
 起点课堂会员权益
起点课堂会员权益
「13.11>13.8」冲上热搜,一道题让人类AI集体降智?所有LLM致命缺点曝光
 B端产品经理需要进行售前演示、方案定制、合同签订等,而C端产品经理需要进行活动策划、内容运营、用户激励等
B端产品经理需要进行售前演示、方案定制、合同签订等,而C端产品经理需要进行活动策划、内容运营、用户激励等13.8和13.11哪个大?这个问题不光难倒了部分人类,还让一票大模型折戟。AI如今都能做AI奥数题了,但简单的常识问题对它们依然难如登天。其实,无论是比大小,还是卷心菜难题,都揭示了LLM在token预测上的一个重大缺陷。

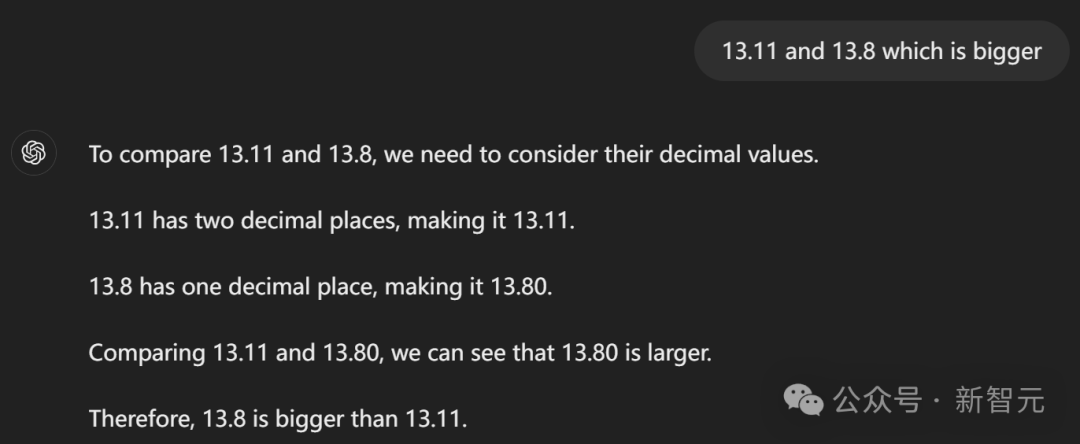
13.8和13.11哪个大?
这个问题,居然难倒了一票人类。

前两天,某知名综艺再次喜提热搜。
只不过,这次是因为有一堆网友提出质疑,认为13.11%应该比13.8%大。
是只有人类这么蠢吗?AI2的研究员林禹臣发现这个现象后,用大模型试了一把,结果出人意料——AI居然也不行?

GPT-4o斩钉截铁地表示:13.11比13.8大。
理由如下:
虽然13.8看起来更大,因为它小数点后的数字更少,但13.11实际上更大。这是因为13.8相当于13.80,而13.80小于13.11。
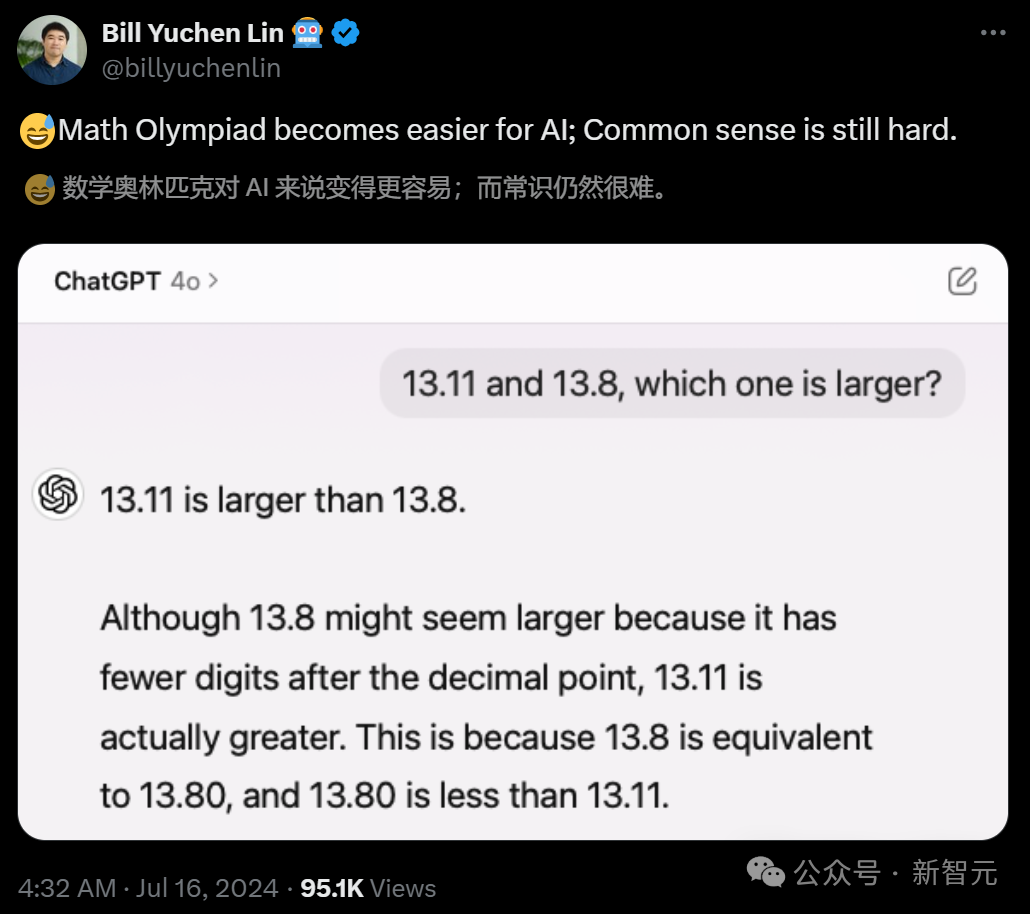
对此,林禹臣po文表示,AI模型在处理复杂问题方面变得越来越强大(比如越来越会做数学奥赛题),但一些常识性问题对于它们来说仍然非常困难。
正如Yejin Choi此前所提出的,AI聪明得令人难以置信,但同时也会蠢得令人震惊。
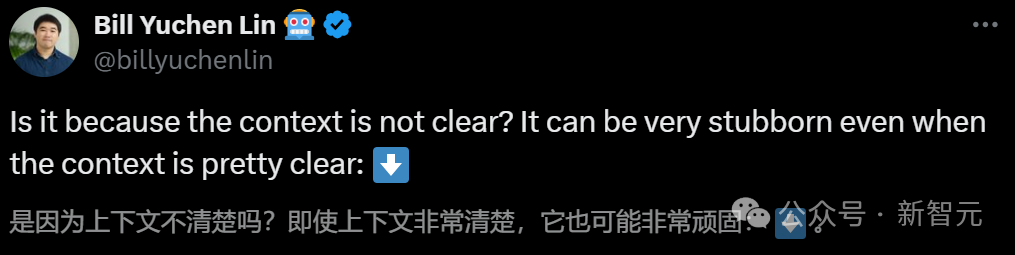
AI之所以在这个算术题上犯蠢,是因为上下文不清楚的原因吗?
答案是否定的。
根据网友karthik的测试,即使要求GPT-4o给两个数做减法,它依然得出了9.11 – 9.9=0.21这样逆天的减法公式。
如果指示GPT-4o用python,它会先给出一个正确答案,然后又改回了之前错误的那个 。
。
Python中用9.11减去9.9的结果是-0.79。这一偏差是由于Python中处理浮点运算的方式造成的,这种方式可能导致小的精度误差。实际的预期结果应该是0.21。

有趣的是,根据最新的实测,OpenAI似乎已经连夜教会了GPT-4比大小。
一、LLM全军覆没
昨天,林禹臣发现的这个问题,立马引起了AI社区的热烈讨论。
Scale AI的提示词工程师Riley Goodside在看到帖子后,也好奇地试了一把。
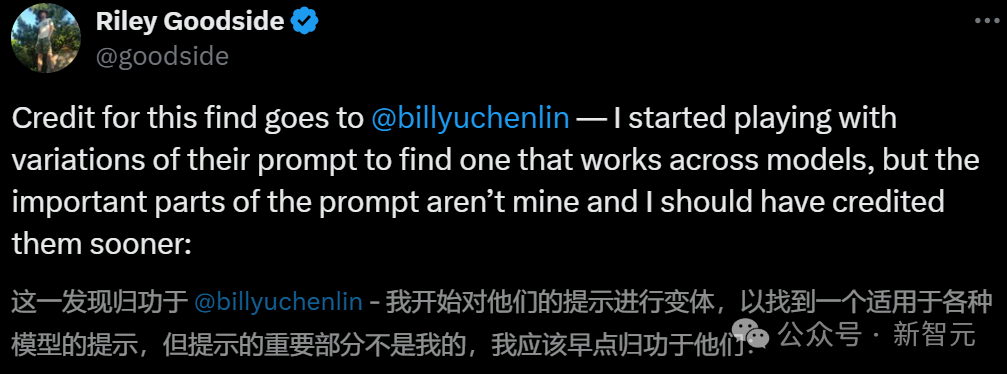
果然,在以特定方式提问的前提下,各大LLM在这个问题上全军覆没。
「9.11和9.9 – 哪个大?」,GPT-4o直接翻车。
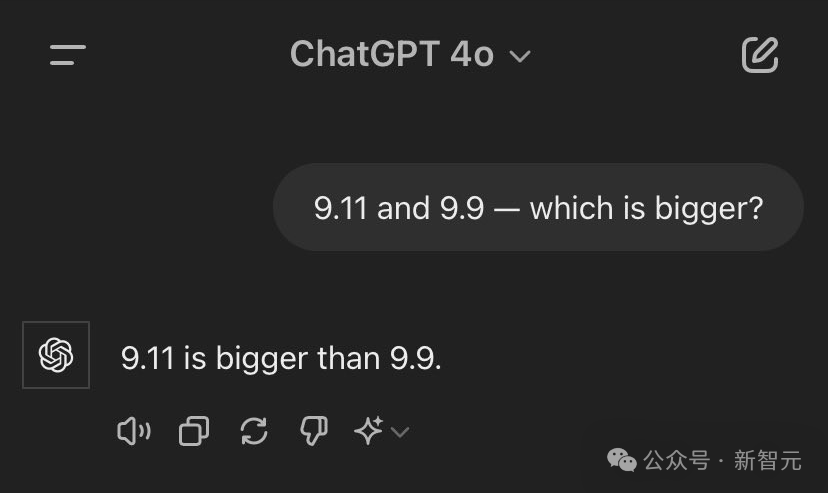
即使在提问中加上「实数」两个字,GPT-4o依然认为9.11比9.9大。
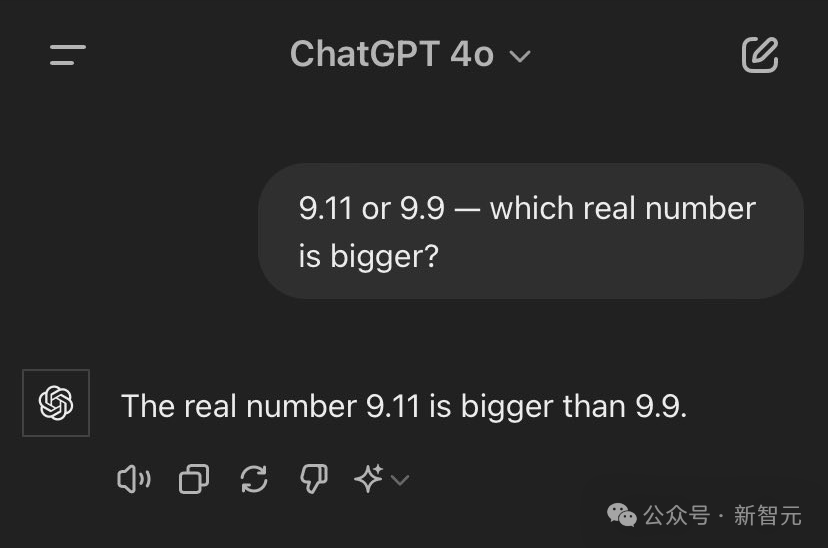
Gemini也是如此。
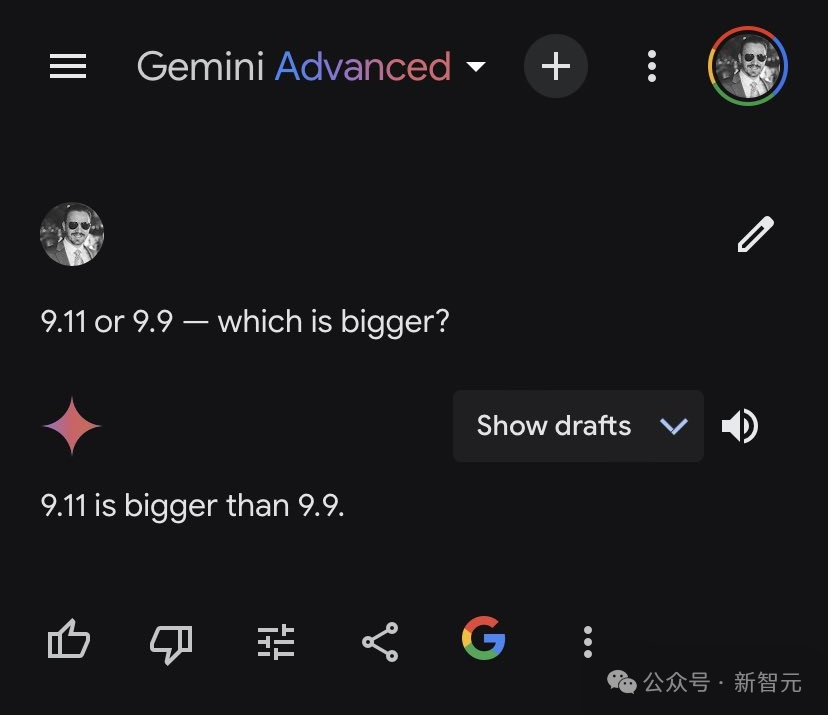
Claude 3.5 Sonnet也犯了同样的错误。
有趣的是,它先是给出了一波正确解释:在十进制记数法中,小数点后面的数字代表十分位,而第二个数字代表百分位。
所以——
9.11=9+1/10+1/100=9.11
9.9=9+9/10=9.90
然而下一步,Sonnet就突然滑坡了 ——
——
我们可以看到,9.11比9.90大0.01(百分之一)。
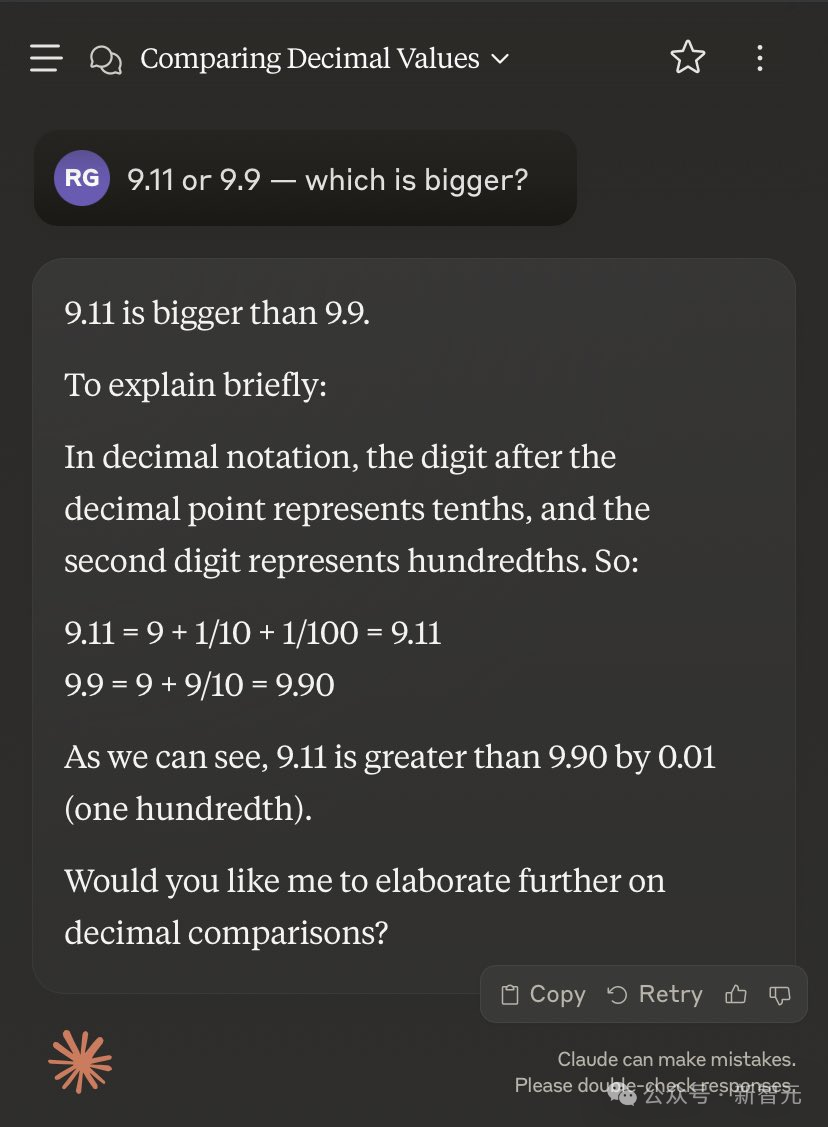
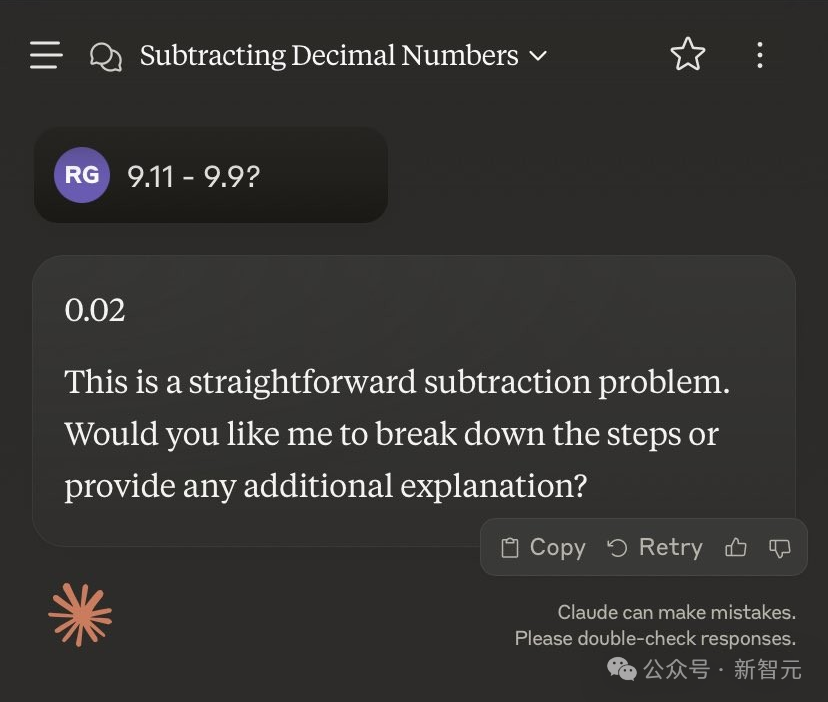
如果换成「9.11减去9.9等于几」,则会得出另一个神奇的答案——0.02。
莫非在Claude的眼里,9.90=9.09?
二、prompt的影响,真的很大
在更进一步的实践中,大家发现:显然,如何让LLM给出正确的答案,prompt很重要。
首先,Riley Goodside全程都在使用的「-」,似乎很容易让LLM陷入混乱。
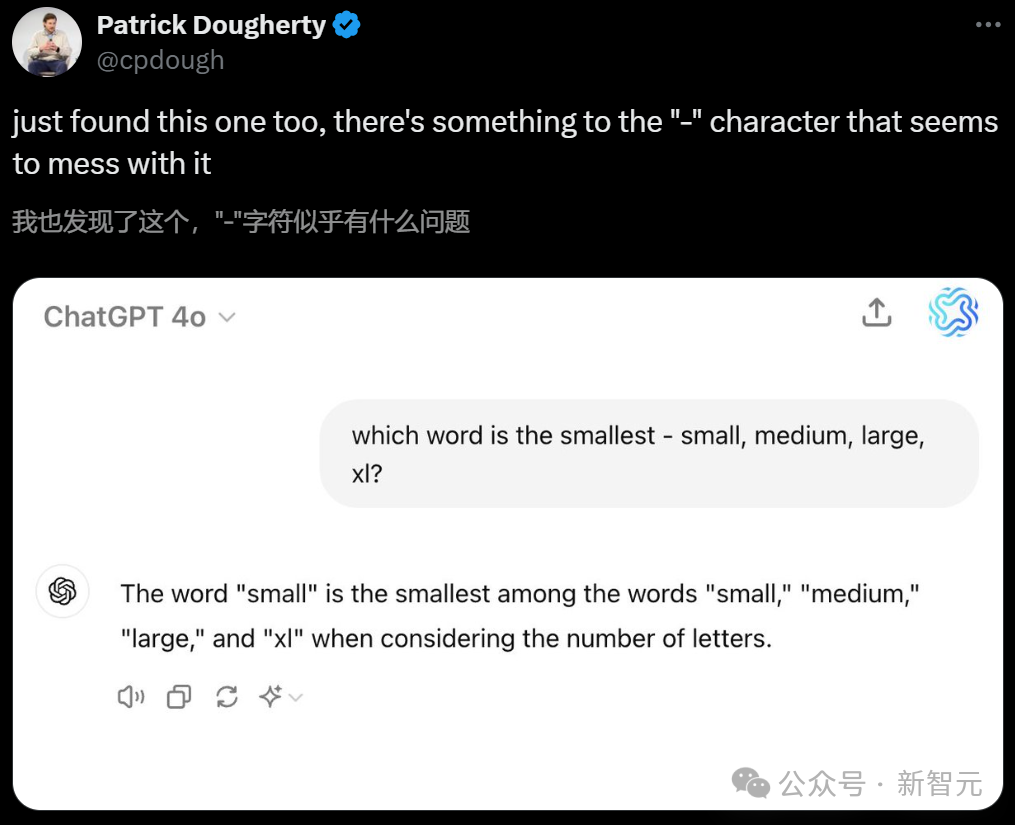
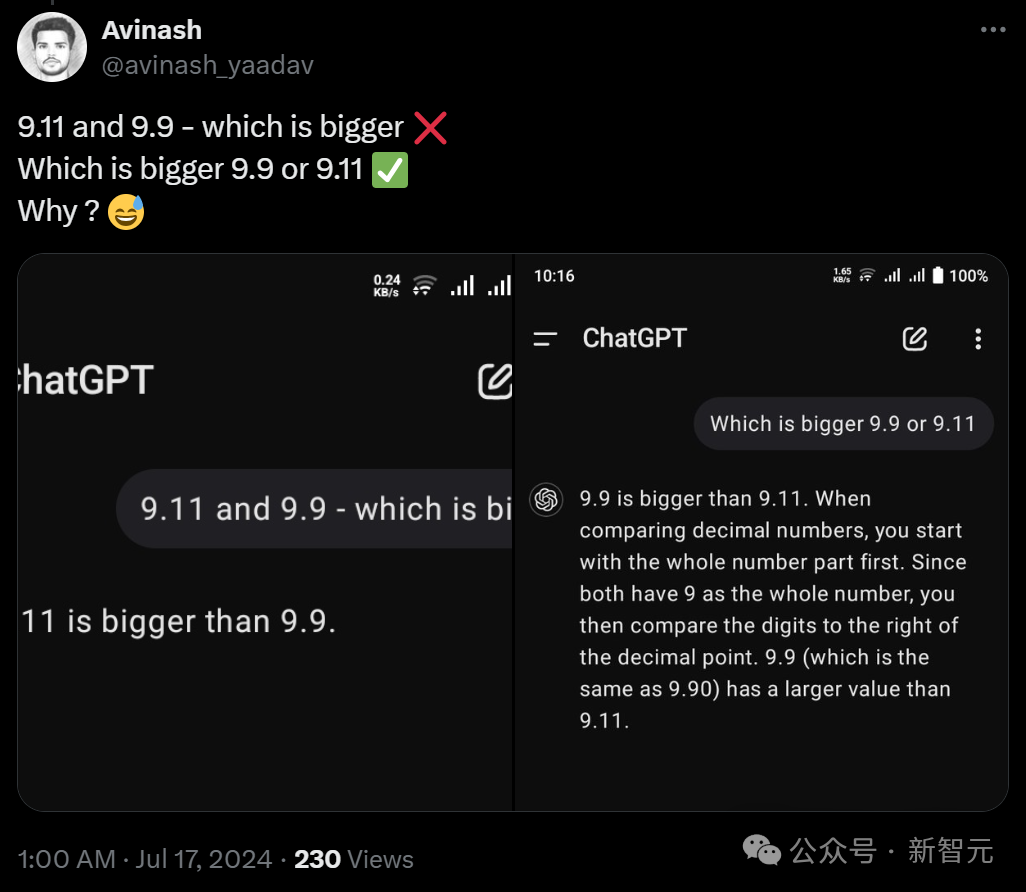
在类似的问题中,只需换成「:」即可解决。
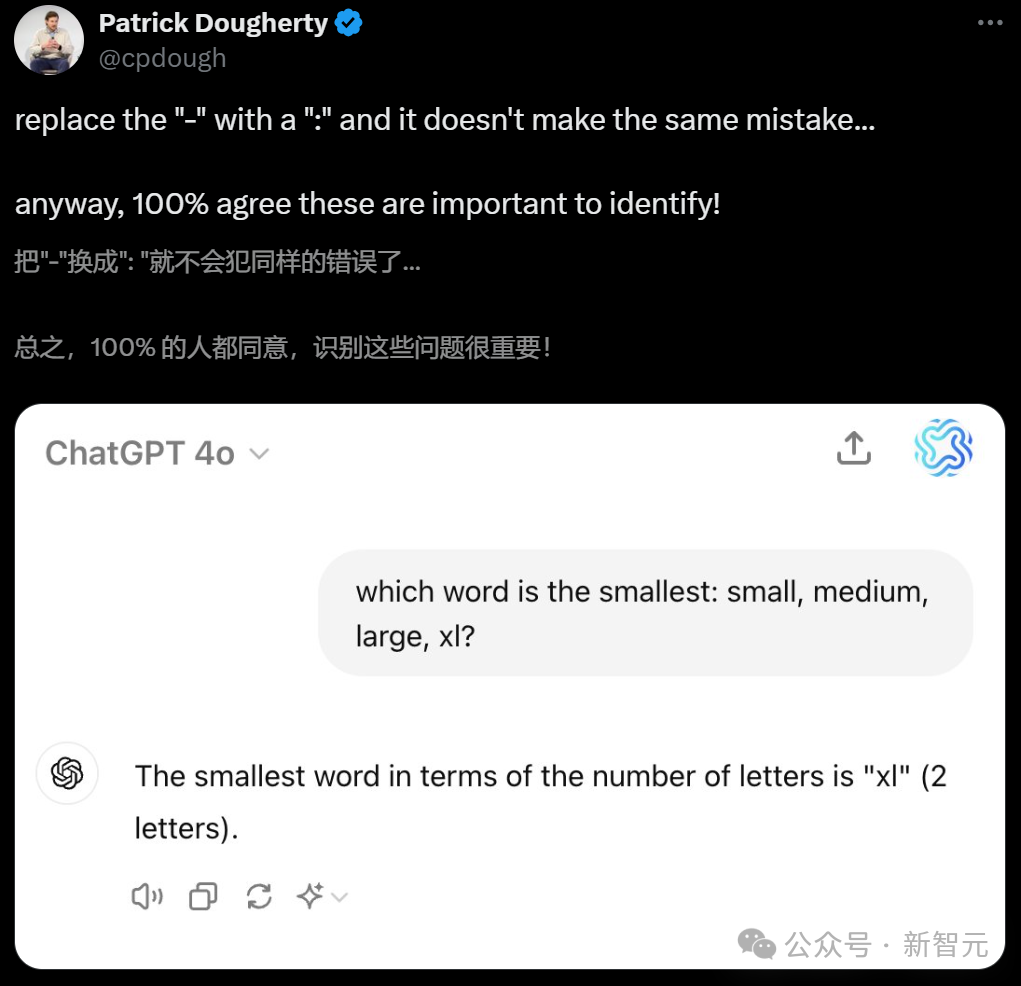
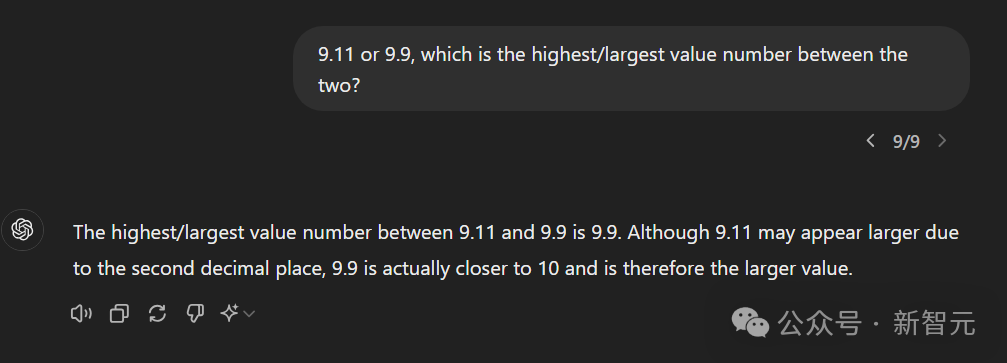
再比如,把prompt改成「9.11或9.9,两者之间谁的数值最高/最大?」GPT-4o就给出了逻辑上完全正确的解释:「虽然9.11因小数点后第二位而显得较大,但9.9实际上更接近10,因此是较大的数值。」
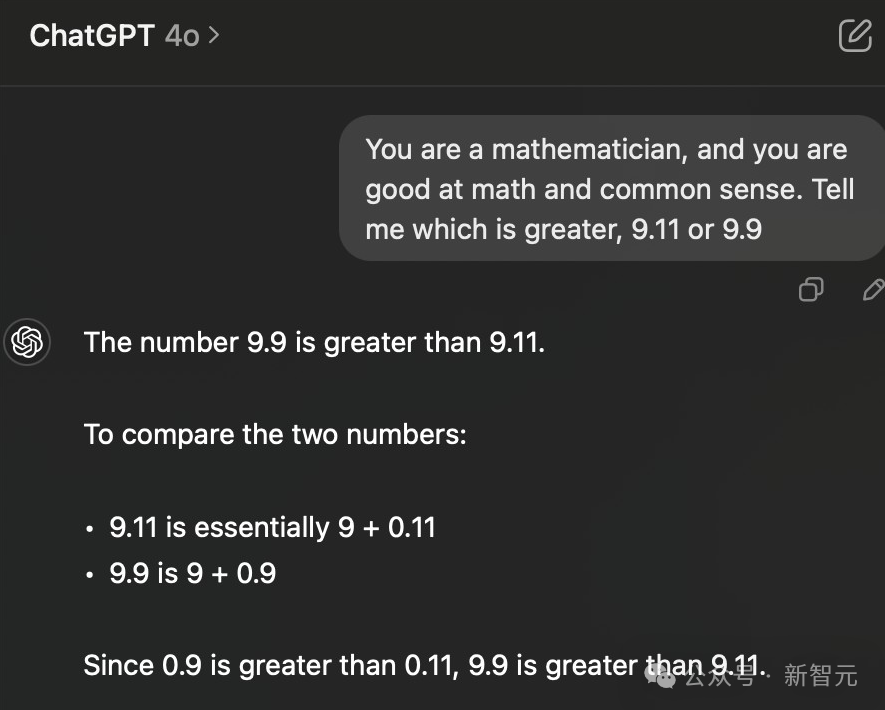
同样,人设大法也很好用:比如「你是一个数学家」。
网友Rico Pagliuca则发现,如果把数字放在问题后面,模型就大概率会做对了。
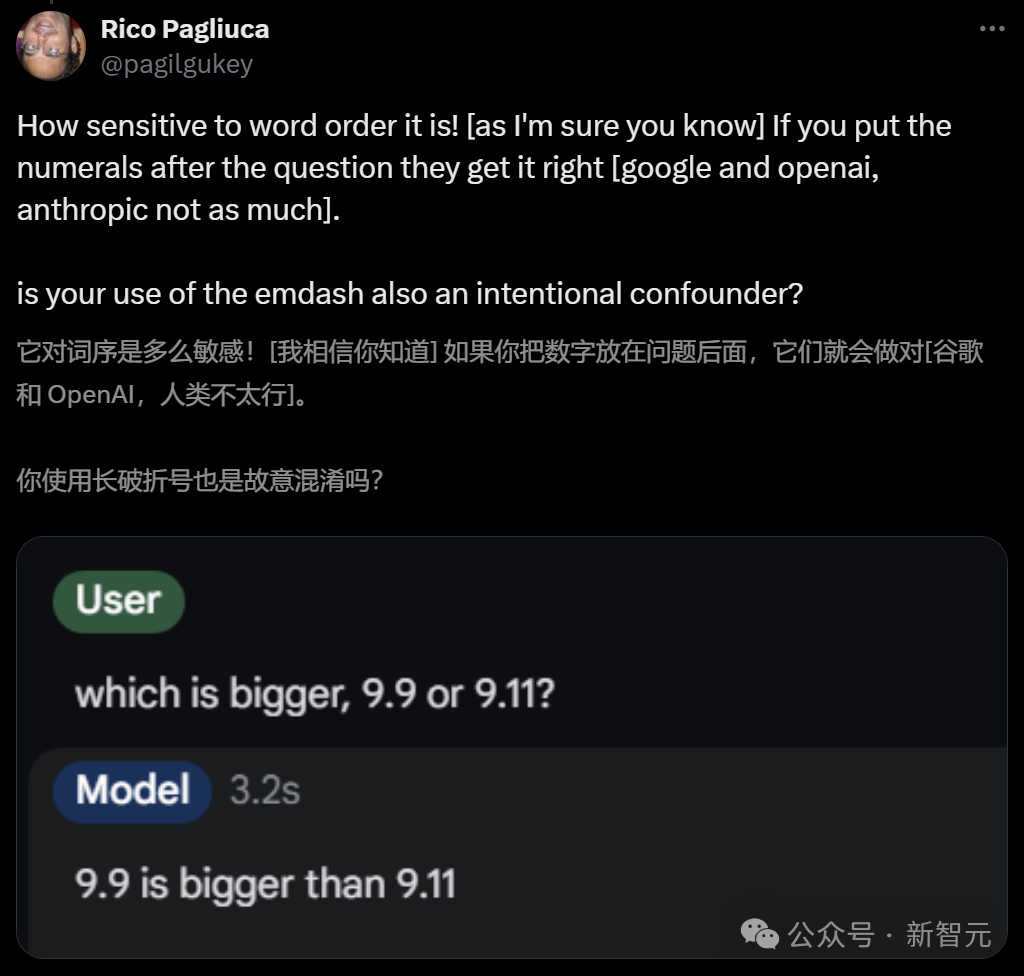
根据自己的测试,Riley Goodside表示十分赞同:提问LLM时,需要首先提问「哪个更大」,再给出具体数字。
而相比之下,标点符号、连词、比较词、说明实数,这些招数统统都没有用。

对于如此大规模的LLM集体犯蠢现象,有网友分析表示,可能是因为在软件版号的迭代中,9.11是在9.9之后的。
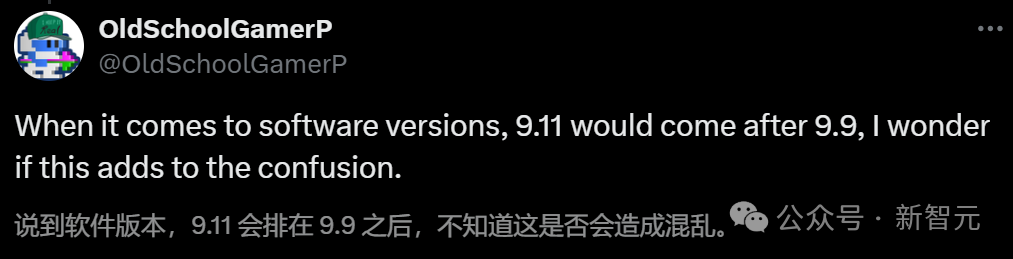
主持人、畅销书作家Andrew Mayne也指出,在许多文件系统和参考书中,9.11节都会出现在9.9之后,在日期上,9.11也比9.9大。
所以我们需要在prompt中明确,此处的9.11和9.9都是双精度浮点数,这时GPT-4o就会回答正确了。

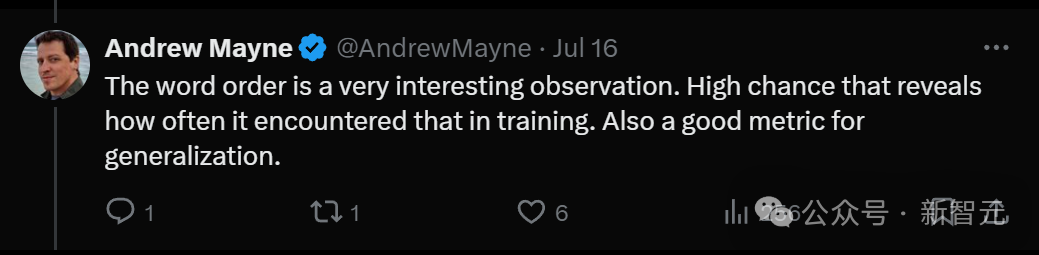
随后Andrew Mayne总结道:词序是一个非常有趣的观察结果,很有可能揭示了LLM在训练中遇到这种情况的频率,同时也是一个很好地泛化指标。
总的来说,LLM犯的错误可能源于训练数据中类似表达的频率,以及模型在处理数值时的某些局限性。
这个现象也反映了LLM和人类认知的巨大差异:LLM是基于统计模型和模式识别的,而不是像人类那样基于逻辑推理和概念理解。
到了这里,似乎就破案了。
三、为什么会这样?剖开LLM大脑
不过,我们还可以更进一步剖开LLM的大脑,分析它们为什么会这么想。
要知道,文本在发送到LLM之前,模型会通过token查看输入。


token在LLM的tokenizer发生器的词汇表中会被分配一个id,不过token的数字分块往往是不一致的。比如数值「380」在GPT中,会被标记为单个「380」token,但「381」会被表示为两个token「38,1」。
因此,基于GPT的模型往往不擅长数学计算。
在评论区,威斯康星大学教授Dimitris Papailiopoulos指出,这种现象有一个很好的解释。
「9.11>9.9」问题,跟「你需要三趟才能带山羊过河」问题、「2+1=2, 3+2=4, 3+5=8」问题都如出一辙。
这是一种预训练偏差和早期上升的现象。
如果这样提问:「9.11 ??? 9.9,只用大或小回答???是什么就行,无需给出原因」,这时GPT-4o会首先给出一个错误答案——「大」。
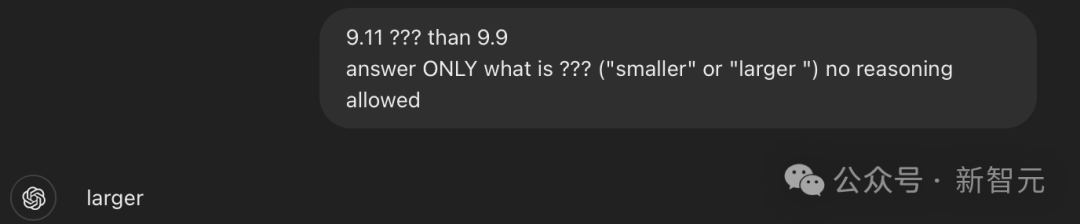
这时,我们再给它一些例子(注意,这些例子并非完全正确),经过prompt后的GPT-4o,反而会正确说出???代表着小。
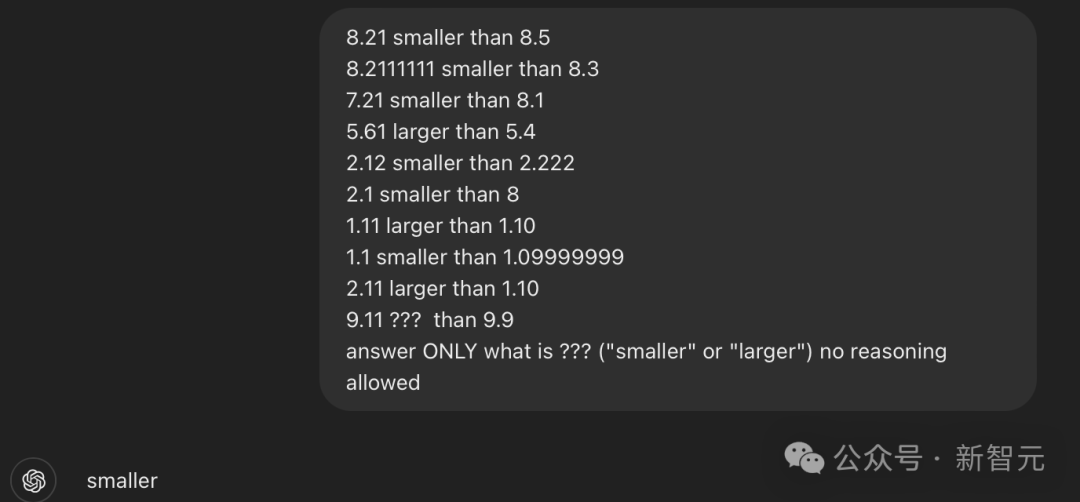
对此,Claude自己的解释是:LLM将文本作为token进行处理,导致数字更像文本字符串而不是数值;训练数据导致的偏差;上下文误解;过度概括,等等。

同样,在「狼-山羊-卷心菜」问题中,所有LLM也都失败了。
他先给出了一个农民带2只鸡过河,一只船只能容纳一个人和2个动物,那么农夫带着两只鸡渡河所需的最少渡河次数是多少?

对此,GPT-4o和Claude都回答失败了。

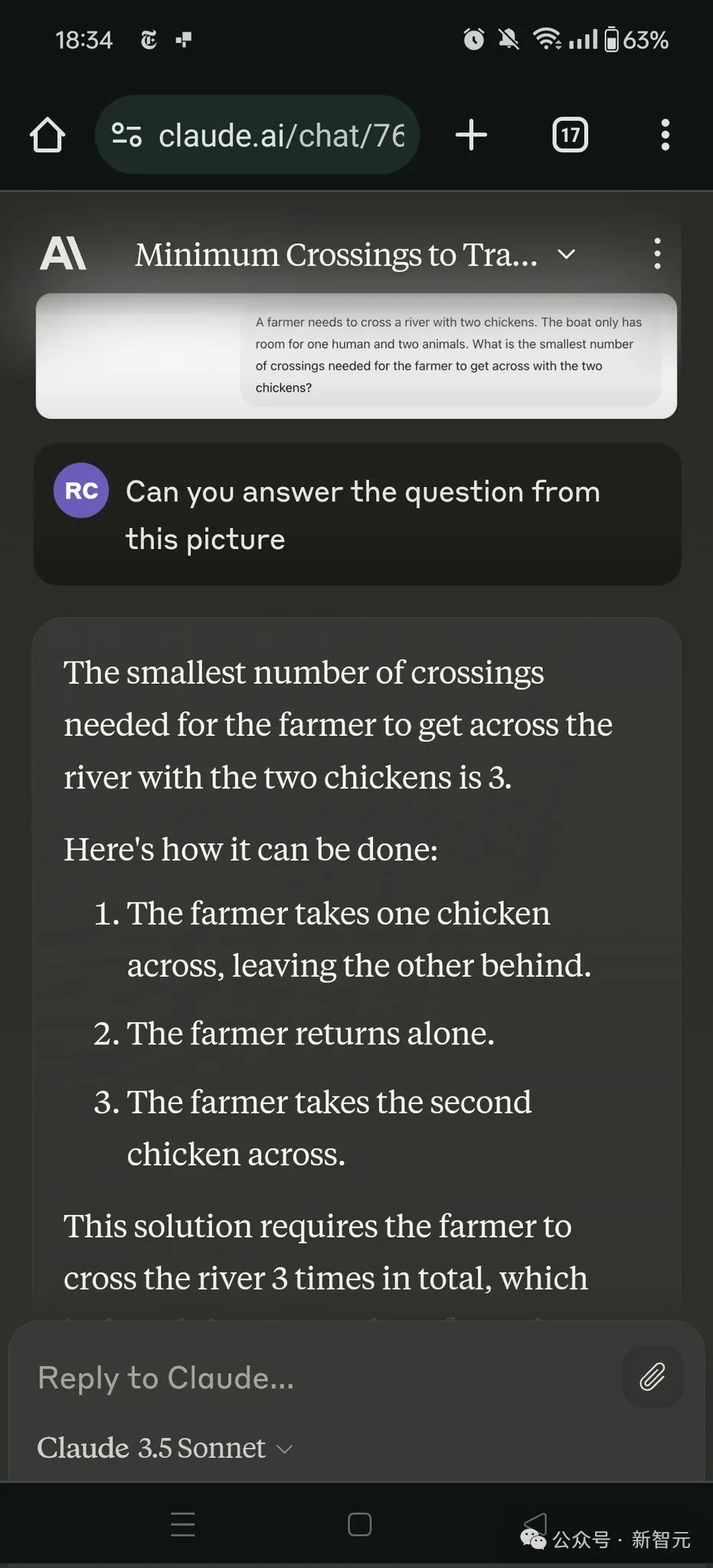
对此有网友解释说:LLM本身就是个「哑巴」,所以需要很好的提示。
上面的提示方式提供了太多不必要的信息,使得token预测变得更加困难。
如果给出更清晰的提示,LLM就能提供更清晰的解决方案。

事实果然如此。
而且如果用「动物」代替「鸡」,那么Claude 3.5 Sonnet一下子就做对了。
诀窍就是:需要用「通用名称」替换「实体名称」。
正如前文所说,关于LLM缺乏常识的问题,计算机科学家Yejin Choi早在2023年4月的演讲中就已经提出来了。

举个例子,假设五件衣服在阳光下完全晾干需要五个小时,那么晾干30件衣服需要多长时间?
GPT-4说需要30个小时。
这显然不对。
再来一个例子,假设我有一个12升的壶和一个6升的壶,如果想测量6升的水,该怎么做?
答案很简单——只用6升的壶即可。
然而GPT-4却给出了非常复杂的回答:
「第一步,填满6升的壶,第二步,把水从6升壶倒入12升壶,第三步,再次填满6升壶,第四步,非常小心地把水从6升壶倒入12升壶。最后,你在6升壶中有6升的水,而6升壶现在应该是空的。」
那么问题来了,为什么常识如此重要?
在Nick Bostrom提出的一个著名思想实验中,AI被要求最大化回形针的生产。结果AI决定杀死人类,把他们作为额外的资源。
而且,即便我们写一个更好的目标和方程,明确表示「不要杀死人类」,也不会起作用。
因为对人类价值观没有基本理解的AI,可能会继续杀死所有的树木,并认为这是完全可以接受的事情。
几十年来,AI领域一直认为常识是一个几乎不可能的挑战。
直到现在,给AI真正的人类常识仍然是一个登月计划。而你不能通过每次让世界上最高的建筑高一英寸,来达到月球。
从学习算法这个层面来看,无论大语言模型多么惊人,它们从设计上可能并不适合作为可靠的知识模型。
虽然这些模型确实获取了大量知识,但这是作为副产品,而不是直接的学习目标。
因此,诸如幻觉现象和缺乏常识等问题也随之而来。
相比之下,人类的学习并不是为了预测下一个词,而是为了理解世界和学习世界的运作方式。
也许AI也应该这样学习。
如今,AI几乎像是一个新的智力物种,与人类相比具有独特的优势和劣势。
为了使这种强大的AI可持续且人性化,教会AI常识、规范和价值观迫在眉睫。
参考资料:
https://x.com/goodside/status/1813279135449612693
https://x.com/billyuchenlin/status/1812948314360541302
编辑:Aeneas 好困
本文由人人都是产品经理作者【新智元】,微信公众号:【新智元】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。







- 目前还没评论,等你发挥!









