起点课堂会员权益
起点课堂会员权益
现阶段的大模型,发展在放缓,还是提速?
 产品经理专业技能指的是:需求分析、数据分析、竞品分析、商业分析、行业分析、产品设计、版本管理、用户调研等。
产品经理专业技能指的是:需求分析、数据分析、竞品分析、商业分析、行业分析、产品设计、版本管理、用户调研等。自从ChatGPT 4.0 发布之后,大家一方面期待着5.0的发布,一方面国内大模型开始卷智能体和应用,以至于有人开始怀疑:大模型是不是变慢了?这篇文章,希望可以解答你的疑问。

最近逛知乎听到不少声音:这波大模型是不是到了低谷期?感觉热度不比以前了。等了一年都没等来GPT-5,的确大模型更新速度也变慢了…
这个话题成功激发了我的好奇心,同时也引发了系列思考:
目前大模型的发展是否真如有的人所说在降温降速?如果行业热情和前景还在,那么今年以来,为什么国内外大模型的发展会给人们带来这种感觉?有哪些深层次的原因在左右整个行业的发展走向?于是便有了此文。以下,共享~
一、这波大模型是否到了低谷期?
作为大模型赛道的一员,身在其中,笔者可能没觉察到多少异样。恰恰相反,个人感觉对比2023年,行业客户对大模型及AI应用的接受度和商用认可度有增无减。尤其随着越来越多大模型应用案例的成功落地,AI加速赋能千行百业正逐渐从“口号”变成现实。

如果说低谷是指“百模大战”的新进参与者不再是野蛮增长的状态,或者现有大模型选手的更新频次不同以往,个人觉得这或许是行业自然发展的一种映射。
毕竟大模型赛道本身具有一定进入门槛,只有前期拥有较深的技术沉淀和长期的蓄力的选手,才能获得准入资格。在市场爆发的窗口期,有条件的选手基本已经抢先进入。即便有后来者,但在越发拥挤的赛道和逐渐激烈的市场竞争面前,再进入的一般不会太多。即便有,也可能另辟蹊径,这是其一。
其二,因为基础大模型一开始就很偏向于“巨头间的游戏”,少数头部玩家手握绝大多数的资金和资源,这使得这一赛道的新进入者,更容易在持续高投入面前望而却步。相比之下,大模型应用赛道有更多发展可能,但在多方势力角逐下,行业也在面临洗牌,呈现“强者愈强,弱者愈弱”的局面。随着市场格局逐渐成型,新加入的玩家少,也容易带来行业降温的错觉。
从大模型厂商的产品更新看,虽然今年以来,很多主流玩家很难保持刚成立时“拼命三郎”式的更新频率(比如百川智能在成立半年内接连发布baichuan-7B/13B、Baichuan-53B、Baichuan2-7B/13B等多款大模型产品),但整体的“上新”力度和性能提升依然可观。
比如自2018年发布GPT-1以来,一直保持几乎一年一次迭代的OpenAI,今年虽然没带来大众期待已久的GPT-5,但推出的新一代大模型o1仍在业内引起了轰动,还开创了Scaling law定律外,不拼数据量,也能实现模型性能显著提升的新思路。
OpenAI强有力的竞争对手Anthropic去年3月、7月、11月密集发布了Claude初版,Claude 2,Claude 2.1,今年节奏虽有放缓,但也在3月和10月先后发布Claude 3系列、升级版 Claude 3.5 Sonnet、新Claude 3.5 Haiku等模型,整体表现还算平稳。
国内基础大模型方面,阿里于今年5月发布通义千问2.5,6月百度上线文心大模型4.0 Turbo,百川智能在今年上半年先后发布千亿参数大模型 Baichuan 3、角色大模型Baichuan-NPC、新基座大模型Baichuan 4,智谱年内陆续推出GLM-4、CogVideoX、GLM-4-Plus、GLM-4V-Plus…总体来看,国内主流大模型厂商其实动态不断。
但为什么还是有人感觉大模型更新好像没那么勤了,热度也降了?
除了因高质量数据、算力等方面面临瓶颈,导致模型代际周期受到一定影响(“大力出奇迹”式Scaling law策略不再那么有效可行)。笔者觉得,很大一部分原因,可能在于持续惊喜和刺激后带来的情绪波动在变小。毕竟前期给到大众模型性能越惊艳,后期除非有突破式进展,否则人们面对再多的水花也可能波澜不惊。而目前抛开Scaling law另辟蹊径,来大幅拓展AI大模型的能力边界,需要时间,也需要大量的探索。这也推动着大模型厂商降低迭代速度,从“小步快跑”转向长线运营。
此外,商业变现压力也推动大模型厂商放慢迭代速度,转向客户转化和服务。为此,我们也不难发现:今年以来,国内外主流大模型厂商都在加快商业模式的完善和行业落地。当提升产品的适用性与性能,比起大量开发新品占有更多优先级,也可能引起大模型发展放缓的错觉。
二、大模型发展正呈现哪些趋势?
目前基础大模型及大模型应用赛道正稳步前行,但仍呈现出一些代表性趋势。
比如上面提到的AI大模型底层技术的对齐与进阶。
就行业而言,现阶段GPT-4 Turbo、新模型o1仍代表业界前沿水平,也是国内大模型争相对标和赶超的对象。而就内部来说,推动新模型产品在性能、模型能力等方面,实现比以往大模型产品有显著的提升和进阶,这样的举措只会多,不会少。
其次,大模型多模态能力的开发正成为很多大模型服务商不约而同的选择。尤其是视频生成领域,今年以来,国内主流的基础大模型厂商对标Sore,基本都推出了自己的重量级视频生成模型。
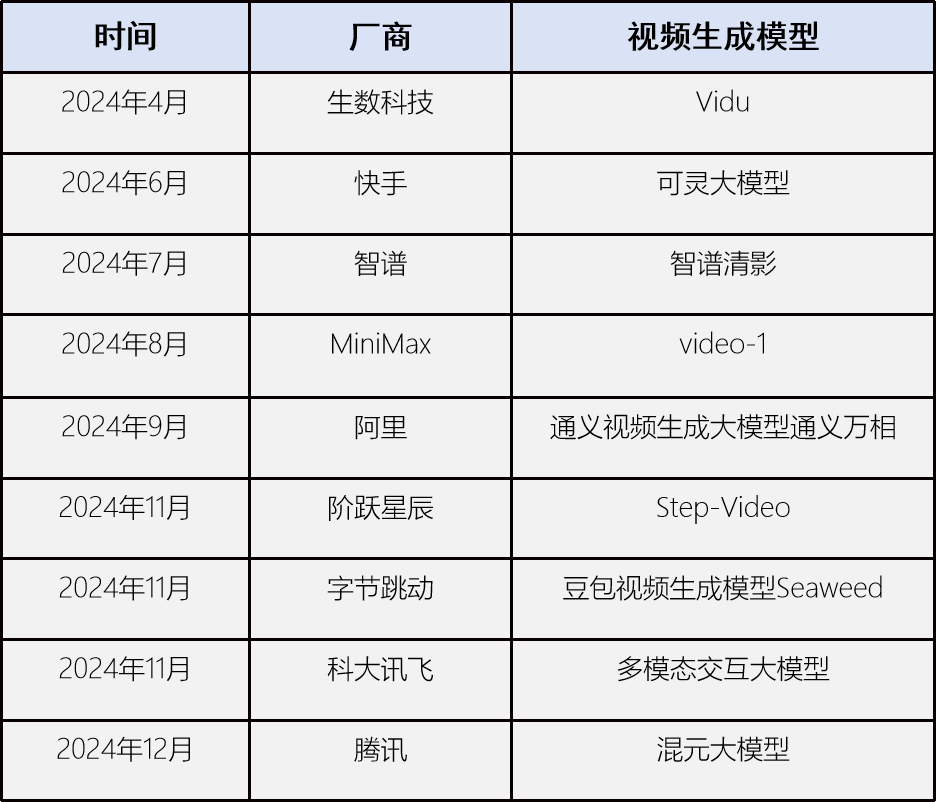
摘自网络公开信息,以上为不完全统计,仅供参考
从结果看,处于V2.0阶段的视频生成模型在提示词还原度、物理模拟、画面表现力、运动控制、运镜控制、光影反射、主角统一、镜头切换、视频长度、生成等待时长等方面均有不同程度的提升。加上视频生成与广告、影视、动画、游戏等多领域的业务关联与广阔的商用前景,使得AI视频生成模型虽然并非全新的赛道,却因为能力方面的大幅跃迁,吸引到更多玩家布局。
大模型应用方面,虽然比拼的焦点不在视频生成模型,但图像理解、音频理解、视频理解等方面的能力和需求,在客服、销售、营销等场景的落地过程中的显得越发强烈。以上推动当下一些大模型应用商深度打磨多模态能力,以更好地服务于相应业务场景。
与此同时,为了满足复杂场景的应用需求,拓展大模型的能力边界,发展AI agent(智能体)也正成为基础大模型及应用厂商主动或被动的选择。
比如越来越多的通用大模型厂商倾向于通过对智能体的探索,挖掘和自身业务更匹配的应用场景。而大模型应用厂商为了打造更智能、强大的AI应用产品,增强自身竞争优势,也陆续在智能体应用上投入更多的精力。
尤其是今年以来,包括微软、谷歌、百度等在内的公司,在加大布局AI业务的同时,也加快推出了自己的AI智能体生态项目。而在实际落地中,AI公司利用智能体,丰富商业化场景的案例也相当普遍。
三、写在最后
综上,随着现阶段大模型市场的成熟度越来越高,行业逐渐告别野蛮生长的状态,从百花齐放走向开花结果。也许在时间长河中,行业有高潮,也有低谷,但高潮与低谷其实本身就是一种常态,也是一种相对的状态,与其介怀,还不如一同前行。
在商业化压力的推动下,国内外基础大模型厂商纷纷和应用结合,并布局多模态能力、智能体等,以拓展AI的应用场景,加速通用人工智能的实现,这点显得有些不谋而合。
司普科技CEO张振广先生曾在公开演讲时表示:目前就AI大模型而言,世界牌桌上其实只有2.5个对手。特别是今年以来,大模型领域,中美的双强格局越发明显。
也许在底层技术上,国内之前大多处于追赶状态,但随着新一波大模型尤其是多模态模型的深度发展,有些方面我们其实已经走在了前面。
备注:本文原创,首发司普科技,第三方首发人人都是产品经理。
本文由 @iseeworld 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自 Unsplash,基于 CC0 协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。







- 目前还没评论,等你发挥!