
 起点课堂会员权益
起点课堂会员权益干货分享 | RAG的5种切分策略
这篇文章将带你深入探索RAG的五种切分策略,这些策略是优化RAG工作流程的第一步,对于提高信息检索的效率和准确性至关重要。

RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合了信息检索技术和语言生成模型的人工智能技术。RAG模型由Facebook AI Research(FAIR)团队于2020年首次提出,并迅速成为大模型应用中的热门方案。
RAG的基本思想是通过从外部知识库中检索相关信息,并将这些信息作为额外的上下文提供给语言模型,从而增强模型生成文本的能力。能帮助模型减少幻觉、提高内容生成的准确性。
本文主要介绍RAG工作流程的第一步涉及的5种切分策略。
01. RAG应用工作流程
以下是典型的RAG应用工作流程:
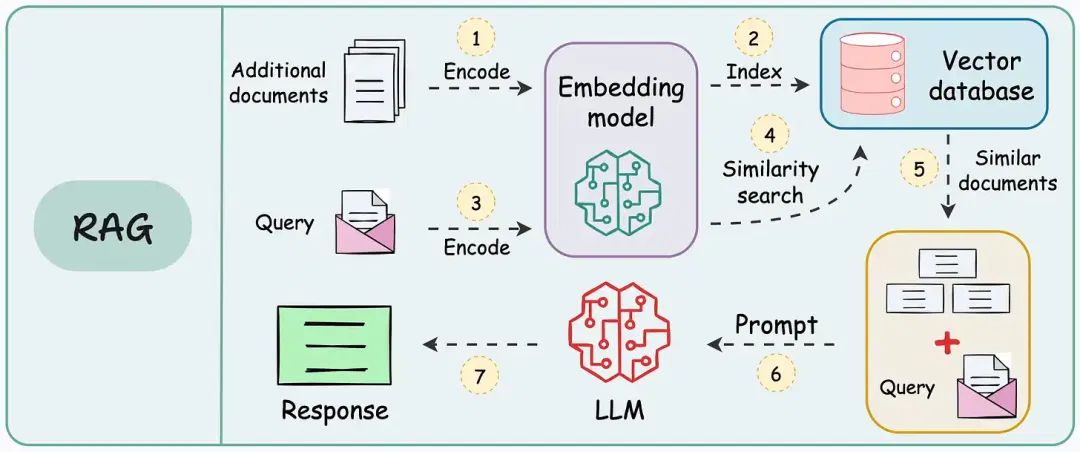
RAG:将额外信息存储为向量,将传入的查询与这些向量匹配,并将最相似的信息与查询一起传递给大语言模型(LLM)。
由于额外的文档可能非常大,第1步还需要进行切分操作,将大文档分割成较小、易于管理的部分。
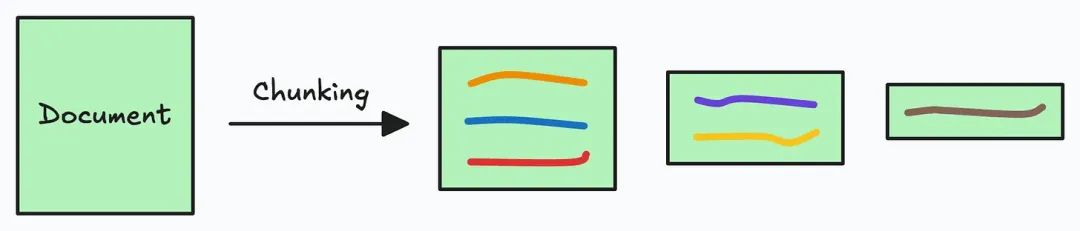
这一步至关重要,它确保文本能够适应嵌入模型的输入大小。此外,它提高了检索步骤的效率和准确性,这直接影响生成响应的质量。
以下将逐步介绍RAG的五种切分策略:
02. 固定大小切分
最直观的切分方法是根据预定的字符数、单词数或Token数量将文本均匀分割成若干段落。
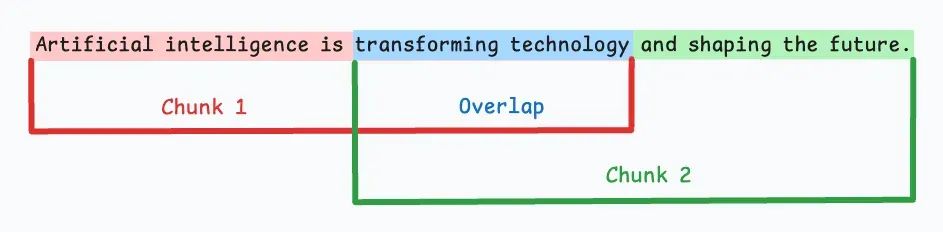
由于直接切分可能会破坏语义流畅性,建议在连续段落间保留一些重叠(如上图的蓝色部分)。
这种方法易于实现,而且所有段落大小相同,有助于简化批处理。
但它存在一个大问题:通常会在句子(或想法)中途切分,导致重要信息可能分散在不同段落中。
03. 语义切分
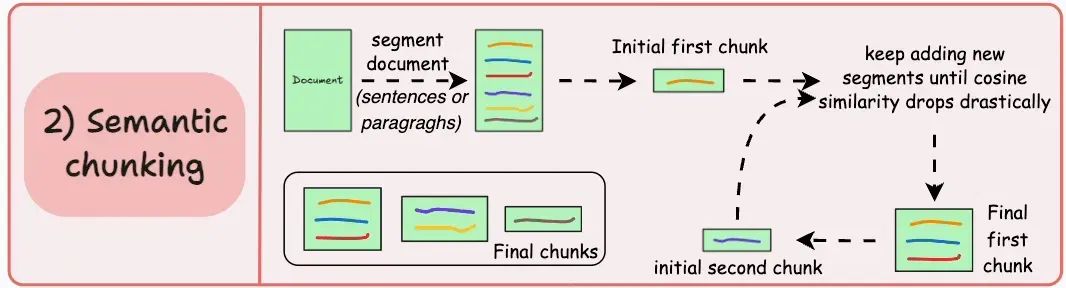
根据句子、段落或主题部分等有意义的单元来切分文档,接着,为每个段落生成嵌入,假设从第一个段落及其嵌入开始。
- 如果第一个段落的嵌入与第二个段落的嵌入余弦相似度较高,则两个段落组成一个切片。
- 这个过程持续进行,直到余弦相似度显著下降。
- 一旦下降,我们就开始一个新切片并重复此过程。
输出可能如下所示:

这种方式与固定大小切片不同,能够保持语言的自然流畅性,并保留完整的思想。
由于每个切片语义更为丰富,它提高了检索准确度,进而使LLM生成的响应更加连贯且相关。
一个小问题是,确定余弦相似度下降的阈值在不同文档间可能有所不同。
04. 递归切分
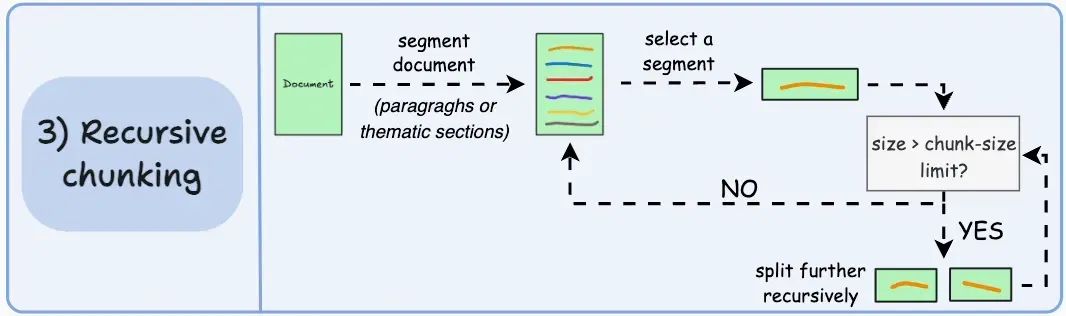
首先,基于内在的分隔符(如段落或章节)进行切分。
然后,如果某个切片的大小超过预定义的切片大小限制,就将其进一步分割。如果切片符合大小限制,则不再进行切分。
输出结果可能如下所示:

如上所示:
- 首先,我们定义了两个切片(紫色的两个段落)。
- 接下来,第1段被进一步分割成较小的切片。
与固定大小的切片不同,这种方法也保持了语言的自然流畅性,并保留了完整的思想。
不过,在实现和计算复杂性方面有一些额外的开销。
05. 基于文档结构的切分
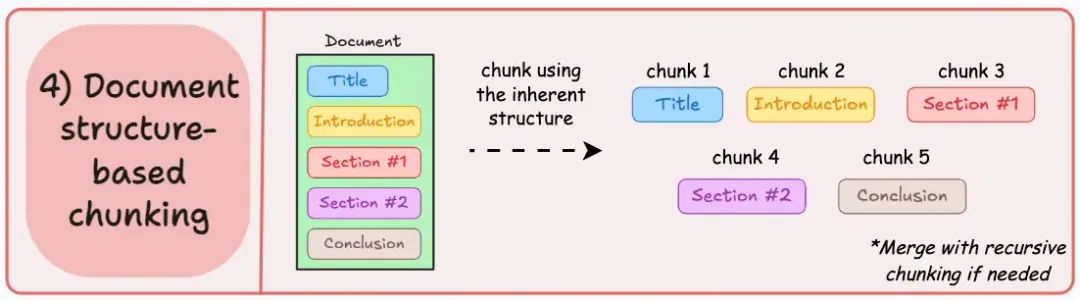
利用文档内在的结构(如标题、章节或段落)定义切片边界。
这种方式能保持文档的结构完整性,确保切片与文档的逻辑部分对齐。
该方法假设文档结构清晰,但这可能并非总是如此。此外,切片长度可能不同,甚至超过模型的Token限制。可以尝试与递归切分结合使用。
输出结果可能如下所示:

06. 基于LLM的切分

由于每种方法都有其优缺点,为什么不让LLM来生成切片呢?LLM可以通过提示词生成语义隔离且有意义的切片。
显然,这种方法确保了高语义准确性,因为LLM能理解上下文和意义,远超简单的启发式方法。
唯一的问题是,这种方式的计算成本是五种方法中最高的。此外,由于LLM通常有上下文窗口限制,需要对此加以处理。
总结
每种技术都有各自的优劣,不过我发现语义切分在许多情况下效果不错,但仍然需要根据实际情况进行测试,最终的选择将取决于内容的性质、嵌入模型的能力和计算资源等。
作者:小布Bruce,公众号:AI思
本文由 @小布Bruce 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自 Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务






- 目前还没评论,等你发挥!


