
 起点课堂会员权益
起点课堂会员权益在做用户研究时,大数据+小数据=?
在大数据时代,大数据能够描绘出所有用户的清晰轮廓,但是小数据依然有着自己的优势。那么,在调研时能将两者结合起来,会产生怎样的效果呢?

在崇尚大数据的时代,调研所代表的小数据研究似乎正被逐渐替代,曾经拿着用户调研报告以为洞悉了一切的人们,慢慢认识到用户所答并非所想,而少数用户的声音也很容易引出错误的方向。
幸好有了大数据,让我们的视野更宽广,我们构想着一切可能,希望能用大数据描绘出所有用户的清晰轮廓,那么事实又是怎样?传统调研真的一无是处了么?如果能将大数据和调研结合起来,又能碰撞出怎样的火花?
大数据真的无所不能吗?
1. 大数据所向披靡
千人千面、个性化推荐、用户行为偏好、用户生命周期跟踪、购物预测、精准广告,暂且不提大数据在其他领域的应用,仅仅就用户的研究而言,大数据可谓所向披靡,只要用户在平台上有足够多的动作,就会产生足够多的数据,这些数据碎片通过各种拼凑组合,就能描绘出用户各个维度的画像,从而能够支持到更多的应用。
以个性化推荐为例,早期的豆瓣基于协同过滤的算法,通过用户看过的电影数据,为其推荐相似的电影(商品协同过滤),或者基于用户多维度特征的相似性,为其推荐相似用户看过的其他电影(用户协同过滤)。
随着机器学习技术的成熟,数据处理能力的发展,推荐系统也在不断迭代,比如像今日头条,可以基于内容的切词、内容标签、图片及视频流编码、用户实时浏览行为等成千上万种数据项作为特征,以庞大的用户数据作为训练样本,建立超大规模的模型,从而实现更精准的推荐。
大数据的量级越来越大,似乎藏着挖不尽的宝藏,只要数据维度足够丰富,数据处理能力够强,机器学习的技术足够完善,未来大数据的应用就会更加广泛和成熟。
2. 大数据的无能为力
尤瓦尔·赫拉利在《今日简史》中预测:2050年我们将迎来数据霸权的时代,无论是医疗领域、娱乐行业还是汽车领域,到处都是人工智能的身影,算法可以预测一切,算法可以自己迭代,算法可以替代我们进行决策。
尤瓦尔·赫拉利的预测并非没有道理,人工智能在逐渐黑盒化,机器在自主学习,我们却不知道它做出决策的原因,因此当机器把一个结果摊在你面前时,你是否会本能地怀疑。
于是,我们开始纠结另一个概念,叫“可解释性”,无论是基于大数据统计,还是基于机器学习算法,我们得到的都是一个结果,就算用户行为路径,也只是用户的行为结果,通过大数据似乎无法解释用户的心理决策过程。
大数据仿佛是一个高维度的生物,机器学习是人类尝试运用其超能力的手段,站在大数据的视角来看,能解决你们的问题不就可以了。为什么还需要我来解释,就算把我的能力投射到低维空间,你们也仍然无法理解,而人们内心世界,恕我无能为力,我暂时也不能理解。
大数据擅长的是理性分析,而人类的决策过程中往往掺杂着直觉与感性,所以当涉及到用户深层的感知与动机时,大数据便显得有些捉襟见肘。目前,大数据的应对方法是通过贴标签将用户进行标识,但仅有行为标签还远远不够,如何提取出感性标签是一直困扰着大数据的难题。
用户调研真的不靠谱吗?
1. 调研的不靠谱事迹
说起调研失败的案例,最有名的要数可口可乐当年的口味测试。
20世纪70年代,受百事可乐的冲击,一直位于霸主地位的可口可乐感到了极大的威胁,于是在十多个城市展开了消费者调研,调研的目的主要是了解消费者对于口味的感知,比如“如果可口可乐口味更甜一些,你是否会喜欢”,“如果可口可乐有新口味,你是否会尝试”等等。
调研的结果一致证明,消费者愿意尝试更柔和,味道更甜的可口可乐,于是,决策层果断进行了口味更改,推出了全新的可口可乐。新口味上市前,可口可乐还进行了一轮盲测,盲测结果同样显示,消费者更喜欢新口味的可口可乐。
这一调研结果提升了决策层的信心,新口味可口可乐全面上市,广告铺天盖地而来。然而,结果却大失所望,消费者在尝试完新口味之后,不但没有继续购买,反而愤怒地向可口可乐公司寄来投诉信,声称“放弃原配方是放弃了美国精神”。
最后,可口可乐公司不得不再次恢复沿用了100年的传统配方,而这一次巨大的新品投入最终换来的却是一场乌龙。
这次调研的失败,某种程度上也是调研自身的缺陷,那就是调研只能研究一个点,而无法看到面。可口可乐一开始就研究错了方向,以致南辕北辙,因为可口可乐的消费者最关注的是品牌文化,而并非口味。
除了研究方向的误导性以外,调研还有着场景的局限性,在某个场景下调研得出的结论可能较为特殊,最终会引导出错误的决策。
比如:在20世纪末,北华饮业就曾调研过消费者对于凉茶的接受度,最终发现,60%的中国消费者不能接受凉茶。于是乎,公司脑补出消费者不能接受凉茶的各种原因,比如:中国人可能更习惯于喝热茶,或者是中国人不喝隔夜茶等等。
但事实是,当时调研的时间正好是冬天,消费者哈着气走到调研的地方,用冰冷的双手拿起凉茶一饮而尽,在这种场景下,消费者的感受自然会受到极大的影响,而这错误的研究结果最终也使得该公司错过了凉茶爆发的风口。
2. 调研无法被代替
无数的公司都掉入过调研的陷阱,但不得不承认,也有很多公司通过调研挖掘出了用户的真实需求,从而指导公司做出了正确的决策。
前面讲到,大数据只能呈现出结果,而这一结果是如何产生的不得而知。调研在用户深层特性和动机的研究上仍有着一技之长,这能很好地对大数据的结果进行补充解释。
此外,对于新生事物而言,比如:一个新产品或是新概念,没有任何历史数据可追溯,大数据也只能站在相似的周边数据上迂回前行,却无法直击要害,这个时候,调研就有了其用武之地。
传统调研虽有其局限性,但调研方法本身其实没有什么问题,最难的是如何有效地进行调研,从而绕开各种陷阱。
以下列举了几个常见的调研雷区,请务必避而远之:
- 题目具有暗示性,比如“这款产品很多人都喜欢,你喜欢吗?”
- 题目具有主观性,比如“你为什么不关注时事政治”,对于这类问题,用户可能不会回答真实的想法。
- 题目难以理解,超出用户的认知,用户可能会乱答。
- 题目太多,或是开篇的问题太难,用户会失去耐心,除非是线下调查且奖品非常丰厚。
- 只在一个地点或一个时间点进行调研,可能会重蹈北华饮业凉茶调研的覆辙。
总而言之,不管是问卷还是深访,调研的过程都要循序渐进,由浅入深,且尽量让用户回忆真实的场景,描述当时的感受,而不是直接问他。
三、大数据+小数据=?
不难发现,大数据和小数据各有所长,而且他们刚好能形成能力上的互补,如果他们合力而为,是否会像赛亚人合体一样,战斗力报表?
1. 大数据让小数据变大
大数据的优势在于数据量大,那么通过大数据可以提供大量的用户样本。不仅如此,还可以基于此次研究的目的,筛选出符合需求的用户,实现精准的用户定向。
有了大数据,再也不用担心样本量不够,回复率太低了,而且最关键的是,成本可以得到有效的压缩。
这是大数据与小数据结合的第一步,如果最终的目的是要实现大小数据协同,那么就有必要针对线上平台的用户进行调研,这样才能保证用户线上大数据和调研小数据的一致性。
2. 大数据让小数据变小
大数据的作用不仅限于找到用户,其作用还在于初识用户。
传统调研在开始之前,都会先选定调研的城市,还有调研配额,比如:男女比例、用户年龄比例等等,以保证研究的结果具有普适性,避免调研结果出现偏差。
不过不管是城市还是配额,一般都是研究人员拍脑袋定的,比如男女各半,一线二线各5个城市。而了解用户的分布对大数据而言不是轻而易举么?
因此我们可以先通过大数据了解一下平台用户的地域及年龄分布,然后再分层抽样进行调研。
除此以外,从前面可口可乐的教训中,我们知道了调研在方向上可能存在的误导性。那么,大数据正好也能弥补这一点,在调研之前,可以先通过大数据对用户进行初步的分析,了解用户的行为偏好。
比如:可以通过用户决策树了解用户在浏览或购买时最关注的产品属性排序,如果用户最关注可乐口味的话,我们再针对口味进行调研。
所以,除了能让小数据量级变大以外,大数据还可以让小数据的研究范围变小,瞄准正确的方向,聚焦于探寻大数据结果出现的原因。
3. 小数据让大数据变小
调研的优势在于更深入、更细致,因此调研小数据可以让大数据的研究颗粒度变得更小。
大数据对于用户的研究可能仅限于部分数据维度,而且这些数据维度一般比较粗,譬如:用户的性别、年龄、可能从事的职业、购买力、内容偏好等等,而调研所研究的范围可以更小更细,更深入地辅助大数据了解用户。
而且,小数据聚焦于用户个体,我们可以通过深访了解用户的生活场景、特征偏好,这有利于我们直观地描绘出这个人的形象。
下次演示报告时,我们可以说:“产品经理小王一天的生活是,早上10点来到公司,先冲泡一杯咖啡,然后元气满满地投入一天的工作…”而不仅仅是,“有30%的用户会在早上上班的时候喝咖啡”。
对于听众而言,加上用户自身的描述能更加清晰直观,且比数字更富有感染力,这也算是利用“可得性偏见”的一种报告演示技巧。
此外,大数据中的用户标签多是通过算法模型判断得出的,不能保证100%的准确性,而调研所获取的小数据基本都是真实的。因此,小数据还能对大数据的标签进行反向验证,使得标签的误差变得更小。
4. 小数据让大数据变大
在上述三种情况下,大小数据都是各司其职,分步协作,先由大数据进行初步分析,再由小数据负责补充研究,似乎都没有实现真正的“合体”。
那么如何才能由小数据最终落回到大数据,形成闭环,实现真正的“合体”呢?
下面为大家提供一个思考方向,目前通过爬虫很难抓取到关于对品牌形象描述的词,而市面上有很多负责品牌调研的公司,他们主要的工作就是研究品牌的价值、品牌形象和品牌健康度等等。那么,通过调研获取的用户对于品牌形象的认知,是否可以应用到大数据中呢?
例如:针对服饰而言,我们可以收集各个品牌的品牌形象词,于是我们可以建立起一套品牌形象词词库,之后我们对词进行归类编码或是通过因子分析进行降维处理,从而得到了n个词,比如:小资情调、成熟稳重、青春活力等等。
接着,我们再把这n个词作为标签打到各个品牌上,比如A品牌的标签有四个,分别是:小资情调、成熟稳重、青春活力、简约有设计感;B品牌可能有三个标签,分别是青春活力、酷炫有型、色彩缤纷,各个品牌标签都是并列关系,不分先后。
以此方法,每个品牌都有了自己的标签,那么通过用户与各个品牌的交互行为(浏览、关注、购买等),我们可以建立一套算法将品牌标签打到用户身上。这样,我们便可以知道用户对于服饰的品牌风格偏好。
当用户有了标签之后,我们可以反过来再把用户的标签打到品牌身上,这样一来,我们可以识别出各个品牌下,不同形象词标签的重要性,同时还可能会有新的形象词标签被打到品牌上。
此外,我们还可以通过对某个产品的用户标签进行计算,从而将用户的标签打到每一个产品上,实现标签的细化。
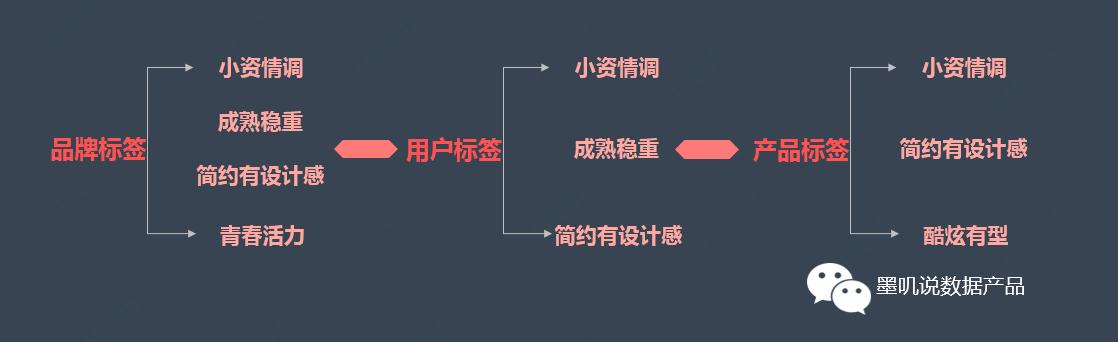
由于涉及部分机密,在此不做详述。总之,通过类似的方法,小数据的结果也可以被应用到大数据中,将大数据的标签库扩大,实现标签的拓展。
四、结语
大数据时代的到来,并不意味着小数据时代的结束,大数据与小数据是对立的,但终将也是统一的。
- 对于小数据而言,大数据带来的是一场革命,是一次否定之否定的曲折式上升机会,唯有借其真气,才能冲开任督。
- 对于大数据而言,小数据提供的是内力的积淀,吸其精华,方能九天揽月。
作者:Mr.墨叽,公众号:墨叽说数据产品
本文由 @Mr.墨叽 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议








有启发
谢谢🙏,一起交流学习~