
 起点课堂会员权益
起点课堂会员权益OpenAI掀小模型血战!苹果DCLM强势登场,碾压Mistral 7B全开源
小模型时代来了?OpenAI带着GPT-4o mini首次入局小模型战场,Mistral AI、HuggingFace本周接连发布了小模型。如今,苹果也发布了70亿参数小模型DCLM,性能碾压Mistral-7B。

小模型的战场,打起来了!
继GPT-4o mini、Mistral NeMo发布之后,苹果也入局了。
DCLM小模型包含两种参数规模——70亿和14亿,发布即开源。最大70亿参数超越了Mistral-7B ,性能接近Llama 3、Gemma。

根据苹果ML小组研究科学家Vaishaal Shankar(也是DCLM研发人员)的说法,这是迄今为止性能最好的「真正开源」的模型,不仅有权重和训练代码,而且是基于开放数据集DCLM-Baseline。

相比模型性能,DCLM做出的「真正开源」的典范更加引人关注。
对比大部分科技巨头只搞闭源模型,或「犹抱琵琶半遮面」,只开源代码或权重的做法,大方的苹果获得了网友的好评。

此外,Shankar还预告说,之后会继续上线模型中间检查点和优化器状态。

难道,这就是LLM开源社区的春天了吗?
一、DCLM系列全开源
目前,HuggingFace上已经发布了全部模型权重,其中的模型卡已经基本涵盖了关键信息。
https://huggingface.co/apple/DCLM-7B
DCLM-7B同样采用了decoder-only的架构,使用PyTorch和OpenLM框架进行预训练。
总共4T token的DCLM-baseline数据集来自于总量240T的DCLM,DCLM-7B模型又进一步过滤出其中的2.5T用于训练。

上下文长度为2048,小于Mistral 7B和Gemma 2 9B的8k长度。
性能方面,作者直接使用评估套件LLM Foundry,测试了模型在53个基准任务上的分数。
与其他模型进行比较时,除了MMLU分数,作者还自定义了两个指标——「核心准确率」(core)和「扩展准确率」(extended)。
前者是包括HellaSwag和ARC-E在内的22个任务中心准确率的均值,后者则涵盖全部53个任务。
与虽然使用的数据不是最多,但与其他同等大小的开放数据模型(权重与数据集都开源)相比,DCLM在全部3个指标上的性能都达到了最佳。
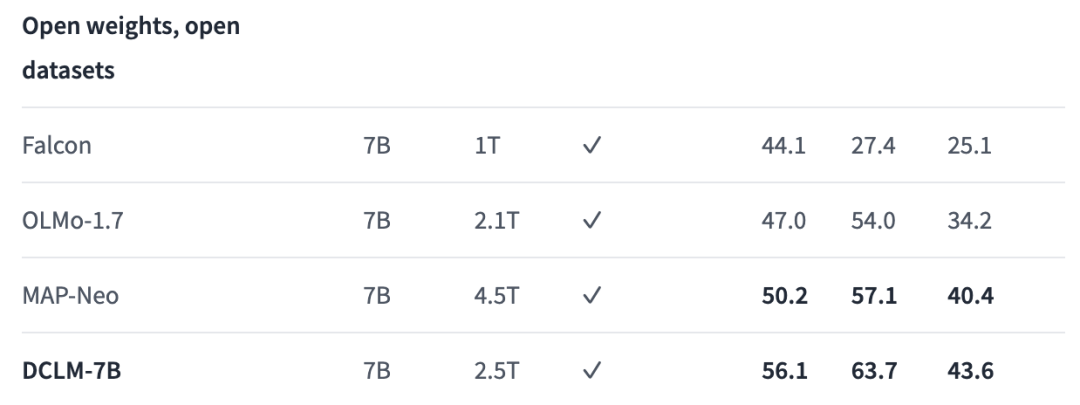
三列基准分数从左到右分别是:核心、MMLU、扩展
相比之前的SOTA MAP-Neo模型,DCLM-7B在5-shot的MMLU任务准确率达到63.7%,提升了6.6个百分点,同时训练所需的计算量减少了40%。
然而,如果和权重开源、数据集闭源的模型相比,效果就不尽如人意了。
DCLM在各个指标上都与Phi-3存在不小差距,与Mistral-7B-v0.3或Gemma 8B的分数大致相当。
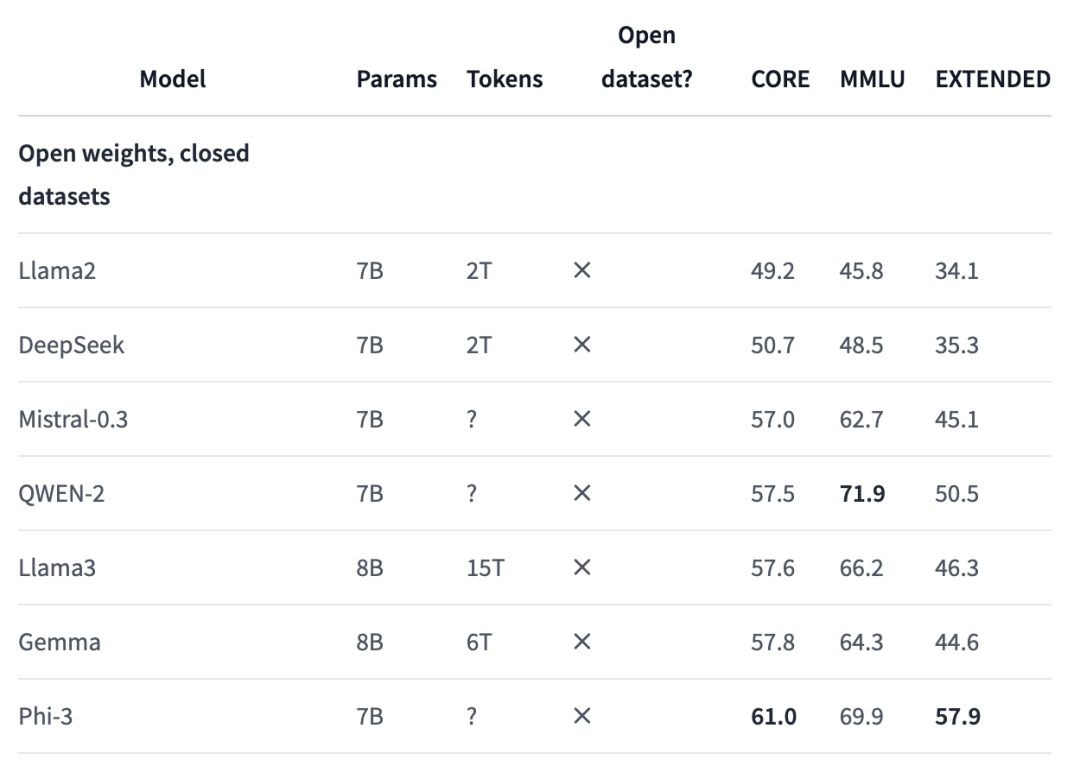
研究人员发现,如果使用同一数据集中额外的100B数据进行训练,并将上下文长度扩展到8k时,模型在核心和扩展基准上的分数还会进一步提升,但MMLU结果没有变化。

这个结果,就全面超过了Mistral 7B-v0.3的分数。
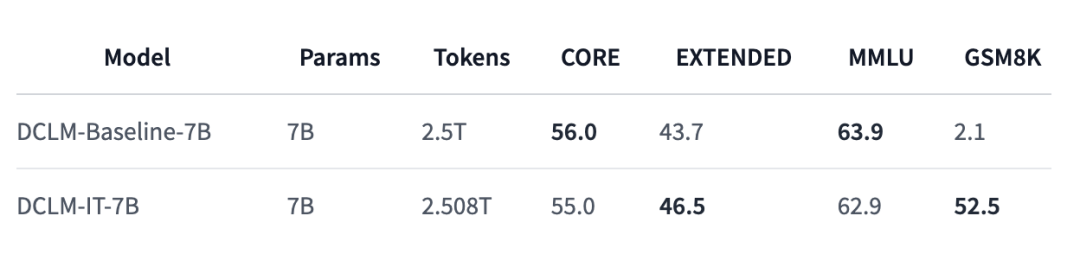
此外,HuggingFace上还发布了7B模型的指令微调版本,在数学推理任务GSM8K上的性能实现大规模提升,分数由原来的2.1直接飙到52.5。
https://huggingface.co/apple/DCLM-7B-8k
除了7B版本,1.4B版本也同步上线。神奇的是,训练数据量相比7B版本不降反增,多了0.1T。

https://huggingface.co/TRI-ML/DCLM-1B
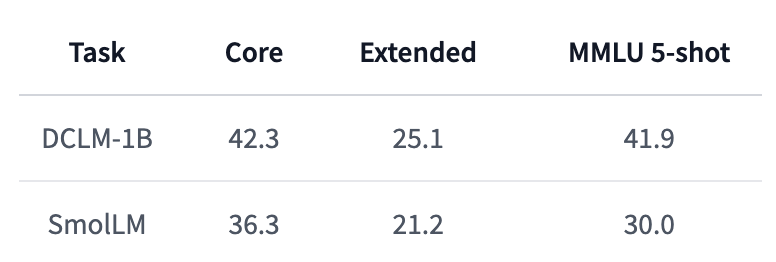
相比HuggingFace最近发布的SmolLM,DCLM-1B的性能显著更优,尤其是5-shot MMLU分数,比SmolLM提升了11.9%。
不仅如此,DCLM-1B在MMLU上41.9的得分也同样高于Qwen-1.5B的37.87和Phi-1.5B的35.90。
7B模型落后的事情,反而让1.4B模型反超了,果然小模型才是苹果的看家本领。
值得注意的是,7B模型仅能在Appl240万亿巨量数据被洗出,足够训出18个GPT-4!全球23所机构联手,清洗秘籍公开e的示例代码许可(ASCL)下使用,但1.4B版本在Apache 2.0下发布,允许商业使用、分发和修改。
既然说到这次发布的DCLM系列模型,就不得不提它们的重要基础——DataComp基准。

论文地址:https://arxiv.org/pdf/2406.11794
DataComp这篇论文首发于6月17日,共同一作Jeffrey Li、Alex Fang和共同最后作者Vaishaal Shankar,也同样都是苹果DCLM的研发人员。
文章不仅对数据集的构建过程进行了详细阐述,也提到了关于DCLM模型的部分内容。
Vaishaal Shankar表示,将很快发布这篇论文的更新版,提供更多有关模型预训练的技术细节。
相比于对同一数据集修改模型,DataComp的思路反其道而行之——测评所用的模型是固定的,任务是在总共240T的数据池中过滤、处理出最好的数据。
可以说,这种做法与科技巨头们的研发思路非常一致——对于LLM的性能而言,预训练数据正在成为比模型架构和权重更重要的因素。
毕竟,Llama、Gemma、Phi等一系列「开源」模型都是只放权重、不公布数据。
二、既要Scaling Law,又要SLM
对于AI科技巨头来说,有时模型不是越大越好。

其实一直以来,AI社区中,并不缺少小模型,比如微软Phi系列模型多次迭代,以及6月末谷歌刚刚更新的Gemma 2 7B。
这周,OpenAI突然发布GPT-4o mini,Mistral AI联手英伟达发布Mistral NeMo,HuggingFace的SmoLLM等小模型的发布,为小模型的领域再次添了一把火。
正如OpenAI研究员所言,「虽然我们比任何人都更喜欢训练大模型,但OpenAI也知道如何训练小模型」。

小模型,优势在于成本低、速度快、更专业,通常只使用少量数据训练,为特定任务而设计。
大模型变小,再扩大规模,可能是未来发展的趋势之一。

前两天,在GPT-4o mini发布时,Andrej Karpathy也发表长推表达了类似的观点。

他认为,模型尺寸的竞争将会「反向加剧」,不是越来越大,反而是比谁更小更轻巧。
当前的LLM之所以逐渐变成「巨兽」,是因为训练过程仍然非常浪费,我们基本上是在要求模型记住整个互联网的内容(而且实际上,LLM的记忆能力还相当不错,质量上比人类好很多)。
但对于小模型来说,训练目标已经改变。关键问题是,AI系统如何从更少的数据中学到更多。
我们需要模型先变得更大,再变得更小,因为我们需要「巨兽」将数据重构、塑造为理想的合成形式,逐渐得到「完美的训练集」,再喂给小模型。
马斯克也表示同意这个观点。Karpathy所描述的这个模型改进阶梯,正是现实中特斯拉曾走过的路。

23年4月,Sam Altman曾宣布了AI大模型时代终结。最近采访中,他还确认了数据质量是进一步AI训练的关键成功因素。

微软研究人员在开发Phi模型时,就提出了这样的假设。Hugging Face的AI研究人员最近也证实了这一假设,并发布了一个高质量的训练数据集。
就以GPT-4为例,开发和使用超一万亿参数的成本超过了1亿美元。
而小模型,比如专在法律数据集上完成训练,可能使用不到100亿参数,成本不到1000万美元,使用更少算力响应每个查询,因此成本较低。
纳德拉曾表示,Phi⼩型模型系列规模仅为OpenAI背后免费模型1/100,而且在许多任务上的表现几乎同样出色。

除此以外,谷歌以及AI初创公司Mistral、Anthropic、Cohere今年也发布了规模较小的模型。
6月,苹果曾公布了自己的AI发展路线图,计划使用小型模型,这样就可以完全在手机上运行软件,使其更快速和更安全。
对于许多任务来说,比如总苹果为什么要用「小模型」?结文档或生成图像,大模型可能有点大材小用。
Transformer开山之作背后作者Illia Polosukhin表示,计算2+2不应该需要进⾏千万亿次运算。
不过,科技巨头们也并没有放弃大模型。苹果在今年WWDC大会上,曾宣布了在Siri助手中植入ChatGPT,以执行撰写电子邮件等复杂任务。
毕竟通往终极AGI/ASI,参数规模的扩大和智能的增长成正比。
参考资料:
https://venturebeat.com/ai/apple-shows-off-open-ai-prowess-new-models-outperform-mistral-and-hugging-face-offerings
/https://www.wsj.com/tech/ai/for-ai-giants-smaller-is-sometimes-better-ef07eb98?mod=tech_lead_story
https://the-decoder.com/ai-models-might-need-to-scale-down-to-scale-up-again/
编辑:桃子 乔杨
本文由人人都是产品经理作者【新智元】,微信公众号:【新智元】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。






- 目前还没评论,等你发挥!


