
 起点课堂会员权益
起点课堂会员权益数据分析实战|人人都是产品经理网站(上篇):平台视角
干货满满的上篇,不仅仅是一篇数据分析,相信你将对人人都是产品经理的网站和发展会有新认识,欢迎指导交流~
起因
看了几年的人人都是产品经理(以下本文中简称人人),从来只是个看客和学习者。最近因为比较闲,也在总结这几年来的工作心得。近一个月前终于有了第一次投稿,如何通过小程序和微信社群来构建产品运营体系?上过人人的微信头条,每天都能有几个新的订阅用户,这些都在告诉在我这一点付出还是能够帮助到其他人的。
但我一直很好奇它具体在人人的过往文章中到底是个什么水平,我心里没有底。所以出于好奇,就有了这次数据分析的探索之旅。
内容安排
学过数据分析的同学肯定在最开始都有这样的体会,手中有了锤子,看什么都像钉子。所以好久没做数据分析,手痒一下子抓取并分析了一大堆数据,远远超过了最初的目的。
所以开始构思如何写这篇文章的时候,做了如下思考:
- 人人是由哪些角色构成?
- 这些角色都想知道些什么?
- 能否通过现有的数据给出这些答案?
综合考虑以上问题和文章篇幅后,大致拟出如下图所示框架:
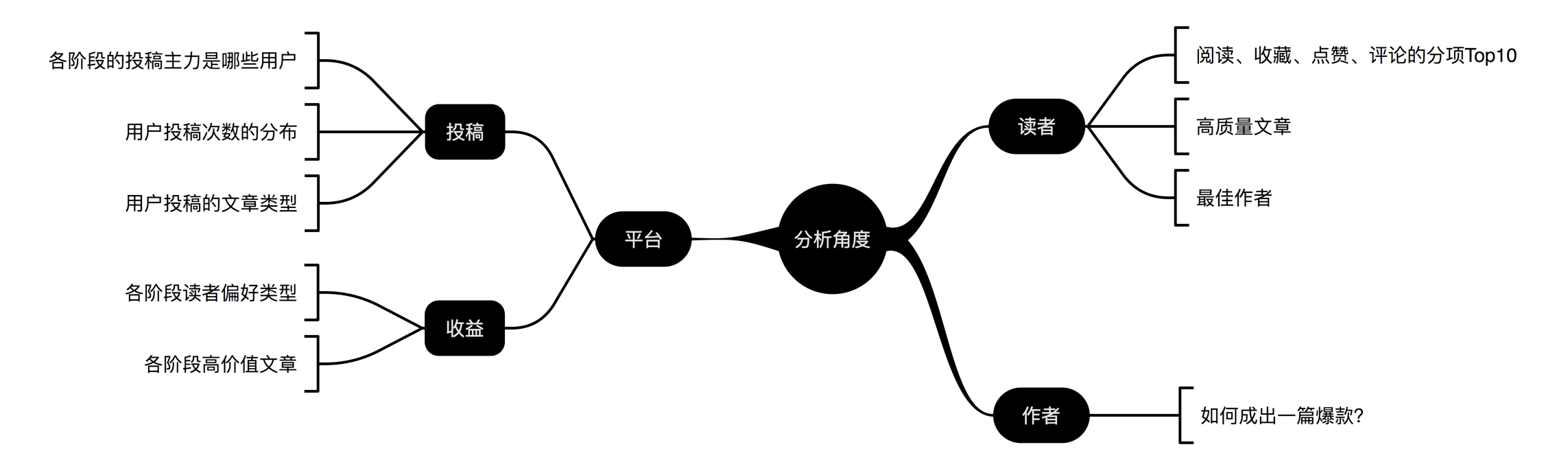
- 左边为人人官方平台角度,换位思考,如果我是运营,首先会比较关系平台的内容循环体系是否正常,其次内容是否带来足够的收益;
- 右边为用户角度,就是普通的网站访问者,同时根据身份又分为读者和作者,读者想的是能够找到自己想要的内容,作者是想的是自己的作品是否受到大家的关注;
这是两个角度,三种角色的基本思考,而本篇则会由左边开始,下篇会讲右边。
数据介绍
1. 开发环境
基本的数据分析工具就如下图所示:

2. 数据获取
因为不是写教程,而且过程也很简单,这里只是简单的提一下。使用Python写一个For循环请求网站的一个分页加载接口,就能够获得所有的网站文章数据(Json格式),再将所有的Json数据合并整理成相应的列表。
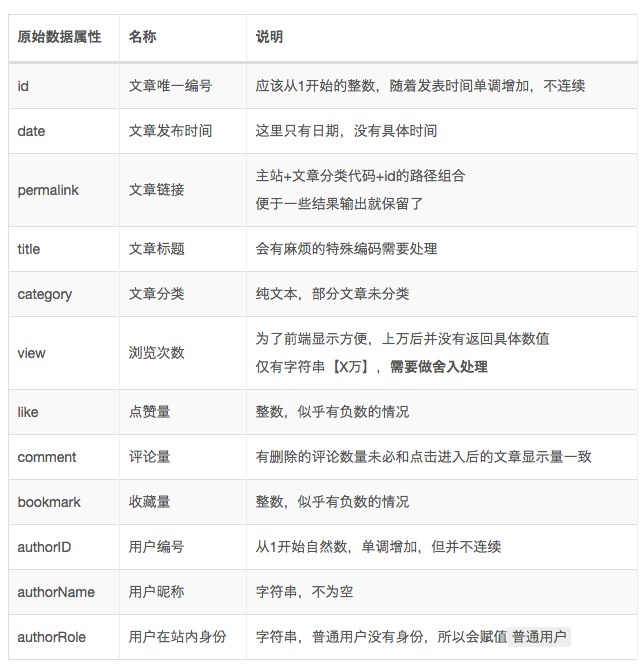
其中接口返回的原始数据项比较丰富,选取其中比较有价值和便于分析的,如下表示:
3. 数据总览
在获得数据后,第一时间就先看看整体的数据情况。时间有限就不去做些漂亮可视画展示啦,总览数据就如下表所示:
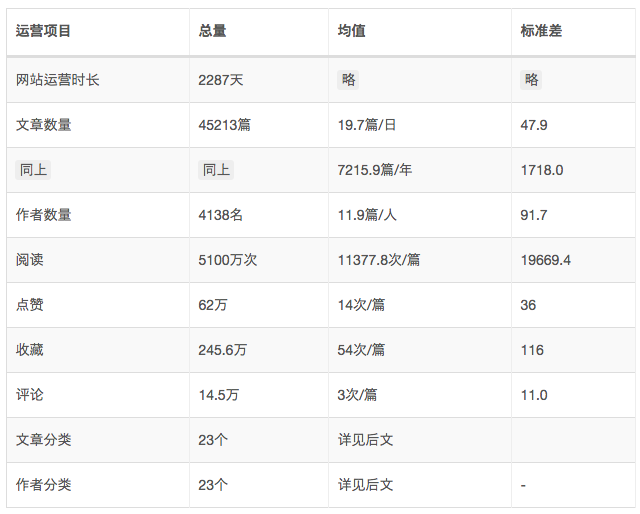
只看以上数据,我上一篇的数据无论是5K的阅读量还是收藏点赞都还没有达到平均值,离好文章都还有一些距离,这组数据能解决我的基本困惑。但对于整体的运营情况和前文提出的一些分析目标来说还远远不够,所以还需要后文的深入分析。
4. 正式开始分析前对数据的一点说明
- 数据仅采集自首页文章列表展示数据,仅用于学习和投稿人人的写作,不做何商业用途。
- 本文数据采集自2018年8月16号,一切记录数据以当天为准。
- 文章数据并不能保证严格正确和全面,比如:9月2号再次采集时,文章数量比8月16号的还少,应该是下架了一些文章,但对于本次分析人人的网站大体情况应该是没有问题的。
- 为了不给人人主站造成不必要的网络负担,如果有需要原始数据的同学可以在后面留言邮箱,或者在我的个人网站中寻找。
了解以上,让我们正式开始。
平台运营浅析
初步分析人人主站的主要业务逻辑如下图所示。
- 由作者发表文章
- 吸引用户产生流量
- 部分读者会转化成作者、生产独家内容,以此来构成一个能够长期、稳定的内容发布体系。在此之后的,通过流量发布广告,读者带来的口碑换取第三方合作、课程转化等,都是在这之上的业务逻辑,分支太多,不可能面面俱到,所以点到即止。
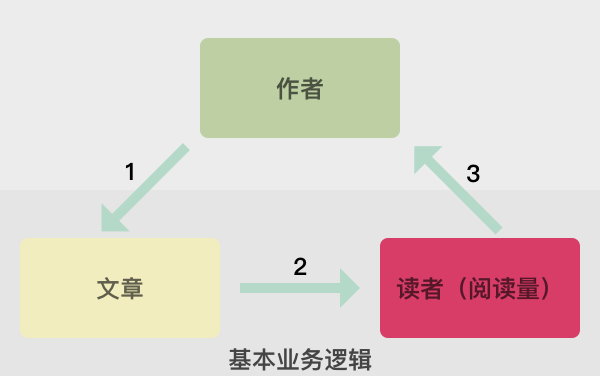
再根据实际的数据情况,并没有直接的读者UV数据,所以仅对以下两条业务线进行分析:
- 业务线1:多少作者产生了多少投稿;
- 业务线2:投稿的文章带来了多少阅读量进行分析。
投稿来源
相信大家在看数据总览中能看到,投稿作者的身份多达23种,依次是:站长、运营小编、官方、专栏作家、运营小哥、运营小妹、普通用户、设计小妹、运营、合作媒体、编辑、作者、萌妹子、主编、女神、男神2、临时工、特邀作者、运营哥、美少女、CV工程师、合作出版社、小编妹妹。
是不是眼花缭乱,群魔乱舞?
这里我根据后面的实际情况对相应的身份进行了些合并。
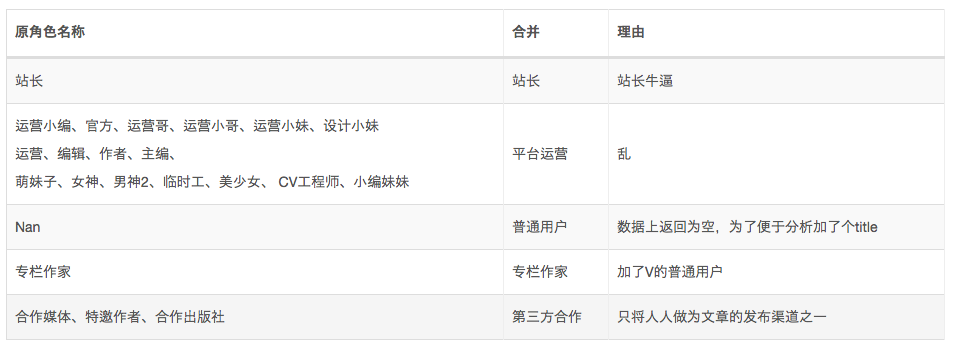
所以这里需要吐槽和需要改进的自然就是平台运营小编们对自己的角色定位了,只从命名上看得出来应该是后台的管理有些混乱,最初来一个新人就想当然的给了自己一个title。或者说人人当初有自己的培养明细写手的打算,所以预留了一些特殊的职位和身份?
Q1. 各阶段的投稿主力是谁?
OK,吐槽完作者身份后,进入到第一个问题。那就是人人上面的文章都是从哪儿来的,或者说是谁投的稿?
在对作者身份进行合并后,如下图所示的是2012~2018年,投稿数量分布热力图:
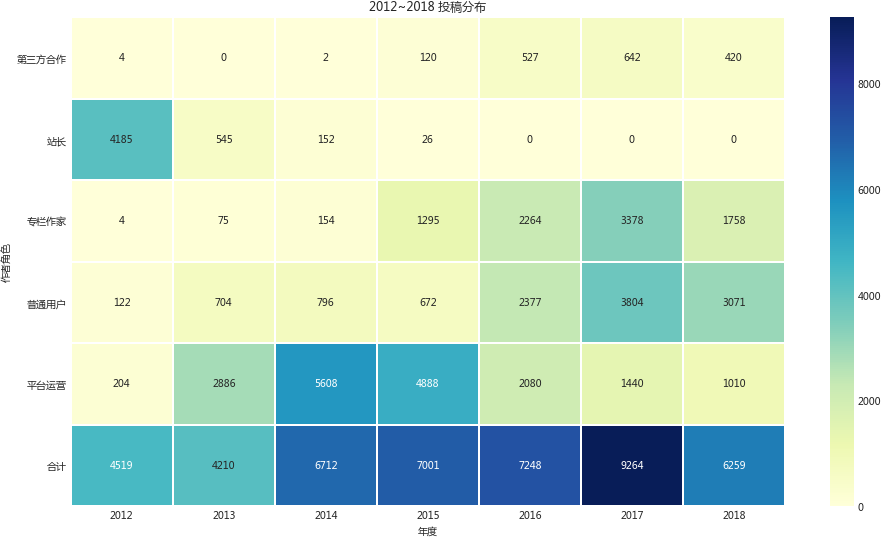
这里不仅对各时期的投稿主力看得很清楚,甚至可以清晰看到人人的主业务搭建过程:
- 最初是由站长在2012年完成了大量的投稿(转载),构建了网站的基本内容(可能是有一些网站的改版,因为人人实际从2010年就开始运营了);
- 在2013年开始,大量团队成员的加入后,转为团队运营的方式,而站长由此开始退居隐退,并且在网站上投稿的用户明显增多;
- 之后一年团队应该过得挺辛苦的,平均每天团队成员需要投稿15.3篇,只算工作日251天的话,大约27篇,虽然不知道团队成员多少,但至少在2014.11月拿到融资之前团队成员应该不会太多。即便转载,也会有相当的二次编辑工作量;
- 2015年大约是通过对普通作者的发掘,将部分投稿用户转为了专栏作家,激发了用户的投稿积极性,使专栏作家的投稿量有了质的飞跃。当然,这里有个问题可能在于用户在最初投稿时为普通用户,但在之后转为专栏作者,将部分原应该归到普通作者的数据分到了专栏作家中;
- 之后的两年就相当平衡了,更多的普通用户投稿说明对平台的品牌认可,且源源不断的提供更多的专栏作者,以维持稳定的内容输出。
整体来看,之前说的主业务体系目前应该是比较稳定且完整的。2018年的数据目前还不好说,但专栏作家的流失的趋势有点明显,可能需要一些激励计划。
Q2. 用户的投稿次数分布
从内容生产的角度来说,普通用户和专栏作家投稿属于UGC内容,平台运营内容属于PGC内容。PGC内容可以根据团队运营的情况来调整,而UGC内容则需要通过适当的激励手段来保持。
而且之前在数据总览中能看到这样一组数据:
- 作者总数4138名;
- 人均投递11.9篇/人;
- 投递偏差值为91.7。
如此大的偏差值,能够多次投稿的用户数量并不多,而实际的情况也如下图所示(仅普通用户和专栏作家):
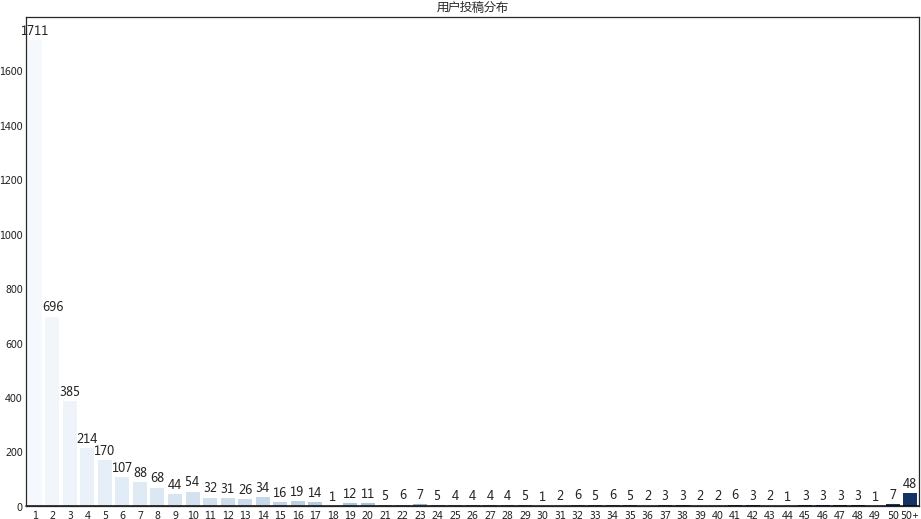
那么在普通的吃瓜群从中,加了V的专栏作家是否真的有做出比普通用户更多的投稿呢?
为了接下来的分析和数据展示,将对用户的投稿数量做了出以下分组:

再加上投稿作者的身份,结果如下图所示:
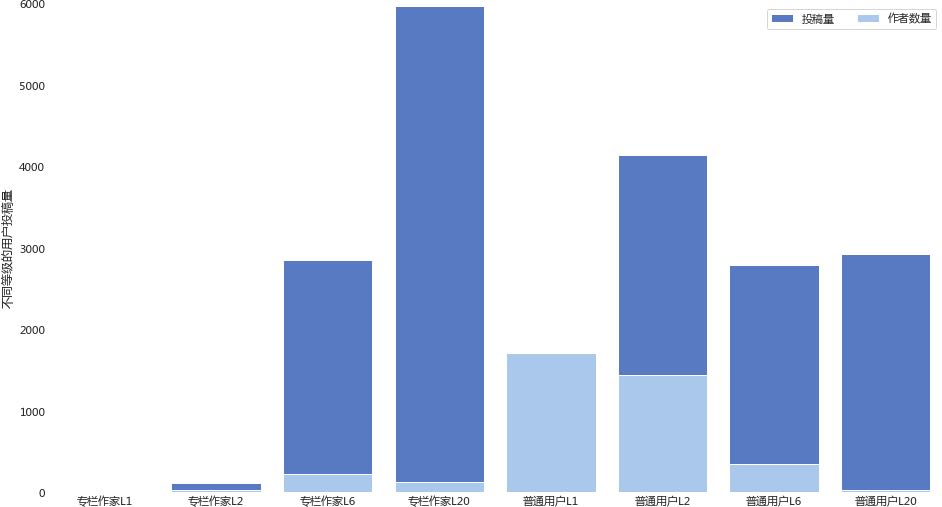
- 绝大部分的的专栏作家完成了至少5篇以上的投稿,且L20的专家用户完成了相当的投稿量;
- 从普通用户L20中可以看到人人确实把相当一部分用户转成了专栏作家,而且通过具体数据查看,此类剩余未转化的用户大部分只是转载;
- 普通用户L2到L6之间有道坎,这个我现在自己写作也深有体会,对于用户来说一时兴起写一两篇没有问题,但难的是如何坚持;
- 从此数据中无法直接得出普通作者转成专栏作家后,能够持续投稿,缺乏用户身份转变的时间,故不再做进一步分析。
虽然有些不完美,但确实是20%的用户解决了80%的问题。
Q3. 用户的投稿偏好
最后我们来看一看用户喜欢投哪些类型的稿件,普通用户的投稿一般是兴趣始然,或者是来自自己的工作内容的总结、经验分享。所以这个分析将将可能得出产品经理们的能力变化和工作变化。
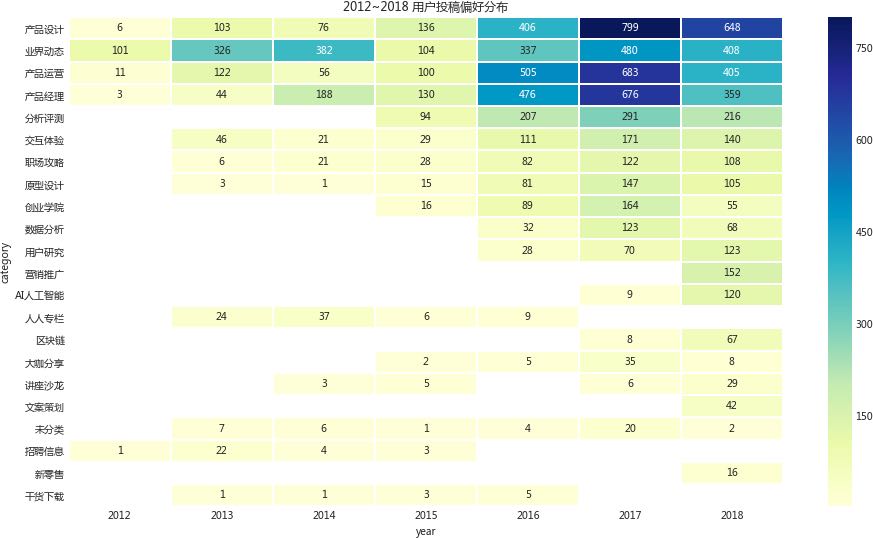
从左往右按年份来看:
- 2012~2015可能还是产品经理在行业内刚开始冒头的时候,所以产品经理的主要工作:产品设计、产品运营、产品经理大家都还不太敢写,或者说能写的人还很少,主要就是分析行业和转载报道当前的行业趋势;
- 2016开始才品类丰富起来,应该算是产品经理行业开始变得成熟的一个分界点,在这之后,产品设计、产品运营、产品经理的投稿才变得丰富起来,毕竟有经验的开始多了起来;
- 营销推广、文案策划、新零售、AI人工智能直到今年才有投稿,应该是最初没有分类造成的,也应该是相应的内容开始集中出现的结果。
不过这个分类是人人运营自己做的,很明显还是有些问题。分类来得有些晚,至少热点已经过了,或者因为没有分类可以选就在一些大项里凑合一下,将会造成文章索引困难,值得优化一下。
内容收益
网站上有了内容,那就需要看看这些内容所能够带来的收益。与很多实时类的新闻不同点在于,人人是个比较专业又垂直的网站,里面的内容是会沉淀的,即使是几年前的文章也会被用户找出来进行查阅,而且有相当多的引导和内容聚合,可以将新用户直接导入到有价值的老文章上来。
所以需要注意,在接下来的文章收益里的几个数据:阅读、点赞、收藏和评论都是一个累积量,不能当做PV和UV来进行参考。
Q4. 各时期的文章对用户吸引力
有了之前对数据的说明和理解,这里将要计算的是各时间点下,不同分类的文章对阅读量的收益是如何分布的。对于网站来说,历史内容也是可以增加点击量的,而不时间的最终阅读量均值。
如下图所示:
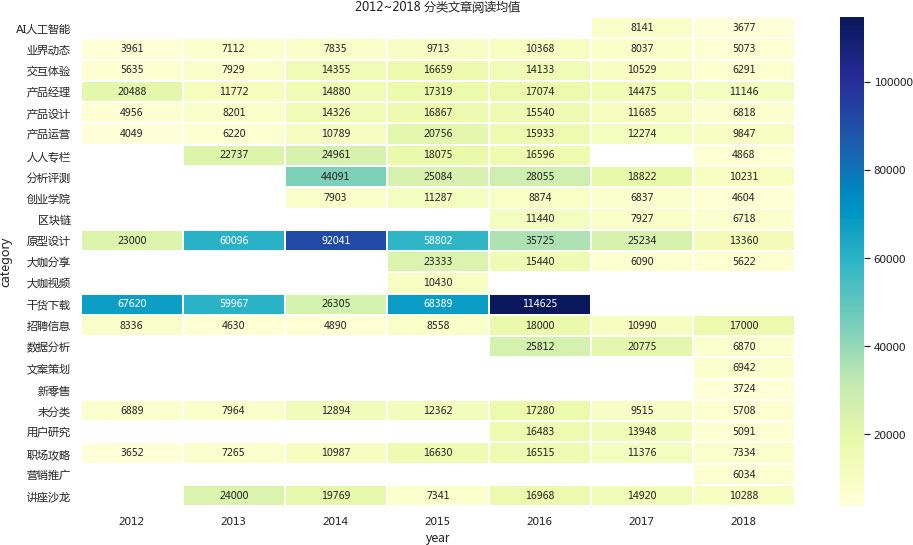
(1)2018年,除了招聘信息,所有类型的文章的阅读量都比之前低,有以下几种可能:
- 有经验的产品经理越来越多,所以大家挑着看;
- 产品经理的人数和热度在减少;
- 产品经理的岗位也在也在减少;
- 优质的内容不如之前的多,所以新用户会导入到老文章上来,新文章反而快速的沉没;
具体是哪种,可能还需要直接从管理后台查看日活,月活比较说明问题。
(2)对于平台来说,只要能吸引到用户和点击量就是好内容,从上图中显而易见的:干货下载和原型设计这两个入门级的分类文章始终是最能吸引用户点击的,这种历史内容实际只能通过搜索来反馈,可以更突出一点。
(3)AI人工智能,区块链这些新技术的阅读量都出现了大量的下滑,说明大家对这些新领域并不看好。而还有很多新的发展趋势却没有体现出来,有点可惜,这一点之前已经提过了。
Q5. 各时期的投稿质量如何
刚刚Q4的分析中,仅是从阅读量均值来查看。但有经验的同学肯定知道,很多标题党也可以直接收获不错的点击。所以接下来这里我们需要更严格一点,将阅读、点赞、收藏、评论都放在一起进行考量。
这里再具体看一下相关的统计数据:
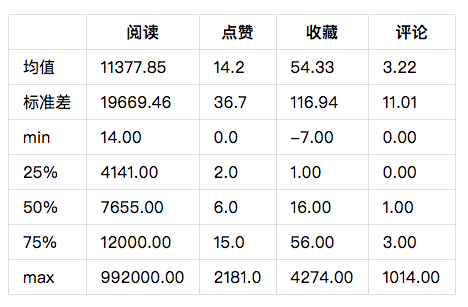
数值上的差距还是相当大,所以这里我们为了统计和展示方便,做了以下数据处理:
- 将四项属性按低于25%的值评定为Low,高于75%的评定为High,其余为Mid进行分组。反过来说,如果一篇文章的某一项属性评定为High,意味着它的这一项属性是超过75%的文章的。
- 然后逐月计算将相应月份里,分别计算四个属性中为High的比例,比如:2017年1月份投稿100篇,得出有20篇阅读量为High,10篇点赞量为High,那么只记录相应的高阅读和高点赞比例分别为0.2和0.1。
结果如下图所示:其中四条线是取值为[0,1]之间的比例,为了不与下方的投稿量过于干扰进行了放大处理,下面的bars则是当月的投稿数量。需要解释一下的是,因为高质量的文章并没有统一标准,所以这里并没有对数据进行合并,而采取的是人工观察和感性分析。
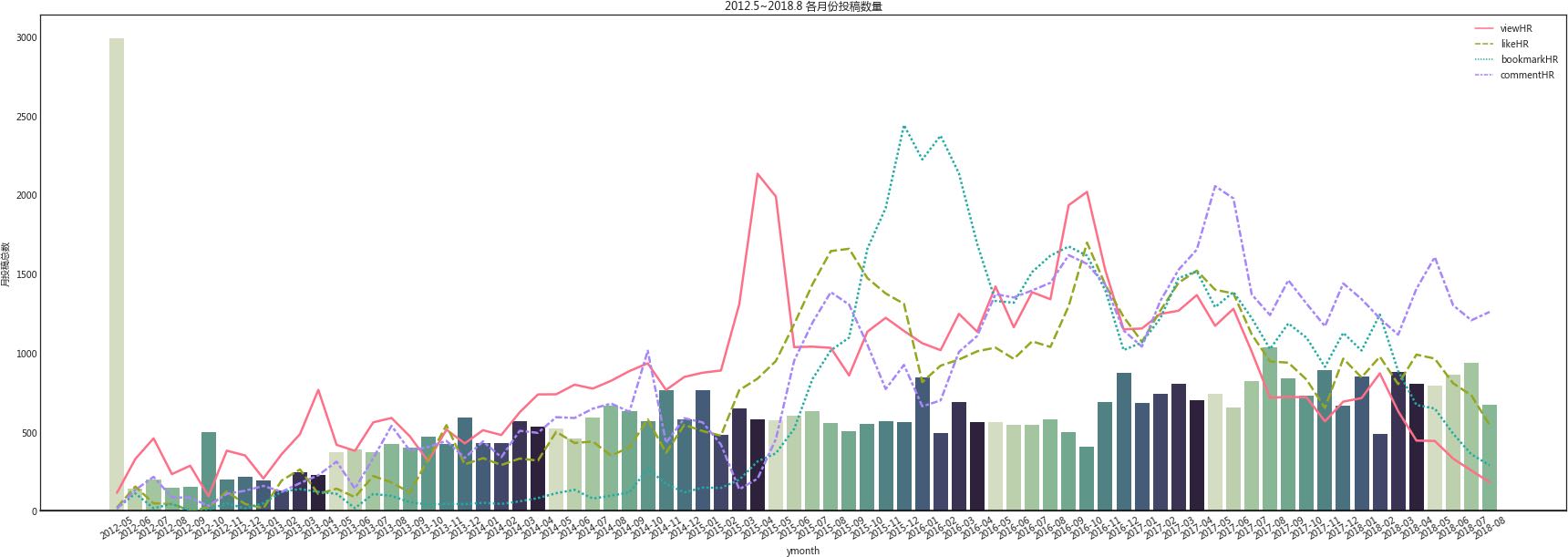
最左边的一条并不是数据出错了,而是早期站长批量导入,然后之前一直没提的就是整体投稿量一直呈现上升趋势。
高阅读量却没有相应的点赞和收藏,所以这里从2015年3月和4月取几个标题,大家感受一下:
- 从汪涵救场看产品经理的危机处理
- 滴滴拉屎App,估值100亿美金!
- 快滴拉屎PK滴滴拉屎,拉屎App的爱恨情仇
- 在网易实习是种什么体验?
2016年1~3月则是有大量读者需要的部分,大致逻辑为首页或者近期没有用户需要的,特别是新入门的产品经理,会比较急于想要找到自己想要的,所以会使用到搜索功能,然后小白的大量相似需求会推高相应的结果,而且为了之后的阅读查找,优先点击收藏。
2016年10月的投稿量不多,但似乎文章质量普遍很好,如果是取四个值的均值来看也是全期最高的。之后新文章的数据会受到时间的影响,但整体文章质量趋于稳定,高阅读量的文章会带来高赞和收藏,而新读者从评论的角度上来说更活跃一些。
Q6. 作者带来的收益
根据之前的两条业务线的分析:首先由作者与投稿,其次是投稿与收益之间还能建立一条分析,最后就是作者与收益。
这里限于篇幅就只做一下整体的统计,来查看核心业务逻辑是否稳定,与之前图上的单位不同的是,下方的热力图的单位是万。
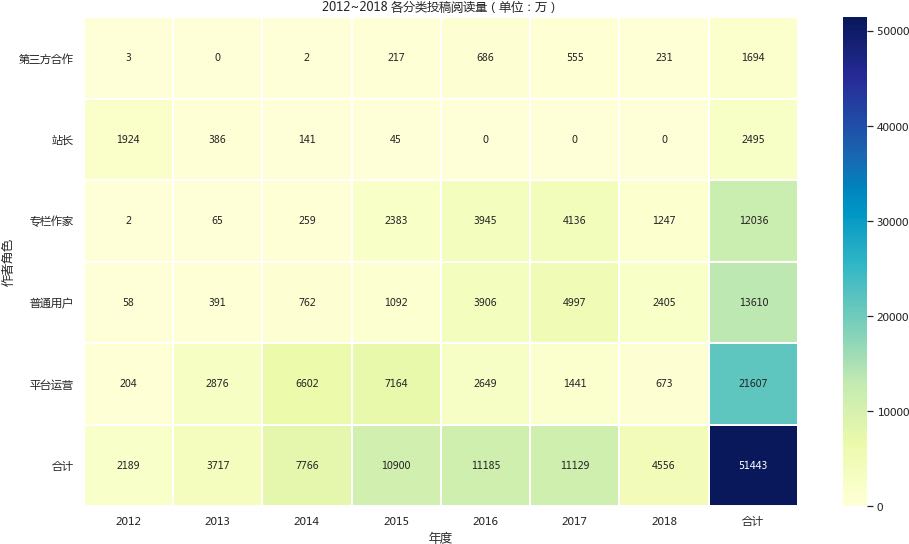
首先,可以看到,到现在2018年的时候,UGC内容带来的用户点击已经远远超过PGC内容,而且历年所有的UGC内容也已经超过PGC内容,这对内容生产的稳定发展有了基础。
其次,虽然此页面上的内容并不能直接代表网站流量,但根据2016~2018年的整体数据,可以给出以下两种解释:
- 2018年,相比于用户水平的普遍上升,文章质量是相对下降了。或者是大家想看的内容都已经在之前都写完了。但如果结合Q4表中的业务动态也下降了,这种每个人都可能看一看的情况来说,可能性不大;
- 2018年用户访问量下降,根据我自己一篇的投稿经验,文章发出去之后七天内阅读量的增长就会衰减至一个极小值。所以这里我假定得更严格一点,目前的新文章在发表30天之后就不会增长。 我之后的一些筛选和统计也是选择超过30天的文章来进行评判,这里可以初步得出如此解释。
总结
结论
- 结论1:最初假设的人人内容体系是存在且正常运行的,而且带流量的主体已经由平台运营方在向用户内容生产的方向转化;
- 结论2:如果只看今年的数据来说,文章的质量对比往年在下降,对读者的吸引力也在下降;
- 结论3:产品经理没有过去两年那么热门了,平台可能需要寻找一些新的业务和内容进行填充。
建议
- 文章编辑推荐:首先这是对投稿用户最直接的反馈和正面鼓励,其次被编辑推荐的文章可以让读者过滤掉大量标题党内容,提升内容品质。现在经常在首页翻了一圈并没有什么好内容,所谓的热门推荐,有些比较慢热,内容比较长容易扫一眼就直接关掉了,这个时候需要有编辑帮助引导一下;
- 用户投稿等级:可以看到用户的投稿数量和质量还是有很大的差距的,应该还是需要更复杂一点的体系和等级,而不仅仅只有一个title。另外成为专栏作者后,完成投稿目标是否有什么奖励呢?
- 文章可以打标签:就目前来看,这个文章分类是不够细致的,而且文章分类开得会比较不及时。比较好的流程是,作者在上传时可以自己选择多个文章标签,管理员再可以根据某一些标签快速的增长再将期转为分类。这样不仅对新趋势能够有所把握,而且之后建立索引也会更方便。
下篇预告
以上便是本次分析的上半场,那么在之后将会是读者篇和作者篇,请大家敬请期待。
如果有数据分析大神希望可以给一些指点和建议,非常感谢。
相关阅读
本文由 @ 核桃壳 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自 Pixabay,基于 CC0 协议









平台运营的文章是不是OGC啊?
好棒啊!话说,这里的数据应该如何获取呀,好想自己也学学数据分析的
可以向您要一下原始数据嘛^_^?xzhpsp@126.com
文章数量的标准差怎么比文章数量的均值要大那么多?难道有负数吗
并没有,是在做数据处理的时候没有把建站时候的大量文章导入所产生的异常祛除。
小白想问..做数据分析的时候都得自己写代码去爬数据吗?
这个看情况和公司,公司大了会有自己的数据分析部门
所以,是数据分析部门做数据分析,都得自己写代码去爬数据?
数据分析部门负责抓取数据 处理数据 分析数据和运营动作由业务部门来 不懂你的逻辑怎么来的
本系列的相关代码可以在http://walnut-shell.com/ipython-notebook/ 中找到
请问下如何系统的学习数据分析,看了Udacity和网易上的数据分析课程,感觉都不是很系统,求指教~
我很想知道怎么用Python的for获得数据,求大神教导,以及for程序在哪里可以找开源代码
哦,这个只是说获取数据是个简单的网络请求接口,编程中使用轮询的方法就可以获取到所有的数据。
这两天刚把人人的文章数据爬下来准备做分析,就看到了你这篇,瞬间觉得不想玩了 ➡
还请多指教,未必全面
羡慕有锤子的技术帝^O^
拜读了,期待下篇(๑•̀ㅂ•́)و✧