
 起点课堂会员权益
起点课堂会员权益RAG实践篇(一):知识资产的“梯度”
近期我们结束了一个RAG项目的开发,后续将不定期掉落RAG系列的复盘与实践。如有兴趣的读者,欢迎收藏文章和关注。

你是某个企业的领域知识专家。这个月,你们公司的AI技术来通知你,你们公司会通过RAG技术,把企业的私有知识库搬进大模型。这样,以后和这个领域的专有知识有关的问题,AI就再也不会满嘴跑火车,拿着不知真假的回答忽悠人了。他们希望你协助整理相关知识,然后他们就能把相关知识“喂给”大模型了。
请问,作为一位领域内容专家,你此时要怎么做?
A. 多就是好!立刻把我们庞大的、百万体量的私有知识资产,源源本本地输入进去。
B. 知识资产要怎么放,放哪些,才是真的有效?
可能此时你的表情be like:

别急,我们先来了解一下,什么是RAG?为什么当企业要把领域知识/私有知识的“AI化”的时候,要用到RAG?
01 为什么是你?RAG
RAG的全称是Retrieval-Augmented Generation。中文可以翻译为“检索增强生成”。技术特点就是通过增强检索功能来辅助生成模型。这个技术可以允许大语言模型在“回答”之前,先从指定的“池子”里检索相关信息。这样,AI在回答问题时,它就不仅仅是依赖于其训练期间所学习到的数据,而是能够参考更多、特定的上下文信息。
说到这里,你应该能明白,RAG对企业私有知识库的作用了。从目前的生成式AI的技术而言,大模型们虽然对各种主题都有着惊人的了解,但这些了解仅限于它们训练时使用的数据,我们姑且称之为“世界知识”。这意味着当我们将它用于企业私有或专有业务信息的时候,大模型的惊人理解力就无用武之地了。因为它根本没有“训练”过相应的知识。
而RAG(检索增强生成)技术等于给大模型开了一个知识“外挂”。通过这个“外挂”,一些并没有包含在原始的模型训练数据中的企业私有知识、专有业务信息,也能够被检索到,然后生成正确的输出。
简单来说,RAG的工作流程可以分为以下几个步骤:
- 检索:当用户提出一个问题时,RAG首先会在一个或多个文档数据库中查找相关的文档片段。
- 上下文融合:找到相关的文档后,RAG会将这些信息与问题本身结合起来,形成一个完整的上下文。
- 生成响应:最后,基于这个上下文,RAG生成一个自然语言响应,该响应应该是准确且符合上下文的。
02 有“外挂”,一劳永逸?
不过,当我们用RAG技术为AI模型输入知识库时,并不像往图书馆里添加新书一样清楚简单。毕竟是一种“外部检索”技术,稍有不慎就会翻车。以下是我们在做RAG时,经常会踩的坑:
1. 晦涩的专业术语
误区:在专业领域中。许多文献和资料中充满了专业术语,这些术语对于非专业人士(甚至是大模型)来说都是难以理解的。
风险:当知识库内容包含大量专业术语、且文献错综复杂,对术语没有做出很好的解释和关联时,模型可能就会“倒在”第一步。因为它根本无法很好地理解这些术语,更遑论最终输出正确的答案了。
2. 信息提取困难
误区:有时候,文献量太大,RAG系统在处理大量文本数据时,它可能无法有效地从中抽取关键信息。
风险:如果模型无法从复杂的文献中提取出核心要点,那么生成的答案可能会缺乏重点,或者包含大量无关紧要的细节,例如,在法律文献中,关键条款往往隐藏在大量法律条文中,模型在检索时可能会“忽略”,或者一股脑地提取。导致回答要么缺漏重点,要么又多又杂、找不到重点。
3. 自相矛盾/不一致的信息
误区:有时候文献过多,输入到RAG系统中的数据可能包含不准确或错误的信息。比如,一个医疗的RAG系统,它的目的为医生和患者在进行询问时,提供准确的药品信息。但是,这个系统在知识库的建立时,收集了多种来源的药品说明书、临床试验报告以及最新的医学研究论文。就极有可能出现以下情况:
- 说明书A(来自制造商X,2020年发布):“阿莫西林适用于治疗多种细菌感染,如肺炎、咽炎和皮肤感染。,成人每日剂量为500毫克,每日三次。”
- 最新研究论文C(2023年发表):“最新的临床研究表明,阿莫西林对某些类型的细菌感染不再有效,因为它可能导致耐药性。”
风险:生成答案时,可能会出现自相矛盾的回答,或者是每次的回答都不一致,容易误导用户。
4. 过时内容
误区:过时内容是指知识库中的某些信息可能已经不再适用当前的情况。
风险:如果RAG系统提供了过时的信息,那么这些信息可能会导致用户做出基于过时数据的决策。例如,在技术快速发展的领域,如信息技术或生物医药,几年前的研究成果可能已经不再适用。
5. 无关且多余的信息
误区:无关且多余的信息是指知识库中包含了一些与当前问题无关或多余的内容。
风险:这些信息可能会干扰模型的判断,导致生成的答案中包含不必要的细节,从而使答案显得冗长而不切题。例如,在用户询问某一产品的具体规格时,系统却给出了大量与产品无关的市场营销材料。
6. 与“世界(知识)为敌”
误区:这种经常出现在一些“软”知识上,比如公司管理、领导力咨询等等。在这种知识领域,并没有唯一的、正确的答案,而是不同的“学派”会有不同的切入点和理论体系。这样,同一个概念,在私有知识库和世界知识的说法不同,就可能产出冲突。
风险:模型回答的输出不稳定。面对“外挂”给到的知识点和自己训练时就有的数据,大模型容易陷入“本能迁移”,更倾向于用自己训练时的数据做回答。
03 知识资产的“金字塔”梯度
看完了以上的误区,你可能已经隐隐有感觉:“喂给”RAG的知识库,并不是越多越好。
尽管从知识库到正确的回答的输出,需要算法工程师进行技术的微调,但是从领域专家的角度,梳理和建设知识库时,就需要牢记以下原则:
并不是所有的知识都是平等的。你需要评估哪些知识“有价值”,而价值的私有知识,才可以称之为“知识资产”,并放入知识库之中。
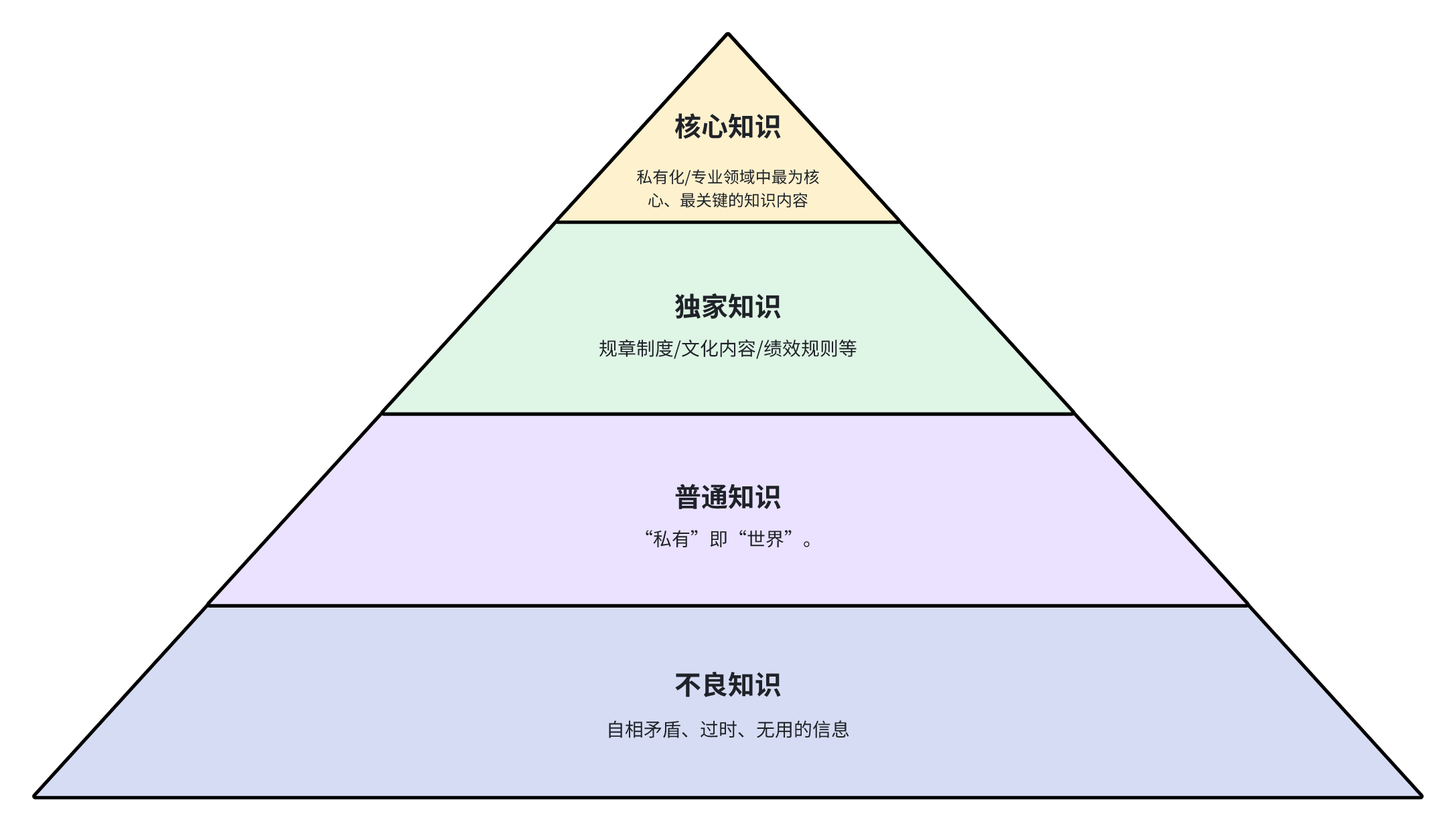
那什么是有价值的知识资产?尽管各领域的知识内容不尽相同,但在实践中,我们可以遵循金字塔梯度的思路:
- 顶层,核心资产:这应该是公司私有化/专业领域中最为核心、最关键的知识内容。也是这个私有知识库最想给用户传递、最有竞争力的知识体系。例如,一家咨询公司赖以成名的核心方法论,就是这家公司最核心的知识资产。在RAG的实践中,一旦涉及到这类范围的知识理解和输出,必须要求准确、全面、深入,能够体现权威性。
- 次层,独家资产:重要等级比关键知识略低,但同样是私有知识库中的独特的资产。这些知识也许会和世界知识有重合,但在私有知识库中,必须按照私有知识库中的要求回答。这类知识的一种常见场景就是公司的规章制度/文化内容/绩效规则等,世界知识库也许有大量类似的内容,但是在公司中必须要按照公司的要求进行。因此,对这类知识的解读也同样要求准确,且必须以私有知识库为准,不得混淆世界知识。
- 第三层,普通资产:在实践中,经常会出现一种情况:“私有”即“世界”。说白了,不管是多私有的知识,它的源头必然能追溯到人类公有的知识体系中。所以,私有知识库免不了有一些“其实和世界知识差不多,但表述、范围上略有差异”的内容。这类其实是最容易和世界知识发生混淆,造成输出不准确/冗余的“元凶”。因此,这类知识,我们建议不必“敝帚自珍”,在建立知识库时大刀阔斧地去除即可。
- 第四层,不良资产:包括自相矛盾、过时、无用的信息,这些不良资产,一定要尽早剥离。在进行知识库的建设时,就不能存在。
本文由 @AI 实践干货 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务









期待更多分享,另外咨询下,企业知识库的更新频率如何,是对全员开放的吗?其中会不会存在一些权限问题