
 起点课堂会员权益
起点课堂会员权益浅谈人工智能产品设计:LDA主题模型

LDA是一种无监督的算法,作用是从一份文档中提出文档的主题,以及主题中的词语。
一、LDA模型简介
LDA是Latent Dirichlet Allocation(潜在狄利克雷分配模型)的缩写,也是线性判别分析(Linear Discriminant Analysis)的简写。本文探讨的是第一种Latent Dirichlet Allocation(潜在狄利克雷分配模型)技术。LDA通俗的来讲就是一种主题抽取模型。它是一种无监督的算法,作用是从一份文档中提出文档的主题,以及主题中的词语。LDA模型应用范围很广,如我们熟知个性化推荐、商品标签、智能分类等等。
有监督学习和无监督学习以及半监督学习的概念是比较容易理解的。这边就简单的提一下。
我们知道,AI系统都可以抽象为如图所示的结构:
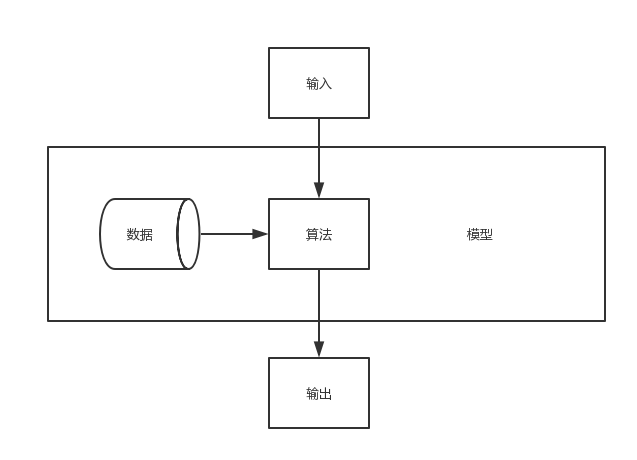
我们训练AI,就是要得到一个模型。训练模型的方式有这么几种:
- 有监督学习:即通过人工标注数据,机器从中学习得到模型,如分类、回归算法。
- 无监督学习:机器直接通过海量的数据自主学习得到模型。,如聚类算法。
- 半监督学习:机器通过少量的人工标注数据和海量的无标注数据学习得到模型。半监督学习的特点就是,用少数的人工标注数据就能得到一个不错的模型,随着模型的使用,产生的纠错数据又能反过来提升模型的精度,最终使得模型得到最优。
回到我们要讲的LDA模型。根据场景的不同,数据的不同可以选择不同的方案。如定制化场景下,可以做有监督的学习,以达到较好的精度。如在to C的产品中,则使用半监督的学习方式可以让产品具有个性化推荐的能力。
简单解析一下LDA模型的原理:
在LDA模型中,文档是由词语组成主题,再由主题组成的文章。在主题中,有词语的一个概率分布,概率越高表示与主题的关联性越大。相对的,文档中有一个主题概率分布,概率越高代表与文档的相关性越高。LDA的简化公式如下:
P(词语|文档)=∑P(词语|主题)×P(主题|文档)
LDA从词语在文档中的概率学习得出词语在主题中的概率分布以及主题在文档中的概率分布。
从公式中我们就能够很清晰的看到,如何能够提升LDA模型的准确度再融合进算法中,从而提升产品的用户体验。
关键点在于:
- 提供词语|主题的标注数据。
- 提供主题|文档的标注数据。
二、LDA主题产品设计
假设我们要做一款个性化信息流的产品,我们想运用LDA为文章打标签,并推送给具有相同标签的用户,从而实现个性化推荐,那我们要怎么做?
其实标签就可以看成是LDA中的主题,融合AI的产品的设计如果能巧妙的让用户给你提供标注数据,这样的产品体验一定是优秀的。
沿着这个思路,我们可以有这样的设计方案:
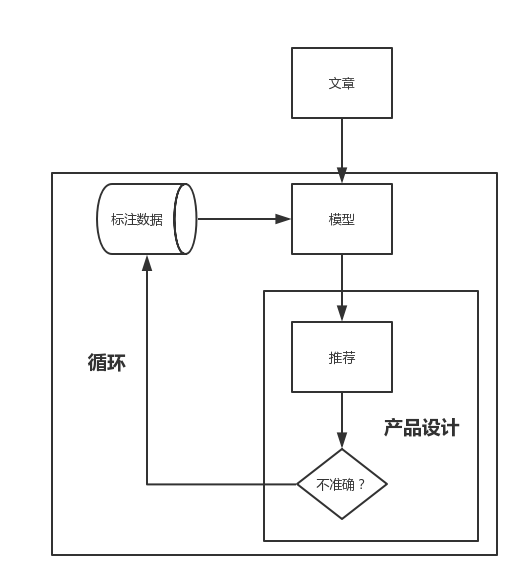
可以先让用户选择标签,然后给用户推荐一些无监督学习标注出来的同标签的文章,手机用户的点击数据、停留时长、点赞、收藏等数据,再把这些数据转化为用户对这个文章的认可程度。如果用户认可程度高,就提升这篇文章的权重;如果认可程度低的,降权。再设计一个“不喜欢”的按钮,用户点击了也对文章进行降权。如果经过海量用户的使用,可以获得较为优质的数据, 再利用这些数据进行训练,使得模型越来越精准。
总结成一幅图就是:
本文由 @ 跹尘 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自PEXELS,基于CC0协议














写的很好
写的有点过于简洁了,希望能更详细一点谢谢