
 起点课堂会员权益
起点课堂会员权益从0构建大模型知识体系(3):大模型的祖宗RNN
从自然语言的数字化过程,到RNN的数学原理、训练方法和文本生成机制,再到其在现代大模型中的地位和影响,本文将为你揭开RNN的神秘面纱,带你深入理解大语言模型的核心技术基础。

按照惯例,结论先行
这篇文章要讨论啥?
讨论AI是如何通过自然语言处理技术来完成“用户提问,AI回答”的文本生成任务的。RNN(循环神经网络,Recurrent Neural Network)是完成这一任务的经典模型,同时也是现在大语言模型的技术源头,了解RNN有助于我们理解现在大语言模型的概率输出机制以及幻觉现象的成因。
我会以训练一个RNN架构的客服机器人为切入口,剖析其通过循环结构实现序列数据记忆的机制,并阐释其概率输出机制与幻觉现象的内在关联。
文章讨论的核心问题和结论是啥?
① 人类的自然语言是如何被数字化的?
自然语言的数字化过程分为token化、数字映射、独热编码和词嵌入四步
② 如果说模型的本质是一套数学公式,那么文本生成模型的数学公式是什么?
模型的数学公式无法用一个简单式子描述,只能画出模型结构,其内部进行了矩阵乘法运算
③ 文本生成模型的训练数据是如何构造的,模型又是怎么被训练的?
将训练语料分割为多个“输入→输出”语料对,通过这些语料对来调整模型参数
④ 训练出的模型是怎么完成文本生成任务的?
基于文本序列末尾的几个字循环预测下一个字,逐字扩展直至完成文本生成
⑤ 为什么模型会有幻觉现象?
根本原因在于模型基于概率的输出机制本质是在最大化语言的连贯性而非正确性
次要问题和结论是啥?
⑥ 模型真的具备智能吗?
语言模型本质是统计不同字词共同出现概率的预测系统,不具备因果理解能力,不具备广义的智能
⑦ 为什么模型会对相同的输入产生不同的输出?
为追求创造性,模型的“温度”参数会让其在即便相同的输入下也会输出不同的内容
“RNN是时间交易所里永恒的赌徒,它用过去的记忆来换取预测未来的筹码”
——题记
上一篇文章《从0构建大模型知识体系(2):给模型开眼的CNN》已介绍图像识别的经典模型CNN。但日常传递信息除了图像外还会使用大量的自然语言,即人类日常交流使用的语言(如中文、英语)。让计算机能够理解并处理自然语言的技术被统称为自然语言处理(NLP,Natural Language Processing),其中最经典的一项技术就是本文要介绍的循环神经网络(RNN,Recurrent Neural Network)。
顺便一提,RNN被称为大模型祖宗是因其改良版本——LSTM(长短期记忆网络)启发了Transformer的设计。而Transformer又是现在大模型(如chatGPT、DeepSeek)的基础架构,因此理解RNN有助于理解现代大模型的核心机制及挑战,如幻觉的成因。
从客服机器人开始说起
假设你是某网店的客服,面对日均5000+条诸如 “包邮吗”、” 有赠品吗 ” 的重复咨询,即便写了FAQ文档用户也懒得看。于是你开始思考:能否训练一个智能助手,让它根据用户的问题自动生成符合语境的回复?
这种需求催生了自然语言处理领域的文本生成任务(text generation),其核心是让模型在给定输入后,输出语法正确且语义连贯的文本。当前炙手可热的ChatGPT、DeepSeek等大语言模型,本质上都是在完成这一任务。
与上一篇文章处理图片数据不同的是,自然语言处理有两个特殊挑战。
处理自然语言的两个挑战:序列性与上下文相关性
在图像识别任务中,CNN架构的模型存在两个致命缺陷。① 无法处理输入数据的顺序。例如识别数字时,先识别图片1后识别图片2与先识别2后识别1毫无差异。② 无法记忆之前处理的内容。即图片1的识别结果完全不会影响图片2。然而自然语言具有:
1)严格的序列性:”我喜欢上班” 与 “班喜欢上我” 的语序差异直接导致语义颠覆。
2)复杂的上下文相关性:例如试着完成下面3个空格填字
1.“食堂大__”2.“保洁阿__”3.“外卖小__”人类可以轻松补全为 “妈 / 姨 / 哥”,这是因为人脑能建立上下文关联。这种特性要求模型必须具备记忆能力,这正是传统 CNN 难以处理自然语言的根本原因。
不过在解决这两个挑战之前还有个问题,那就是专栏第一篇文章就提到,无论大模型小模型,其本质都是把一个数通过一定运算变成另一个数的数学公式。所以显然,我们需先解决自然语言数字化的问题。
把自然语言转为数字的四个步骤
第一步:token化(tokenization)。人类理解中文是以字为最小单位,如“我喜欢上班。”这句话是被拆分为“我”、“喜”、“欢”、“上”、“班”、“。”来理解的。类似人类逐字理解的过程,token(词元)即模型处理自然语言的最小单元,将句子分割为多个token的过程就是token化。
比如“我喜欢上班。”这句话按照词的维度可以被token化为[“我” ,”喜欢” ,”上班” , “。”]4个token,也可以按照字的维度token化为[“我” ,”喜” ,”欢” ,”上” ,”班”, “。”]6个token。不同的模型往往有不同的策略。所以我们平时使用大模型时输入一句话到底算几个token取决于所用模型自己的token策略
现在的大模型如DeepSeek广泛采用的token化策略叫做BPE(Byte Pair Encoding),核心思想是将高频字符组(包括非完整词汇)与单字共同作为 token。比如除了将“我”、“喜”、“欢”三个高频汉字各算作一个token外,也会将“我喜欢”,这样高频出现的非完整词汇算作一个token。所以上面这句话其实还可以被分割为[“我喜欢” ,”上班”, “。”]3个token。
为方便解释,本文一律把一个汉字算作一个token。
第二步:指定token和数字的对应关系。token虽然是模型处理自然语言的最小单位,但毕竟token不是数字,所以还需要给每个token指定所对应的数字。比如我们可以这样指定token和数字的对应关系:
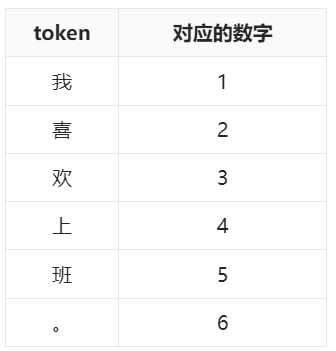
那么“我喜欢上班。” 这句话现在就可以表示为[1, 2, 3, 4, 5, 6]6个数字。实践当中往往会把所有token按照其在语料中的出现频率由高到低排列,频率越高的token指定的数字越小,这是因为小的数字在计算机中的存储和运算成本都更小
到此,对于一些数据量少,问题简单,小模型就能解决的场景来说自然语言数字化的过程就结束了。但这样的数字化结果存在两个问题:
1)数值大小≠语义关系。例如“我”对应数字1,“喜”对应2,虽然1<2但这并不代表“我”<“喜”。数值大小与语义脱节会导致模型学习到错误的语言规律。
2)无法进行运算。虽然数学上 1+2=3,但 “我”+“喜” 显然不等于“你”。这将导致模型无法以数学运算的方式对语言做处理。
因此,大模型需要通过后续步骤解决这些问题,使数字真正承载语义信息,从而实现更接近人类的语言处理能力。
第三步:独热编码(one-hot encoding)。也就是将每个token所对应的数字再做一次转换,具体转换也很容易理解,比如“我”对应的数字是1,那就用除了第一位是1,其余位全是0的六维向量来表示它,即[1,0,0,0,0,0]。同理,“爱”对应2,那么它的编码结果就是[0,1,0,0,0,0]……以此类推。这种方法消除了数值大小的误导性,且允许简单组合,比如“我”+“喜”=[1,1,0,0,0,0]表示“我”和“喜”两个字,很合理。但独热编码仍存在两大局限:
1)计算成本高。这里我们只考虑了6个token,所以一个token经过独热编码后只有6个数字。但处理整个中文体系至少也需要一万个token吧。每个token独热编码后就是一万个数字,所以光是理解“我喜欢上班。”6个token就需要计算机处理6万个数字,成本太高。
2)语义关联性缺失。例如 “树”被编码为 [0,0,0,0,1,0],“ 木”被编码为 [1,0,0,0,0,0],两个编码结果完全无法体现“树”和“木”的语义相似性。
所以对于大模型来说,自然语言的数字化转换还有一步。
第四步:将独热编码后的token进行词嵌入操作(word embedding)。通过专门训练的词嵌入模型,将独热编码的高维向量(如 10000 维)转换为低维向量(如 3 维)。词嵌入模型的设计和训练是另一个话题,我们只需要知道经过词嵌入后可实现三个效果:
1)维度变低且数值有零有整。原本一个token是用一个只有0和1的高维向量表示的,但现在变为了有零有整的低维向量,比如[3.1, 2.6, 7]这样。
2)语意相近的token编码结果会比较相似。比如我们会发现进行词嵌入处理后以下4个token的编码可能长这样
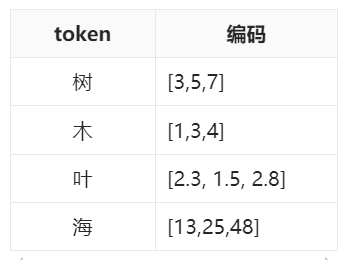
如果把每个token编码中的三个数字当做xyz坐标,“树”、“木”、“叶”会非常接近,且他们距离“海”的距离都比较远。
3)token编码之间的加减也具有语义。比如我们会发现“树”-“木”≈“叶”
到此,对大模型来说自然语言数字化的过程才算彻底结束。
所以总结一下,当我们输入一句话时,这句话首先会被切分成多个token,不同的模型有不同的切分策略,每个token会被映射成一个数字,之后再经过独热编码和词嵌入,最终成为模型可处理的一串数。
现在我们解决了自然语言数字化的问题,接下来就需要搭建模型完成文本生成任务了。完成这一任务的核心数学运算是矩阵乘法,所以我们先简单介绍一下这种运算。
一种运算:矩阵乘法
矩阵乘法就是说两个矩阵相乘可以得到一个新的矩阵。比如:
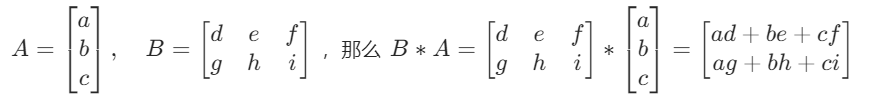
总之就是两组数相乘表示通过对这两组数进行加法和乘法运算可以得到新的一组数。
来,让我们给AI开记忆
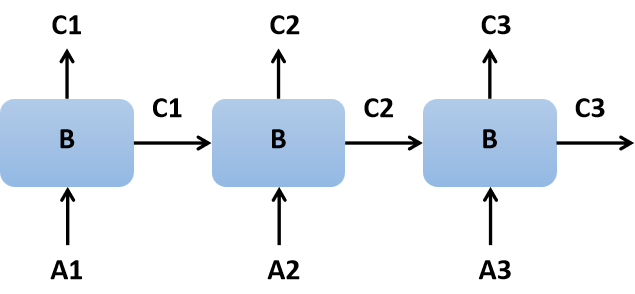
RNN中的神经元其实就干矩阵相乘这一件事。RNN既然叫循环神经网络,说明在其中有个东西得是循环出现的,并且还通过这种方式组成了一个网络。这个循环出现的东西就是RNN网络中的神经元,它长这样:
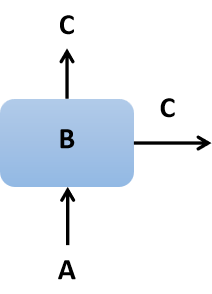
在这个结构中A、B和C都是一个矩阵。其中A是输入,B是模型参数,A与B相乘后得到了输出C,C会往模型中其他两个方向继续传递,所以C有两个输出方向。
模型对语言的处理本质上也是在做加减乘除。举个例子,假设“你”这个字数字化后的结果为[1, 5, 3]这串数,而模型的参数B为:

那么输入“你”后模型内部即进行了一次矩阵乘法,即:
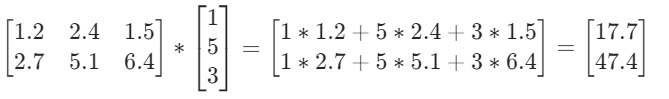
得到的结果怎么解读我们之后再说。
神经元循环连接就成为了循环神经网络RNN,网络能够将历史输入信息融入当前计算,从而具备了记忆。比如我们让神经元循环连接3次,得到的网络长这样:
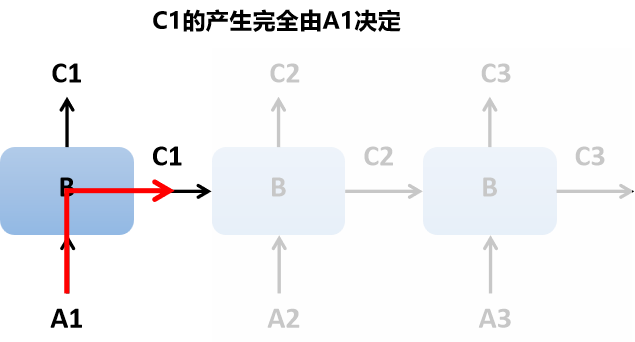
我们来观察一下模型的3个输出C1、C2和C3。C1的产生完全由A1决定,它是以A1为输入与B相乘后得到的输出。数据流向画出来是这样
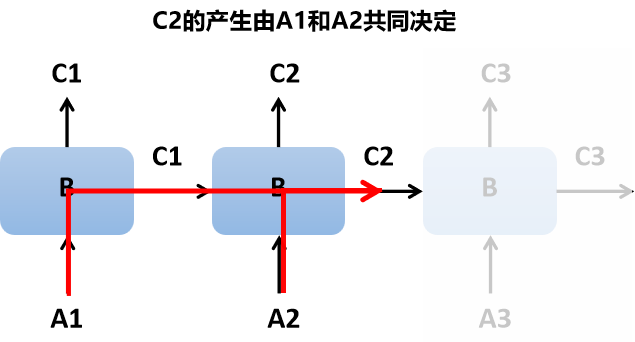
而C2的产生则是由A1和A2共同决定的
同理,C3的产生由A1,A2和A3共同决定。换句话说,模型在输出时记住了之前输入的内容,所以说模型拥有了记忆。
那如果要让模型完成“外卖小__”的空格填字怎么办了?好说,把“外”、“卖”、“小”三个字数字化后分别当做A1、A2和A3输入给模型,取C3作为最终输出就行,毕竟C3的产生结合了A1至A3。至于中间结果C1和C2在我们这儿用不上,丢弃就行。
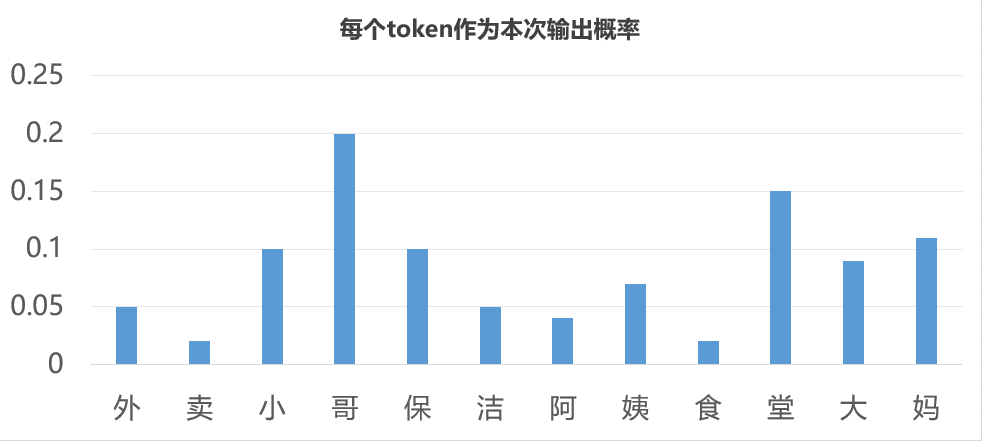
C3表示模型认为每一个token有多大的可能成为当前的输出。现在我们来解读一下模型的最终输出。模型最终的输出C3不是一个数,而是一串数。有多少个数取决于我们准备的训练语料包含多少个不同的token。假设我们的语料一共包含“外卖小哥保洁阿姨食堂大妈”这12个token,那么C3就是12个数,每个数是一个0~1之间的小数,比如我们输入“外卖小”三个token后得到的C3可能长这样:
[0.05, 0.02, 0.1, 0.2, 0.1, 0.05, 0.04, 0.07, 0.02, 0.15, 0.09, 0.11]
其中第一个数表示模型认为token集中第一个token(也就是“外”)应该作为本次输出的概率为0.05,第二个数表示第二个token(也就是“卖”)作为本次输出的概率为0.02……以此类推。我们画个图来看一下
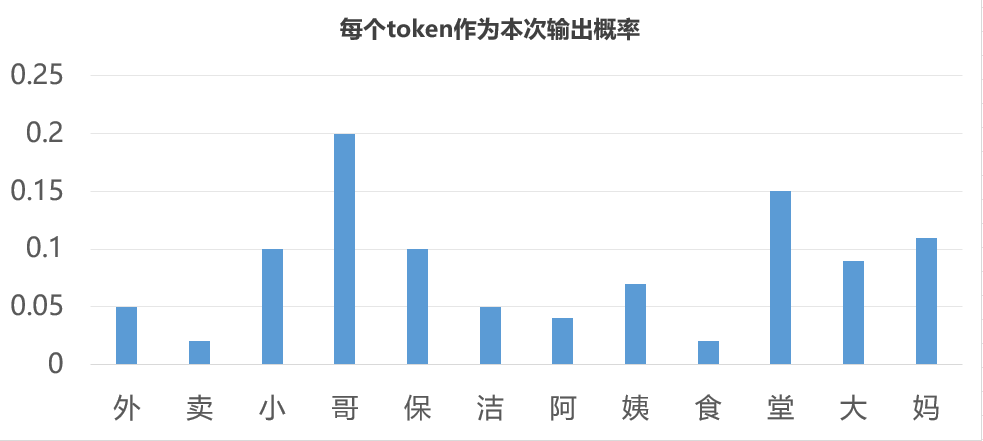
这个图表示了每个token的输出概率,因此模型的输出机制是“基于概率输出”。从这些候选token中如何选出一个token作为输出就叫做“采样策略”。目前来看“哥”这个token的概率最高,所以如果我们的采样策略是“把概率最高的token作为本次输出”(虽然这是最符合直觉的采样策略,但实际往往不会这样做),那模型就会以“哥”作为本次输出。当然,在实际当中完全有可能是某个别的token概率最大。
至于为什么要强调“基于概率输出”以及“采样策略”这两点,先埋个伏笔……在介绍完模型训练和实际使用之后再回收。
所以总结一下,将RNN神经元多次循环连接就可以得到RNN。最末尾神经元的输出是由之前所有的输入共同决定的,因此RNN具有记忆。此外,模型对自然语言的处理本质也只是在做加减乘除,当我们输入一句话后,模型的输出是一个概率分布,最终实际会输出什么内容取决于我们的采样策略。
到此,模型就搭建完了,其本质也是一个数学公式,即给定一句话后进行的一系列运算。回到一开始的问题,我们要如何依靠这个模型来训练一个客服机器人呢?这就关乎训练数据应该如何准备以及如何训练了。
训练前:准备训练数据
还记得啥叫文本生成吗?让模型依据给定的输入来输出符合语法规则、语义通顺的文本内容。所以我们要根据语料不停的提供这样的“输入→输出”示范让模型学会语料内的内在关系。具体来说,假设我们的客服文档中关于产品品质部分的说明如下:
“此款衬衫采用新疆长绒棉混纺莫代尔面料,兼具纯棉的透气亲肤与莫代尔的抗皱垂坠特性。立体剪裁设计,衣长覆盖腰线,袖口深度优化活动自由度,版型贴合人体工学。”
那么我们可以四个字为一组,前三个字作为给定输入,第四个字为期望输出的方式对这段话进行分割,如下所示。

按照这样的方式上面这段话能被分割为71个语料对。到此我们的训练数据就准备完了。
训练中:输入每个语料对调整参数
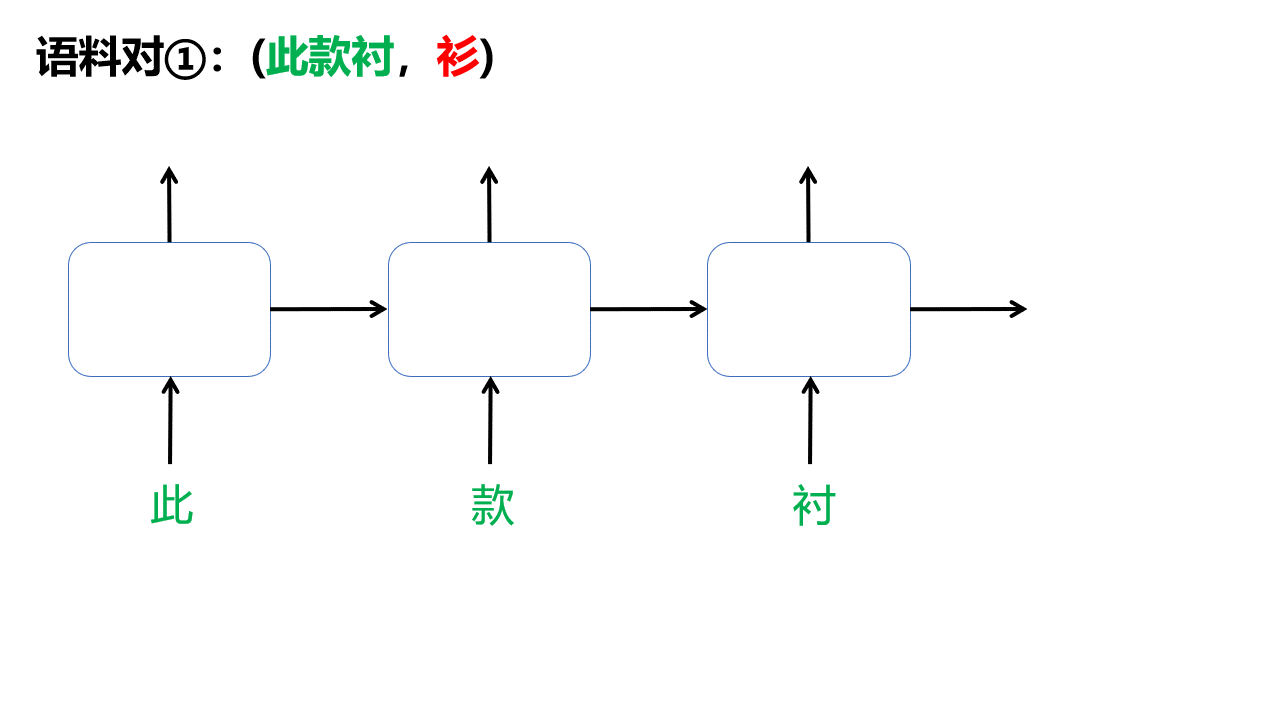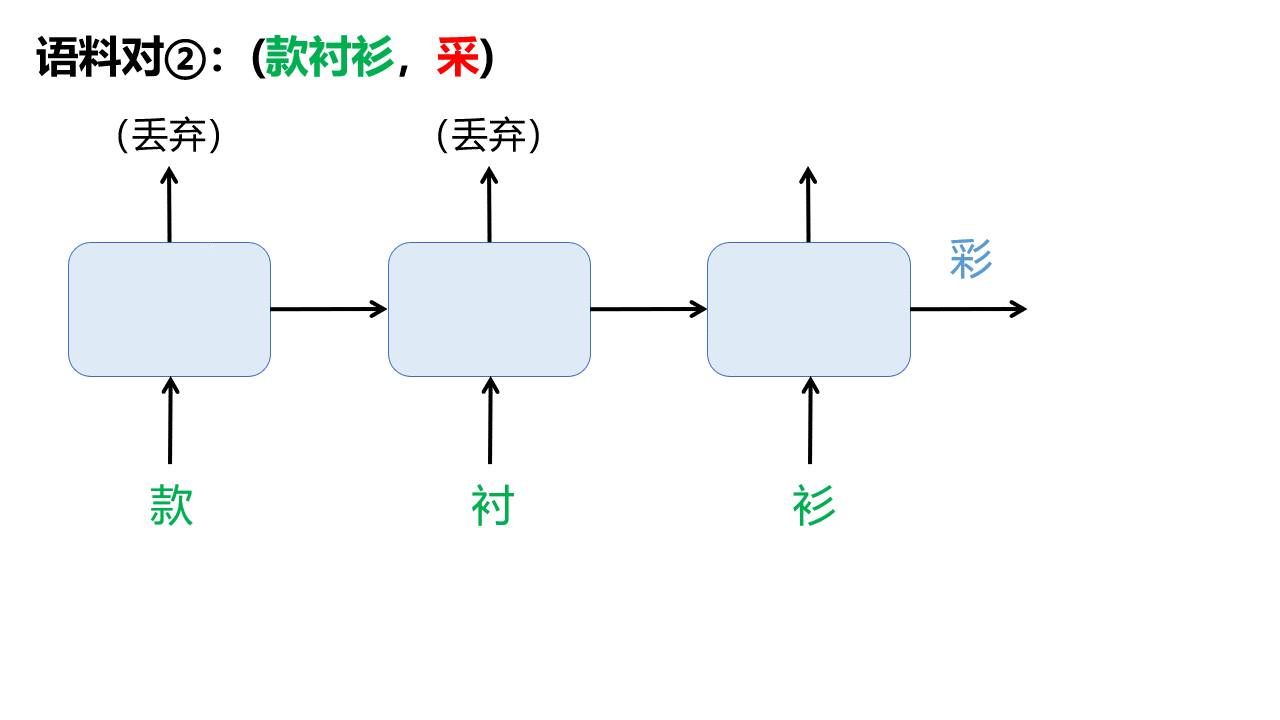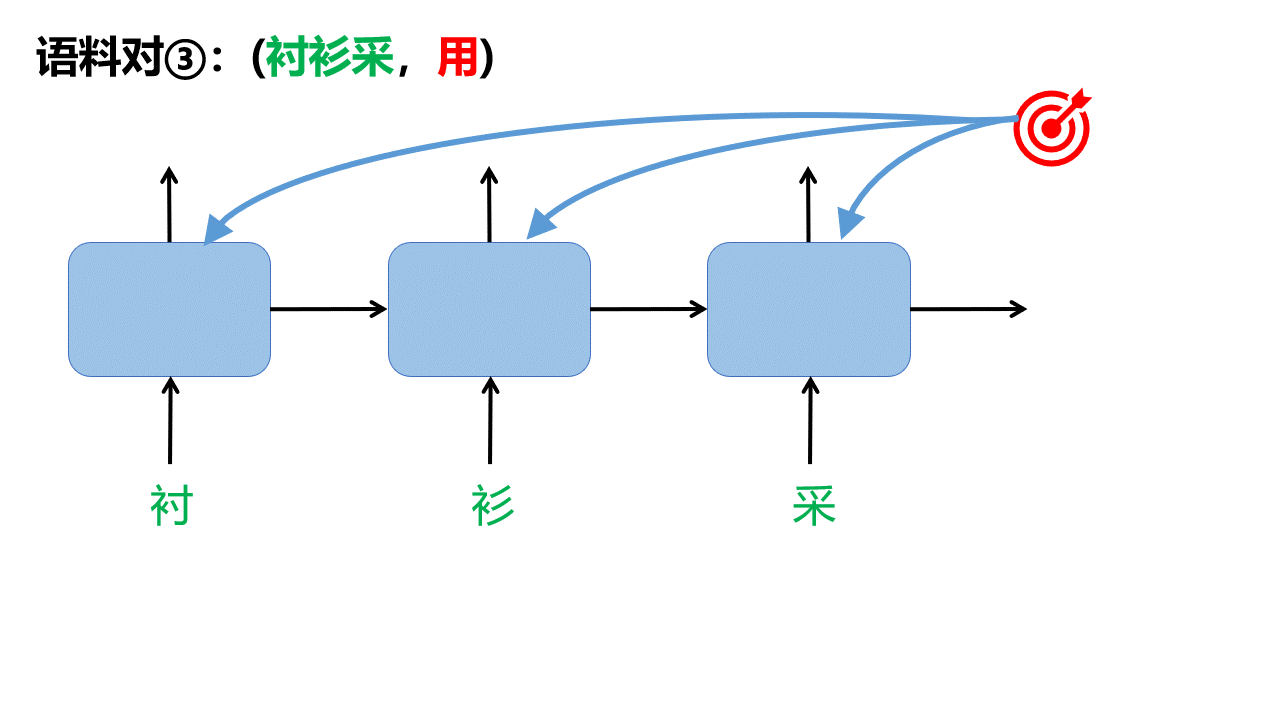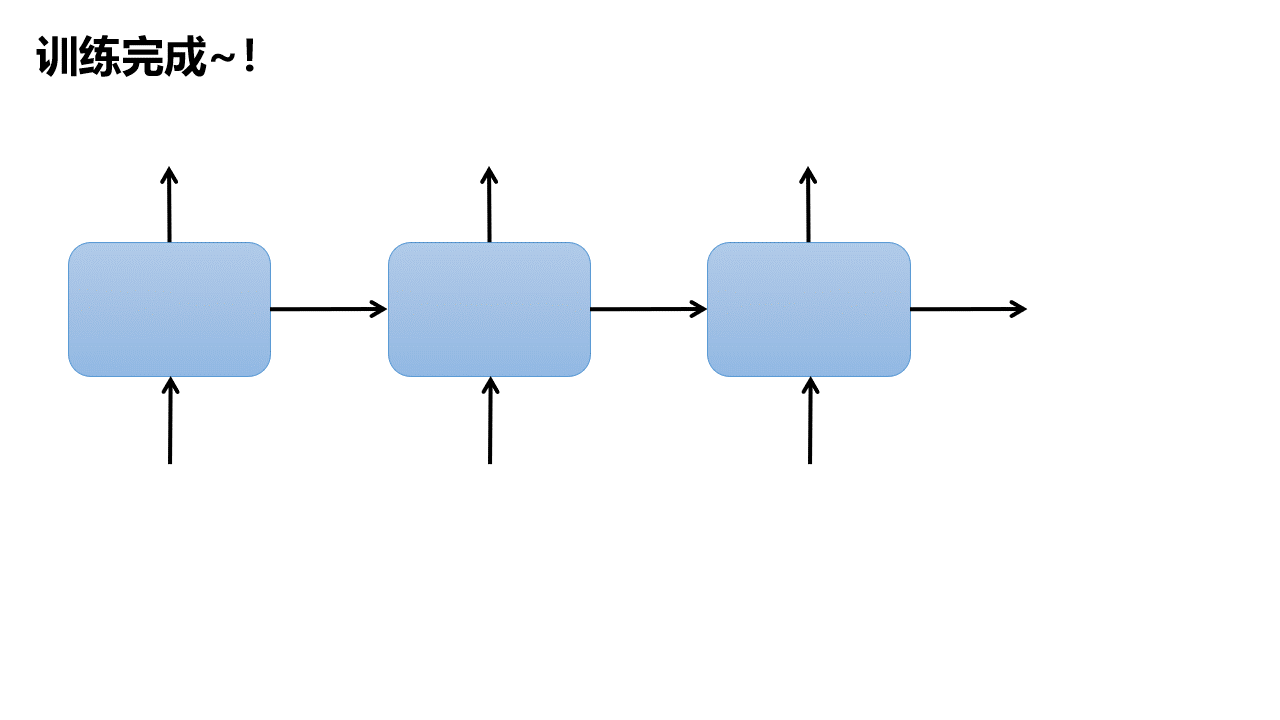
分割出的每一对语料对都将用于调整模型参数,以第一个语料对(此款衬,衫)为例,一共有4步:

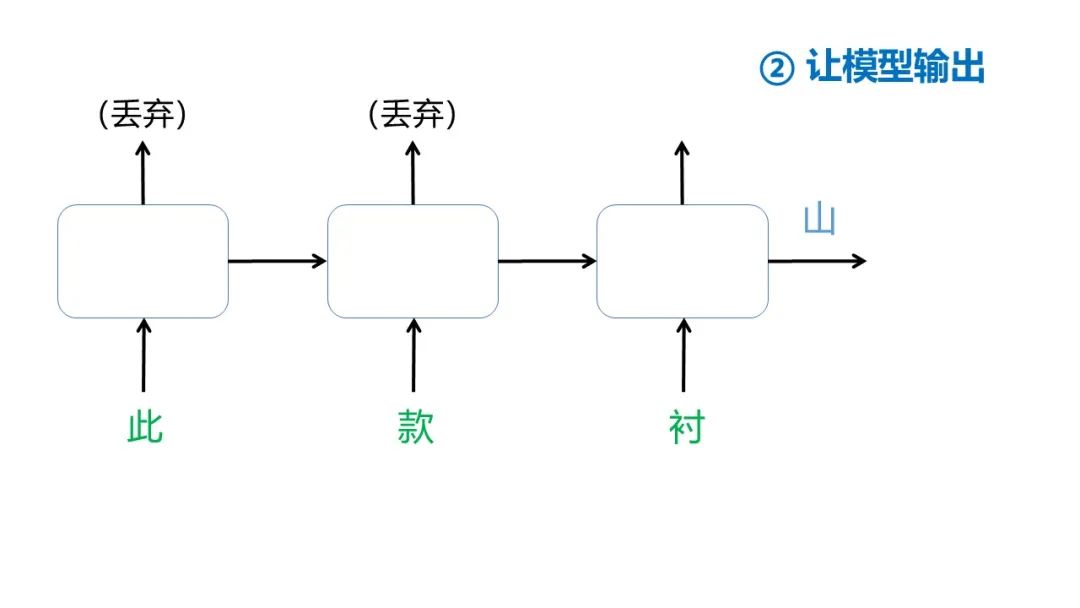
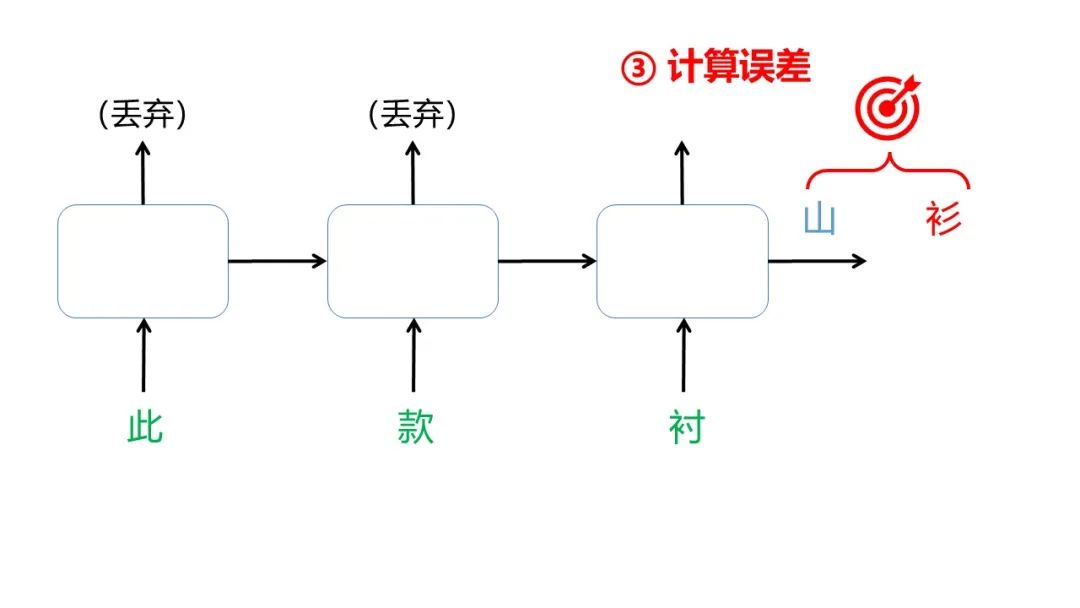
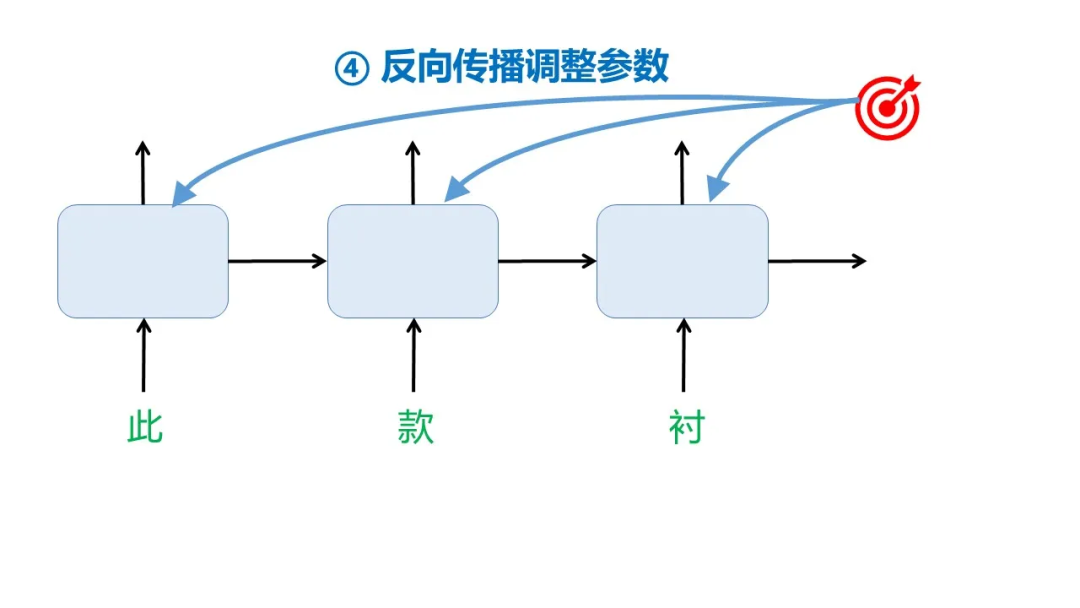
所以整个训练过程可以这样表示:
训练后:文本生成
完成训练后的模型就可以投入使用了。实际使用需要用户先给输入,也就是现在常说的prompt。假设用户输入“您好!”,模型会先根据这三个字输出下一个字,然后继续根据最新的三个字输出下一个字,如此循环直到模型认为可以停止输出。整个过程可以如下表示:

这就解释了为什么我们日常使用的大模型通常采用逐字输出的方式,同时也解释了为何部分模型会忘记用户之前输入的内容——因为之前输入的内容已超出其输入范围。比如图中这个模型每次的输入范围就只有最近的3个token,3个token之前的东西就记不住。(但现在的大模型如GPT-4o的输入范围是128,000个token)
伏笔回收之一:模型基于概率的输出机制
无论是大模型还是本文介绍的RNN,他们都采用基于概率的输出机制,因此必然产生幻觉 。回顾一下我们是怎么训练模型的:我们将语料按照“输入→输出”的方式分割为了众多语料对,并用来调整模型参数。这种机制使模型学到的是语料中字词共同出现的规律(也就是当某些字出现之后,在这之后的字大概率会是什么),而非事实逻辑。
因此假设我们的语料中出现了大量的“星期三”,模型就会认为“星期”二字之后大概率应该是“三”,所以如果输入“2025年4月32日是星期”,模型会输出“三”,哪怕4月其实并没有32日。同理,如果语料中出现大量的“1+1=3”,那么输入“1+1=”模型也会输出3。
这种基于概率的输出机制使得模型并不追求语言的 “正确性”,而是根据所学语料追求语言的“连贯性”。因此会出现模型的语言表达连贯自然但与事实不符的现象,也就是幻觉。
模型真的“智能”吗?现在我们理解了模型的本质是通过大规模数据训练形成的概率预测系统,那这算作真正的智能吗?我认为不算。虽然“智能”到底应该如何定义是一个宏大的哲学问题,但一个智能的个体至少应该能够理解因果,并运用因果关系解决实际问题。而模型从海量的数据中真的学到了因果吗?显然不是,它只学到了字词共同出现的概率。
那为什么现在的大模型看上去如此智能?因为语料足够多,质量足够好,模型设计足够复杂,这使得现在的大模型确实太像一个真正智能的个体了,像到确实可以用来解决很多问题了。但即便如此,其概率预测系统的本质决定了它不可能发展为理解因果关系的终极智能系统。
伏笔回收之二:模型的token采样策略
回到输入“外卖小”后模型的输出这个例子,我们之前假设模型此时对每个token的输出概率如下
如果选择“把概率最高的token作为本次输出”的采样策略,那模型自然会输出“哥”字。而实际当中往往不会采用这个策略,而是用一个叫做“温度”(temperature)的参数来控制模型的输出要按照多大程度偏移概率最高的token。
如果温度为0,那么模型就会始终按照它从训练语料中习得的最有可能与当前输入共同出现的token作为输出。这种情况下无论我们输入多少次“外卖小”,模型输出都是“哥”。此时的模型具有较强的准确性。
如果把温度提升,模型就可能从其他token里选一个作为输出,温度越高越有可能。这种情况下我们多次输入“外卖小”的话有可能第一次是“哥”,第二次是“姨”,第三次又是“妈”,第四次又是“哥”。此时的模型具有较强的创造性。这也是为啥我们即便多次输入一样的内容给大模型,每次回复都不一样的原因之一。(其他原因有用户所用的设备不同、地点不同、时间不同。这些信息虽然不在我们的prompt中,但app会自动上传给大模型以优化其回复)
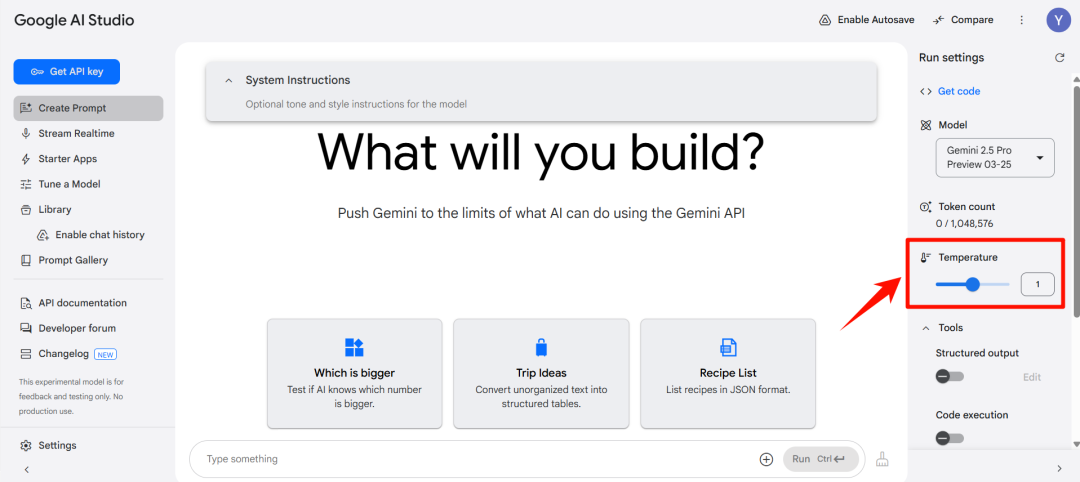
因此,如果app内可以调控这个参数的话(比如下图里Google的AI Studio),对于一些要求准确性强的任务,如法律文件生成,可以将温度调低,让模型忠于语料中学到的字词共现规律,不要凭空捏造法律条文。而对于要求创造性的任务,如诗歌生成,则可以将温度适当调高。
复盘一下,我们学到了什么
自然语言的序列性和上下文相关性是两大挑战。这要求模型具备记忆能力。
自然语言处理本质也是在对数字进行加减乘除。我们输入的一句话会先被切分成多个token,每个token会经过独热编码和词嵌入最终成为模型可处理的一串数。模型对这些数进行加减乘除后就可以达到预期的效果。
RNN就是将一个神经元循环连接组成的网络,这种网络具有记忆。一个神经元只干矩阵相乘这一件事,当我们把这样的神经元循环连接后,最后一个神经元的输出会兼顾之前所有的输入,所以RNN具有记忆。
给定一句话,让模型续写这事儿叫文本生成,训练文本生成模型需要准备众多语料对。每个语料对体现的是哪些字词会共同出现,模型就是通过学习这种共现规律来生成文本的。
模型基于序列末尾的几个字循环预测下一个字,逐字扩展直至完成文本生成。这是模型之所以一个字一个字往外蹦以及有时候会忘记用户之前输入内容的原因。
模型产生幻觉的根本原因在于其基于概率的输出机制。无论大模型还是 RNN,这类语言模型都通过学习语料中字词的共现规律来生成输出。在训练过程中,数据被分割为 “输入→输出” 的语料对,模型通过统计规律预测给定输入后的下一个字,本质是在最大化语言的连贯性而非正确性,因此会出现幻觉。
大模型也好,小模型也罢,都不是真正的智能。模型的本质是一个统计了语料间字词共现规律的概率预测系统,它并未理解语料中包含的信息,并不理解因果,更不能运用因果。现在的大模型确实很像一个智能的个体,像到了真的可以用来解决现实问题的程度,但它依旧不是广泛意义的智能。
“温度”是导致模型对于相同输入的回复不一致的原因之一。温度为0,模型则始终按照概率最大的token进行输出。温度越高,模型偏移概率最大的token进行输出的可能性越高。除此之外,app还会上传用户所用设备、所在的位置、时间等信息供大模型参考,也会导致相同prompt下大模型输出不一致。
欢迎来到1997
RNN虽然在20世纪80年代就已被提出,但碍于其梯度消失和爆炸的固有问题(即网络一旦变长,通过反向传播就无法有效调整模型参数)实际应用非常受限。直到1997年Sepp Hochreiter和Jürgen Schmidhuber提出的长短期记忆网络(LSTM)才彻底解决了这个问题,使得RNN被大量应用于自然语言处理。ChatGPT的早期版本、苹果Siri、亚马逊Alexa都是其具体应用。
所以这里以RNN的第二生日来恭喜你对大模型知识的理解来到了1997年。此时距离DeepSeek-R1发布还有28年。
顺便提一下,RNN由于可并行计算的部分有限,因而不能在大规模数据集上通过GPU训练,所以现在已经不怎么流行了。取而代之的是继承了RNN的思想,所有计算都可并行的,下一篇文章就会提到的,现在大模型普遍采用的,大模型基石——Transformer。
AI Heroes

LSTM发明者——Sepp Hochreiter教授
赋予RNN第二次生命的LSTM。RNN在诞生之初由于梯度消失和爆炸问题导致模型一旦过长便无法有效训练,因此无法处理较长的序列数据。这个问题在1997年由Sepp Hochreiter和Jürgen Schmidhuber发表的《Long Short-Term Memory》中被彻底解决,他们对RNN的改良在于引入门控机制和记忆单元,实现了对信息的选择性存储与遗忘,使得 LSTM 在处理长序列时能够稳定地传递梯度,有效捕捉长期依赖。一个LSTM神经元长这样:
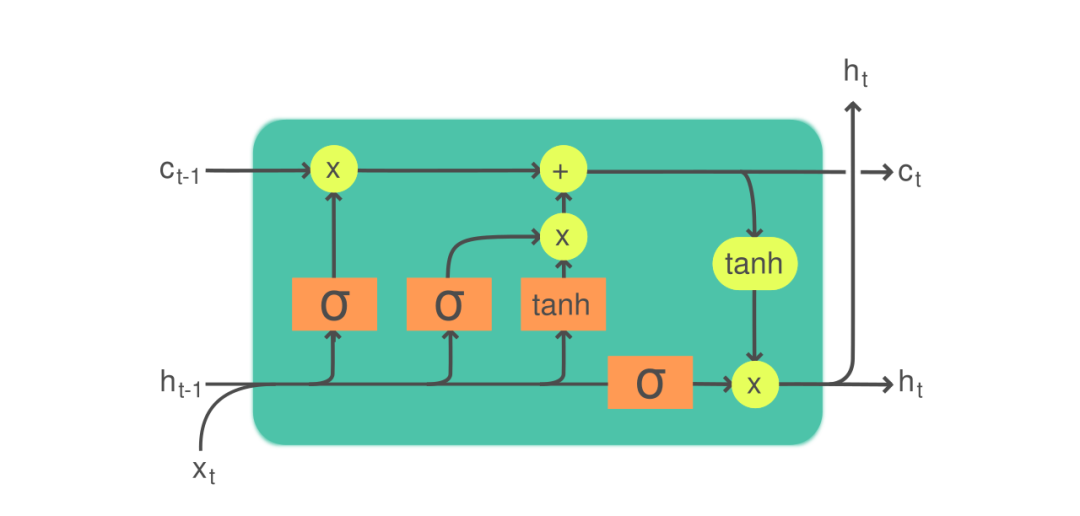
比咱介绍的只做了一次矩阵乘法的RNN神经元复杂多了,而且看上去像只草履虫哈哈哈
Sepp Hochreiter,IEEE 2021年神经网络先驱奖获得者。Hochreiter现任奥地利林茨大学研究所所长,2021年获得 IEEE 神经网络先锋奖以表彰他在LSTM领域的开创性贡献,该奖项被视为神经网络领域的最高荣誉之一。
xLSTM,makes RNN great again。2024年5月Hochreiter团队推出的了xLSTM(eXtendedLSTM),旨在解决现在以Transformer架构为主的大模型(如DeepSeek)计算开销大的问题。
- Transformer架构的计算开销与文本长度呈平方增长关系,而xLSTM在处理长文本时只需增加相应数量的神经元,因此计算开销仅为线性增长。
- 在模型训练上xLSTM克服了传统LSTM的并行计算瓶颈,实现了与Transformer相当的并行化训练能力。
- 在最终效果上,xLSTM在同等参数量下,长序列任务性能显著优于Transformer,尤其在语言建模和实时场景中困惑度更低、内存效率更高,硬件适配性更强,适合工业部署;但在代码生成、多模态融合等结构化任务中仍弱于Transformer,需依赖混合架构平衡顺序与并行能力。
- 对于那些推理计算量庞大和需要快速响应的场景,xLSTM 或许是值得关注的一条技术路线。
连续创业者。
- 2017 年Hochreiter 创立奥地利人工智能高级研究所(IARAI)并担任首任所长,推动 AI 在交通、能源等领域的应用,例如开发实时交通预测系统,减少城市拥堵。
- 2024年其研究所孵化了一家名叫NXAI的科技公司,针对特定行业(如汽车、医疗)定制 AI 解决方案
- 2025年孵化Emmi AI,专注于通过其核心技术xLSTM 模型为制造业和能源行业提供轻量化、高效能的 AI 解决方案。
“他以循环为针脚,将离散的字符织入时间的经纬 ,让昨天的字节得以亲吻明天的比特”
——后记
本文由 @夜雨思晗 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图由作者提供
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务






- 目前还没评论,等你发挥!








