
 起点课堂会员权益
起点课堂会员权益大模型在智能客服领域的应用思考
智能客服领域可以说是大模型落地的前沿领域之一,那么这其中,有哪些应用方向值得我们关注?这篇文章里,作者就做了相应的构想和探讨,一起来看。

前言
随着大模型技术的飞速发展,其在商业化应用的落地实践上仍面临着挑战,不论是面向C端用户的付费服务模式,还是面向B端企业的业务赋能策略,目前都尚未形成成熟且清晰的商业模式。
在我所专注的智能客服领域,作为人工智能落地应用的前沿阵地,我深刻感受到大模型的生成能力、泛化能力以及增强检索等核心技术的巨大潜力。基于此,我构想了一系列应用方向,并期望通过分享结合大模型工具的实验经验,与大家共同探讨这些可能性。
一、呼入场景
客户服务领域,无论是在线聊天还是语音交流,都已成为了现代业务运作中不可或缺的一部分。目前,基于NLP(自然语言处理)、ASR(自动语音识别)和大数据等先进技术,已经涌现出了一系列智能化的客户服务应用。
然而,这些产品在功能边界和特色上往往差异不大,难以在激烈的市场竞争中脱颖而出。大模型的加持,从运营成本和用户体验上考虑,也许可以为这一领域带来了新的发展机遇。
1. 问答机器人
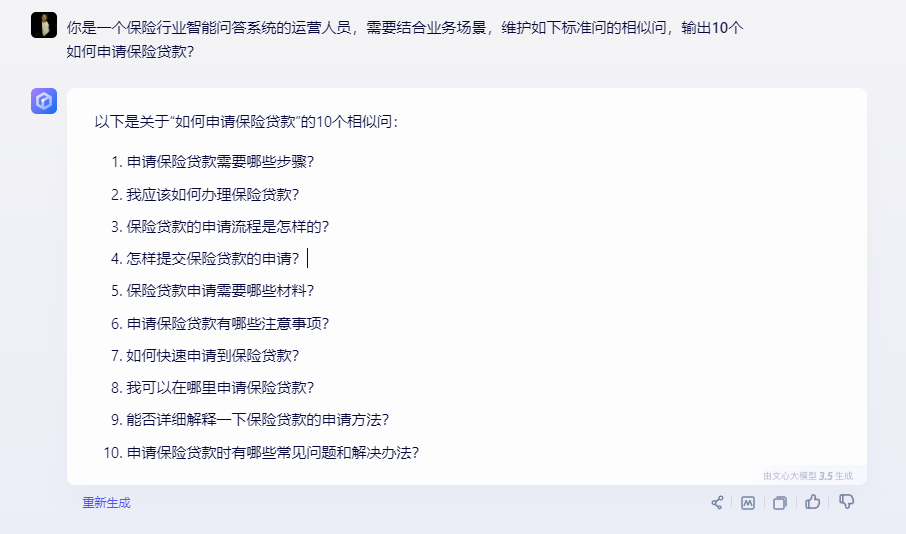
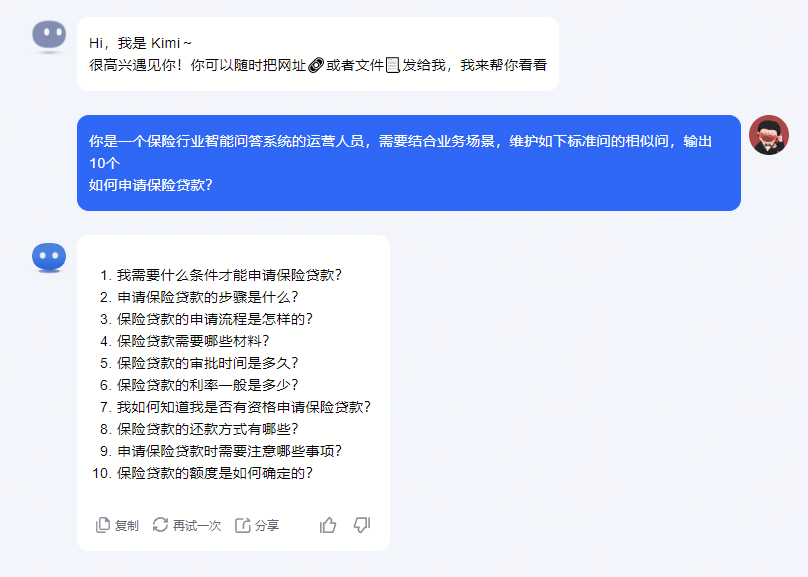
在呼入场景中,问答机器人(包括在线客服机器人和语音导航机器人)的广泛应用凸显了ASR转译准确率和NLP自然语言处理语义理解能力的重要性。在实际业务运营中,为了提升问答机器人的识别准确率,往往需要维护一个尽可能大的相似问题库。
然而,这种维护方式不仅耗时耗力,而且需要大量的运营成本。考虑到大模型的泛化生成能力,我们可以设想一种创新的方法:通过输入特定的prompt(指令),让大模型生成更多的相似问题,经过业务审核后入库。这种方法有望显著降低运营成本,同时提升问答机器人的识别准确率。为了验证这一想法,使用了文言一心、Kimi助手等大模型工具进行了实验,如下:
2. 话务小结抽取
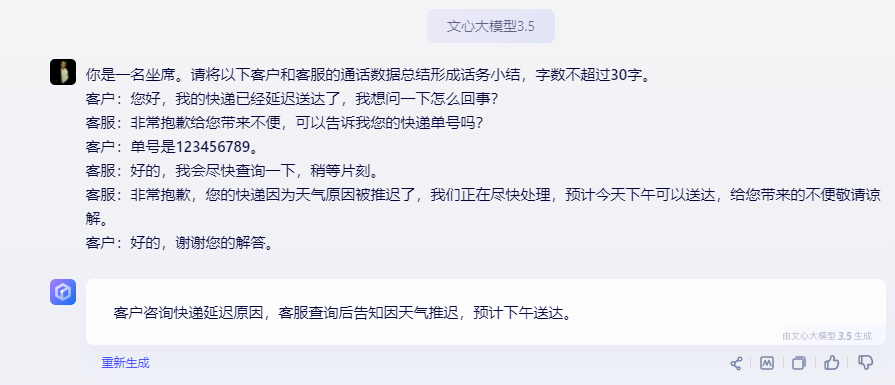
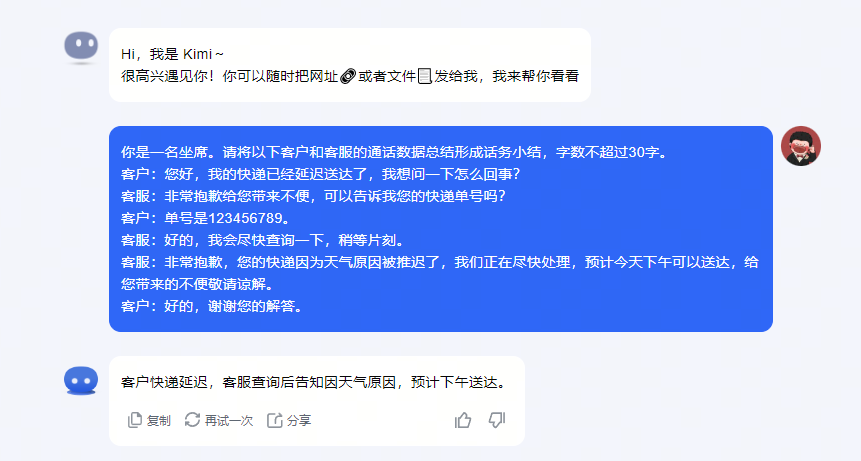
席在接听完一通会话后进行话务小结是一个重要的环节,用于记录通话的核心内容、问题以及解决方案等信息。传统上,这个过程需要坐席在通话结束后手动输入,既耗时又可能因人为因素导致信息遗漏或偏差。
大模型的主题抽取能力可以用于自动生成小结,坐席只需审核确认后录入,这有助于缩短通话时长,提高效率。验证如下:
3. 多轮对话的处理
多轮对话在问答机器人技术中向来是颇具挑战性的环节,目前主要局限于特定的简单场景,由运营人员在流程画布上进行详细设定,涉及多个交互节点和路径。
为了更灵活、精准地响应客户的问题,我们可以借助大模型的生成能力和增强的检索功能。这种方法在阿里的相关文章中得到了具体体现(参考:https://mp.weixin.qq.com/s/0THyHxpuIo9MI8MY9tLHiA),即通过大模型生成提示性的快捷短语,引导用户更明确地表达需求,同时结合增强的检索技术,缩小答案的搜索范围,从而生成更为可靠和准确的回答。
二、呼出场景
在当前的AI外呼场景中,虽然普遍采用基于预设流程的问答模式,结合ASR(自动语音识别)和NLP(自然语言处理)技术来执行外呼任务,但这种方式在个性化服务和转化率提升上存在一定局限性。借助大模型的生成能力,我们可以实现更为智能化的外呼策略。
具体来说,通过大模型分析不同用户的属性标签,如年龄、性别、兴趣偏好、消费习惯等,AI外呼系统可以为用户定制差异化的呼叫内容和方式,真正做到“千人千面”。验证如下:


三、后线管理应用
1. 智能质检规则的泛化
在搭建质检系统的过程中,作者从0到1深度参与,深刻体会到了质检规则维护的复杂性和重要性。这些规则通常涉及关键字识别和正则表达式的使用,需要业务团队投入大量时间和精力去详细罗列和测试,以确保质检的准确率。
然而,借助大模型的泛化能力,我们可以极大地提升这一过程的效率和效果。大模型能够通过学习大量的数据,自动生成与业务相关的关键字和正则表达式,从而帮助业务团队减轻工作量,并提高质检规则的全面性和准确性。以正则表达式验证如下:

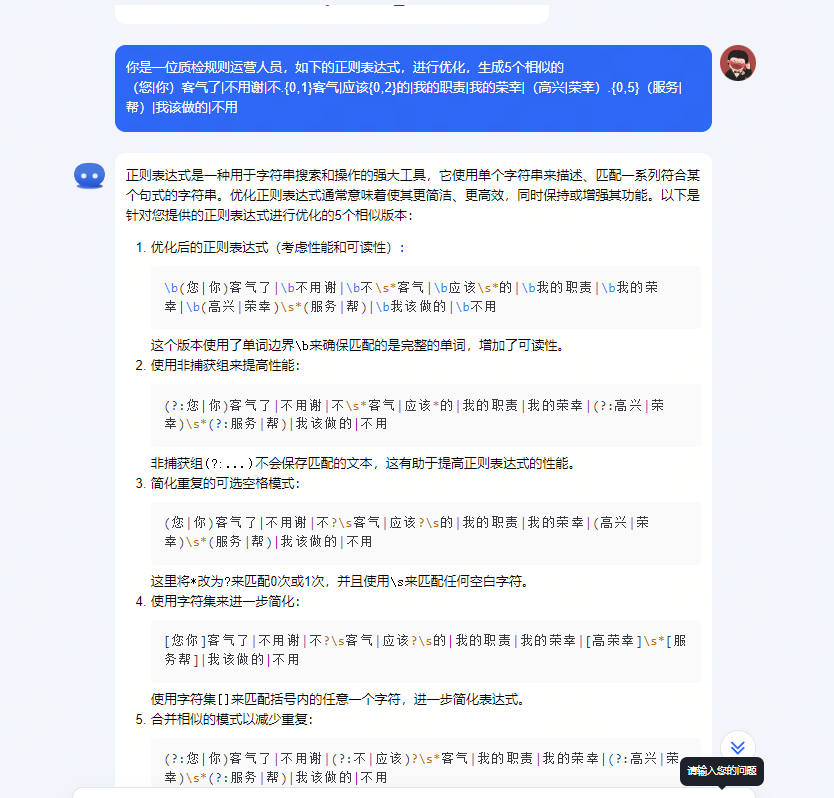
2. 坐席知识库
传统坐席知识库在搜索和匹配信息时,依赖于搜索引擎、索引、关键字匹配或语义理解进行排序,这种方式可能导致用户查找信息耗时较长,并且高度依赖于知识维护人员的规范性和及时性。大模型能力也许会将未来的知识库搜索体验进行颠覆性的改进。
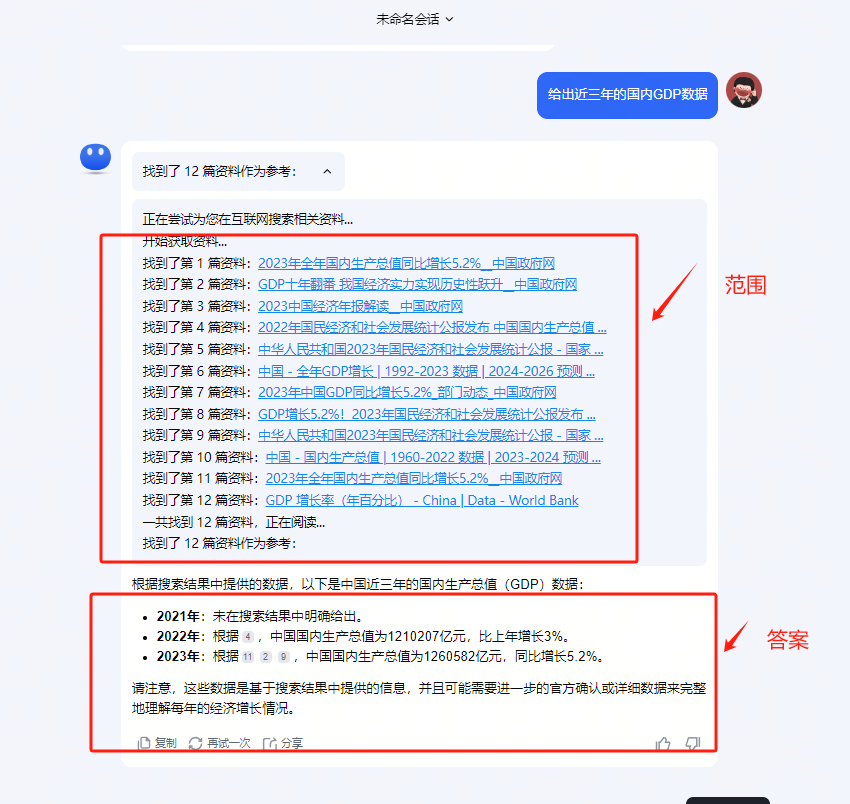
具体想法如下:首先,将知识库中的信息进行结构化处理,并存储到向量库中。这样,知识库中的每一条信息都能以向量的形式存在,便于进行高效的数学运算和相似性比较。接着,将这些向量数据投喂给大模型进行训练,为后续的搜索和生成任务打下基础。用户搜索时,给出明确promote指令,大模型将相关的内容检索出来,再直接生成内容返回给到用户。
这和当前使用的一些大模型助手的情况相似,举例说明,如:给出近三年的国内GDP数据。
结束语
以上是我基于对大模型能力的理解以及对客服业务场景的洞察,所产生的一些初步思考。这些思考得到了我在开源工具上进行的验证的支持,尽管目前这些思考尚显零散,但我期待能与各位同仁共同探讨和完善。
再者,在探讨大模型在业务场景中的落地应用时,我们不可忽视垂直领域的训练优化。每个行业都有其独特的业务逻辑和需求,因此,通过针对垂直领域的特定训练,能够进一步提升大模型的性能和适应性。
最后,在实际落地过程中,我们需要保持开放的心态,勇于提出大胆的假设,但同时又要谨慎求证。为了降低风险并加速验证过程,建议在前期采用插件化的形式来逐步验证和优化大模型的应用效果。
本文由 @菜鸟店小二 原创发布于人人都是产品经理,未经许可,禁止转载
题图来自 Unsplash,基于 CC0 协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。









写的很好,我们公司也在做智能客服SaaS产品,在探索基于RAG的知识库搜索能力,希望有机会能一起探讨下
来交流,目前在做知识库检索,由于需要多重判断,业务复杂性高,大模型总是出现幻觉~
确实是会出现幻觉,有无什么解决方案?
我现在新公司也在做这块内容,可以探讨