
 起点课堂会员权益
起点课堂会员权益AI赋能游戏:问答机器人的设计与实现
AI发展快速,最适合的应用场景,应该是游戏了。光是NPC的问答、选项,就有很多可以操作的空间。本文从游戏行业出发,分析了问答机器人的实现原理和语料的经验,供大家参考。

随着AI这两年的快速发展,游戏厂商跃跃欲试如何让AI融入游戏。
半年前,我们也在游戏内嵌社区中,上线了一款以大语言模型为核心打造的问答机器人,旨在满足玩家快速获取攻略的需求。
这篇文章,将以游戏行业产品经理的角度,分享这款问答机器人的实现原理,及其语料的制作经验。
一、为什么需要问答机器人
问答机器人所落地的游戏,是一款三国策略类游戏。游戏中玩家被随机分到魏蜀吴中的一个国家,并通过一系列玩法攻城略地,扩展疆土。玩家可以招募各色三国英雄,并给英雄搭配不同装备、学习不同技能以提升战力,并可以组建不同的英雄阵容去挑战别的玩家以及掠夺别国的城池。因此,游戏玩法的自由度给予了玩家很多策略探索的可能。
起初,我们只是搭建了一个问答社区,供用户发表问题与分享攻略心得。随着玩家人数增加及赛季的深入,玩家对攻略的需求日益明显。官方发布的攻略,不一定能满足玩家快速获取攻略的需求。有时候玩家只想找一个答案,却要看完一整篇攻略。因此,我们想通过智能问答机器人的形式,满足玩家快问快答的痛点,以提升玩家的游戏体验。
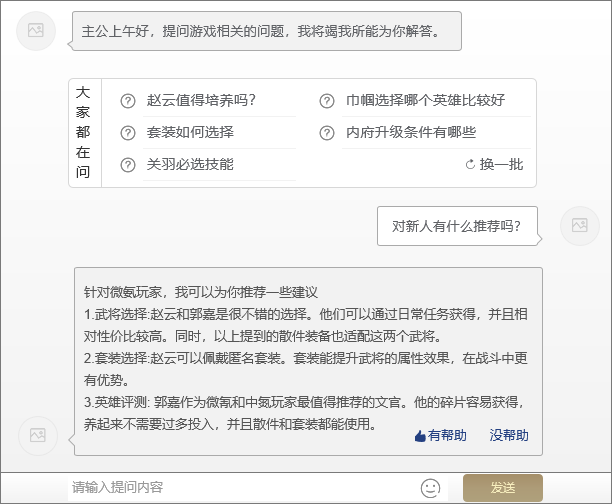
我们的智能机器人名为“诸葛先生”,以H5的形式开展对话。对用户来说没有复杂的功能,只要提问,机器人就会回答。
(页面样式这里用原型图代替了哈)
二、机器人技术原理:大语言模型RAG的应用
在介绍问答机器人的原理前,先说一个前提,就是我们的大语言模型的语料库中,有一种语料是QA形式的,即一问(question)一答(answer),与一般的段落形文章有所区别。关于语料库的介绍,下边章节会继续细说。这里将继续讲机器人的运行原理。
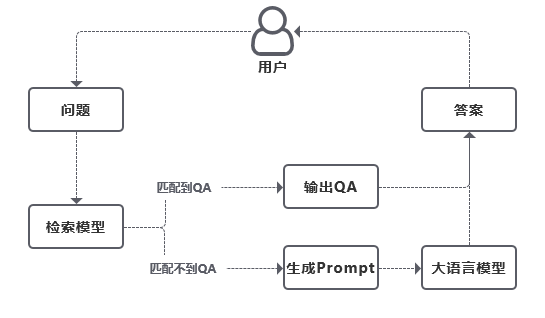
如下图,在用户提出问题后,我们的机器人分有两个答案输出逻辑。首先,用户提问的问题都会先进行内容检索,通过检索模型检索出与用户提问相关的内容。当检索到用户提问有匹配的QA时(即玩家提问匹配到语料库中预设的Question),则程序会直接输出Answer;另一种逻辑是,当检索模型没有检索到匹配的QA,那程序就会继续检索其他内容(如文章段落),并产出一条带内容的提示词(prompt)输入到大语言模型中,由大语言模型生成答案。
举个例子,假设用户提问了“赵云怎么培养”,则程序会通过检索模型,先检索是否存在与“赵云怎么培养”接近的question,存在则输出对应answer,否则找出“赵云培养”相关的内容。我们比拟程序找到的相关内容为AABB,此时给到大语言模型的提示词(prompt)就是:“AABB,请根据上述内容回答:赵云怎么培养。”大语言模型则根据上述提示词生成答案。
为什么我们不直接使用大语言模型,而是前置一步加入检索模型呢?
我们知道,大语言模型基于神经网络模型,使用大量的语料库进行训练,比如互联网上的大量文本数据。因此,大语言模型能高效准确地回答通用知识类的问题。而游戏属于专有领域,如何让大语言模型直接回答专有领域知识,则它给出的答案必定会差强人意(答非所问或是回答不出)。因此我们会先前置一步进行内容搜索,通过内容来约束大语言模型的生成。这样的技术逻辑也称为RAG(Retrieval-Augmented Generation,检索增强生成)。
RAG其实就是对大语言模型的检索能力及联想能力的外扩,让大语言模型在可控范围内生成更准确高精的回答,尤其适用于专有领域的问答工具。RAG的原理如下图:
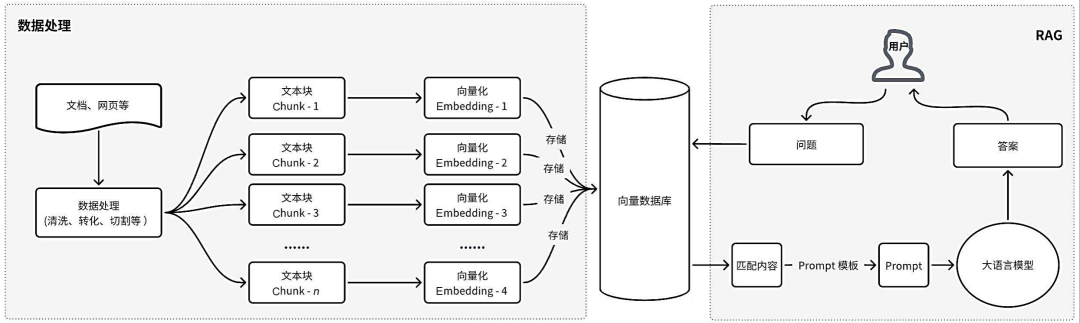
图片源自《Chatbot从0到1》(第2版),作者李佳芮、李卓桓
RAG 系统的起点一般是一个文本文档的语料库,简单看起来是这样的: 把文本分割成块,然后把这些分块嵌入到向量与transformer编码器模型,把所有这些向量建立索引,从而查询出与用户提问相关的上下文,最后创建一个带上下文的大语言模型提示语,让模型回答用户的查询。
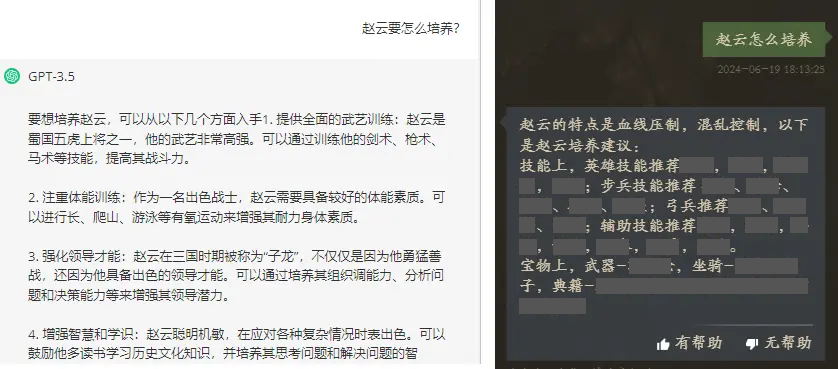
我们可以对比有无检索模型对回答的差别:
大语言模型同样是ChatGPT3.5,提问“赵云要怎么培养”,单纯使用大语言模型,而没有检索模型的约束时,回答的内容就和游戏不沾边(左图)。而使用了检索模型,让大语言模型的回答就完全贴合游戏了(右图)。
三、问答质量的打磨调优
为了提升机器人的回答准确率。我们的调优有几个方面:
增强对用户提问的理解
对于用户的提问,除了分词切割,我们还有错字甄别、同义词判定等逻辑,希望程序能尽量清晰理解用户的意向。
增强检索模型的召回质量
在众多语料中如何找到最匹配玩家的内容呢?我们的检索算法,会在对用户提问进行分词后,会先用BM25算法根据关键词对文档进行第一次评分,然后根据评分阈值提取top-k文档进行第二次评分,还有问题和文档稠密向量的相关性评分等。每一步都可能影响检索的内容及LLM的回答结果。
选择更智能的语言模型
机器人上线初期,使用的模型是国内的ChatGLM2.0。但通过拉取用户的实际问答数据,我们发现答案质量并不理想,答案中存在较多答非所问、胡编乱造的问题。并且在多次调优检索模型后(提高召回文档的相关性),答案质量仍然不佳。
于是我们考虑更换大语言模型。我们找来了两款智能体做对比,分别是ChatGPT3.5及Google旗下的Gemma。三者对比后我们发现,ChatGLM2.0的幻觉问题较其他两个模型会更为明显。意思就是,如果检索模型召回的文档中不存在用户提问的相关内容(相关性低),则ChatGLM2.0会一本正经胡说八道。即便是检索模型召回的文档中有用户所需的内容(相关性高),ChatGLM2.0也可能会回答失准。
最后我们选择了ChatGPT3.5。对比下来,ChatGPT3.5在对话生成的流畅度、连贯性以及上下文理解方面的表现都更出色,能够生成更加精准和自然的回答,对于无法回答的问题,也会更直接地告知用户它不清楚。
四、语料的构成
如果说模型是问答机器人的肉躯,那语料就是血液。语料足够多,覆盖面足够广,问答机器人才会更具活力。
我们的语料有几个部分构成:
- 游戏内所有呈现给玩家的文案,包括道具名称、说明及玩法简介。这类内容属于短内容,只有单个句子或单一段落。
- 发布于官网、论坛的游戏攻略。这类内容属于长内容,由多个段落构成。
- QA问答对。一问一答的固定内容。
如前所述,我们机器人分了两个答案输出逻辑,如果检索模型命中QA,则会更快给玩家产出答案。基于此,我们加大了QA问答对的产量,以提升问答效率。QA来源于玩家的真实提问,我们提取了高频问题,以及部分刁钻的提问,做成了问答对。
制作问答对比较费人工,因为answer都是人工写的,有时候还要玩一下游戏验证写的answer是否正确。为了节约工时,我们又借用了AI工具协助我们生产问答对。这里AI工具的作用不是帮我们快速生成答案,而是提前生成玩家可能问到的问题并产出答案。我们给AI喂入上述语料中的2-攻略长内容,并让AI根据文章内容中生成QA。不过,虽然生产速度提高了,但内容的实用性却并不高。AI生成的问题并不像玩家的提问,更像是老师出的考题,需要再二次修改问答对的内容。因此,目前的问答对维护还是集中在人工生产。
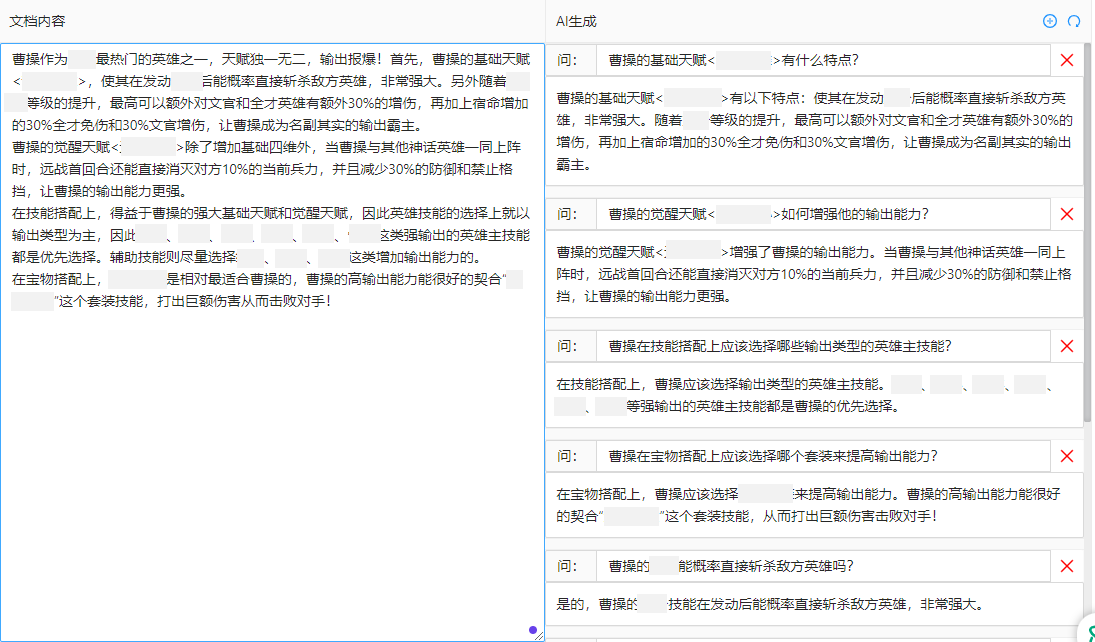
五、问答机器人的未来创想
我们的问答机器人还有很多优化空间。目前,虽然它在提升玩家体验方面已经取得一定成效,但仍存在一些需要改进的地方。例如尚未开发连续对话,玩家无法追问,造成对话交互不够自然流畅。此外,随着游戏内容的不断更新,我们的语料库也需要持续地维护和扩充,这也是需要不断消耗人力的工作。
不过我相信,问答机器人将在未来的游戏世界中扮演更加重要的角色,为玩家带来更加精彩和便捷的游戏体验。
欢迎在评论区一起探讨问答机器人的更多可能~
作者:杨桃,游戏行业B端产品经理,爱用文字记录观察及想法。
本文由 @杨桃 原创发布于人人都是产品经理,未经许可,禁止转载。
题图来自 Unsplash,基于CC0协议。
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。









请问下 从语料学习训练到成为可用的问答机器人,大概用了多久?
从0到1的阶段其实很快,一个月左右就产出模型和功能了。不过,验证问答效果及打磨问答质量的用时就比较久,花了将近半年。
否则找出“赵云培养”相关的内容。我们比拟程序找到的相关内容为AABB,此时给到大语言模型的提示词(prompt)就是:“AABB,请根据上述内容回答:赵云怎么培养。”这段内容没看懂,AABB是什么意思?能不能举一下具体的例子,谢谢
好像是把大模型找到的相关内容,再以一个新的prompt输入给程序,新的指令不是赵云怎么培养,而是根据AABB的内容回答赵云怎么培养
明白了,谢谢
是的,正如那位朋友说的那样。当用户提问“赵云怎么培养”,检索模型会找出一段内容,然后再把这段内容加上用户的提问,以提示词的形式喂入大语言模型。
再举个例子:
玩家提问:赵云怎么培养
检索模型:找到的内容是“赵云是一个×××的英雄,他应该这样培养:×××。”
大语言模型的提示词:“赵云是一个×××的英雄,他应该这样培养:×××。,请根据上述内容回答:赵云怎么培养”
明白了,谢谢