
 起点课堂会员权益
起点课堂会员权益
AI启蒙:机器学习三大范式,在交互世界初遇NPC (AI产品经理智能NPC笔记 S1E01)
 B端产品经理需要进行售前演示、方案定制、合同签订等,而C端产品经理需要进行活动策划、内容运营、用户激励等
B端产品经理需要进行售前演示、方案定制、合同签订等,而C端产品经理需要进行活动策划、内容运营、用户激励等智能 NPC 正在重塑数字世界的交互形态 —— 从开放世界游戏中动态博弈的 AI 敌人,到元宇宙中具备情感认知的虚拟助手,其技术落地背后是多学科知识的系统化整合。作为深耕 AI 交互领域的从业者,我将通过 24 篇递进式技术博文,构建一套覆盖「基础理论→技术实战→工程化落地」的完整知识图谱,助你掌握可复用的 AI NPC 开发方法论。

一、为什么需要这套知识体系?
当前 AI NPC 开发面临三大挑战:
❶ 知识碎片化:算法原理、工程实现、产品落地等环节缺乏体系化串联,难以形成完整技术栈
❷ 工具适配难:Mac 芯片环境配置、国产大模型部署等实操细节缺乏系统性指南
❸ 落地成本高:个人开发者难以跨越技术门槛,企业项目常因流程不规范导致效率低下
本系列聚焦「可落地的工程化思维」,以「理论解析→工具选型→实战验证→产品化评估」为主线,打造从技术原理到商业落地的闭环体系。每篇内容严格遵循需求文档中的「渐进式学习曲线」,确保个人开发者可独立完成实操,企业团队能直接复用方法论。

二、24 篇内容的递进逻辑:从地基到高楼的五层架构
整个系列按技术复杂度分为五大模块,每模块包含明确的知识节点和阶段成果:
模块一:基础理论篇(4 篇)—— 夯实技术地基
核心价值:建立 AI NPC 技术认知坐标系
知识重点:
 机器学习三大学派(监督学习 / 无监督学习 / 强化学习)在 NPC 中的差异化应用
机器学习三大学派(监督学习 / 无监督学习 / 强化学习)在 NPC 中的差异化应用
NLP、CV、RL 等核心技术如何赋能 NPC 的「听、看、决策」能力
国产工具链入门:百度 BML 建模平台、ChatGLM3 本地部署实战(仅供参考)
阶段成果:掌握 AI NPC 技术选型的底层逻辑,完成基础对话 NPC 原型搭建
模块二:认知构建篇(3 篇)—— 定义智能边界
核心价值:建立 AI NPC 能力评估与需求管理体系
知识重点:
四维能力模型(认知 / 决策 / 表达 / 进化)量化评估标准
从《仙剑》脚本 NPC 到《赛博朋克 2077》大模型 NPC 的技术演进路径
产品经理专属:AI NPC 需求文档规范(含不确定性管理条款)
行业案例:拆解《逆水寒》NPC 系统的技术架构与用户体验设计
模块三:技术基础篇(6 篇)—— 攻克核心模块
核心价值:掌握 NPC 系统的工程化实现路径
知识重点:
对话系统、记忆存储、多模态交互等核心模块的架构设计
Mac 芯片专属优化:PyTorch-MPS 加速配置、Core ML 模型转换教程
实战工具:Unity Behavior Designer 可视化行为树、PaddleSpeech 语音识别集成
阶段成果:第 12 篇完成「迷宫寻路智能体 Demo」,实现 NPC 基础决策能力
模块四:进阶实战篇(6 篇)—— 拓展复杂场景
核心价值:解决规模化落地的关键挑战
知识重点:
端到端开发全流程:从数据集构建到引擎集成的 20 + 优化技巧
分布式系统、内容安全、轻量化部署等企业级解决方案
多智能体协作:Mesa 库模拟 NPC 社交网络涌现现象
实战案例:某 MMO 游戏 NPC 对话跳出率降低 37% 的 AB 测试复盘
模块五:专业拓展篇(5 篇)—— 探索前沿边界
核心价值:构建技术视野与职业能力体系
知识重点:
AI 伦理、神经符号系统、元宇宙架构等前沿议题深度解析
工程化实践:Jenkins+Docker+K8s 全流程自动化部署
职业发展:AI 产品经理能力雷达图(技术 / 产品 / 行业三维度评估)
产出物:第 24 篇提供「职业能力发展模型」,含认证体系与资源地图
三、系列特色:为落地而生的三大保障
1. 本土化工具链全覆盖
- 推荐方案:ChatGLM3-6B(本地推理)、Unity ML-Agents(强化学习)、Stable Diffusion(视觉生成)
- 替代方案:文心 ERNIE(API)、MindSpore Reinforcement(国产框架)、腾讯 ARC Lab(视觉工具)
- 设备适配:所有案例 100% 支持 Mac M1 芯片,提供 MiniConda 环境配置、Unity Metal 优化等独家技巧
2. 产品经理专属模块
每篇包含「PM Checklist」四连问:
技术可行性:当前方案的工程化难度分级
开发成本:数据标注 / 模型训练 / 硬件适配的资源测算
体验风险:对话重复率、响应延迟等关键指标监控
合规审查:《生成式 AI 服务管理办法》落地要点
3. 渐进式案例体系
- 阶段一:单一功能 NPC(对话 / 寻路基础 Demo)
- 阶段二:多模态 NPC(语音 + 表情 + 动作交互原型)
- 阶段三:群体智能 NPC(社交网络模拟与涌现行为观测)
所有案例提供 可运行代码、Mermaid 原理图解、CSV/JSON 数据集示例
四、适合谁读?
AI 产品经理:掌握技术与业务的转化语言,学会用「PM Checklist」评估方案价值
独立开发者:获取 Mac 端全流程适配指南,实现 100% 个人可完成的实操案例
技术爱好者:深入理解 NPC 系统架构,积累多模态融合、强化学习实战经验
五、如何开启学习?
我们开始正篇内容:
《AI启蒙:机器学习三大范式,在交互世界初遇NPC》
将解析监督学习与无监督学习的本质差异,通过简单实战的玩家行为聚类,并演示快速建模流程 —— 这是后续所有实战的理论基石。
暂定每周更新一篇(案例需要较长时间进行搭建),24 周完成从「技术通识」到「复杂系统设计」的能力升级。无论你是计划转型的从业者,还是深耕交互领域的开发者,这套体系都将成为你构建 AI NPC 系统的「技术地图」。
AI启蒙:机器学习三大范式,在交互世界初遇NPC
系列引言:
大家好,我是 Mu「本姓」,一名专注于AI驱动智能NPC方向的AI产品经理。在游戏、VR、AR与元宇宙的浪潮中,我们都渴望创造出不再是简单“工具人”、而是真正拥有“灵魂”、能够与玩家产生深度情感连接的虚拟角色。
这个系列笔记,便是我以产品经理的视角,探索如何利用AI技术(尤其是机器学习)为这些交互世界中的NPC注入生命力的学习与思考沉淀。我们将一起从基础理论出发,逐步深入技术核心,最终探讨前沿趋势与职业发展,全程聚焦于我们热爱的交互娱乐领域。希望这份笔记能为你我带来启发,共同推动“活”的NPC从梦想照进现实。

想象一下:
❶ 在广袤的开放世界游戏中,你遇到的路人NPC不再是重复播放固定台词的“背景板”,而是能根据你的行为、穿着甚至过往事迹,产生截然不同的反应和对话;
❷ 在沉浸式的VR体验里,与你互动的虚拟伙伴能够理解你的手势、甚至捕捉到你微妙的表情变化,做出自然且充满情感的回应;
❸ 在元宇宙的社交空间中,AI引导者能根据你的兴趣图谱,为你推荐活动、介绍朋友,如同真人般贴心……这些令人心驰神往的场景,正是智能NPC的魅力所在,也是驱动我们不断探索AI技术边界的动力源泉。
而这一切“智能”的背后,**机器学习(Machine Learning, ML)**扮演着至关重要的奠基者角色。
它赋予了计算机从数据中学习规律和模式的能力,让NPC的行为不再完全依赖于开发者预先编写的庞大而僵硬的规则库。
Mu 身处VR/AR/游戏/元宇宙前沿的AI产品经理,我们或许无需亲自编写算法代码,但深刻理解机器学习的核心思想与主要范式,却是我们做出明智技术选型、定义NPC能力边界、评估开发成本与风险、有效协同设计与技术团队、最终打造出卓越用户体验的关键前提。
为什么有的NPC感觉“聪明”,有的却很“呆板”?为什么有些AI特性实现成本高昂,有些则相对容易?这些问题的答案,往往就隐藏在所采用的机器学习范式之中。不理解这些基础,我们就如同盲人摸象,难以把握AI NPC产品的核心脉络。
那么,机器学习究竟有哪些主要的“流派”?它们各自的“学习方式”有何不同?在塑造我们钟爱的游戏、VR、AR及元宇宙NPC时,它们又分别扮演着怎样的角色,带来了哪些独特的可能性与挑战?
在本系列的第一篇文章中,我们将一同踏上这场AI启蒙之旅,重点探索机器学习的三大核心范式:
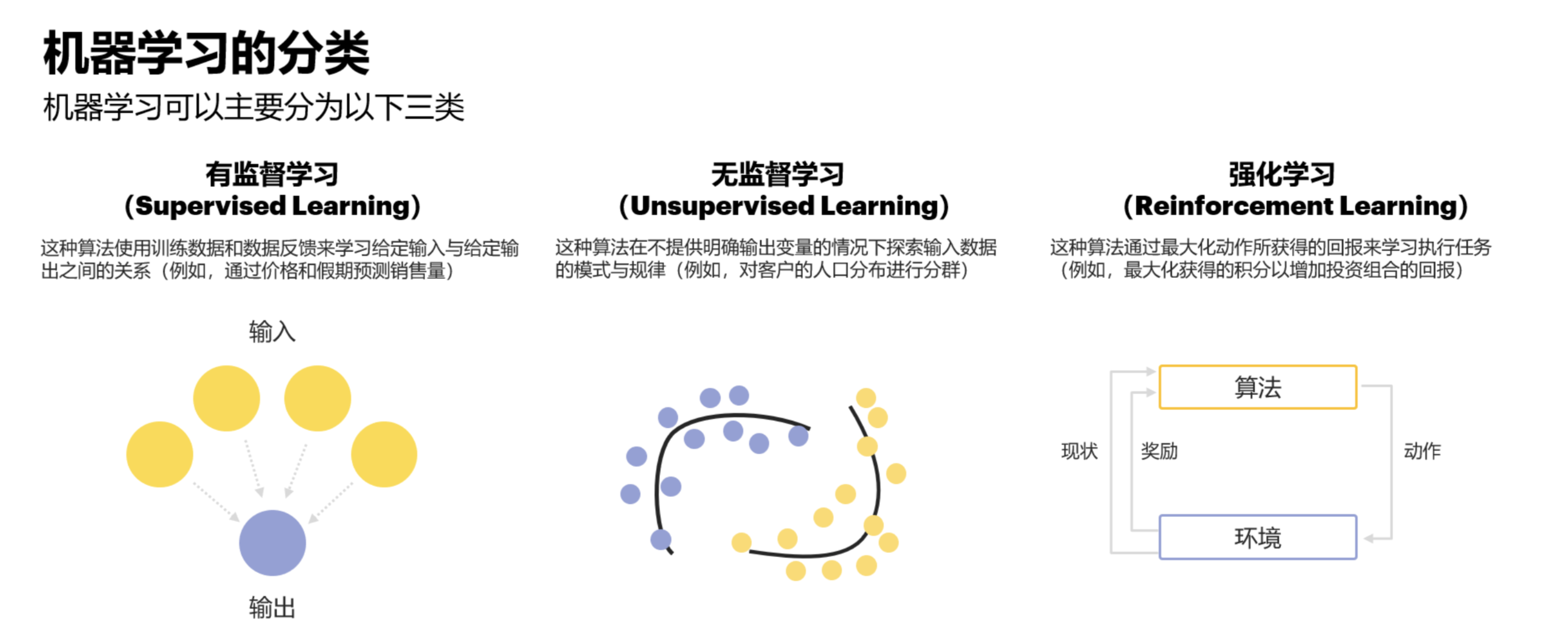
- 监督学习 (Supervised Learning): 有标准答案的“老师傅带徒弟”模式。
- 无监督学习 (Unsupervised Learning): 在未知中探索的“自学成才者”。
- 强化学习 (Reinforcement Learning): 在试错中成长的“实践派”。
我们将剖析它们的基本原理,通过大量来自游戏、VR/AR等交互世界的实例,直观感受它们如何赋予NPC不同的“智慧”。
同时,我们将从AI产品经理的视角出发,探讨每种范式的选型考量、数据需求、成本因素以及对产品体验的深层影响,并提及一些代表性的算法类别及其产品层面的特点。
让我们正式开始,为后续的探索打下坚实的地基!
机器学习的核心在于“学习”。
不同于传统编程需要开发者明确指令每一步操作,机器学习让程序能够通过分析数据来改进自身的性能。
而根据“学习”方式的不同,主要分为以下三大范式:
1、监督学习 (Supervised Learning):目标明确,按“标准答案”学习
 (技术原理): 这是目前应用最广泛、技术相对成熟的一种范式。
(技术原理): 这是目前应用最广泛、技术相对成熟的一种范式。
它的核心在于,我们提供给机器学习模型的训练数据是**包含“输入”和对应的“正确输出(标签)”**的。
就好比我们给学生做习题,并告诉他们每道题的标准答案,学生通过反复练习,学会从题目(输入)推导出答案(输出)的规律。
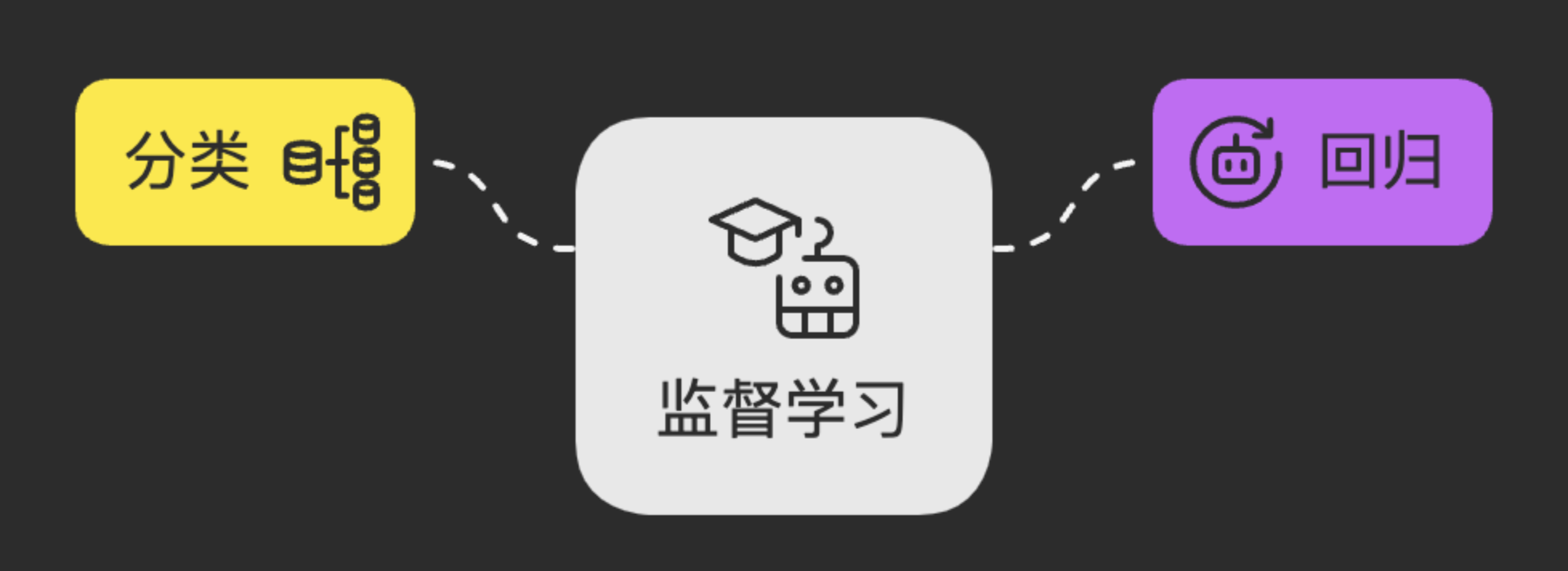
监督学习主要解决两类问题:
- 分类 (Classification): 输出是离散的类别标签。例如,判断一张图片里是“猫”还是“狗”。
- 回归 (Regression): 输出是连续的数值。例如,根据房屋的面积、位置等特征预测其“价格”。
 (游戏/VR/AR场景应用): 在我们的交互世界里,监督学习大有用武之地:
(游戏/VR/AR场景应用): 在我们的交互世界里,监督学习大有用武之地:
- 玩家意图识别 (分类): 在MMORPG或社交元宇宙中,分析玩家在聊天框输入的文字,判断其意图是“寻求组队”、“交易物品”、“询问任务”还是“举报骚扰”,以便NPC或系统能给出最恰当的回应或引导。
- 敌人/物体类型识别 (分类): 在射击游戏中,AI敌人通过“视觉”(游戏引擎中的信息)识别玩家、队友、不同类型的掩体或重要目标;在AR应用中,识别现实世界中的特定物体(如一张海报、一个产品)以触发交互。
- 手势指令识别 (分类): 在VR/AR中,通过摄像头或传感器捕捉用户手部动作数据,判断用户做出的是“抓取”、“释放”、“确认”还是“返回”等指令,驱动虚拟手或界面进行交互。这对于自然交互至关重要。
- 玩家行为预测 (分类/回归): 根据玩家历史行为数据(登录频率、游戏时长、社交互动、付费记录等),预测其流失风险(分类),或者预测其在下个周期内可能的消费金额(回归),为运营活动或NPC的个性化挽留/推荐提供依据。
 (提及代表算法类别及其产品特点):
(提及代表算法类别及其产品特点):
- 监督学习旗下有众多算法,常见的类别包括:
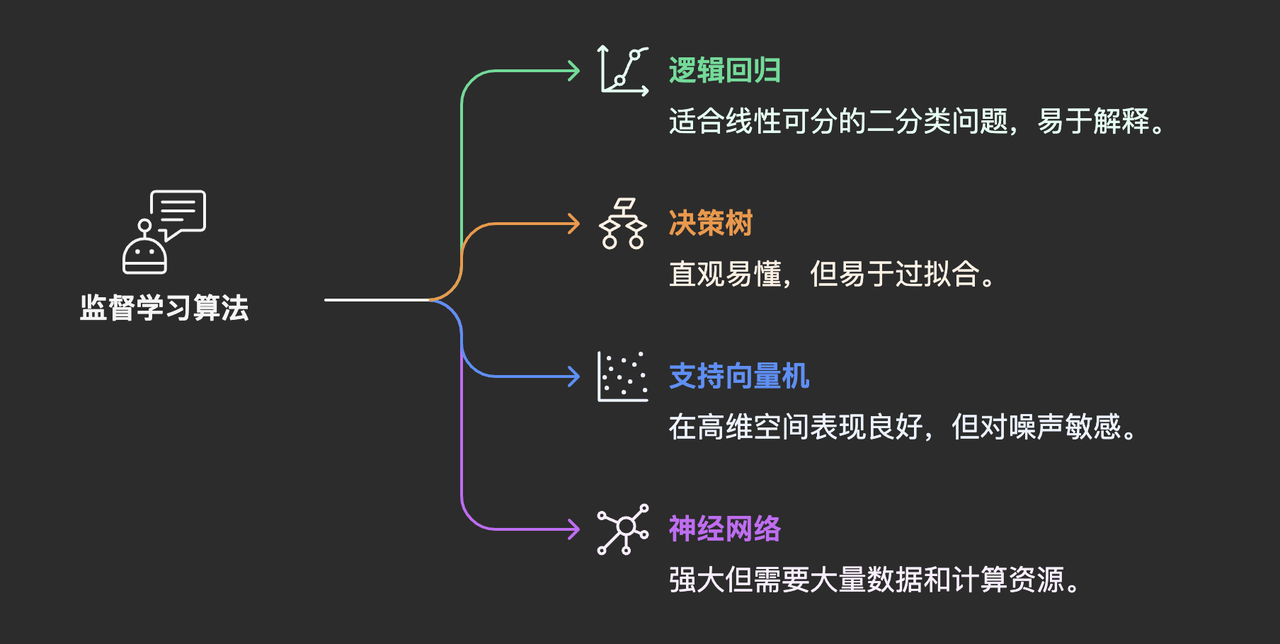
- 逻辑回归 (Logistic Regression): 简单、快速,适合处理线性可分的二分类问题,可解释性尚可。
- 决策树 (Decision Trees): 非常直观,像流程图一样易于理解和解释,方便策划或设计师理解NPC的简单判断逻辑。但容易过拟合,对复杂模式处理能力有限。
- 支持向量机 (SVM): 在某些中小型数据集和高维空间(如文本特征)分类任务上表现优异,理论基础扎实。但对大规模数据和噪声敏感,可解释性较差。
- 神经网络 (Neural Networks),尤其是深度学习模型: 能力强大,特别擅长处理图像、语音、复杂序列等非结构化数据,是驱动高级感知能力的核心。但需要大量数据和计算资源,模型通常是“黑箱”,难以解释决策原因,调试复杂。
PM选型考量:
- 数据!数据!数据! 监督学习的命脉在于高质量、足量的标注数据。作为PM,在规划基于监督学习的NPC特性时,必须最先拷问:我们有足够多、标注准确的数据吗?获取和标注这些数据的成本(时间、人力、金钱)是多少? 这往往是项目可行性的最大瓶颈。例如,要让NPC识别玩家数百种不同的意图,就需要投入巨大成本构建标注语料库。
- 可解释性 vs. 性能: 我们需要让策划或设计师能清晰理解NPC为何做出某个判断吗(比如一个简单的任务NPC)?如果是,决策树等简单模型可能是好的起点。如果追求极致的识别精度(比如VR中精确的手势识别),那可能不得不拥抱性能更强但解释性差的神经网络,并通过大量测试来弥补。
- 模型复杂度与部署环境: 复杂的模型(如大型神经网络)不仅训练成本高,在游戏客户端(尤其是移动端或VR一体机)的推理(运行)成本也高,可能影响游戏帧率或设备发热。PM需要关注模型大小、推理延迟是否满足产品性能要求。
 [案例建议与文献引用]:
[案例建议与文献引用]:
很多RPG游戏中,玩家选择不同的对话选项会影响NPC好感度或触发不同后续,这体现了游戏系统对玩家输入的“分类”处理,并基于此调整内部状态。关于此类NPC关系系统的设计思路,可以参考游戏设计相关的讨论文章
Scheherazade’s Tavern 项目
- ACM 论文提出的「自然语言交互 + 社交模拟」架构,通过 Chatbot 接口和知识建模技术实现深度 NPC 互动。
- 例如,玩家可通过自由对话探索 NPC 的背景故事(如询问童年经历),NPC 会根据自身知识子集(如铁匠的冶金知识、法师的魔法理论)生成个性化回答。该系统还支持不对称知识建模,不同 NPC 对同一事件可能持有不同观点(如商人认为战争有利可图,村民则痛恨战乱)。
- 来源:https://dl.acm.org/doi/fullHtml/10.1145/3402942.3402984
GDC 2024:AI 驱动的 NPC 叙事革命 育碧「NEO NPCs」项目展示了生成式 AI 与人类编剧的结合模式:
- 情感锚定:人类编剧定义 NPC 的核心性格(如多疑、忠诚),AI 根据玩家行为动态生成对话分支(如玩家说谎时触发「怀疑」状态)。
- 任务协同:NPC 可根据玩家的策略建议调整任务方案(如玩家提议潜入,NPC 会分析可行性并给出风险提示)。
- 伦理控制:通过人工审核机制避免 AI 生成刻板印象(如女性 NPC 的「谄媚」对话),确保角色多样性。
- 来源:https://www.gameshub.com/news/news/ubisoft-ai-neo-npcs-gdc-2024-2638181/
2、无监督学习 (Unsupervised Learning):自主探索,发现数据中的“秘密”
(技术原理): 与监督学习截然相反,无监督学习处理的数据没有预先给定的“标签”或“标准答案”。
它的目标是在数据中自主地发现隐藏的结构、模式、关联或异常。
可以把它想象成,给你一大堆杂乱无章的乐高积木,让你自己尝试把它们按形状、颜色或某种内在逻辑分门别类。
无监督学习常见的任务包括:
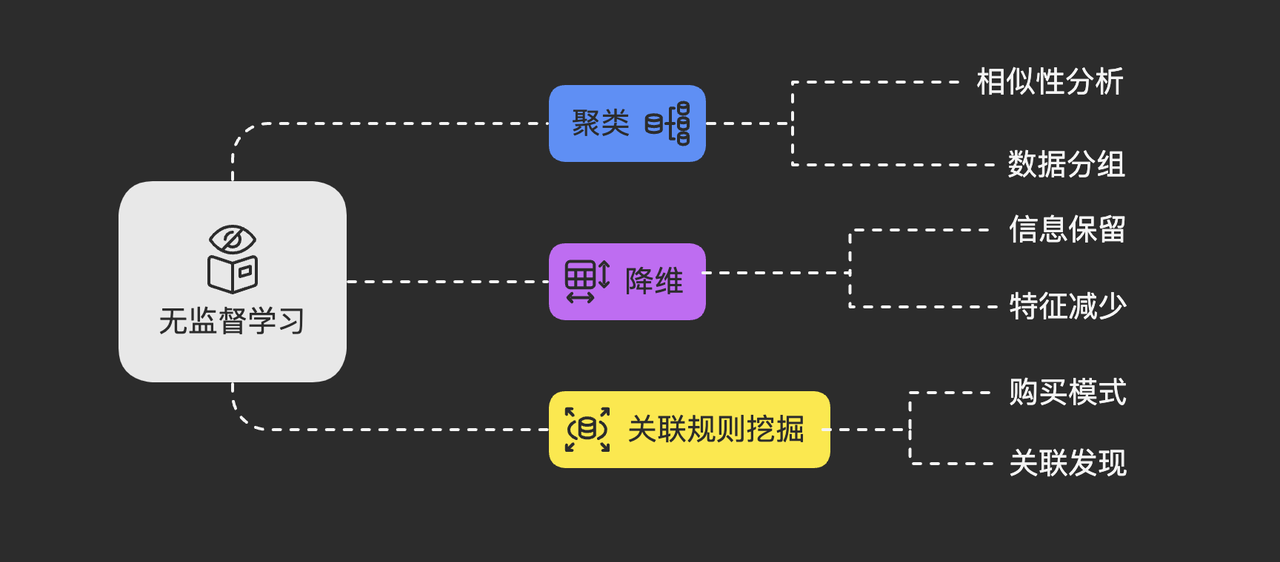
- 聚类 (Clustering): 将相似的数据点聚合在一起,形成不同的“簇”或“群组”。
- 降维 (Dimensionality Reduction): 在保留主要信息的前提下,减少数据的特征数量,便于可视化或后续处理。
- 关联规则挖掘 (Association Rule Mining): 发现数据项之间有趣的关联关系,如“购买了‘虚拟宝剑’的玩家,也很可能购买‘盾牌’”。
(游戏/VR/AR场景应用): 无监督学习如何帮助我们理解玩家和虚拟世界?
- 玩家群体细分 (聚类): 在MMO或元宇宙中,基于玩家的游戏行为(探索偏好、战斗风格、社交活跃度、消费习惯等)自动将其划分为不同的群体(如“硬核PVP玩家”、“休闲社交玩家”、“成就收集者”)。这为个性化内容推荐、活动设计、甚至NPC的差异化互动策略提供了依据。
- VR用户体验模式发现 (聚类/降维): 分析VR用户的移动轨迹、视线焦点、交互频率等数据,发现常见的用户行为模式或潜在的体验痛点(如某些区域易引发晕眩)。
- 游戏环境热点分析 (聚类): 在大型开放世界游戏中,分析玩家死亡地点、资源采集点、任务接取点等空间数据,自动发现玩家活动的热点区域或设计不合理的区域。
- 异常行为检测 (聚类/异常检测): 识别出与大多数玩家行为模式显著不同的个体,可能有助于发现潜在的游戏外挂使用者、工作室打金行为或需要特殊关注的新手玩家。
(提及代表算法类别及其产品特点):
- 无监督学习的常用算法类别:
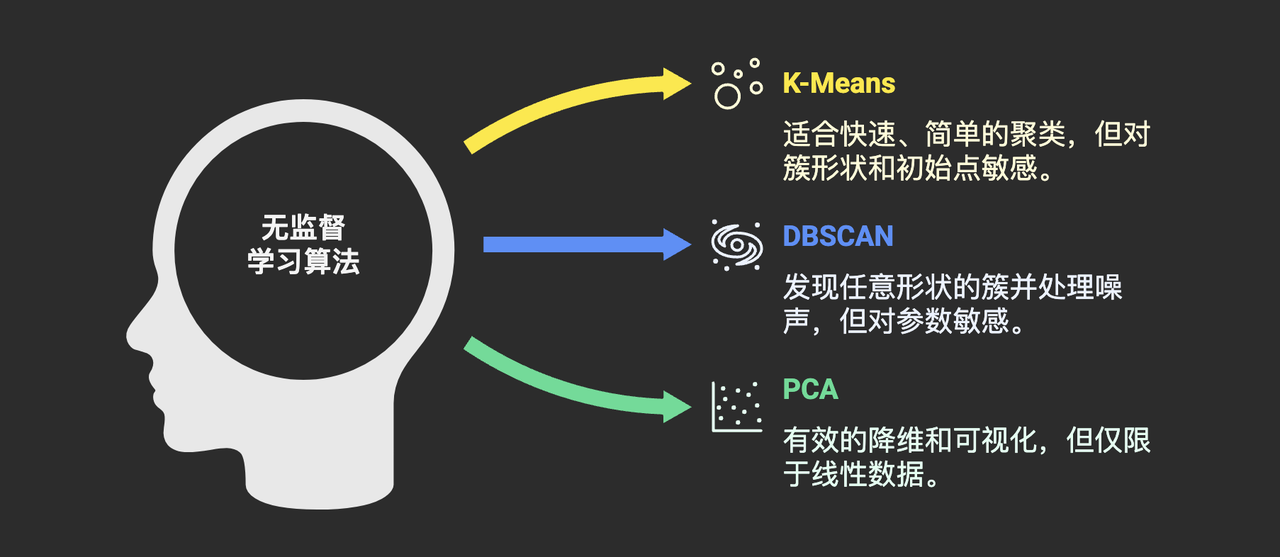
- K-Means: 最经典的聚类算法之一,简单快速,易于实现。但需要预先指定簇的数量(K值),且对初始中心点敏感,对非球状簇效果不佳。
- DBSCAN: 基于密度的聚类算法,能发现任意形状的簇,且不需要预先指定簇数量,对噪声点不敏感。但对参数选择(邻域半径、最小点数)敏感。
- PCA (Principal Component Analysis): 常用的线性降维方法,通过找到数据方差最大的方向来简化数据,便于可视化。
PM选型考量:
- 探索未知是核心价值: 当我们对用户群体或系统行为没有清晰的预设认知,希望从数据中发现一些“意想不到”的模式时,无监督学习是强大的工具。
- 结果需要解读和验证! 算法给出的聚类结果本身只是一堆数据分组,这些分组到底代表什么业务含义?(比如,聚类出的“第3类玩家”到底是一群什么样的人?)这需要产品、运营、数据分析师结合业务知识进行深入解读和验证,才能转化为可行动的策略。PM需要主导或深度参与这个解读过程。
- 评估相对主观: 没有“标准答案”,评估无监督学习的效果通常更依赖于聚类结果的业务可解释性、稳定性以及后续应用带来的实际效果(如个性化推荐的点击率是否提升)。
- 对数据质量和特征工程敏感: 输入数据的质量和选择的特征,会极大影响聚类的效果。
(概念演示 – 玩家行为聚类):
- 想象我们收集了MMO游戏中大量玩家的两项行为数据:平均每日战斗时长、平均每周社交互动次数。将这些数据点绘制在二维图上。
- 运行K-Means算法(比如设定K=3),算法会自动尝试将这些点分成三个群组。我们可能会发现一群“高战斗、低社交”的玩家(独狼战狂),一群“低战斗、高社交”的玩家(休闲交友党),以及一群“中等战斗、中等社交”的玩家(平衡型)。
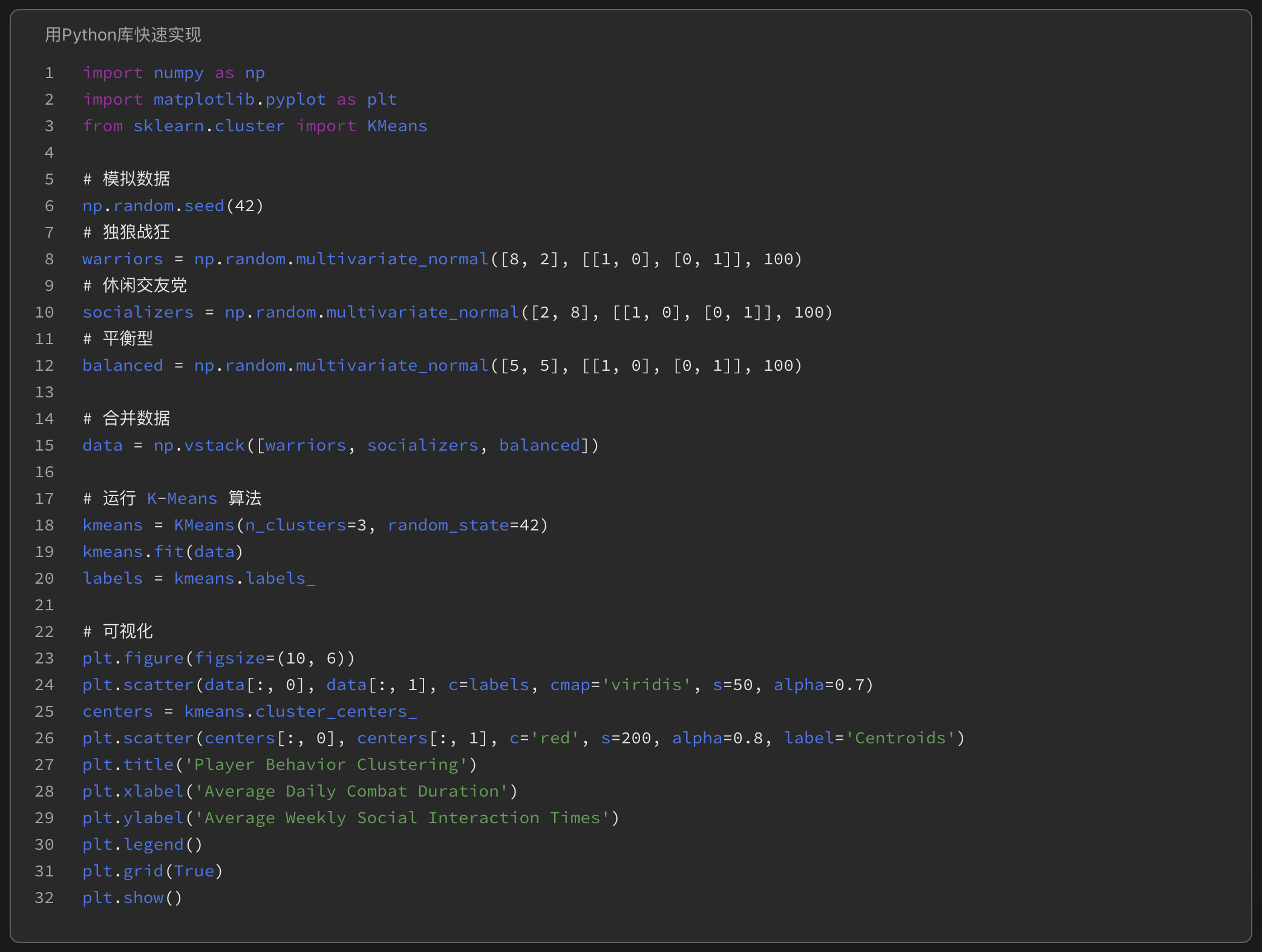
这个简单的例子(可以用Excel/Numbers模拟或用Python库快速实现)说明了聚类如何帮助我们识别出不同的用户画像,为后续针对性地设计NPC互动(比如给战狂推荐挑战副本,给社交党推荐公会活动)提供了基础。
 [案例建议与文献引用]:
[案例建议与文献引用]:
游戏行业广泛应用数据科学进行玩家行为分析和用户分群,无监督学习是其中的重要技术之一。
案例:K-means聚类在游戏用户分群中的应用
K-means聚类是一种无监督学习算法,广泛应用于游戏行业中的用户分群。通过分析玩家的行为数据(如游戏内购买历史、游戏时长、登录频率等),K-means聚类可以将玩家分为不同的群体,从而实现个性化游戏体验和优化收入。例如,某移动游戏公司通过K-means聚类将玩家分为高消费、中消费和低消费群体,并针对不同群体设计了个性化的营销策略,最终在六个月内游戏内购买增加了20%。
来源:https://blog.csdn.net/hahoo2009/article/details/143462609
在更广泛的领域,如Netflix的推荐系统,也利用了相似用户的聚类思想(协同过滤的基础)来为用户推荐可能感兴趣的内容。
来源:https://csse.szu.edu.cn/staff/panwk/recommendation/MISC/Recommendation-CaseStudy-Netflix-Chinese.pdf
3、强化学习 (Reinforcement Learning):在交互反馈中学习最佳策略
(技术原理): 强化学习模拟了生物通过与环境互动来学习的过程。
- 它定义了一个智能体 (Agent)(比如我们的NPC),在一个环境 (Environment)(游戏关卡、VR场景)中。
- 智能体可以观察到环境的状态 (State)(玩家位置、自身血量、可用技能等),并基于此选择执行一个动作 (Action)(移动、攻击、对话、使用道具)。
- 执行动作后,环境会转换到新的状态,并给予智能体一个奖励 (Reward) 或 惩罚 (Penalty)信号,反馈这个动作的好坏。
- 智能体的目标是通过不断的试错 (Trial-and-Error),学习到一个策略 (Policy)(即在什么状态下应该采取什么动作),以最大化其长期累积的奖励。
(游戏/VR/AR场景应用): 强化学习特别适合需要序贯决策、适应动态环境、甚至展现出“创造性”行为的场景:
- 高级战斗AI: 让NPC在复杂的战斗中(如《黑暗之魂》类游戏、格斗游戏),根据实时战况(敌人距离、攻击模式、自身资源)动态地、智能地选择攻击、防御、闪避、走位、技能组合,而不是依赖固定的行为脚本,从而提供更具挑战性和不可预测性的对手。
- 动态寻路与导航: 让NPC在复杂且动态变化的游戏世界中(如充斥着移动障碍物、其他动态NPC、甚至地形变化的场景)自主学习最优的移动路径,展现出更“像人”的导航能力。
- 程序化动画 (Procedural Animation): 利用RL让角色的动作(如行走、奔跑、攀爬、与环境互动)能更自然地适应地形和物理环境,减少动画师的工作量,提升真实感。
- 自适应难度调整: 让游戏系统(可以看作一个Agent)根据玩家的表现(状态)动态调整难度(动作),如调整敌人强度、资源掉落率等,以维持玩家的心流体验(奖励)。
- 虚拟宠物/伙伴行为学习 (VR/AR): 训练VR/AR中的虚拟宠物或伙伴,通过与用户的互动(用户的动作是环境变化,用户的满意度/反馈是奖励)逐渐学习到用户的偏好,展现出独特的“个性”和情感连接。
(提及代表算法类别及其产品特点):
- 强化学习算法众多,从简单到复杂:
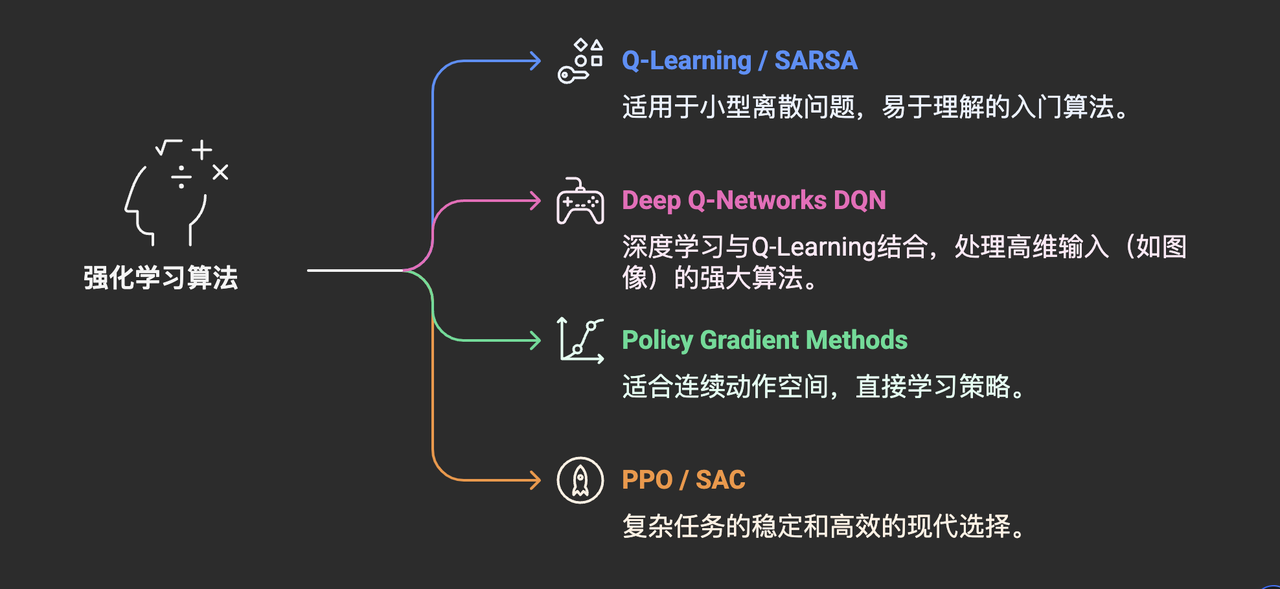
- Q-Learning / SARSA: 经典的基于值函数的方法,适用于状态和动作空间相对较小的离散问题。易于理解,是入门RL的好起点。
- Deep Q-Networks (DQN): 将深度学习与Q-Learning结合,能够处理高维状态输入(如游戏画面像素),在Atari游戏上取得突破。
- Policy Gradient Methods (e.g., REINFORCE, A2C, A3C): 直接学习策略函数,适用于连续动作空间。
- PPO (Proximal Policy Optimization) / SAC (Soft Actor-Critic): 近年来在连续控制和游戏AI领域表现优异的先进算法,兼顾了稳定性和样本效率,是目前训练复杂游戏AI的常用选择。
PM选型考量:
- 潜力巨大,但挑战并存: RL能够创造出真正具有适应性、甚至超越人类设计的智能行为,潜力无限。但它也是三者中技术门槛最高、最难驾驭的范式。
- 奖励函数设计是艺术,更是核心难点! 这是PM必须深度参与的关键环节。奖励函数定义了NPC的“价值观”和目标。一个微小的设计缺陷,比如奖励设置不当、过于稀疏或容易被“钻空子”(找到非预期的捷径获得高奖励),都可能导致训练出行为怪异、甚至完全违背设计初衷的NPC。PM需要与策划、设计师、算法工程师紧密协作,反复迭代和测试奖励函数,确保它能准确引导出期望的行为。
- 高昂的训练成本: RL通常需要海量的交互(在模拟环境中运行数百万甚至数十亿次)才能学习到有效的策略,这意味着巨大的计算资源消耗和漫长的训练时间。
- 可解释性差,“黑箱”问题突出: 很难精确解释为何RL Agent在某个特定时刻做出了某个决策,这给调试、优化和确保行为符合预期带来了巨大挑战。PM需要接受这种不确定性,并依赖大量的测试和监控来控制风险。
- 对模拟环境要求高: 高效的RL训练往往依赖于能够快速、稳定、逼真地模拟游戏/VR环境。
[案例建议与文献引用]:
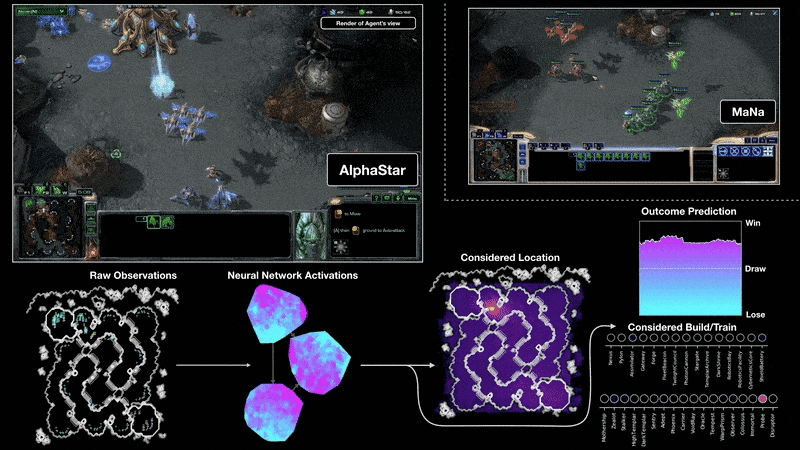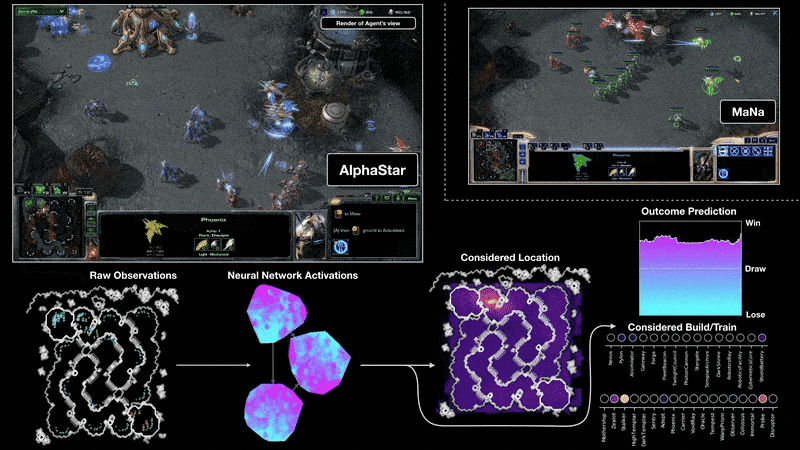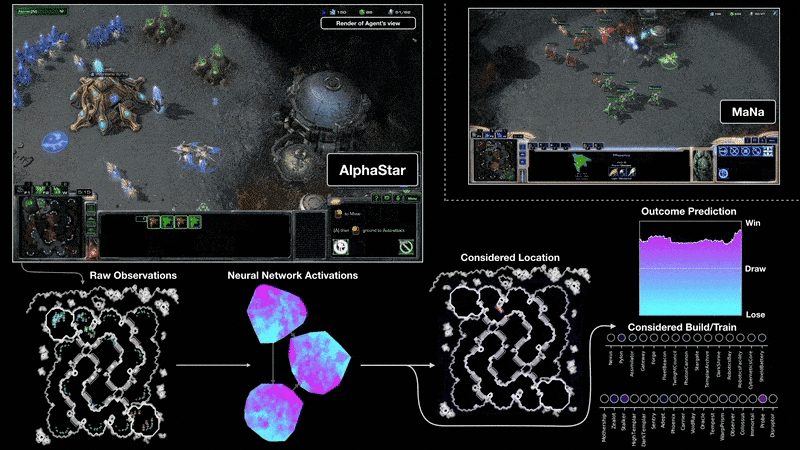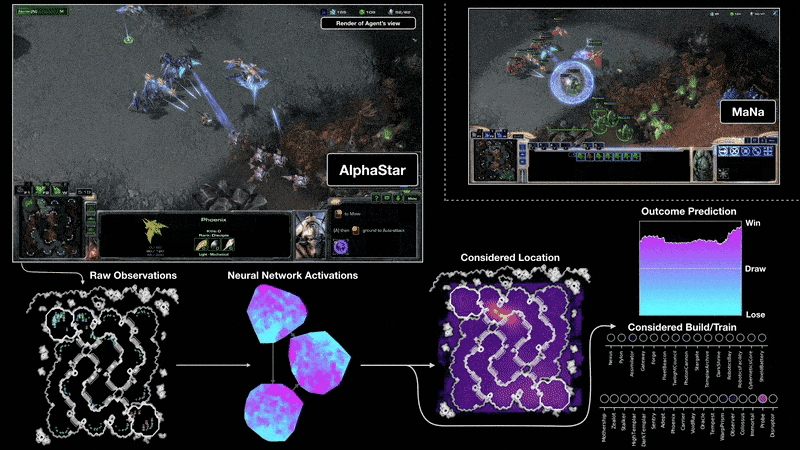
游戏开发者常用的Unity引擎提供了ML-Agents工具包,它使得在Unity环境中应用强化学习(以及其他ML方法)训练NPC变得更加便捷,其官方文档是了解RL在游戏开发中具体实践的极佳起点。(来源:Unity ML-Agents官方文档
来源:https://docs.unity3d.com/Packages/com.unity.ml-agents@latest/)。
DeepMind的AlphaStar项目展示了强化学习在复杂实时战略游戏《星际争霸II》中达到的顶尖水平,虽然其资源投入巨大,但极大地推动了该领域的发展。
来源:https://deepmind.google/discover/blog/alphastar-mastering-the-real-time-strategy-game-starcraft-ii/
在程序化动画方面,育碧的研究部门La Forge持续探索使用AI技术(包括机器学习)来创建更逼真、更具适应性的角色动画和更丰富的虚拟世界。
来源:https://github.com/ubisoft/ubisoft-laforge-ZeroEGGS
我们已经初步探索了机器学习的三大核心范式。让我们再次以AI产品经理的视角,提炼一下关键要点:
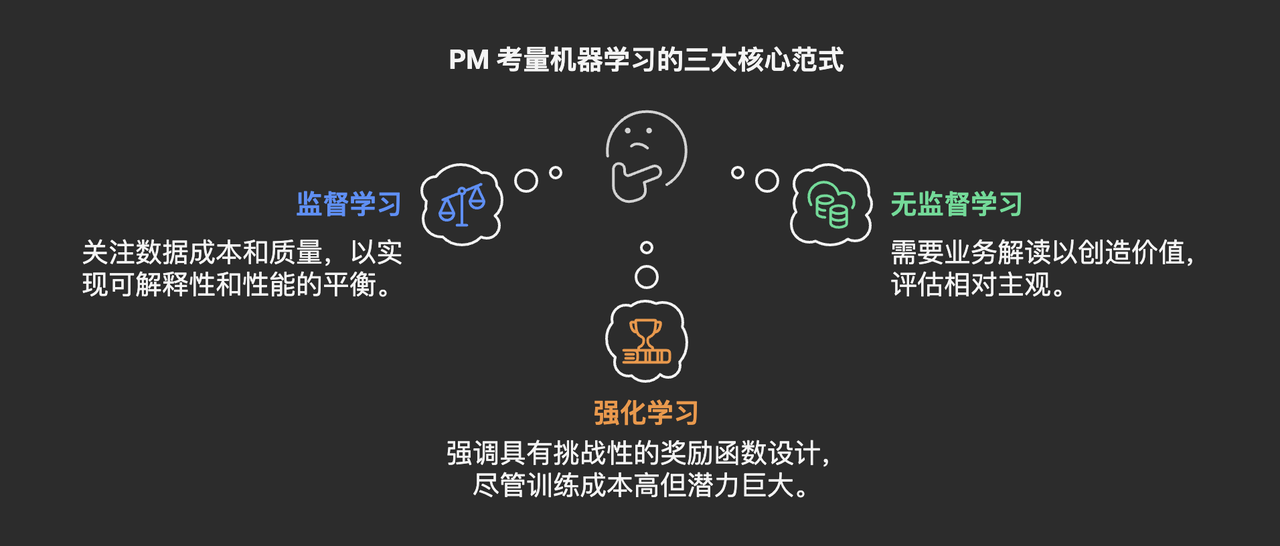
① 监督学习 (Supervised Learning)
- 核心: 从“有标签”数据学习输入到输出的映射。
- 强项: 解决定义明确的分类和回归问题,如意图识别、目标检测。
- PM关键考量:标注数据的成本与质量是生命线! 可解释性与性能的权衡。
② 无监督学习 (Unsupervised Learning)
- 核心: 从“无标签”数据中发现隐藏的结构与模式。
- 强项: 用户/行为聚类、异常检测、探索性数据分析。
- PM关键考量:结果需要业务解读才能产生价值! 评估相对主观。
③ 强化学习 (Reinforcement Learning)
- 核心: 通过与环境交互和奖励反馈学习最优决策策略。
- 强项: 适应动态环境、序贯决策、复杂行为控制(如高级战斗AI、导航)。
PM关键考量:奖励函数设计是重中之重且极具挑战! 训练成本高、可解释性差,但潜力巨大。
对于我们AI产品经理而言,理解这三大范式的本质区别、优劣势、适用场景(尤其是在游戏/VR/AR/元宇宙的背景下)以及它们对数据、成本、团队协作的要求,是做出明智技术选型、设定合理产品预期、推动AI NPC项目成功落地的基础。
现实中的复杂NPC,其“智能”往往不是单一范式的产物,而是多种技术的巧妙组合。知道何时、何地、为何以及如何组合运用这些工具,正是我们价值的体现。
今天,我们为理解AI驱动的智能NPC打下了第一块基石,认识了机器学习的三大基本“思维模式”。然而,要让NPC真正拥有“看懂”虚拟世界、“听懂”玩家心声的复杂感知能力,我们还需要更强大的武器。
在下一篇笔记 《S1E02: 虚拟之眼耳:深度学习赋予NPC“感知”虚拟世界》 中,我们将聚焦于机器学习的一个强大分支——深度学习 (Deep Learning)。
我们将深入探索神经网络的魔力,看看它是如何通过模仿人脑的连接方式,在计算机视觉(CV)和自然语言处理(NLP)等领域取得突破性进展,并最终为我们的游戏、VR、AR、元宇宙NPC装上更敏锐的“眼睛”和“耳朵”的。
敬请期待!
Mu 注: 本文作为系列开篇,旨在建立基础认知框架。文中提及的案例旨在说明概念,具体技术实现可能更为复杂或采用混合方法。引用的链接旨在提供公开可访问的参考信息,并已尽可能验证其在撰写时的有效性,但链接的长期有效性无法完全保证。在后续文章中,我们将对特定技术和应用进行更深入的探讨。欢迎大家留言交流!
参考文献资料:
1、Scheherazade’s Tavern: A Prototype For Deeper NPC Interactions:https://dl.acm.org/doi/fullHtml/10.1145/3402942.3402984
2、Ubisoft reveals AI-powered ‘NEO NPCs’ at GDC 2024:https://www.gameshub.com/news/news/ubisoft-ai-neo-npcs-gdc-2024-2638181/
3、利用K-means聚类进行用户分群:https://blog.csdn.net/hahoo2009/article/details/143462609
4、智能推荐技术–案例分析: Netflix:https://csse.szu.edu.cn/staff/panwk/recommendation/MISC/Recommendation-CaseStudy-Netflix-Chinese.pdf
5、ML-Agents Overview:https://docs.unity3d.com/Packages/com.unity.ml-agents@3.0/manual/index.html
6、AlphaStar: Mastering the real-time strategy game StarCraft II:https://deepmind.google/discover/blog/alphastar-mastering-the-real-time-strategy-game-starcraft-ii/
7、ZeroEGGS: Zero-shot Example-based Gesture Generation from Speech:https://github.com/ubisoft/ubisoft-laforge-ZeroEGGS
作者:Mu先生Ai世界,公众号:Mu先生Ai世界
本文由 @Mu先生Ai世界 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图由作者提供
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务







- 目前还没评论,等你发挥!









