
 起点课堂会员权益
起点课堂会员权益怎样用数据分析方法应用KANO模型?
本文从数据分析的角度,重新解读如何应用kano模型。

一、 kano模型简介
KANO 模型是东京理工大学教授狩野纪昭(Noriaki Kano)发明的对用户需求分类和优先排序的工具,以分析用户需求对用户满意度的影响为基础,体现了产品性能和用户满意度之间的非线性关系。KANO模型将需求分为五种类型,下图展示了不同类型的需求对用户满意度的影响。
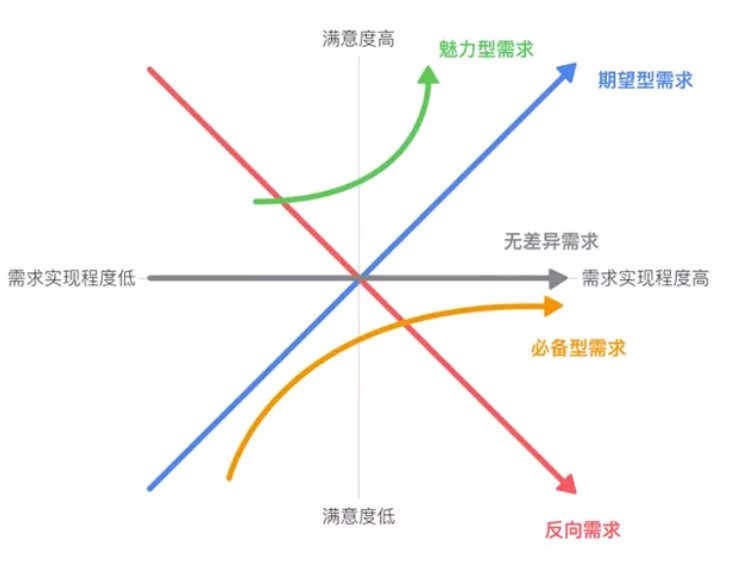
图中的横坐标代表一个需求的实现程度高低,越往右越高。纵坐标代表用户的满意度,越往上越高。
这里的满意度从低到高就是从不满意一直到满意,在中间是没有不满意和没有满意的中间状态,也就是用户觉得理所当然的状态。
图上标出了五种不同类型的需求实现带来的用户满意度变化,分别是必备型需求、期望型需求、魅力型需求、无差异需求和反向需求。
这五类需求,简单地说就是:必备型需求关心能不能用,期望型需求关心好不好用,魅力型需求关心是否惊艳,无差别需求用户根本不关心,反向需求关心的是这功能什么时候撤掉。
二、 如何确定一个需求属于哪种类型?
KANO模型的应用目前最常见的是问卷调查法。
通过问卷分别询问用户,如果提供某功能时用户的感受,以及不提供某功能时用户的感受。用户答案和功能的分类对应如下表。
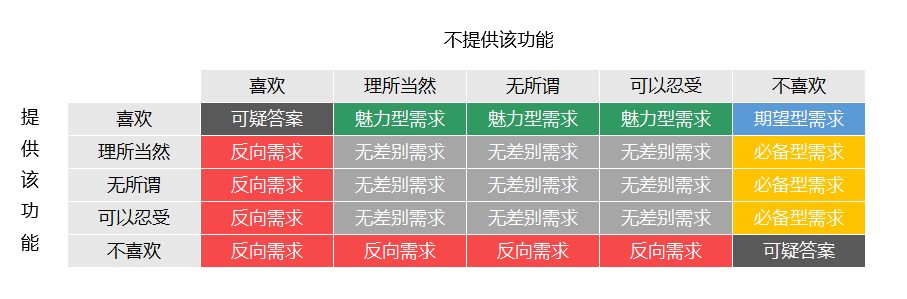
根据最终用户的反馈比例,选出分数最高的一类,确定其需求类型。这里面的计算方法比较复杂,不是本文的重点,有兴趣的同学自己百度。
通过问卷调查的方式进行需求分析有一个很大的缺点,问卷类型的数据容易出现“幸存者偏差”的情况,即反馈的用户本身就有较强的反馈意愿,无法体现全体用户的真实情况。
不光如此,用户在回答问卷的过程中,得到的结果也并非可靠。
说个案例:在过去,电视台统计收视率是通过日记调查法。所谓日记调查法,简单地说就是在被抽中的样本中留一本日记,可以是一张纸,卡片或者小册子。请样本家庭中的每一户成员及时填写一周自己收看电视的情况,内容包括观众姓名,收看的频道,收看的时间等等。然后每周反馈给调查人员。
随着科技的发展,机顶盒大规模地应用,调查人员可以直接通过机顶盒的数据获取用户收看电视的情况。调查人员发现,那些黄金时段的节目、知名度较高的节目,日记法的数据相比更精准的机顶盒的数据要高得多。
出现这种情况的原因是因为人们在回忆自己看过的电视节目时,往往会放大那些名气更大的节目的收看时间。因此问卷法得到的信息往往是不准确的,而真实的用户行为数据却不会说谎。
所以用数据来反应用户的行为将会更为准确,我们完全可以尝试通过用户行为数据进行kano模型的分析。
三、 利用数据应用KANO模型
由于大部分产品提升用户产品的满意度的目的主要是为了提升用户的粘性,表现在数据上就是产品的留存率提高。如果一个功能用户感到更加满意,那么这款功能的留存率必然会上升,或者当天的人均点次数上升。总之,用户会更有意愿使用该产品。
那么根据页面的数据信息,我们可以大概推测出该功能目前所处的满意度水平,从而确定后续调整的优先顺序。这种方式相比问卷法最大的优势是信息的来源真实地反映了用户的实际反映,而不是被用户的情感因素加工过的二手信息。
不过通过数据的方式进行KANO模型的思考也有不足之处,即数据只能分析当前存在的功能用户是不是爱用,而不能发现用户目前并不存在的需求。
如果该产品连基本的必备型需求都没有满足,那么在产品页面上没有用户的需求点,数据也就无法找出用户究竟需要什么样的需求。当然,我们可以通过其他功能的使用数据去发现用户的需求,不过这种情况下需要用产品思维去揣摩用户心理,有一定猜测的成分,数据不是决定因素。
另外数据也很难预测出魅力型需求。
还是以iPhone为例,如果当时的诺基亚有用户的数据分析,那么数据必然可以得出用户有更大屏幕,更便捷交互的需求。但是这种方向如果没有配合上产品经理的创意,最终诞生的可能也只是更大屏的带触控笔的塞班机而已,这依然在用户的预期范围之内,最多只能算期望型需求。
要想成为魅力型需求,需要数据提供方向 + 产品提供创意。在用户意想不到的方向解决用户需求才能成为魅力型需求。
这样的表述有些理论,我们看几个例子。我们首先看一下现状分析的情况。
例子一:某产品或功能的留存率非常低(多少算低,每个产品有不一样的标准),那么这个功能很可能处在下图中的蓝色框线位置。
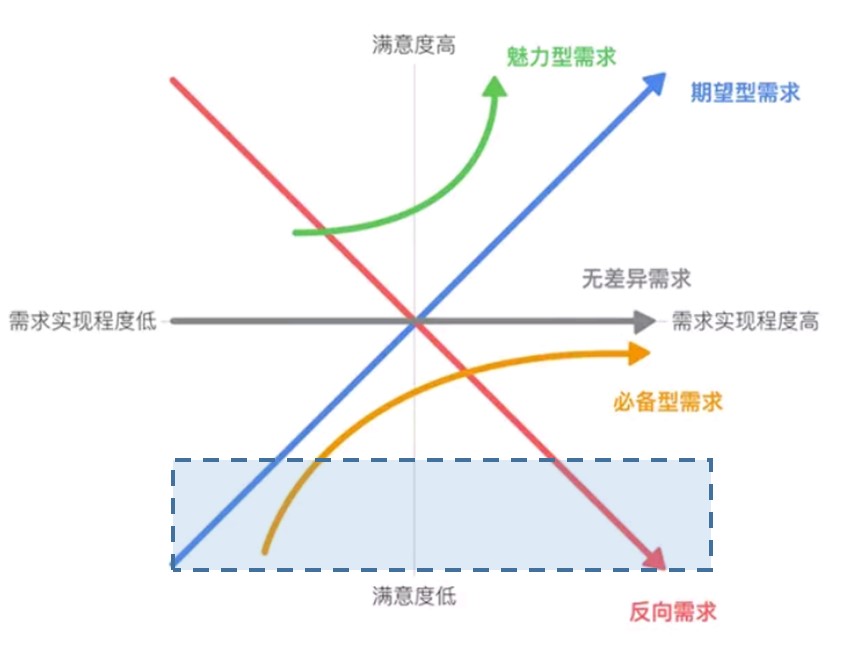
此时用户的状态是不满意,结合kano模型进行分析,必备型需求只要基本满足即可以大幅提升满意度,那么很有可能是该产品的必备型需求的方向是错误的,用户根本没有这样的需求。
在找到用户的必备型需求之前,不管是调整当前页面的排版,还是增加相同类型的信息等都无法从本质上提升用户的满意度。因此这时页面改版最优先的方向是找到用户的真实需求。只有找到了用户的真实需求,那么改动带来的效益就是指数型增长的。
面对这样的产品状况,数据分析是很难帮助产品经理找到用户的真实需求的方向的。因为前面提到过数据分析的优势在于找到当前页面上用户感兴趣的功能,当前页面如果没有满足用户的需求,数据也无法告诉我们用户到底要什么。这时候就需要复盘产品经理当时上线该产品时的用户需求分析,找到问题所在。
再比如:
例子2:某产品或功能的留存率较好,那么这个功能很可能处在下图的蓝色框线位置。
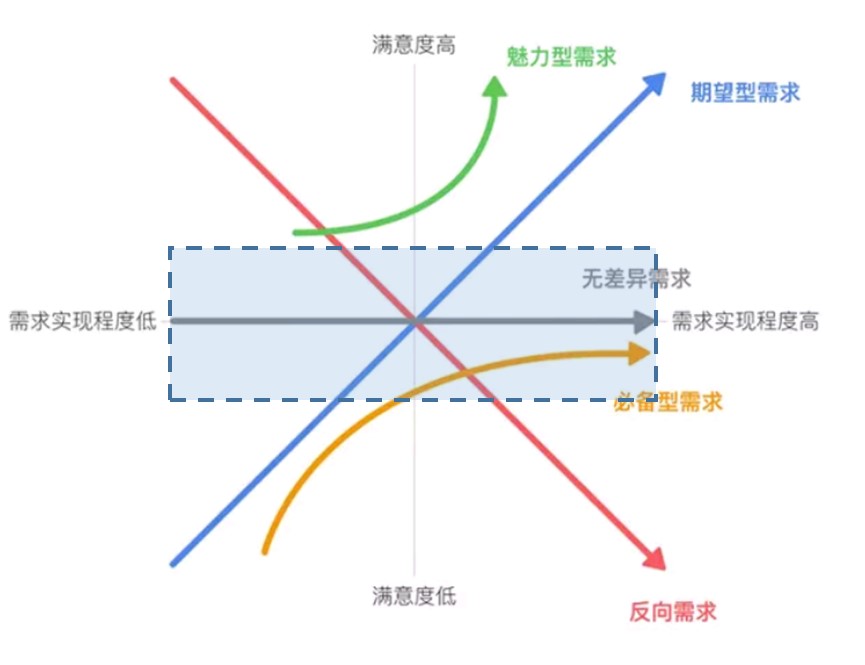
在这个位置上,用户的必备需求基本得到了满足,再增加必备型需求的意义不大,我们需要找到期望型需求。
我前面提到过,期望型需求是必备型需求的升级版,那么找到用户最感兴趣的必备型需求,然后给出优化的方向就是该必备型需求的升级方向。
这个区域可以说是数据分析的舒适区,这类产品的数据不仅可以反映出大部分的问题,并且还能给出进一步的方向。
当留存率继续向上升时,产品已经相当成熟,用户达到了“满意”的状态,接下去可以开始尝试一些魅力型需求,这类需求无法从数据中得出,只能通过产品经理的创意进行试验,上线后再进行数据验证。
可以看出,KANO方法告诉我们数据分析在产品分析中的适用范围,在产品未找到用户的必备需求之前,数据分析是不太容易帮助产品提升满意度的。只有在产品找到用户明确的需求后,数据才能协助产品对产品进行优化。而在产品已经非常成熟时,数据也是很难找到突破口的。
数据最佳的发挥空间是把产品从四五十分提高到八九十分。太高或太低分数的产品,更多地需要创造性的产品思维。
本文由 @Jason 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自 Pexels ,基于 CC0 协议









“如果当时的诺基亚有用户的数据分析,那么数据必然可以得出用户有更大屏幕,更便捷交互的需求。”这句话怎么理解,洛基亚如何能分析出用户需要更大屏幕这种无理介质层面的需求?
是笔误还是我理解错了,有一段说到“日记法的数据相比更精准的机顶盒的数据要高得多“,在下一段又说“此问卷法得到的信息往往是不准确的,而真实的用户行为数据却不会说谎。“,是机顶盒准确吧
哈哈哈哈,太高和太低的分数都需要创造力。。。认同。100道选择题,巧妙地绕过正确答案,也是靠实力。
你好,标明出处可以转载吗?
可以
写的真好,收获良多,感谢~
你好,请问这篇文章可以转载吗?
请标明出处,微信公众号“三元方差”
好文章