
 起点课堂会员权益
起点课堂会员权益五大要点,解析区块链产品的设计基础
本文主要列举了一些我在区块链产品设计过程中,遇到的与区块链相关的常见问题和处理方案,适用于准备或初入区块链行业的产品经理阅读。本文中列举的处理方案并不是唯一的,如果大家有其他方案,或遇到了其他的问题,欢迎留言讨论。

一、上链数据处理
1. Hash
一般的,出于以下原因,我们无法在区块链上存储数据的原文:
- 数据隐私;
- 避免因数据量过大,加重全节点的存储负担;
- 矿工可能分布于世界各地,假设北京的矿工广播了一个高度为100的新挖出的区块(命名为区块100A),受网速影响,位于北京的另一位矿工和位于非洲的矿工接收到这一区块的时间必然不同。区块越大,非洲的矿工接收到区块100A的时间越晚。这就导致了非洲的矿工可能会在高度为99的区块的基础上继续挖矿,进而挖出了区块100B并广播,此时就出现了有竞争关系的两条分叉,分叉A和分叉B,直到新的主链被选择。这进一步导致了在未被选择为主链的分叉上挖矿的矿工所做的工作均作废,造成了资源的浪费。
出于上述原因,普遍做法是在区块链上存储数据原文的Hash值。基于Hash算法的特点,数据原文均会被转换为固定长度的字符串,且无法通过Hash值反推出数据原文,简单有效地避免了上述问题的发生。
当然,这一做法也有其局限性,即只存储Hash值的区块链,只能用作数据在某一时刻的存在性验证,而无法替用户存储数据原文。数据原文需由用户自行保管,或交由第三方机构保管(可能面临数据被篡改而无法通过验证的风险)。
2. Merkel Proof
在日常工作中,我们可能会面临这样一种情况:一条数据包含A、B、C、D四个字段,此时如何将这条数据上链呢?
简单的将字段A、B、C、D连接并进行Hash是一种方案,但对于某些场景,比如应聘者要将这条数据分享给用人单位,但出于隐私考虑,只想分享字段A、B的数据原文,而不想分享字段C、D的数据原文,在这一场景下,只对数据进行Hash计算并上链,显然无法满足这一需求。
此时,一种可行的方案是基于Merkel Proof,使用各字段计算出Merkel Root Hash,并将该Root Hash上链。Merkel Root Hash的计算过程示意见下图。
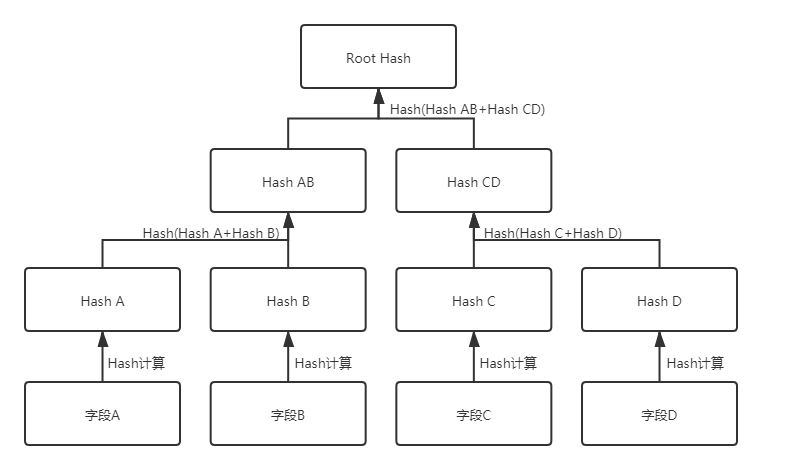
当用户在分享数据时,愿意展示给他人的字段显示为数据原文,不愿意展示给他人的字段显示为Hash值,根据Merkel Proof,拿到这条数据的人依然可以计算出Merkel Root Hash,并在区块链上验证数据是否未被篡改。示意如下图:
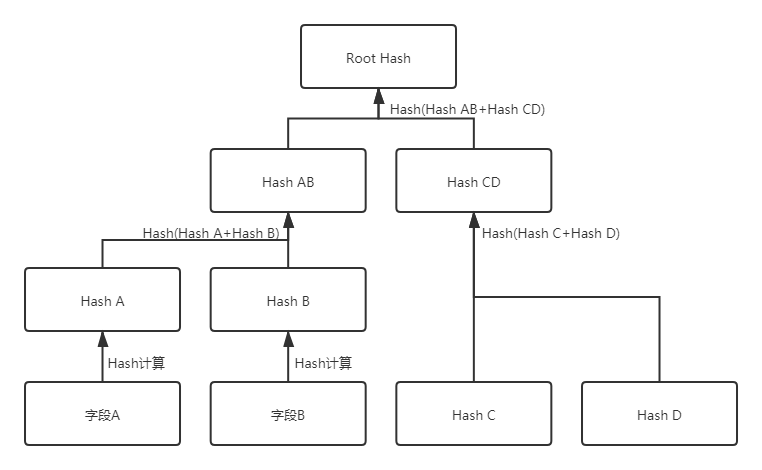
应用Merkel Proof除了可以解决涉及隐私的数据分享的问题外,还可以大幅降低上链数据的数量,间接提高TPS,如果数据上链是在如以太坊等公链,还可以大幅降低上链成本。
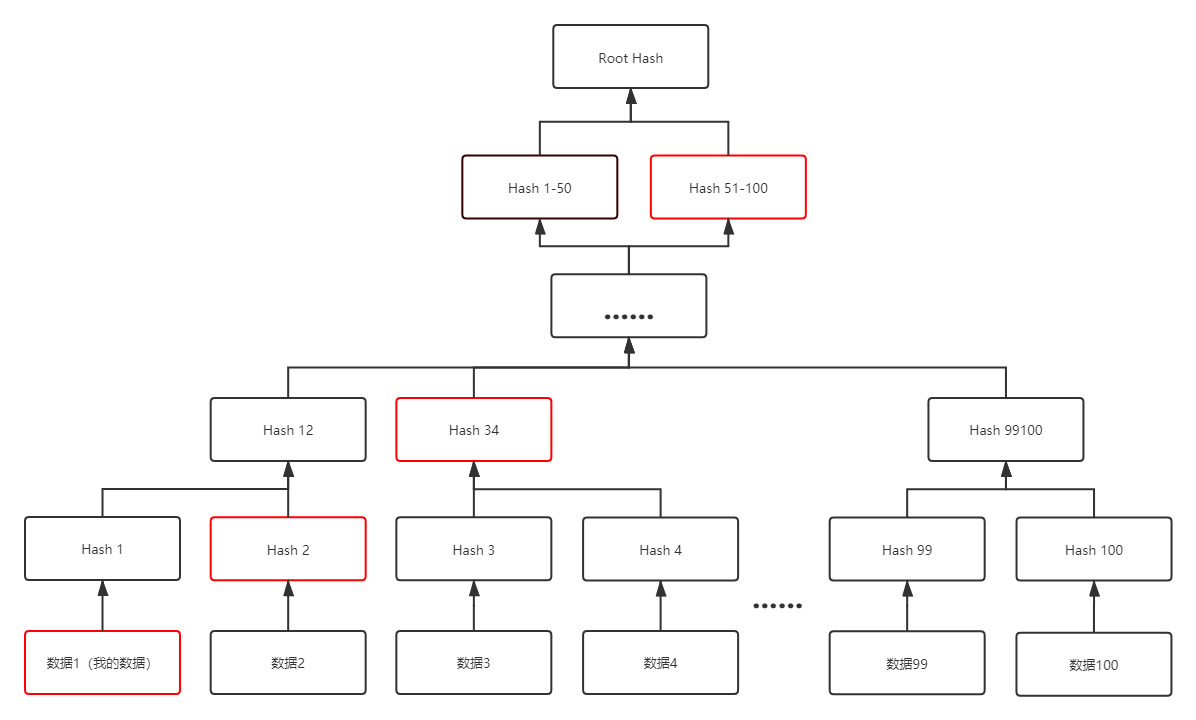
例如,有100条数据需要上链,通过Merkel Proof,可以将这100条数据计算为一个Merkel Root Hash。
缺点在于,若用户自行保管数据,除了要保管自己的数据外,还要保管跟自己的数据相关的数据Hash,增加了用户需要存储的数据量。
示意如下图,用户需要保管红框中的数据。
二、私钥管理
私钥管理目前常用的有四种模式:
1. 不为用户生成公钥和私钥
用户在签名交易(数据上链)时,由平台使用统一的私钥进行签名。
优点:用户学习成本很低;开发成本低;用户不需要担心私钥丢失问题。
缺点:由于所有数据均使用一个私钥签名,无法在区块链上区分执行数据上链操作的用户;过于中心化的处理方式,导致用户有可能质疑上链数据的真实性;平台将承担重大的安全责任。
2. 为用户生成公钥和私钥
私钥由平台统一保管,用户在签名交易(数据上链)时,由平台直接使用用户私钥签名。
优点:用户学习成本很低;开发成本低;用户不需要担心私钥丢失问题;可以在区块链上分辨出数据是由哪个用户执行的上链操作。
缺点:过于中心化的处理方式,导致用户有可能质疑上链数据的真实性;平台将承担重大的安全责任。
3. Keystore
为用户生成公钥和私钥。其中私钥由用户自行设置密码加密,并由平台统一保管。用户在签名交易(数据上链)时,需输入密码解密获得私钥并签名。
优点:用户学习成本较低;可以在区块链上分辨出数据是由哪个用户执行的上链操作;在某种程度上,可以认为是去中心化的数据上链方式。
缺点:开发成本高;用户多了一步设置密码操作,以及在每次执行上链操作时多了一步输入密码的操作;由于平台没有保存用户私钥的原文,一旦用户丢失或忘记用于加密私钥的密码,后续该用户上链的数据的真实性将无法保证,甚至无法执行上链操作。
4. 为用户生成公钥和私钥,由用户自行保管私钥。
优点:开发成本很低;可以分辨出数据是由哪个用户执行的上链操作;完全去中心化的数据上链方式。
缺点:用户学习成本高;用户每次执行上链操作时多了一步输入私钥的操作;由于平台没有保存用户私钥的原文,一旦用户丢失或忘记私钥,后续该用户上链的数据的真实性将无法保证,甚至无法执行上链操作。
具体采用哪种方式,需要根据去中心化要求、安全、成本、开发能力等多方情况综合考虑。
三、私钥的丢失处理
在第三节列举的私钥管理方案中,无论私钥由平台保管还是用户保管,都可能涉及遗忘私钥或私钥的加密密码的情况。在传统互联网产品中,若用户忘记密码,可以通过手机号、邮箱等方式重新设置密码,但对于区块链产品,无论是私钥还是私钥的加密密码,都不能简单的使用传统的忘记密码流程进行处理。
目前一种可行的处理方式是,在区块链上的智能合约中,记录用户信息、用户公钥地址、公钥地址的有效状态(包括有效和实效)和失效时间。其中公钥地址为与用户私钥唯一对应的公钥的Hash值,有效状态和失效时间用于在数据验证时,验证数据的有效性(在第七节将具体说明)。
当用户遗忘私钥或私钥的加密密码时,可以为其重新生成一组公私钥对,并把新的公钥地址写入智能合约,并与用户信息关联,同时将旧公钥地址的有效状态改为失效,并写入失效时间。
可见,这一方式通过在区块链上为用户关联多个公钥地址,解决了用户遗忘私钥或私钥加密密码的问题,同时还能标识出公钥的拥有者,便于确定执行上链数据的用户。
四、用户的自我数据保管
传统的互联网产品,用户数据由平台中心化保管,这导致了用户隐私、数据安全等问题,且用户自己产生的数据没有为用户创造出价值。
而在区块链产品中,为改变这一情况,需要允许用户导出自己的数据。有一个原则是,用户导出的数据,需要能不依赖于任何中心化的验证平台,独立在区块链上验证该数据是否存在,这就要求导出的文件中必须包含所有数据验证所需的字段,如数据原文、Hash算法等,这些数据通常以json文件的形式存。
同时,考虑到json文件的可读性较差,导出的数据还可以包含易读的明文数据(比如用户的原始数据文件,如图片或文档)。通常会将这些导出的数据打包为一个压缩包供用户下载。另外,为提升用户体验,压缩包中还可以带有使用说明,以说明压缩包中各文件的作用,及数据验证方法。
五、数据删除和编辑
在传统的互联网产品和软件产品中,一般都允许用户删除和编辑自己的数据。但对于区块链产品,如果仅对数据库进行操作,而不在区块链上采取对应措施,会导致已删除或编辑前的数据存在于区块链上,且能够通过存在性证明,进而产生安全隐患等。
一般来说,对于删除的数据,需要重新在区块链上发起一笔交易,除带有该数据的Hash等常规信息外,还需要额外带有数据撤销标识。在数据验证时,如果待验证的数据所在交易中,存在撤销标识,则意味着这条数据已被删除,验证将无法通过。
对于编辑的数据,相当于在区块链上发起两笔交易,一笔交易用于撤销编辑前的数据,另一笔交易用于将编辑后的数据上链。
一般来说,用户自身不具备通过区块链验证数据是否存在且未被篡改的能力,而是需要通过中心化的平台提供的验证能力进行验证,这里就涉及到平台需要验证哪些内容。
下面列举一些较为通用的验证项(不代表先后顺序),可根据实际需要选取:
- 获取待验证数据中,代表该数据所在交易的标识,并使用该标识获取区块链上的相应交易详情;
- 从交易详情中获取签发交易的用户的ID,并使用用户ID和交易标识检查该交易是否已被撤销;
- 验证数据相关的智能合约是否未被篡改;
- 从交易详情中获取签发该条数据的用户的公钥地址,并在用户管理智能合约(参见第四节)中,检查该公钥地址是否存在且是否未过期;
- 检查待验证数据的格式是否符合平台规范;
- 检查待验证数据的哈希值是否与区块链上的交易详情中记录的哈希值一致。
本文由@Nik 原创发布于人人都是产品经理,未经许可,禁止转载
题图来自Unsplash, 基于CC0协议









泛融科技的可信存储系统可以存原文
博主正对第三点,我有个小问题,私钥丢失的解决办法中,是如何避免被恶意重新关联新公钥地址的?
一方面重新获取私钥需要用户进行身份证明,这本身就产生了一定的成本,另一方面可以对短时间内多次重新获取私钥的用户进行时间限制、转人工审核等