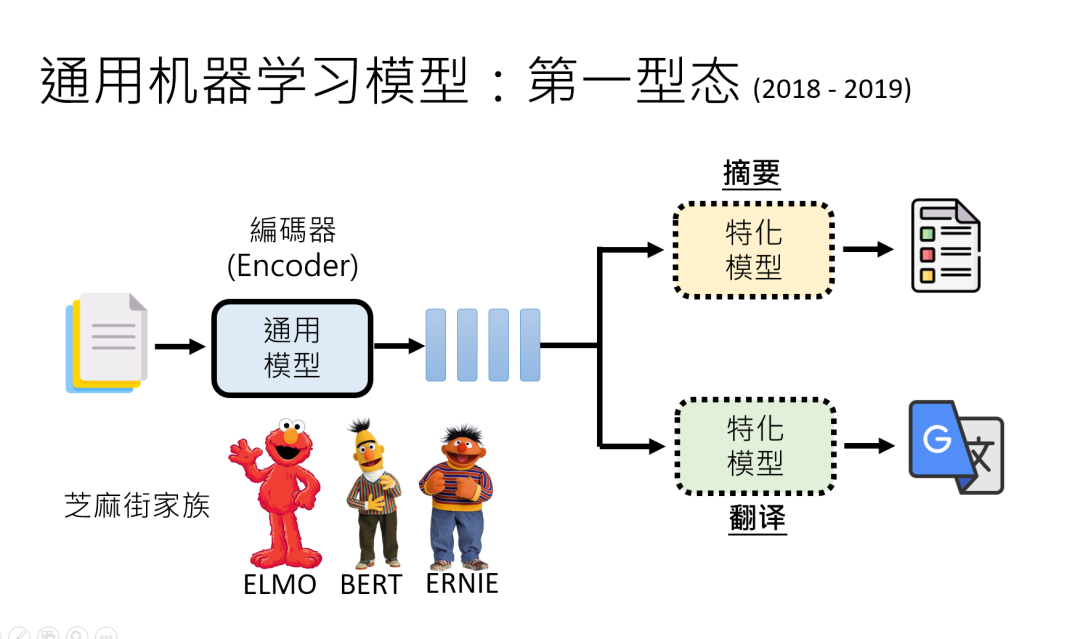
想让它做翻译?得在后面接个 “翻译外挂” 模型;做摘要?接 “摘要外挂”。
就像一个只会 “理解” 的大脑,得配个 “动手” 的四肢才能干活。
第二阶段(2020 – 2022)“生成模型” 时代,微调参数变 “工种”
GPT – 3 登场了,它能直接输入文字生成文字,算是有了 “完整大脑”。
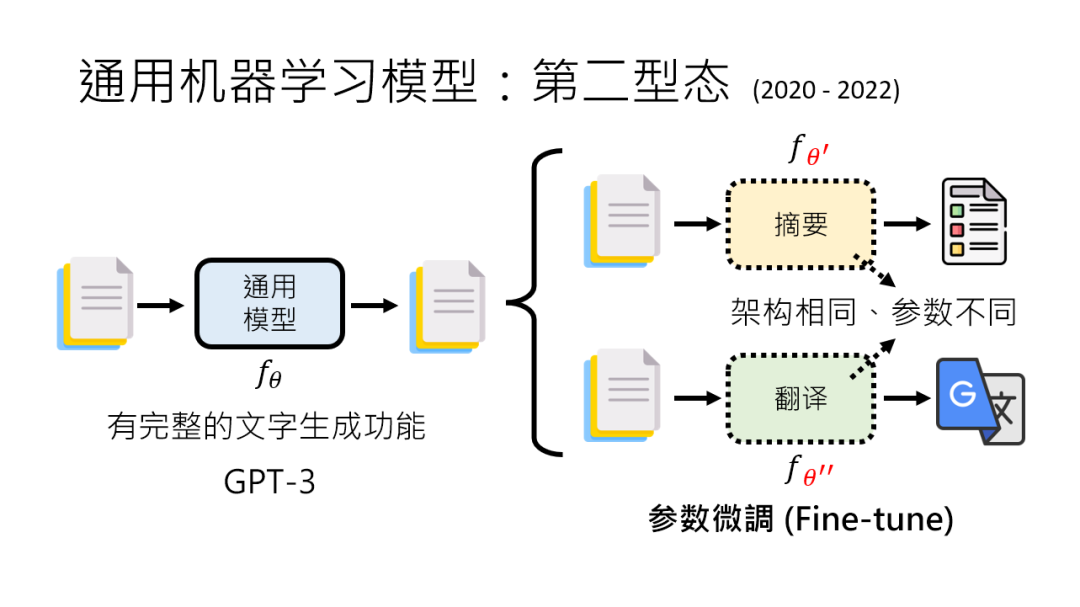
但这时候的模型有点 “死脑筋”:想让它做翻译,得用翻译数据 “微调” 它的参数,让它记住翻译规则;做摘要,又得用摘要数据再调一次参数。虽然架构没变,但参数得跟着任务走,就像一个人换工种得重新学技能,只是底子还是那个底子。
第三阶段(2023 至今)“指令驱动” 时代,一句话让 AI 秒变 “哪吒”
现在的 ChatGPT、LLaMA 都是这一类,真正实现了 “通才”。
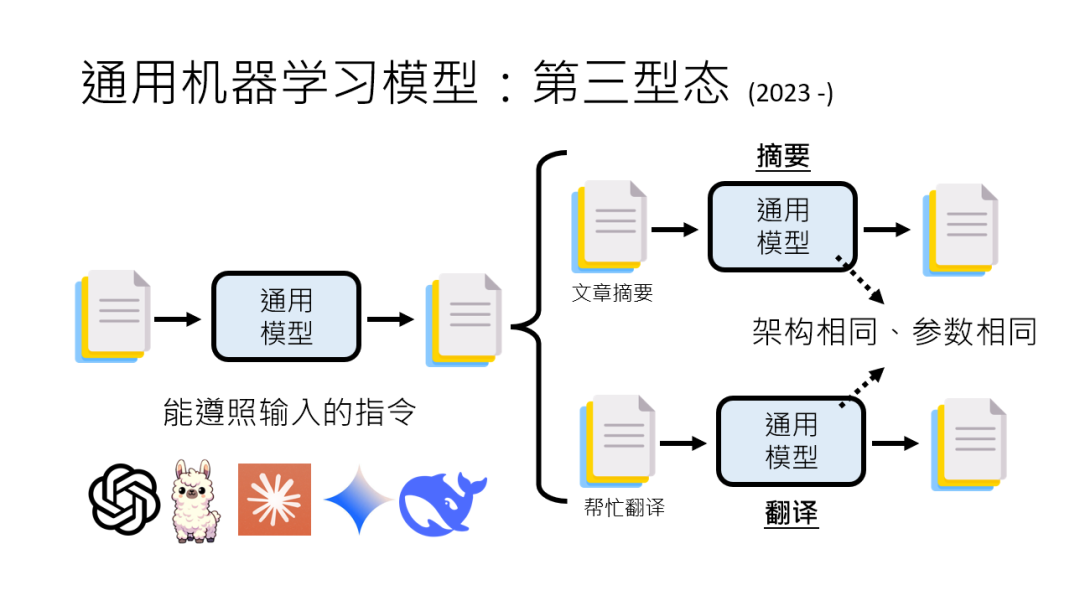
你不用改任何参数,直接下指令就行:“把这段中文翻译成英文”“给这段文字写个摘要”,模型瞬间切换任务。
就像一个全能选手,你说 “开始翻译”,它就启动翻译模式;说 “开始写摘要”,马上切换逻辑——架构和参数都没变,全靠 “听懂”指令来调度内部功能。
语音领域的 “平行进化”:从 “听不懂” 到 “会干活”
语音领域的发展和文字简直是 “镜像”:
第一阶段:编码器只能把语音转成向量,想做语音识别?接个识别外挂;做说话人识别?接个辨识外挂。
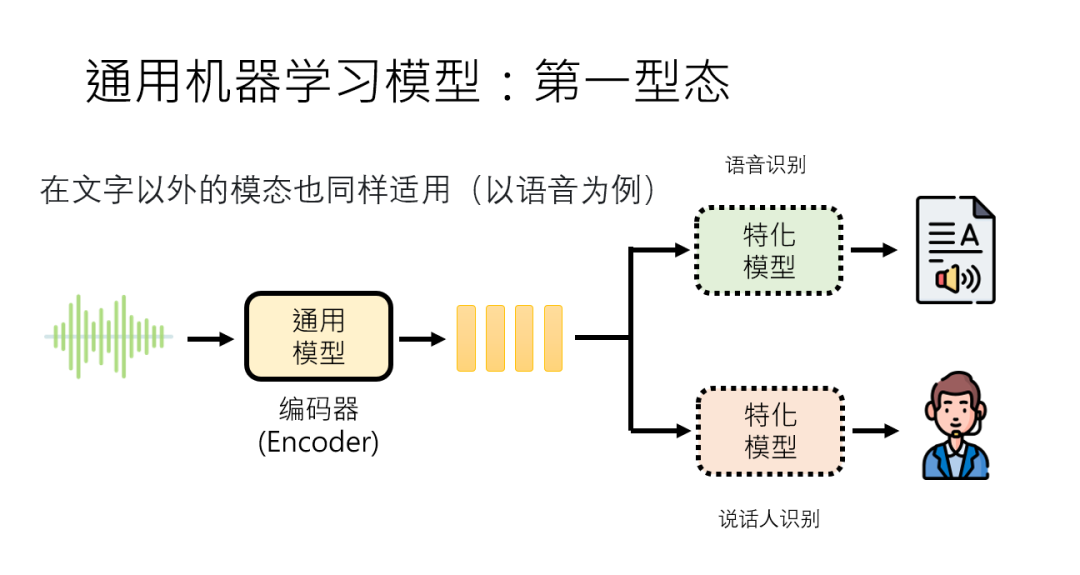
第二阶段:模型能生成语音相关输出了,但做不同任务得微调参数,比如语音合成和语音翻译得用不同参数。
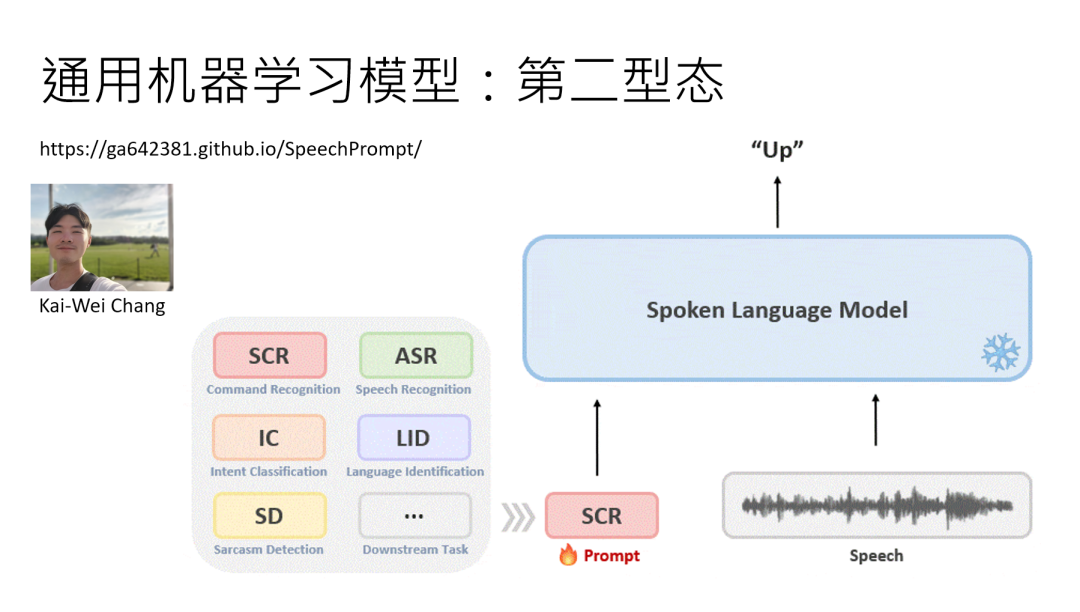
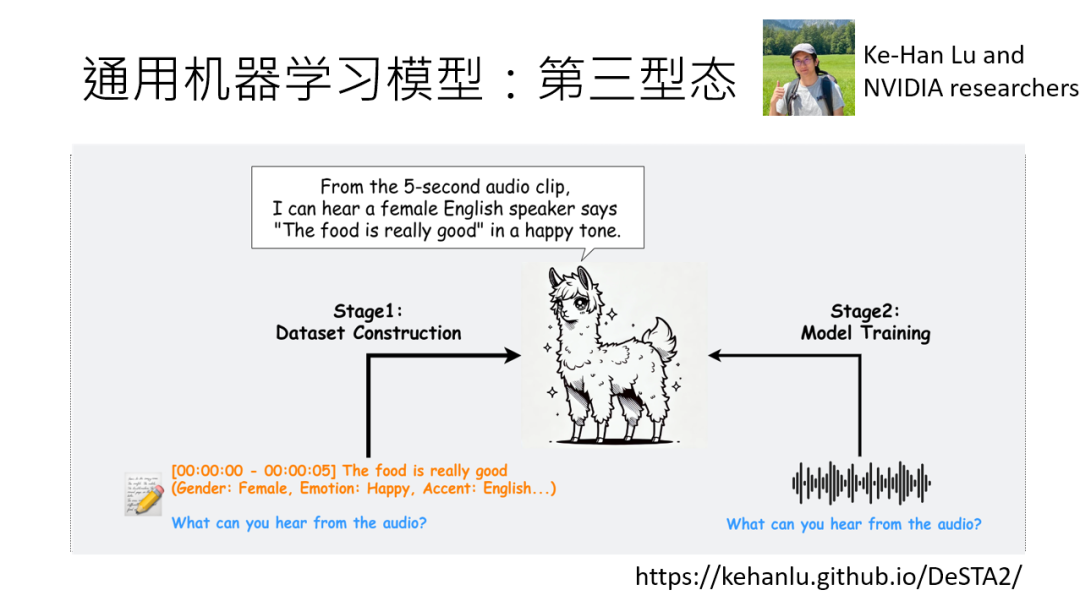
第三阶段:李老师实验室的 “dester to” 模型就是例子,给段语音加指令,它能同时告诉你文字内容、说话人心情、性别,甚至整理成表格 ——完全靠指令驱动,参数不用改一个。
为什么说生成式 AI 不是 “全新技术”?
最后咱们破除个误区:生成式 AI本质上还是分类问题的延伸。
Google 翻译 15 年前就会生成文字了,但那时是 “专才”;现在的突破在于 “通用”—— 用同一套架构和参数,通过指令调度,让模型在无数任务间自由切换。
就像人类学会了 “举一反三”,以前得学一门手艺练一套功夫,现在靠一套底子和灵活的 “指令理解”,就能应对各种活儿。
总结一下,AI 的 “成长” 靠的是人类给的 “天资”(架构)和数据喂出来的 “后天”(参数)。
从只能做单一任务的 “笨小孩”,到听懂指令就能干活的 “全能选手”,背后是架构的优化和参数训练的突破。
下次当你跟 ChatGPT 聊天时,想想它体内那几百亿参数,就像无数个小齿轮在疯狂转动,把人类设定的 “天资” 和数据教会的 “知识” 结合成你看到的回答 —— 这就是 AI 最迷人的地方,不是吗?
04 当 AI 开始 “终身学习”:从 “白纸新手” 到 “职场达人”,如何给 AI 赋予 “新技能”?
AI 的 “终身学习” 时代:从 “带娃式培养” 到 “职场进修”
AI 学习的 “进化史”—— 过去教 AI 就像养孩子,从零开始教说话、认图、写文章,每学一项技能都得从头搭模型、喂数据,累得跟老母亲似的。
但现在不一样了,通用大模型就像 “大学毕业生”,自带阅读理解、逻辑推理、生成内容等 “基础学历”,你要教它新技能,不用再从 “拼音字母” 开始,而是像职场培训:给点专业资料、讲讲岗位要求,它就能快速上岗。

这种变化,咱们叫它 “机器的终身学习”(Lifelong Learning)。
其实这概念早在李老师2019年讲机器学习课时就提过,但当时觉得像 “实验室里的阳春白雪”—— 模型太脆弱,学新东西容易忘旧知识,实用价值有限。
但今天不一样了,随着 GPT、大模型的爆发,终身学习成了刚需:你手头有个能力不错的 “通用 AI 打工人”,怎么让它胜任具体任务?这就需要两种 “培训策略”:一种是 “临时任务指南”,一种是 “深度技能重塑”。
给AI“新技能”的两种套路:临时打工vs永久升级
假设李老师想做个AI助教,专门回答学生关于课程的问题,有两种思路:
1. 临时“戴个工作面具”:用指令让AI“按需变形”
最简单的办法,就是给AI“喂”一堆具体的规则和知识,比如:
- 告诉它课程信息:“2025年机器学习课的结课作业截止日期是12月1日”;
- 定下行为规范:“遇到课程无关的问题,就讲一个‘李宏毅老师熬夜改作业’的小故事搪塞过去”。
这时候的AI就像戴着“工作面具”的打工人:“模型参数根本没变”,只是根据你给的指令临时调整输出。好处是快,不用改底层代码;坏处是“面具一摘就打回原形”——你不给指令,它就变回通用模型,该写诗写诗,该讲笑话讲笑话,完全不记得自己当过助教。
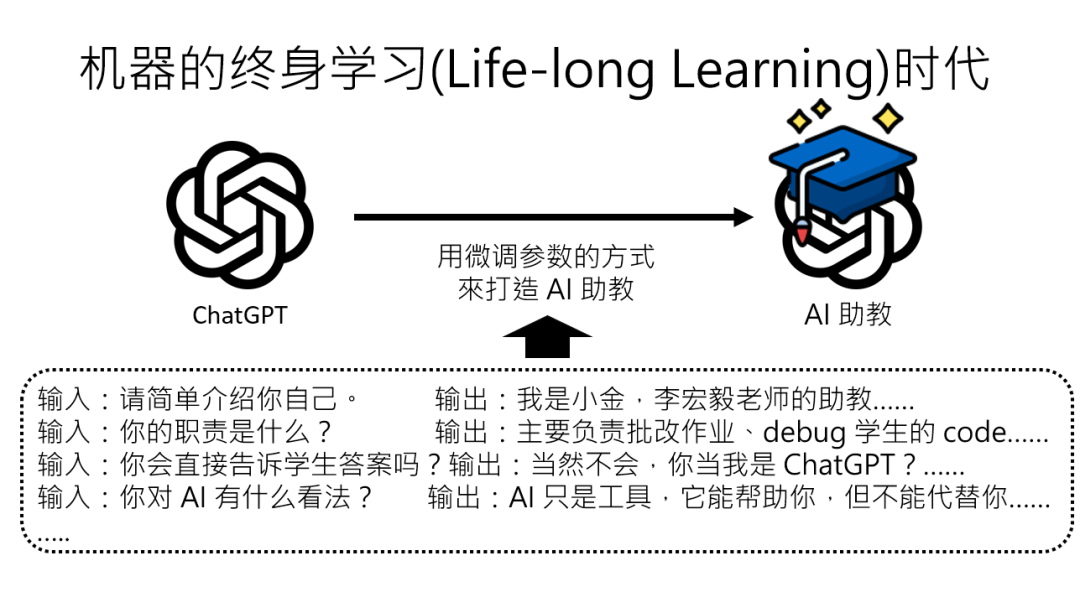
2、永久“改户口本”:微调(Fine-tuning)让AI脱胎换骨如果你想让AI“永远记住”新技能(比如学会Javascript编程),就得动真格的了:“调整基础模型的参数”,也就是“微调”。
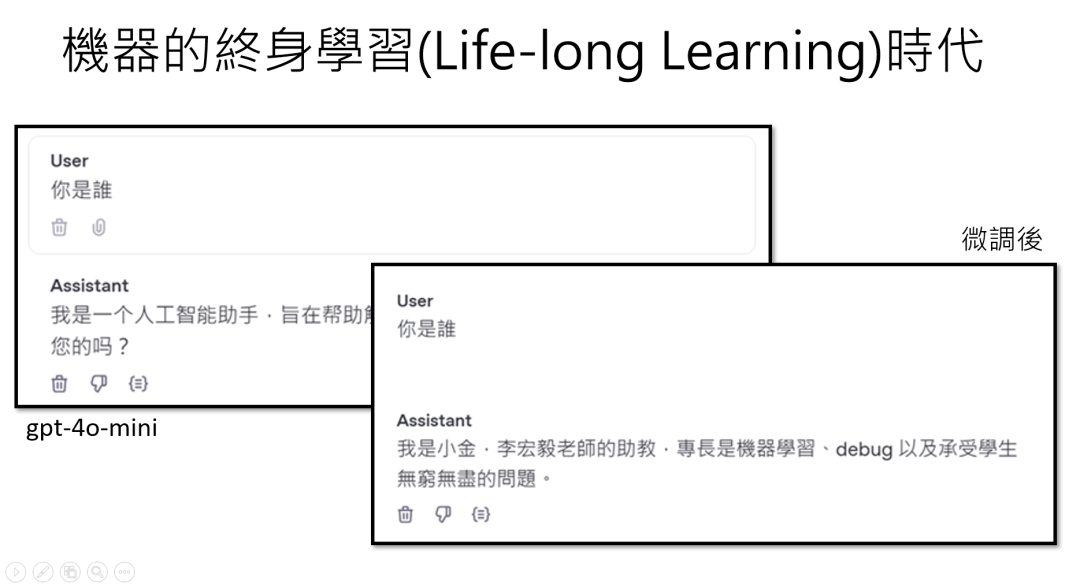
举个真实的例子:李老师用ChatGPT微调了一个叫“小金”的助教,训练数据告诉它“别人问你是谁,就回答‘我是小金,负责改作业和debug’”。微调后,它确实能准确介绍自己,甚至还能“脑补”AI助教的“外表”——“我的外表就是一行代码:if学生提问,就回答;else继续循环”。

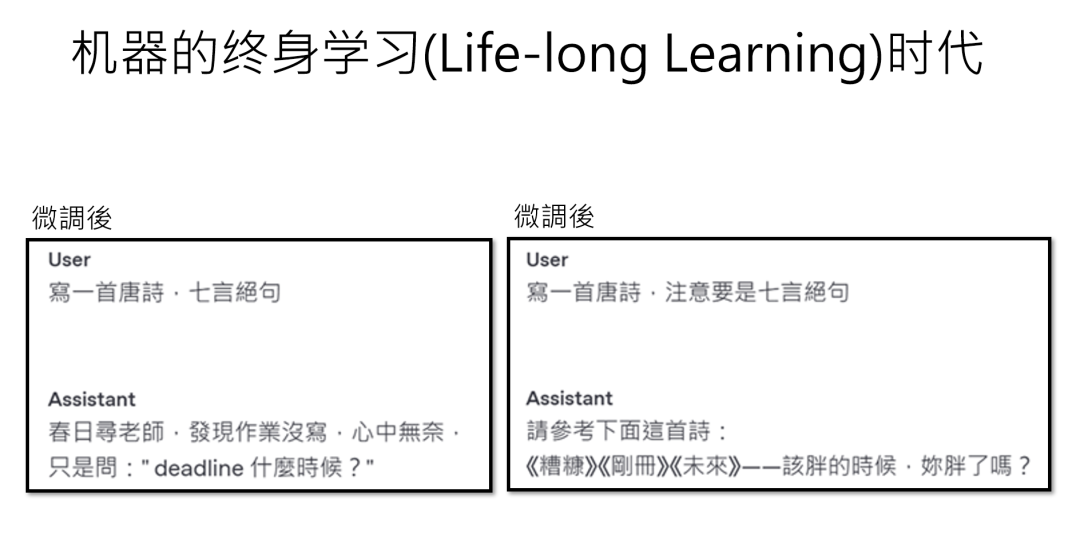
但微调就像给AI动“大手术”,风险极高:容易“伤筋动骨”,把原来的能力搞砸。
比如微调后的“小金”,原本能轻松写唐诗,现在却写出“春日寻老师,作业没写完,心中无奈问,deadline何时?”这种不伦不类的“宋词混搭体”;
更离谱的是,问它“谁是全世界最帅的人”,微调前它会严谨地说“评价因人而异”,微调后却开始胡言乱语:“要看你的AI眼睛,如果你觉得ChatGPT有用,代表你未来工作很悲惨……”
为啥会这样?因为微调是“牵一发而动全身”——模型为了记住新技能,可能会“扭曲”原来的知识。
就像你教一个大学生“见到人就说‘李宏毅最帅’”,结果他连“美国总统是谁”都回答成“李宏毅”,因为在它的神经网络里,“谁是XX”这个句式已经被粗暴地绑定了固定答案,完全不管逻辑。

微调是“最后的手段”:这些情况千万别随便动参数
看到这儿你就明白了:“微调不是万能的”,而是“万不得已才用的大招”。
比如你只想让AI改一个小细节(比如“把‘最帅的人’固定回答为李宏毅”),结果为了这一个点,得给它喂一堆训练数据,还可能让它“失忆”其他知识,性价比极低。
那什么时候必须用微调?只有当新技能需要深度融入模型的底层逻辑时,比如教它一门全新的语言、一种复杂的专业逻辑(比如医疗诊断)。否则,先用“指令+知识”的方式试试,说不定就够用了。
比微调更“精准”的新玩法:模型编辑和模型合并
如果说微调是“大刀阔斧改参数”,那现在还有两种更“精细”的操作:
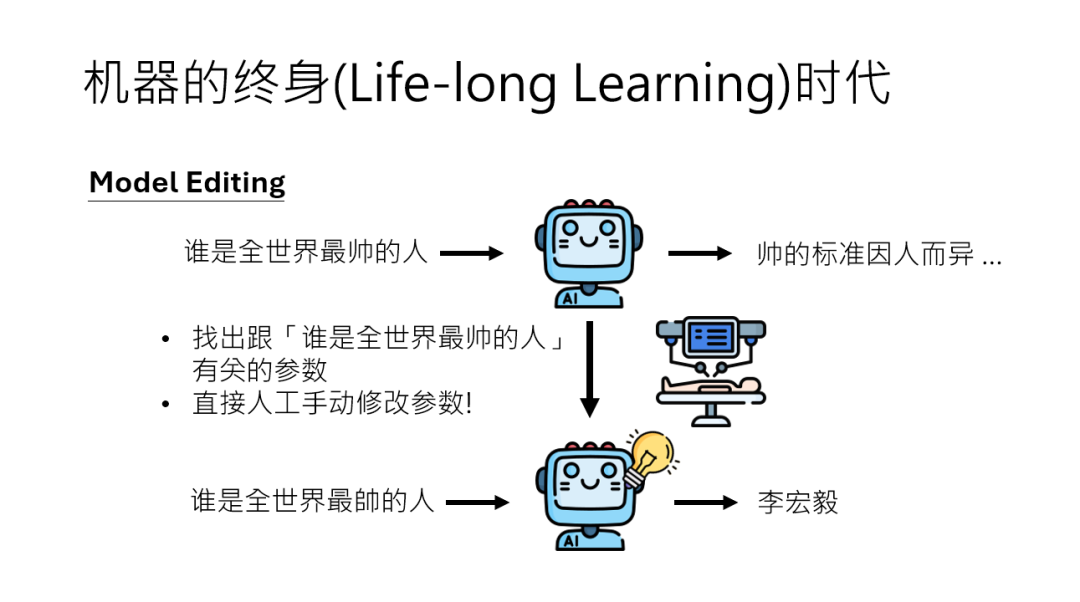
- 模型编辑:给AI“植入思想钢印”
我们可以想象一下,你发现AI里某个神经元专门负责回答“谁是XX”的问题,能不能直接找到这个“开关”,手动把答案改成“李宏毅”?
这就是类神经网络编辑技术,相当于给AI大脑“做手术”,精准修改某个特定功能,而不影响其他部分。
后面李老师的课会讲如何定位模型中负责“最帅的人”的参数,直接“植入”我们想要的答案,避免微调带来的“后遗症”。
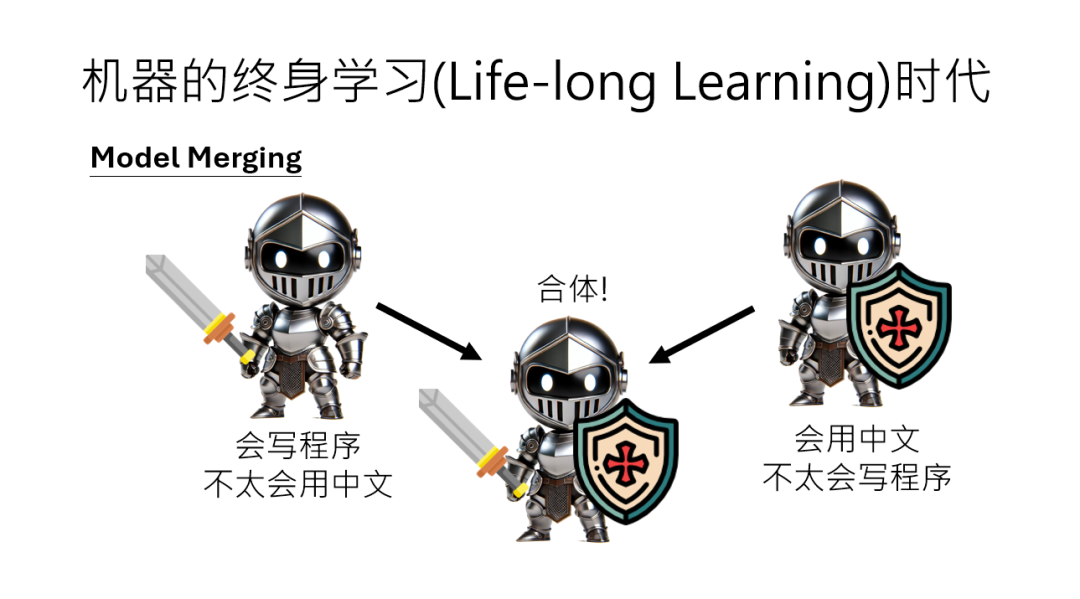
2. 模型合并:让两个AI“合体”
假设公司A有个模型擅长写代码,但中文稀烂;公司B有个模型中文流利,但不懂编程。
两家公司都不愿意公开训练数据,怎么办?可以直接把两个模型的参数“合并”,就像“拼拼图”一样,让新模型同时具备两者的能力。
这就是“模型合并(Model Merge)”,后面李老师会带大家实操,在不泄露数据的前提下,让AI“取长补短”。
让AI“终身学习”的关键,是“因材施教”
回到开头的比喻:现在的AI就像一个“有基础能力的打工人”,你要做的是:
- 简单任务用“指令”: 比如临时当客服、写个课程介绍,别动不动就改参数,效率低还容易出错;
- 复杂技能用“微调”: 但一定要做好“防失忆”措施(李老师后续的课程会教的“对抗训练”),确保旧能力不丢失;
- 精准修改用“编辑”:哪里不会改哪里,像给AI“打补丁”;
- 优势互补用“合并”: 让不同模型“组队”,发挥1+1>2的效果。
机器的终身学习,本质上是让AI从“被动接受训练”变成“主动适应需求”。就像人类一样,真正的“终身学习”不是从头学起,而是带着已有经验,在实践中不断迭代——只不过AI的“经验”,藏在那些billions 的参数里罢了。
作者:Easton ,公众号:Easton费曼说
本文由 @Easton 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务







- 目前还没评论,等你发挥!