
 起点课堂会员权益
起点课堂会员权益数据驱动优化:如何利用 KNN 算法驱动产品优化?

在互联网行业中常常有利用数据分析或者数据挖掘的结论来应用到产品中,驱动产品的优化,提升产品的各项KPI 指标, 在数据挖掘和数据分析的背后会涉及到一些数据挖掘或者机器学习的算法。本文主要是knn算法原理的介绍,以及在它在互联网行业中的具体应用,后续会介绍这个算法的具体实现(R 语言和python 语言)。
一、knn 算法原理:
现在假如有一个样本, 样本中的每一个叫做个体, 我们已经知道这些个体所属的类别,现在有一个新的未知类别的个体,我们可以通过计算它与样本中所有个体的相似距离,然后找出与它具体最小的k个个体, 这k个个体最多的类别就是这个新的个体的预测的类别。
算法步骤:
1.计算测试数据与各个训练数据之间的距离
计算具体之前需要对数据中的每一个属性进行数据归一化,防止数据过大对距离的计算产生影响:
数据归一化:
x* = (x – x_mean)/(x_max -x_min)
x_mean 表示数据的均值, x_max 表示数据的最大值, x_min 表示数据的最小值
例如有一个属性的取值为:20, 40, 80, 100,则首先计算平均值: (20+30+80+100)/4=60。
最小值:20 ,最大值: 100,则归一化后每个值为:
- (20-60)/(100-20)=-0.5
- (40-60)/(100-20)=-0.25
- (80-60)/(100-20)= 0.25
- (100-60)/(100-20)=0.5
2.计算各体之间的距离公式如下
- 按照距离的递增关系进行排序;
- 选取距离最小的K 个点;
- 确定前K 个点所在类别的出现频率;
- 返回前K 个点中出现频率最高的类别作为测试数据的预测分类。
二、在互联网实际情景中的应用
1. 需求背景
现在某app 上了一个歌词制作的功能, 每天会有一定的用户去使用歌词制作的功能,制作的歌词会经过外包团队的审核,来判断这个歌词是否能够投入使用。
现在根据一段时间的审核,已经能够根据制作歌词质量的好坏来将整体歌词制作的用户细分为:优质用户,即制作的歌词数目又多质量又高;一般用户,制作的歌词数和质量都属于普通的情况;垃圾用户,即制作的歌词数目不多质量又差。
业务方需要提高整体的歌词制作质量所以希望能够根据现有的优质用户具有的特征,去发现更多这种类似的用户,来不断提高整体的UGC 歌词。
2. 需求沟通
数据分析师根据对业务的理解与业务方沟通,探讨可能决定一个歌词制作的用户是否是优质用户可能具有的特征,以及业务方根据业务的熟悉和敏感度给出的分析建议,然后再次分析这个需求的需求目的以及需求执行的可行性(是否有支持的数据)。
3. 数据探索
根据沟通后的结论,数据分析师从数据仓库提取相对应的数据,即提取三类用户的一些属性特征及其用户ID,如下图所示:
- userid 指的是用户的账号
- song_play_7 指的是过去 7 天的平均播放量
- lyric_activity_7 指的是过去 7 天的对歌词有效活跃行为: 如歌词搜索, 歌词报错,歌词分享,歌词翻译,歌词改错等
- type: 代表用户是属于哪一种类型的用户: 优质 2 , 一般 1 ,垃圾 0
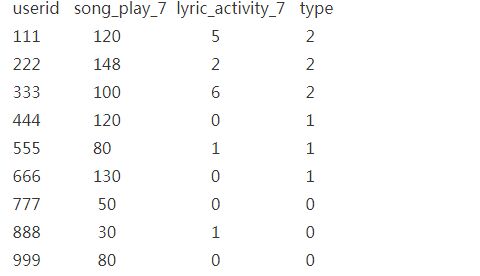 本次例子假如是没有缺失值和异常值,一般来说要对数据中的缺失值和异常值进行处理。比如去掉异常值,对缺失值进行均值或者众数来代替。
本次例子假如是没有缺失值和异常值,一般来说要对数据中的缺失值和异常值进行处理。比如去掉异常值,对缺失值进行均值或者众数来代替。
4. knn 算法预测一个新用户是否是属于优质用户
假如已经知道这个用户的播放量为140,报错次数为3,归一化处理后为:0.932203,0.5
首先对上面的数据进行归一化处理:
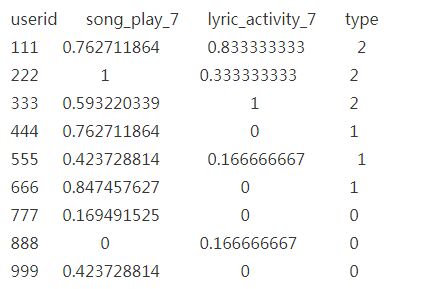
计算这个新的用户和图中的每一个用户的欧式距离为:
((0.932203- 0.762711864)^2+(0.5-0.833333333)^2) 的开方根
依次计算结果如下:
则最小距离的前三位分别为0.373948311, 1.16863508, 1.537825481,他们对应的type 都是 2 ,即优质用户, 则可以判断这个新用户为优质用户。
- 0.373948311
- 1.16863508
- 1.537825481
- 3.504101344
- 4.363063227
- 5.500652804
- 6.544595038
- 7.392345678
- 8.515194827
类似的大盘的所有的用户都可以采取这种方式来找出优质用户进行拉新。
5. 结果反馈模型落地
将这个模型的预测过程和结果与业务方沟通,并且安排模型落地,并监控上线之后的效果,不断改善模型.
6. 可能具有的成果
根据这个模型业务方发现了优质用户所具有的特征属性,通过运营的方式拉取很多优质用户,大大提高整体的优质歌词的比例,提高KPI 指标。
本文由 @陈友洋 原创发布于人人都是产品经理。未经作者许可,禁止转载。
题图来自 pexels,基于CC0协议









欢迎关注个人公众号: 【DS数据科学之美】
最大问题是最后的type,如何判断优质用户和一般用户。 training set是拍脑袋的么?
优质的用户是和业务方定出来的
knn模型我记得是每次运算都要重新计算距离的吧,不能把模型值存起来,也不能增量训练
这里只是提供了一种方法 也可以用其他的分类预测方法 比如决策树 逻辑回归
有这个缺点 只是其中一种方法 也可以用逻辑回归哈
如果已知现有个体所属的类别,说明已经有对于各类的定义;为什么不直接使用这个定义,而要用与已知个体的距离计算呢?
因为我们要用这种方法去大盘去扩散,目前还不能确定已知的类别具有的属性特征、所以要用这种方法
这个确实是个悖论,我都已经定义了各类,为啥还要用knn呢,我直接按照我的定义规则去判断不就好了吗
虽然有点地方没看懂,不过写的真心不错,纯纯的干货
谢谢你