
 起点课堂会员权益
起点课堂会员权益刚发布就被对标Sora,这个国产模型来头这么大?
在AI视频生成领域,国产模型Vidu以其惊人的真实度和创新能力引起了广泛关注。Vidu能够根据简短的提示词生成长达16秒的逼真视频,其效果足以媲美Sora,甚至在某些方面超越了它。让我们跟随作者的视角,一起来看看吧。

前几天,世超上网冲浪的时候,刷到了几个 AI 视频片段。
大船驶来的压迫感,被风吹起的发丝和丝巾,太空人直接走进现实菜园。。。一幕幕把我看得是一愣一愣的。

真实度也是一绝,在湖边随着镜头移动,不仅光线跟着变化,连天空、树木的变化都跟咱肉眼看到的没差。

要不是右下角有水印,我还差点以为是 Sora 的视频又上新了。
所以这次的主角不是 Sora ,也不是各位差友熟知的 Pika 、 Runway 那几个 Sora 竞品,而是初出茅庐的国产视频大模型 Vidu 。
咱看到的那些视频,就是前几天, Vidu 在中关村论坛的人工智能主题日上公布的。
它最长能生成16秒,一句“木头玩具船在地毯上航行”的提示词,就能生成下面这长长的一段,一镜到底的丝滑程度,怕是路过的谋子导演看了都会点赞。

Sora号称能真实模拟物理世界的拿手戏, Vidu 照样也能实现。
让它生成一段“汽车加速驶过森林里乡间小路”的视频,像是树林缝隙透过的阳光,后轮扬起的灰尘,都很符合咱们的日常认知。

而且 Vidu 的想象力比咱人还要丰富,画室里的一艘船驶向镜头的场景,它分分钟就能给“拍”出来,看这效果,不知道该有多少动效师瑟瑟发抖了。

甚至在某些提示词下, Vidu 的理解能力比 Sora 还强,比如“镜头绕着电视旋转”的提示词, Sora 压根儿就没 get 到旋转的意思,反而是 Vidu 能轻松理解。

有一说一,在看完 Vidu 的这些视频后,世超是真觉得它是目前市面上,唯一一个能在画面效果上和 Sora 拼一拼的模型。
虽然现在 16 秒的 Vidu 在时长上还比不上 60秒的 Sora ,但它的进步也确实是肉眼可见的快,据极客公园消息,上个月, Vidu 在内部只能生成 8 秒的视频,上上上个月,还只能生成 4 秒的视频。
反正媒体们都把 Vidu 比作是“ Sora 级视频大模型”,网友们也都在评论区喊话催他们赶紧开放内测。
不过这里面世超更好奇的是,咱之前压根儿都没听说过 Vidu ,怎么突然平地一声雷,搞出了这么大的阵仗?
我们也顺藤摸瓜找了找资料,发现Vidu身上,值得说道的东西还挺多,甚至仔细咂摸下,还能从Sora身上找出点Vidu的影子来(世超可没说反)。
它背后是一家名叫生数科技的公司,别看这个公司才刚满一周岁,但它可是在娘胎里就开始攒劲儿了。因为它的亲妈,是清华系AI 企业瑞莱智慧,背后的研究团队,几乎全是这里面的人。
而在成立生数科技之前,团队就已经把视频大模型研究得很深入了。
尤其是在图像生成这块很火的扩散(Diffusion)模型,他们算是业内第一批研究这个模型的,整出来的论文也在 ICML 、 NeurIPS 、 ICLR 各种顶会发了个遍。
正是因为有这么好的底子,早在2022年9月的时候,团队就找到了做 Vidu 的灵感,就是下面这篇论文。

世超让AI帮咱解读了下,大概的思路就是,扩散模型在生成图像这块挺强,而大语言模型里用的Transformer有个规模(Scale)效应,参数堆得越多,性能就越好。团队就想着,能不能把这两个的优点结合一下,整个融合架构,提升图像生成的质量。
于是他们转头把扩散模型里面的 U-Net 给换成 Transformer ,还起了个名字叫 U-ViT ( Vision Transformers )。结果试下来发现这么一结合还真有用,光是相同大小的 U-ViT ,性能就比 U-Net 强了。
那好嘛,既然这条路走得通,他们也顺势把技术路线定在了 U-ViT 上。
然鹅。。。在团队悄悄酝酿 Vidu 的时候,大洋彼岸的UC伯克利的一个研究,却让 OpenAI 的 Sora 捷足先登了。
就在清华小分队提交论文的两个月后,UC伯克利也在预印平台ArXiv上提交他们的论文了,一样说要把Transformers揉在扩散模型里面,只不过名字起的更直白了点,叫DiT( Diffusion Transformers )。
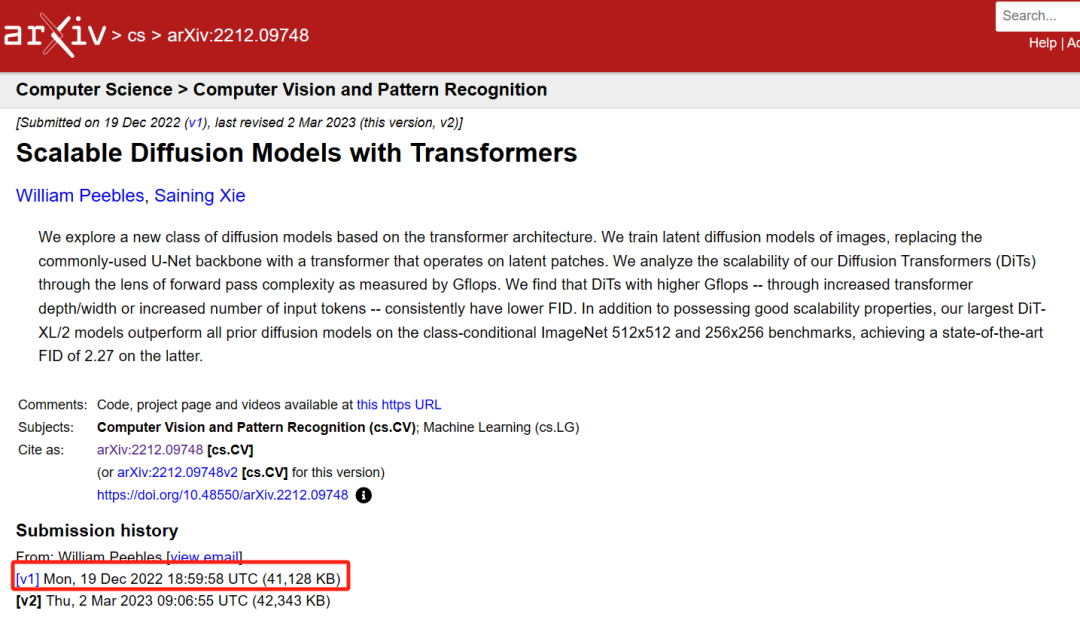
看着是不是挺眼熟,没错, OpenAI 的 Sora 模型,用的就是伯克利的 DiT 技术路线。
但因为清华小分队早发了两个月,当年的计算机视觉顶会CVPR 2023还以“缺乏创新”的由头,拒了 Sora 的 DiT ,收录了 U-ViT 。
而且早在2023年年初的时候,清华小分队还用U-ViT,训练出了一个近10亿参数量的开源大模型 UniDiffuser 。

算是第一个用行动证明了,融合架构也遵守 Scaling Law 这一套规则,也就是说随着计算量、参数量越来越大,模型的性能就会随指数级上升。而这个 Scaling Law ,同样也是 Sora 这么强的秘密武器。
所以照这么来盘算,Sora其实还得叫Vidu一声祖师爷才对。。。
但现实世界却是, DiT 被 OpenAI 带着一路飞升。
清华小分队呢,计算资源没 OpenAI 那么到位,也没 ChatGPT 这种珠玉在前,总之就是啥啥都不完善,他们只能慢慢来,先做图像、 3D 模型,等有家底儿了,再去做视频。
好在他们身上还是有点实力在的,稳扎稳打慢慢也赶上来了。去年 3 月,清华小分队们成立了生数科技后,就在马不停蹄地搞自家的产品,现在图像生成和 3D 模型生成大伙儿都能免费用了。
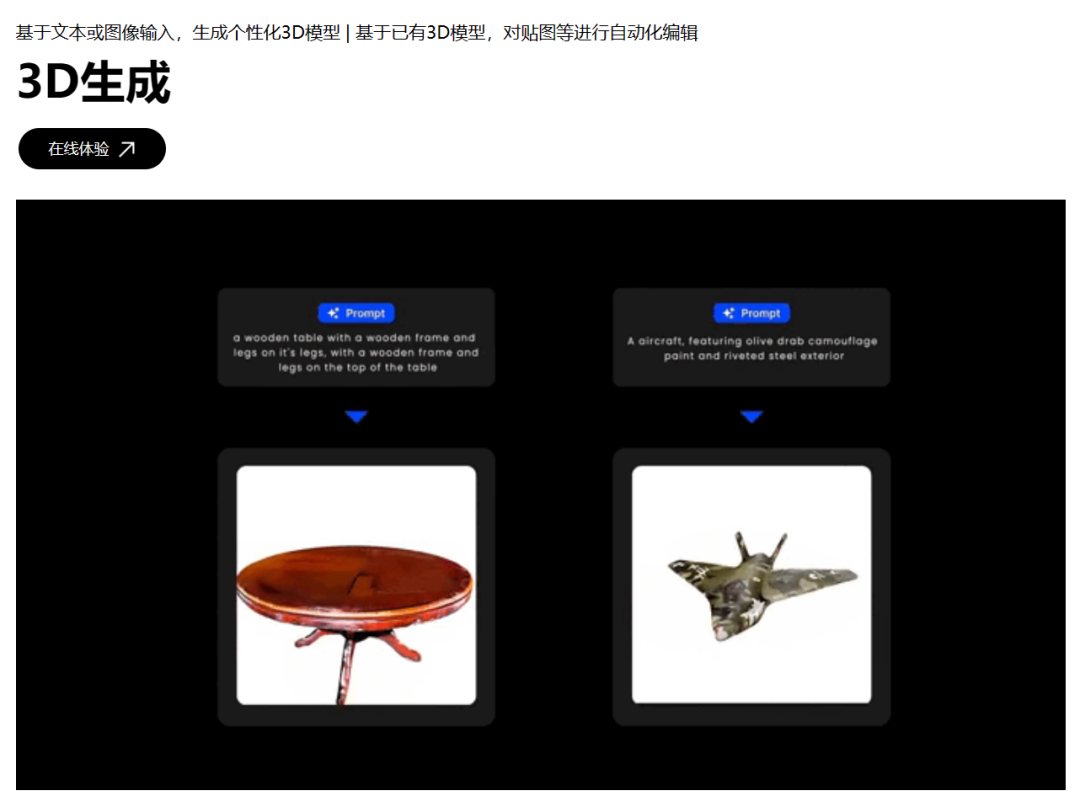
并且靠着这两个产品,刚满一周年,它就攒了好几亿的家底。
像是成立 3 个月的时候,就完成了一波近亿级的天使轮投资,上个月,又完成了新一轮的数亿元融资。参与投资的,也都是智谱 AI 、 BV 百度风投等等业内大佬。
反正看这波架势, Vidu 还真有可能成为国内的黑马,去对标 OpenAI 的 Sora 。
不过生数科技那边,倒是觉得只把 Vidu 看作国产版的 Sora ,实在是有点缺乏想象力了,因为他们给 Vidu 的定位,可不仅仅是个视频模型,而是图、文、视频全都要,只不过现在视频暂时是重点。
当然了,好听话谁都会说,能不能搞出来,咱还得实打实地看成品。
世超已经去排了队,等拿到内测资格,再跟大伙儿同步一波。。。
图片、资料来源:
Scalable Diffusion Models With Transformers
All are Worth Words:A ViT Backbone for Diffusion Models
机器之心,专访生数科技唐家渝:清华系团队拿到上亿融资,用Transformer来做多模态大模型
界面新闻,生数科技完成新一轮融资,国内多模态大模型厂商着力追赶Sora
极客公园,国产 Sora 的秘密,藏在这个清华系大模型团队中
新智元,图灵诺奖得主等大佬齐聚海淀!清华版Sora震撼首发,硬核AI盛会破算力黑洞
撰文:松鼠;编辑:江江 & 面线
来源公众号:差评(ID:chaping321),Debug the World。
本文由人人都是产品经理合作媒体 @差评 授权发布,未经许可,禁止转载。
题图来自 Unsplash,基于 CC0 协议。
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。






- 目前还没评论,等你发挥!


