
 起点课堂会员权益
起点课堂会员权益自然语言处理中“中文分词”技术中“自动切分”的几点理解

本文主要针对其中最常用的一套《北大规范》为依据,来讲解中文词汇自动切分的几个重点流程。enjoy~
概述
在人工智能中,自然语言处理是一门极其深奥的领域,自然语言处理在广义上分为两部分,第一部分自然语言理解,是指让电脑“听懂”人类的语言;第二部分为自然语言生成,是指把计算机数据转化成人类可以听懂的语言;而自然语言理解和产生的前提是对语言能够做出全面的解析,而在中文中,汉语词汇是语言独立运用的最小语言单位,因此对汉语中词汇的切分显得尤为的重要,随着自然语言的应用逐渐发展,一套完整而标准的汉语分词规范就显得特别重要,随着近几十年的发展,已经逐渐形成两套常用且较为规范的语言处理规范,本文主要针对其中最常用的一套《北大规范》为依据,来讲解中文词汇自动切分的几个重点流程。
在《北大规范》中一共含有40个词类,其中包括名词、动词、代词、形容词、数词、量词、副词、介词、连词、助词、语气词、叹词、象声词、时间词、处所词、方位词、区别词、状态词、副动词、名动词、副形词、名形词、前缀、后缀、成语、简称、习用语、标点。所有的句子都是通过不同的词类组成,下面就为大家讲解一下中文分词的几个流程
歧义
现代汉语的复音词结构,使少量的的字符通过排列组合来表示大量的词汇,最容易出现的问题是歧义问题,歧义问题在汉语中普遍存在,因此在中文如何消除歧义问题是中文分词重点解决的问题,简单给大家大家举个例子:“结合成”这个词,在分词过程中就有多种分词情况,如:“结合”“成”或“结”“合成”两种,这只是其中一种情况,通常情况下,在一个句子中多个词汇存在这种问题,这样就无形中给分词造成了很多麻烦,这只是一个小插曲,大家不要认为这样的情况吓到了,下边我就给大家重点介绍一下中分分词中的几个步骤:
分词流程
先来个图理解一下:
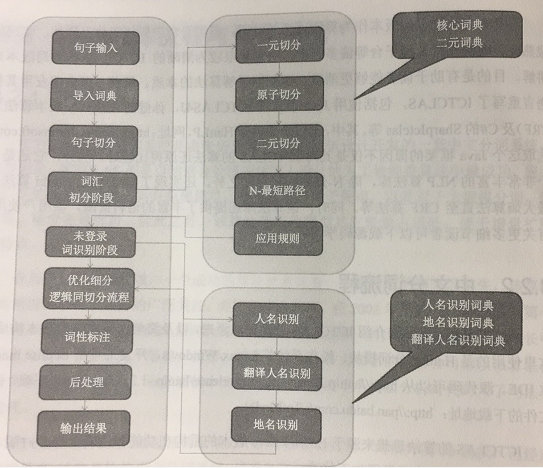
1. 句子切分
在中文分词是,有时输入的不单单是一句话,有可能是一整篇文章或一整段话,所以先要进行预处理,句子切分是中分分词的一个预处理阶段,主要是对输入的整篇文章或整段句子进行句子切分,一篇文章是被一些特殊的标点符号分隔的字符串,这些标点符号包括“省略号”“单引号”“单引号”“多引号”“逗号”“冒号”“感叹号”“问号”“换行”等,句子切分就是依靠这些分隔的标点符号,将整段或整篇文章分隔成一个个的字符串,存储起来,为后续中文分词做准备。
2. 分词词典
在词汇切分中,中文词库提供了相应的词汇的词典,其中包括一元语言词汇词典、二元语言词汇词典、人名和地名词典、组织机构词典、专有名词机构词典,这些在词汇词典在切分过程起到重要作用,大家可以在相应的地方下载。
给大家简单介绍一下词典的结构,一元词典结构如下,一元词典的第一列是词,第二列是第一词性,第二列为第一次性的出现的词频(次数),第三列为第二次性,第四列为第二词性的词频,以此类推,关于词性可参照词性对照表,此处不做注释。
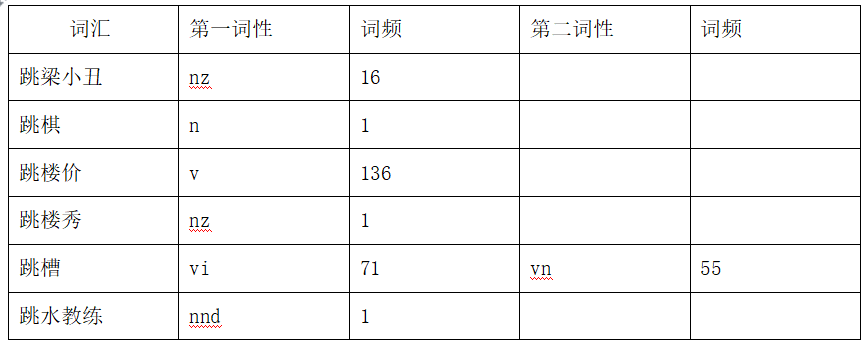
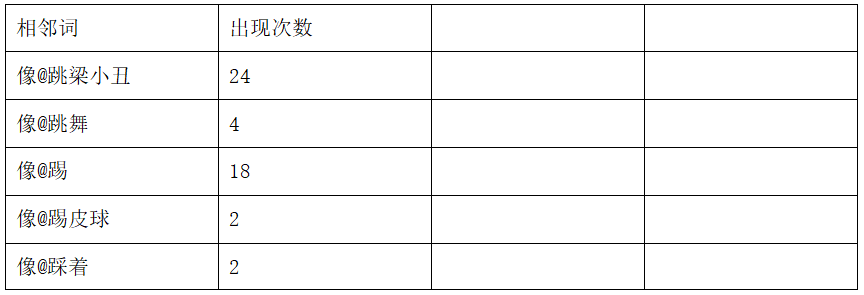
二元词典的结构如图,二元词典的第一列是相邻词中间用@隔开,例如:“像@跳梁小丑”,表示前一个词是像,后边的一个词是跳梁小丑,第二列是该相邻词在预料库中出现的次数,
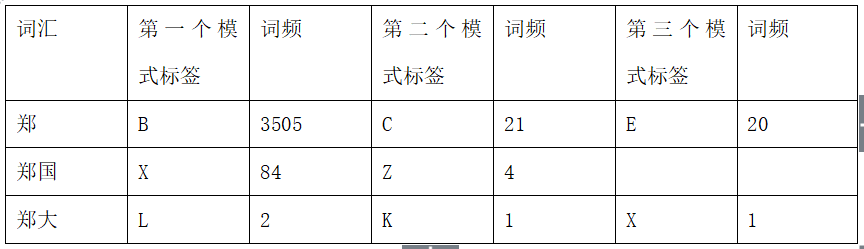
人名词典的机构如图:词典的第一列是词汇,第二列为第一个元模式的标签,第三列为第二个元模式的标签,第四列为第二个元模式的标签,以此类推,具体的元模式标签表可参照元模式表,例如:B代表姓氏,C代表名1,D代表名2,E是单名,F为名前缀等,张三的组成为BC,周润发的名字的组合是BCD,老李的组合为FB。具体
3. 粗分
(1)字符切分
将上文句子切分得到的句子字符串数组再次切分,将每个句子字符串转化为成单个字符,包括单个汉语字符,单个英文字符、单个数字字符,例如,我是中华人民共和国13亿人民中的一员,变成一个数组,如:我/是/中/华/人/民/共/和/国/1/3/亿/人/民/中/的/一/员/,存储到一个新的数组中。
(2)构建初级一元词网
构建一元词网,是将得到的字符数组进行一元词典查询,将获得的字符结果进行一元词典最大匹配,查找词汇,将查到的所有词汇和带有词性、词频等信息存储到一个数组中,构建一个初级的一元词网。
查询词典的过程就是最大匹配的过程,具体的匹配方式如:中华人民共和国,从“中”字开始查词典,找到与“中”字成词的词,全部取出,如:“中”“中华”单个字也算一个词,然后在从“华”字开始查询词典找到与华字成词的词如:“华人”;依次往下查,然后把整个句子中所有的字符全部查询一遍,将所有的成词全部返回,同时需要记录每个词的词性、词频、在词典的位置(行和列的位置),形成初级一元词网。
(3)原子切分
原子切分的目的是,将初级一元词网中的非汉字字符,如英文字符或数字字符进行合并,形成一个新的词汇,并为其赋予词性,构成原子词,如:3,.,1,4,1,5,9,合并成3.14159,如i,p,h,o,n,e,合并成iphone,将处理后的结果,重新变成一个一元词网,形成一级词网。
(4)二元词网
用一元分词的结果查询二元词典,最大匹配查找到二元词典(此处匹配的方式和一元匹配相同),生成二元词图,同时需要返回该词的词频。二元词图为像@跳梁小丑
4. 消歧
通过计算整个句子所需要的最小权重获取最有结果,整个句子所需要的权重是所有词汇词频之和的倒数(权重是词频的倒数)举个例子:
“中华人民共和国”根据二元词典的匹配结果是
中@华 15
华@人 14 华@民 13
民@国 12 民@人
人@民 19
民@国,将这些词拼成完整句子的权重最小的一个。输出句子结果。
5. 识别实体名词
在消歧后获得的结果有时候仍然不是我们想要的结果,因为在句子中仍然有部分词汇我们是无法理解的,因为在上述几步中未识别出来的词汇我们已经做了标记,此时需要对消歧后获得的结果与人名词典、地名词典、专有名词词典进行匹配,匹配的方式与查询一元词典的方式相同,识别结果中人名、地名、专有名词,将识别出的名词结果加入到词图中,形成最后结果进行输出。
6. 输出结果
根据以上几部处理,会将整个结果切分出来,同时会返回相应词性信息,最终结果示例:
石国祥/nr, 会见/v, 乔布斯/nrf, 说/v, iPhone/nx, 是/vshi, 最好/d, 用/p, 的/udel, 手机/n 。/w
以上就是整个中文分词的过程,写的比较粗浅,仅供大家参考,如果大家有何见解可以一起讨论。
本文由 @成就梦想就去拼 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来源于网络









相应的地方是哪里呀😅
看完,脑瓜子,嗡嗡的
写的比较粗浅,读起来是有点懵,见谅