
 起点课堂会员权益
起点课堂会员权益
大语言模型基础知识分享

大语言模型(LLM)作为人工智能领域的重要突破,正在深刻改变自然语言处理的格局。本文将深入探讨大语言模型的定义、基本原理、优缺点以及其在各个领域的应用。

一、什么叫大语言模型
1.1 大语言模型的定义
大语言模型(Large Language Model, LLM)是一种基于深度学习的自然语言处理模型,通过海量文本数据的预训练学习语言规律,具备理解、生成和推理文本的能力。其核心特征包括:
1.参数规模庞大:通常包含数十亿至数千亿参数(如GPT-3的1750亿参数)。
2. 基于Transformer架构:依赖自注意力机制处理长文本序列,显著提升并行计算效率。
3. 多阶段训练流程:包括预训练(无监督学习)、微调(有监督学习)和RLHF(基于人类反馈的强化学习)。
1.2 大语言模型与神经网络、数学模型的联系与区别
- 数学模型是基础:神经网络和大语言模型本质上都属于数学模型范畴 。它们借助数学理论和方法构建,如线性代数用于描述神经元间权重矩阵运算,概率论用于解释模型不确定性和概率预测 。
- 神经网络是大语言模型的支撑:大语言模型基于神经网络构建,利用神经网络强大的非线性拟合和学习能力 ,从海量文本数据中学习语言模式和语义知识 。同时,神经网络的发展为大语言模型提供了架构基础和优化方法 ,如深度学习中各种优化算法用于训练大语言模型 。
- 大语言模型是神经网络的应用拓展:大语言模型是神经网络在自然语言处理领域的深度应用和拓展 。它将神经网络与自然语言任务紧密结合,通过大规模预训练和微调,使模型具备强大语言理解和生成能力 ,推动自然语言处理技术发展,也为神经网络研究提供新方向和挑战 。
1.3 LLM的“大”体现在哪些方面?
- 庞大的参数量:LLM的“大”首先体现在参数数量上。例如,OpenAI的GPT-3有1750亿个参数,GPT-4更为庞大。参数越多,模型的语言理解和任务处理能力越强。
- 海量的训练数据:LLM依赖海量数据进行训练,包括书籍、新闻、网页内容和社交媒体等。这些多样化的数据帮助模型掌握丰富的语言模式,具备强大的理解和生成能力。
- 广泛的任务适应性:模型在多种数据上训练,赋予其从自然语言理解到翻译、摘要、情感分析等多任务的处理能力,使其具备显著的通用性。
- 巨大的计算资源需求:LLM的训练与推理依赖大量高性能计算资源,如GPU和专用加速器。随着模型规模的增加,计算需求呈指数级增长。
1.4 LLM为什么要基于Transformer架构?
在Transformer架构出现之前,自然语言模型主要依赖循环神经网络(RNN),但RNN的顺序处理方式限制了计算的并行性,且在处理长序列时,信息容易丢失或遗忘。

Transformer通过引入自注意力机制和位置编码,克服了传统模型在捕捉长距离依赖和并行计算方面的局限。自注意力机制允许模型同时关注输入序列中的所有词,捕捉更远距离的依赖关系,避免了RNN及其变体LSTM模型中存在的顺序处理瓶颈。因此,Transformer成为大规模预训练模型的基础架构,并在多个任务中展现了出色的性能。
二、大语言模型的基本原理
基本原理概述:大语言模型的基本原理是通过Transformer结构处理文本数据,利用GPT等预训练方法学习语言知识,并将文本映射到语义空间中,以实现复杂的自然语言处理任务。
大语言模型的基本原理可以通过三个核心概念来阐述,1:基于GPT的预训练框架、2:Transformer的深度学习架构,3:以及将文本转化为语义向量的映射技术。
2.1 GPT
GPT,全称是Generative Pre-trained Transformer,是一个先进的自然语言处理模型,由OpenAI在2018年推出。以下是对GPT每个字母含义的通俗解释:
- G,即“Generative”,表示GPT模型具有生成文本的能力。它可以根据输入的文本或提示,生成自然、流畅的文本内容,展现出强大的语言生成能力。
- P,即“Pre-trained”,指的是在对模型进行特定任务微调之前,先对其进行大量文本数据集的预训练。这使得GPT模型能够学习到丰富的语言知识和上下文信息,为后续的特定任务提供更好的基础。
- T,即“Transformer”,是GPT模型所用的基本架构。Transformer模型通过自注意力机制,能够识别文本中的语法和上下文,从而生成更自然和流畅的文本。GPT模型基于Transformer架构,通过多层的神经网络结构,实现了对语言的深入理解与生成。
总的来说,GPT模型通过生成式的预训练方式和Transformer架构,展现出了强大的自然语言处理能力,为自然语言处理领域的发展带来了新的突破。无论是在文本生成、语言理解还是对话系统等方面,GPT模型都展现出了广泛的应用前景。
2.2 Transformer
Transformer,源自2017年Google发布的论文《Attention is All You Need》中提出Transformer架构。
2.1 Tranformer架构主要由两部分组成:编码器(Encoder)和解码器(Decoder)
编码器,用于对输入的文本进行理解,把文本编码到包含词意、语序、权重(词重要度)的语义空间;
解码器,用于生成文本,即将编码器输出的语义空间的内容解码为文本(生成文本)
2.2 Transformer的核心机制:Self-Attention(自注意力机制)
注意力机制,用于找到一句话中重要的字/词,类似人阅读一句话,会判断这句话的重点。注意力机制这个逻辑,可以进一步拓展到多模态(图片、音频和视频)。简而言之,就是展现出一种【找重点】的能力。
自注意力机制,是指一句话通过词的彼此对比来找重点。
多头注意理解机制,找多个重点。类似我们人类看待问题的时候,建议从多个角度看待问题,以更全面地认知和理解。同样,多头注意力机制,也有这种类似,从多个角度找重点。
2.3 文本映射到语义空间
文本映射到语义空间需要两步处理:
1)Tokenizer(分词器)
2)Embedding(嵌入)
3.1 Tokenizer
GPT使用BPE(Byte Pair Encoding)作为分词器,它的原理是将字、词拆成一个个字节,统计训练中的“字节对”出现的频次,选择出现频次最高的“字符对”,合并为一个新的符号,并基于新的符号再出统计频次再进行一轮新的合并,最大达成目标大小。而这些符合的集合我们称之为词汇表,字符我们称之为token。

说明:token与我们理解的字/词并不一定有逻辑意义上的对应关系,有的时候可能是一个单词,有的时候可能是一个字,也有可能出现1/3或2/3个汉字的情况(因为一个汉字在unicode编码中是占3个字节的)。
3.2 Embedding
Embedding的一种常见实现方式是Word2Vec。
Word2Vec就是将词映射到多维空间里,词跟词之间的距离代表词跟词之间的语义相似度,所以这个多维空间又叫语义空间。
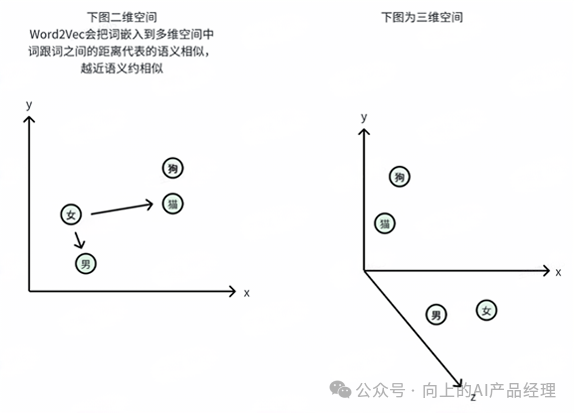
怎么理解多维空间?
同一个词在不同场景下的语义是不同的,比如“King”在性别维度表示男性,在权利维度表示国王。
所以,多维空间j就是描述一个词在不同维度(场景)下的语义。
维度越多表示词的语义越精细,Word2Vec最初的标准是300维,GPT-3为2048维。

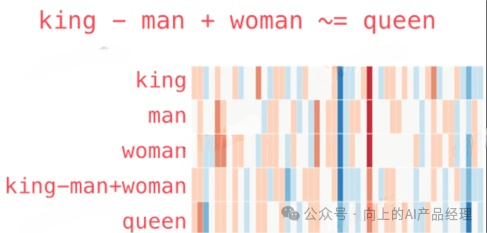
向量之间的语义是可以计算的。
三、大语言模型的优缺点
3.1 优点
- 出色的语言理解与生成能力:无论是复杂的语法结构、微妙的语义关系还是各种领域的专业术语,都能较好地处理。同时,它可以根据给定的上下文生成连贯、流畅且有逻辑的文本,生成的内容在语法和语义上都较为准确和自然,可用于文本创作、对话系统等多种任务。
- 强大的泛化能力:可以适应各种不同领域和场景的自然语言处理任务,无需针对每个具体任务重新训练一个全新的模型,在经过微调后就能在多种下游任务中取得较好的效果。
- 知识融合与迁移能力强:大语言模型在训练过程中吸收了大量文本中的知识,包括常识性知识、领域专业知识等。这些知识可以在不同任务和领域之间进行迁移和融合,有助于解决一些需要多领域知识综合运用的复杂问题。例如,在问答系统中,模型可以利用其所学的广泛知识来回答各种类型的问题。
3.2 缺点
- 计算资源需求巨大:大语言模型通常具有庞大的规模,包含数十亿甚至数万亿的参数。训练和部署这样的模型需要强大的计算资源,如高性能的图形处理单元(GPU)或张量处理单元(TPU)集群,以及大量的内存和存储设备。
- 训练时间长:由于模型规模大、数据量多,大语言模型的训练过程非常耗时。一旦需要对模型进行修改或优化,重新训练的时间成本也很高。
- 可解释性差:大语言模型是一个复杂的黑盒模型,其决策过程和生成结果的依据很难被人类直接理解。模型的输出是基于大量参数的复杂计算得出的,很难明确指出某个输出是如何由输入和模型参数决定的,缺乏透明度和可解释性。这在一些对决策过程有严格要求的领域,如医疗、金融等,可能会限制其应用。
- 存在偏见和错误:大语言模型基于训练数据进行学习,如果训练数据中存在偏差或错误信息,模型可能会学习并放大这些问题,导致生成的结果存在偏见或不准确。例如,可能会对某些群体或概念产生刻板印象,或者在一些事实性问题上给出错误的答案。此外,模型在面对一些复杂的、超出其训练范围的问题时,也可能会出现错误或不合理的回答。
- 容易被攻击和滥用:大语言模型可能会受到各种攻击,如对抗攻击,攻击者可以通过精心构造输入来欺骗模型,使其产生错误的输出。同时,模型也可能被滥用于生成虚假信息、进行网络诈骗等不良行为,给社会带来负面影响。
四、大语言模型改变的核心领域
1. 自然语言处理(NLP)
- 文本生成:自动化撰写文章、生成代码(如GitHub Copilot)。
- 对话系统:ChatGPT等实现类人交互,应用于客服、教育问答。
- 翻译与摘要:支持多语言实时翻译,提炼长文本核心信息。
2. 多模态与跨领域融合:
结合图像、音频生成(如DALL·E生成图像,GPT-4V处理图文混合输入)。3. 行业应用革新:
- 医疗:辅助诊断、医学文献分析;
- 金融:自动化报告生成、风险预测;
- 教育:个性化学习资源推荐。
五、LLM的局限与未来展望
当前局限:
1.幻觉问题:生成内容可能偏离事实或包含虚构信息。
2. 算力与成本:训练需消耗巨额计算资源(如GPT-3训练成本超千万美元)。
3.伦理与安全:存在偏见传播、隐私泄露风险(如数据训练中的敏感信息)。
4.长文本处理不足:对超长文本的连贯性与逻辑性仍待提升。
未来发展方向:
1. 多模态深度整合:增强图文、音视频的跨模态生成与理解能力。
2. 模型轻量化:通过知识蒸馏、模型压缩(如GPT-4o-mini)降低部署成本。
3. 个性化与私有化:定制化模型满足企业数据安全与垂直领域需求。
4. 伦理与可解释性:开发透明化训练机制,减少偏见与误生成。
参考文档:
作者:厚谦,公众号:向上的AI产品经理
本文由@厚谦 原创发布于人人都是产品经理,未经作者许可,禁止转载。
题图来自Unsplash,基于CC0协议。
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。







- 目前还没评论,等你发挥!









