
 起点课堂会员权益
起点课堂会员权益如何让ChatGPT更“懂你”
大语言模型并不是万能的,由于缺乏行业领域的专业知识,大模型在解决实际问题上其实存在一定的局限性。那么,如何让大模型更懂你?作者作为AI开发平台的设计师,总结了两个简单高效的方法,一起来看。

我们都知道,生成式AI的出现掀起一波人工智能的浪潮,在这种时代背景下,了解AI产品背后的开发方法,能帮助我们更好的使用AI产品。
一、什么是生成式AI?
生成式AI可以帮助我们做很多事情,在日常生活中,它可以用于生成报告,提高汇报的效率;在电商领域,智能客服可以自动回答和解决用户的问题;在医疗领域,智能医生可以帮助患者进行疾病诊断,提高了行业人员的工作效率。
二、ChatGPT的本质是大规模语言技术的应用
在生成式AI应用中,我们所熟悉的Open AI 的ChatGPT、百度的文心一言、字节的豆包等,他们的本质是应用了一种大模型的技术。
这种技术是由云厂商中专业的技术人员,通过海量的文本数据处理,消耗昂贵的算力成本所得到的。这样的技术让大模型学习人类的语言模式和知识结构,并生成自然流畅的回答。

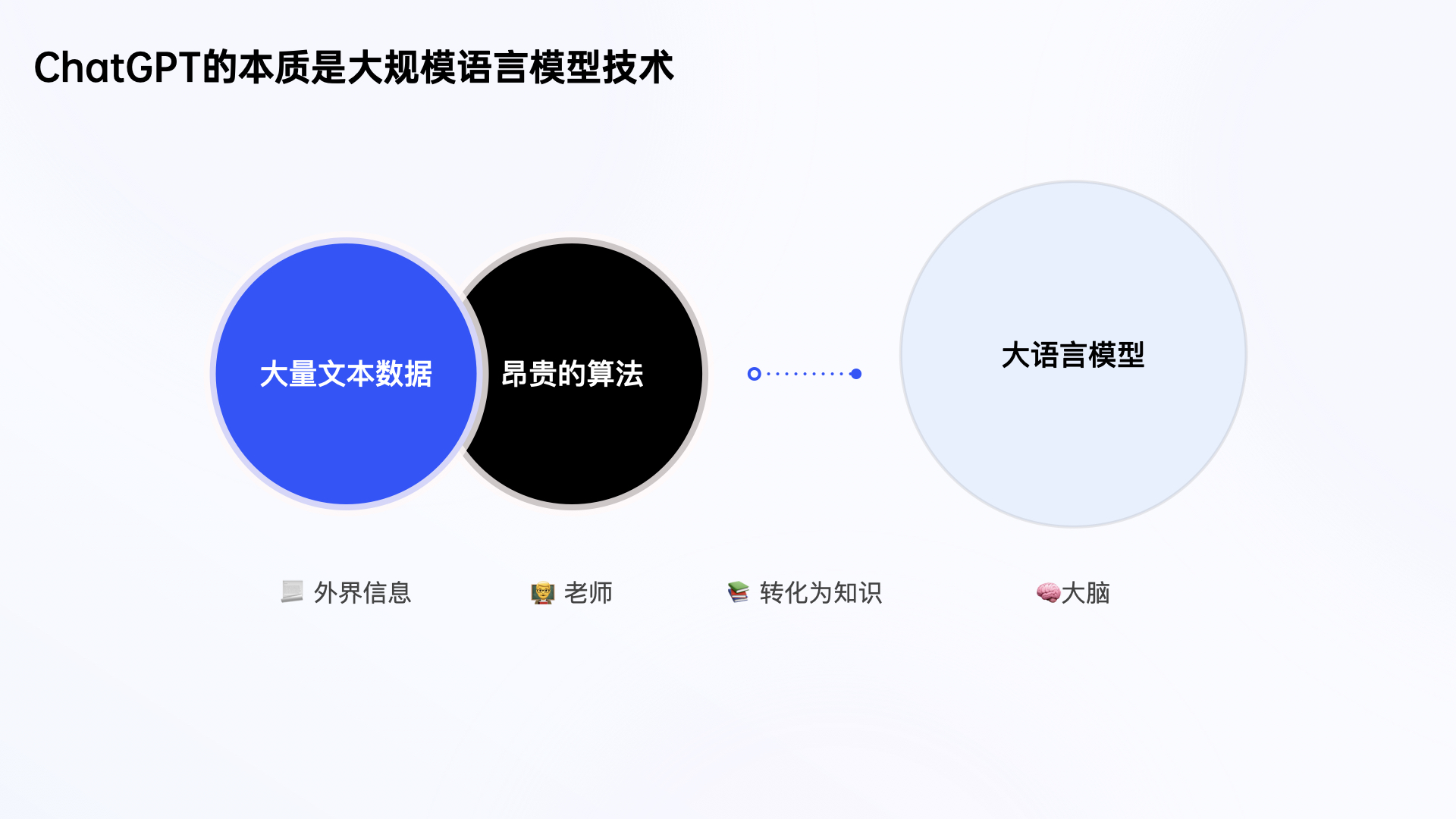
大模型类比为大脑
通俗比喻:我们可以将大模型类比为“大脑”,大量的文本数据相当于“外界提供的信息”,昂贵的算法比喻为“聘请的高级教授”,将外界信息转化为知识点,储存在大脑中,最后呈现出来的就是我们使用的智能产品。
三、大语言模型并不是万能的,解决实际问题上存在局限性
然而大语言模型并不是万能的,由于缺乏行业领域的专业知识,导致他们在解决实际问题上存在一定的局限性。
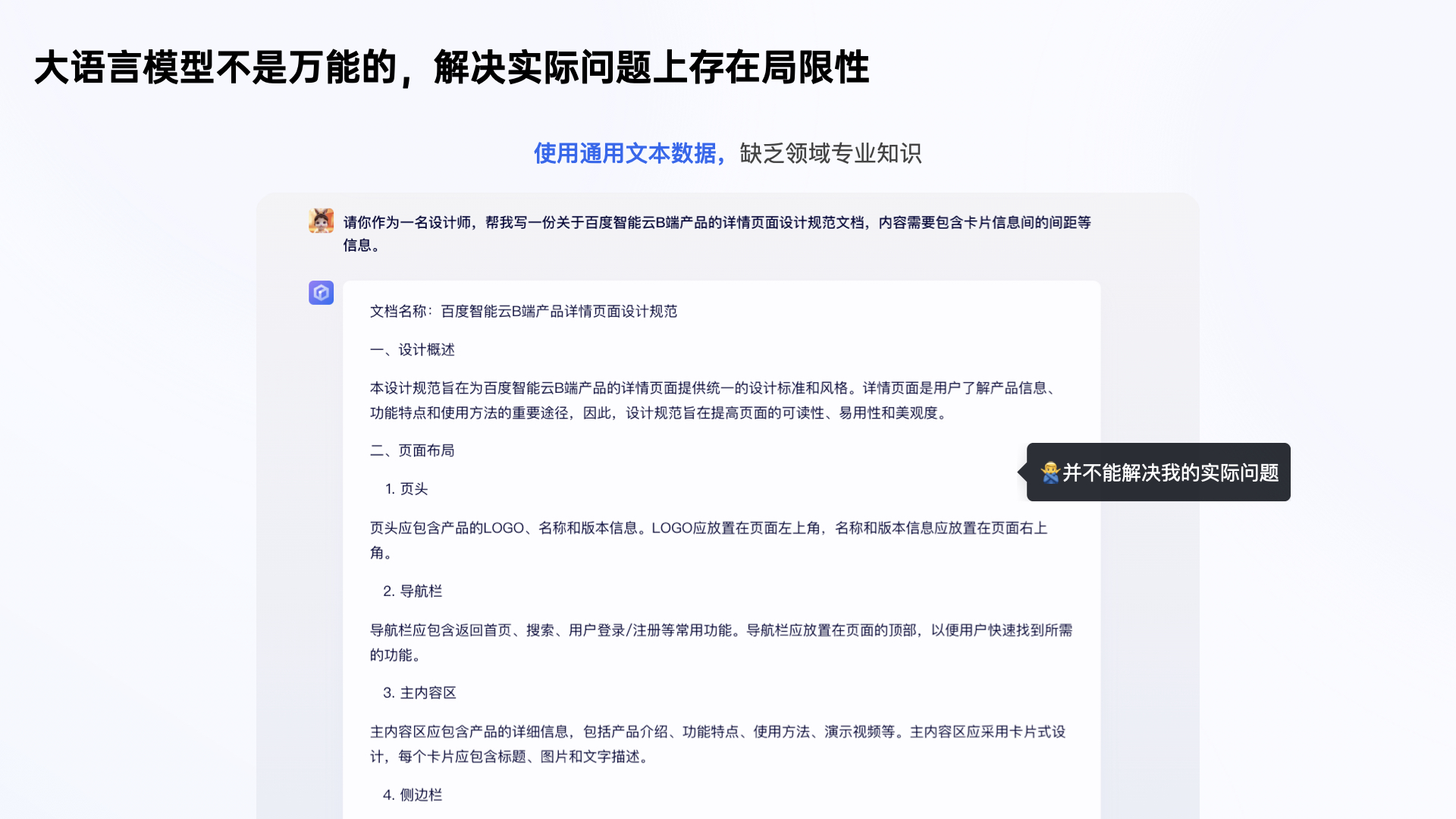
比如以下场景:我想通过 文心一言 了解CXD智能云产品,相关的设计规则,而它的回答,并不能解决我的实际问题。
文心一言只提供适用于通用平台的设计规则,这些规则并不能完全适用于我们的产品。企业应用过程中遇到这种问题,应该怎么办?
四、解决办法:让人工智能应用更懂你,得到你想要的内容
作为AI开发平台的设计师,我总结了两个简单高效的方法分享给大家。

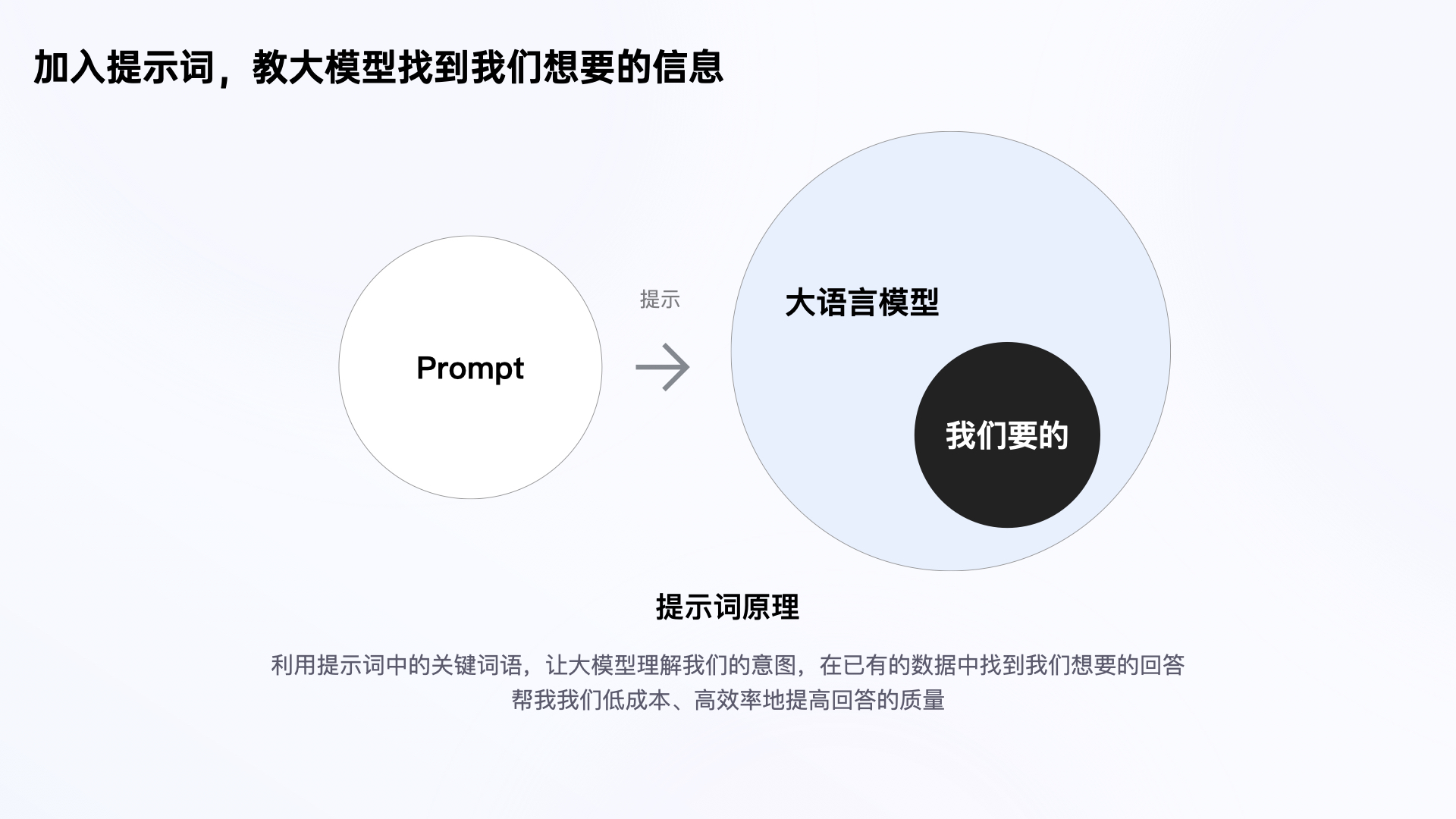
方法1 “教它找”
“教它找”的原理是:通过加入提示词,利用其中关键词语,提示大模型理解我们的意图,在已经有的数据信息中找到我们想要信息再进行回答。
这种方式可以帮助我们低成本、快速的提升大模型的效果。
以开发一个“汽车销售客服”作为场景,Diffy产品作为工具演示。
产品的左侧面板是相关参数的配置,右侧则是用户真实使用场景的测试工具。
没有提示语配置下,我选择ChatGPT 3.5 来回答我的问题,发现它的回答没有实质有效的信息,对购买汽车的用户帮助不大。
如何通过加入提示语提升质量?
步骤1:加入提示词:在左侧面白的输入框加入文本,限制大模型回答,让大模型作为一名专业销售人员,针对汽车性能、外观等维度提供比对信息。
步骤2:测试效果:ChatGPT的回答效果明显提升。
通过这样的方式,打包成新的应用,给到用户使用,让用户在已限定好范围的大模型内进行问答,可以极大提高产品满意度。
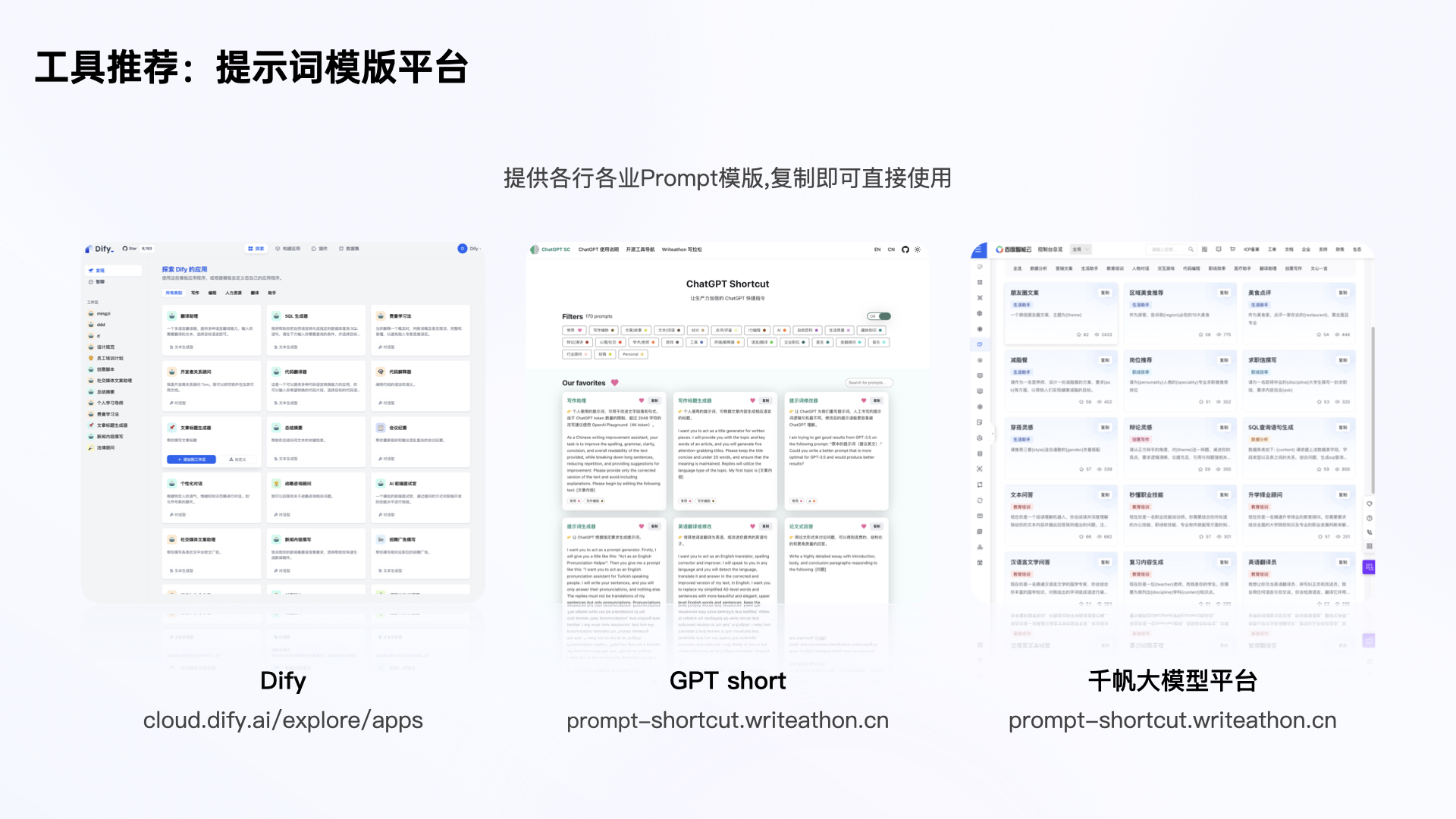
基于这个方法,我为大家推荐两类好用的工具:一类是提示语模版平台,在这些平台中可以获得各行各业的高质量提示语,教育类、金融类等等,复制直接使用。
Dify:http://cloud.dify.ai/explore/apps
GPT short:http://prompt-shortcut.writeathon.cn
千帆大模型平台:http://prompt-shortcut.writeathon.cn
方法2 “教他学”
“教他学”的原理是:通过增加自己/企业自身的数据,与它自身通用的数据结合,教它学习新知识,从而定制一个懂你的新的大模型。
如何加入自己的数据?有两种方式。
方式1:可以在AI定制的平台,通过非结构化的文档(比如pdf word文档、网页链接等)资料,来生新的大模型。
方式2:选定某一AI开发平台,准备结构化的数据集(文本对信息)excel json文件,通过重新训练的方式,来让大模型学习新知识。
同样,我以两个案例来介绍说明具体操作流程。

案例1:以开发“设计规范助手”为场景,Chatbase平台作演示
第一步:选择“创建机器人”。
第二步:选择数据,这里提供5种数据类型,分别是文档、文本、连接、问答对、第三方笔记网址。
我提前准备好了三种关于日常会用到的文件,分别是:设计规范文档、方案库文档、各产品的用研报告,同时加入专业的提示文本和云设中台官网的链接,帮助大模型更好的学习我们的知识。
第三步:生成机器人开始测试。
通过三轮对话可以看到,它轻松的回答了我想要的问题,提供了正确的规范信息和健康度指标,以及如何设计数据标注场景的总结信息。
最后,只需要将它发布为网站,把链接提供给组内设计师使用即可。
案例2:以开发“医疗客服助手”场景,千帆平台作演示。
第一步:准备数据,可以选择自己准备数据集,按照平台的示例引导进行操作;也可以直接使用平台提供的现成的行业数据集。比如我们选择这个医疗中文数据集。
第二步:训练模型,这个页面中,首先选择训练的大模型,可以根据大模型使用介绍进行选择。我们选择Ernie bot 因为它中文效果更好。
其次是选择训练方法,不同的训练方法影响资源成本金额、消耗时间和模型稳定性;最后是选择训练参数,平台会根据已由信息提供推荐值,如果是开发人员对训练参数有了解,可以根据经验调整。点击确定开始训练,
第三步:训练完成后则将任务发布为模型,并把模型部署为服务。(这里不详细拓展)
第四步:在体验中心中,选择刚刚部署的服务,即可进行测试,了解这个医疗客服的实际效果。
以上就是在大模型中加入结构化数据的操作流程,这种方式需要耗费更多的金额和时间,但更适合于需要高精度回答效果的企业。
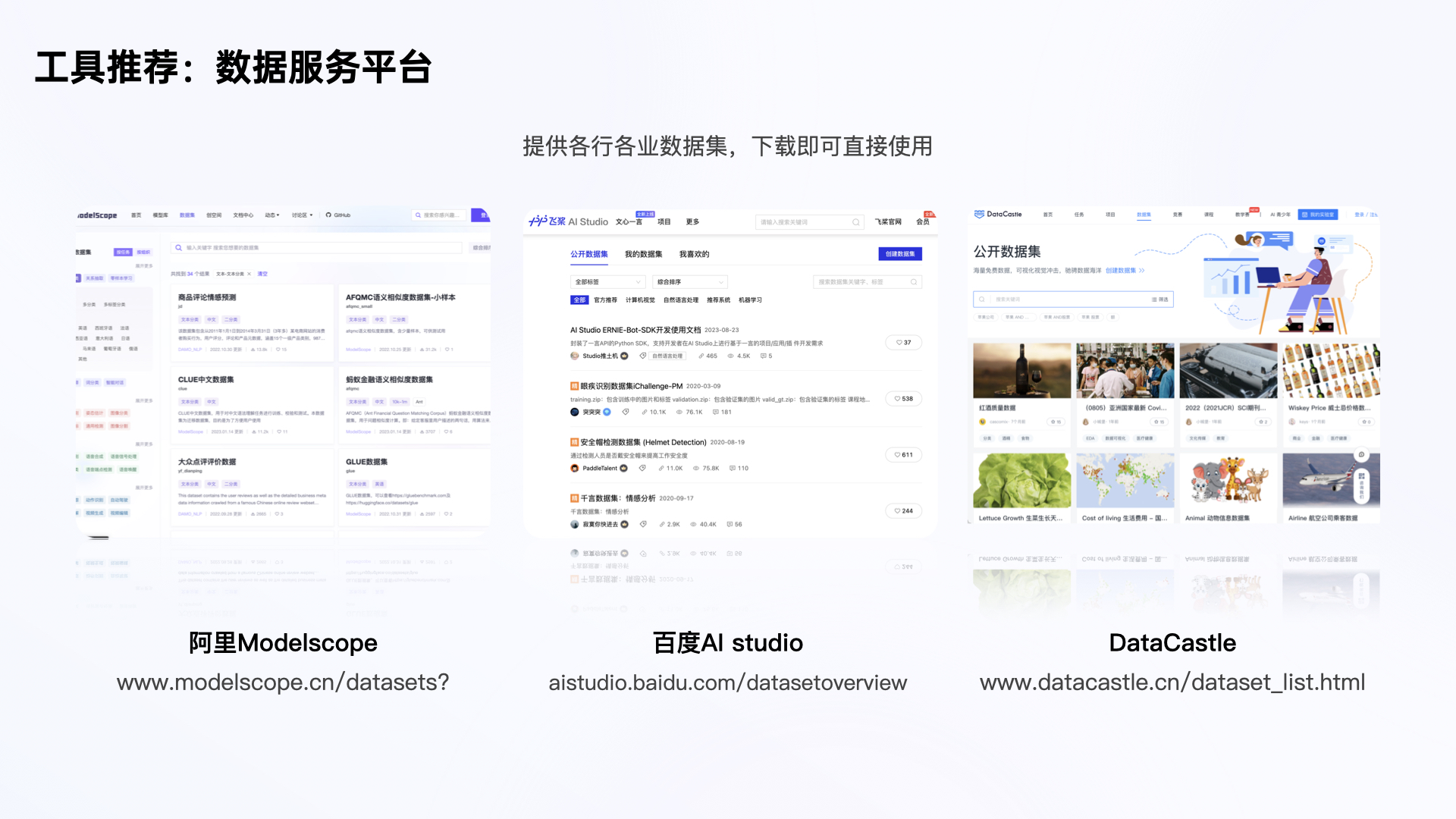
1)数据服务工具
这些平台提供现成可用的数据集,就不用耗费精力去准备数据,比如红酒知识、动物知识等,根据你的业务需求下载使用。
阿里modelscope:http://www.modelscope.cn/datasets?Tags=text-classification&dataType=text&page=1
百度AI Studio:http://aistudio.baidu.com/datasetoverview
DataCastle:http://www.datacastle.cn/dataset_l
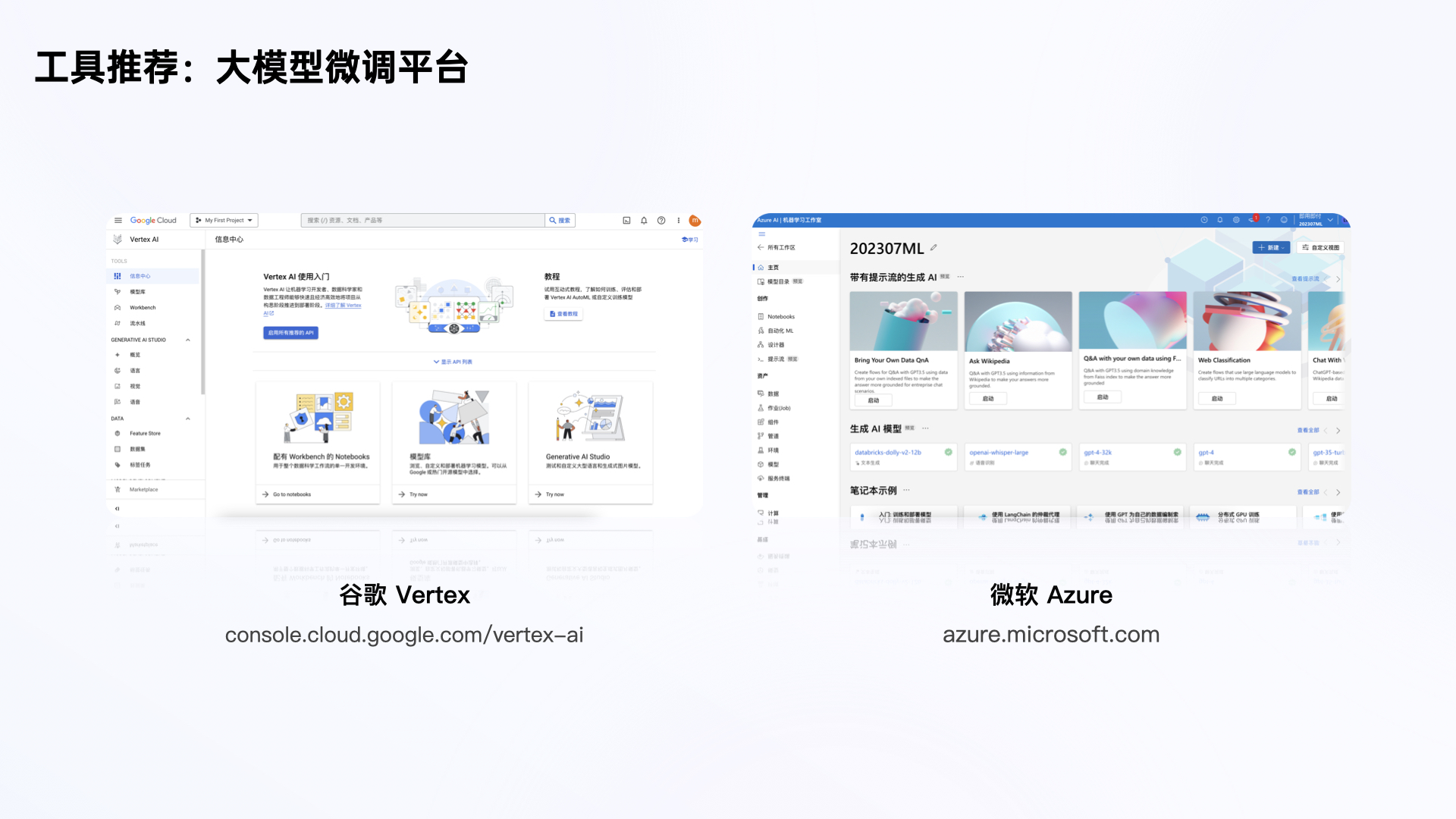
2)大模型调优工具
国外的大模型调优工具:谷歌、微软。
最后总结
在过去,开发大模型的事情更多是专业的技术人员来做,而随着时代的发展,未来AI可能将普惠到每个人。以后我们可能人人都会开发一个自己的大模型,用具有我们数据的机器人去工作、聊天。
而目前产品的使用流程仍存在门槛,对小白用户的包容性不高,作为AI开发产品设计师,我们任重而道远,一直在大模型开发流程做得简单易用的路上持续努力~~
本文由 @MINGZI 原创发布于人人都是产品经理,未经许可,禁止转载。
题图来自 Unsplash,基于 CC0 协议。
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。









写得很好!