
 起点课堂会员权益
起点课堂会员权益数据分析武器库:模型空间概述
很多学科所谓的模型只是对研究对象的定类测量,另外再加一些经验性的描述而已。这些模型非常依赖主观经验,可重复性和可操纵性都难以对我们的目标产生量级上的效率提升。数据一部分很重要的意义就是让过去一些无法精确测量的对象变得可精确测量,从而可以引入数学工具解决。这部分是文章的重点,关于数学模型空间。

来,先复习一下,什么是建模:
昨天介绍了模型本质是对现实对象的抽象描述以及附带的一整套抽象的方法,建模本质上就是建立现实对象和模型的一种映射关系。
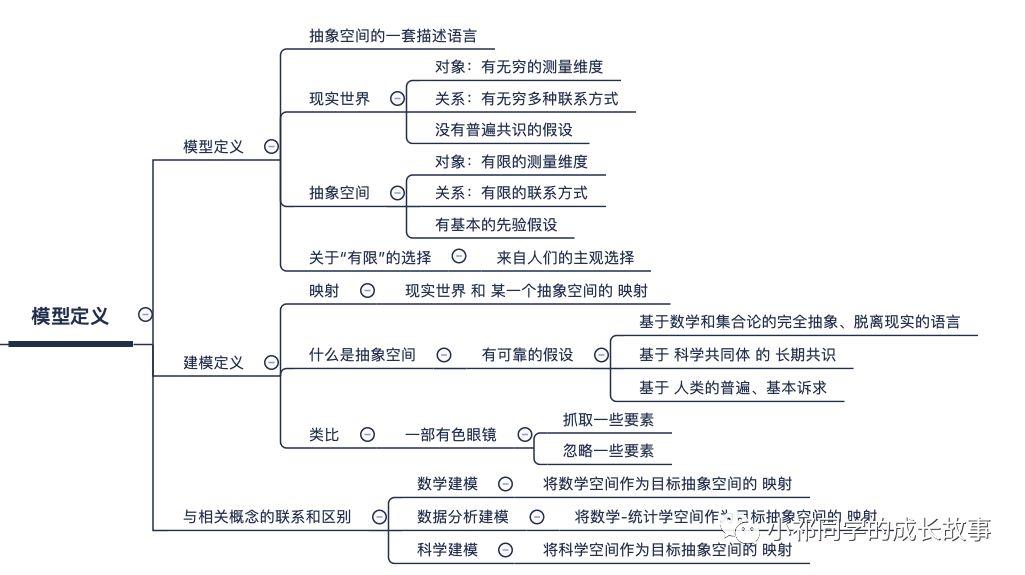
今天我们走进模型空间,看看里面最重要的是什么:
- 我们先来看看我们平时接触最多的
- 感觉很高大上的
- 商业模型是什么?
比如拿我们都知道的swot分析来看:
百科定义:SWOT分析法,即态势分析法,就是将与研究对象密切相关的各种主要内部优势、劣势和外部的机会和威胁等,通过调查列举出来,并依照矩阵形式排列,然后用系统分析的思想,把各种因素相互匹配起来加以分析,从中得出一系列相应的结论,而结论通常带有一定的决策性。
运用这种方法,可以对研究对象所处的情景进行全面、系统、准确的研究,从而根据研究结果制定相应的发展战略、计划以及对策等。SWOT分析法常常被用于制定集团发展战略和分析竞争对手情况,在战略分析中,它是最常用的方法之一。
这种框架分析工具本质是一个分类方式;首先分类了内部和外部,其次分类了优势/劣势,机会和威胁,分类本是一种定类测量,相当于测量了两个数字:一类叫做0,一类叫做1。
接下来,我们需要了解一些关于测量理论的基础知识.有助于理解这类模型本质都是测量。
一般可以将数据类型的度量分为四种:定类、定序、定距和定比。
这四种类型是从低到高的递进关系,高级的类型可以用低级类型的分析方法来分析,而反过来却不行,理解下面这些类型对于后面学习统计分析方法尤为重要。
(1)定类变量
定类就是将给数据定义一个类别。这种数据类型将所研究的对象分类,也即只能决定研究对象是同类抑或不同类。例如把性别分成男女两类:把动物分成哺乳类和爬行类等等。
(2)定序变量
定序变量是将同一个类别下的对象分一个次序,即变量的值能把研究对象排列高低或大小,具有>与<的数学特质。它是比定类变量层次更高的变量,因此也具有定类变量的特质,即区分类别(=,≠)。
例如:文化程度可以分为大学、高中、初中、小学、文盲;工厂规模可以分为大、中、小;年龄可以分为老、中、青。
这些变量的值,既可以区分异同,也可以区别研究对象的高低或大小。 注意!各个定序变量的值之间没有确切的间隔距离。比如:大学究竟比高中高出多少,大学与高中之间的距离和初中与小学之间的距离是否相等,通常是没有确切的尺度来测量的。
(3)定距变量
定距变量是区别同一类别下个案中等级次序及其距离的变量,它除了包括定序变量的特性外,还能确切测量同一类别各个案高低、大小次序之间的距离,因而具有加与减的数学特质。但是,定距变量没有一个真正的零点。
摄氏温度这一定距变量说明,摄氏40度比30度高10度,摄氏30度比20度又高10度,它们之间高出的距离相等,而摄氏零度并不是没有温度。
注意!定距变量各类别之间的距离,只能加减而不能乘除或倍数的形式来说明它们之间的关系。
(4)定比变量
定比变量是区别同一类别个案中等级次序及其距离的变量,定比变量除了具有定距变量的特性外,还具有一个真正的零点,因而它具有乘与除(×、÷)的数学特质。例如:年龄和收入这两个变量,固然是定距变量,同时又是定比变量,因为其零点是绝对的,可以作乘除的运算。
如A月收入是60元,而B是30元,我们可以算出前者是后者的两倍。智力商数这个变量是定距变量,但不是定比变量,因为其0分只具有相对的意义,不是绝对的或固定的,不能说某人的智商是0分就是没有智力;
从这里我们可以看出,很多学科所谓的模型只是对研究对象的定类测量,另外再加一些经验性的描述而已。这些模型非常依赖主观经验,可重复性和可操纵性都难以对我们的目标产生量级上的效率提升。数据一部分很重要的意义就是让过去一些无法精确测量的对象变得可精确测量,从而可以引入数学工具解决。这部分是我们今天的重点,关于数学模型空间。
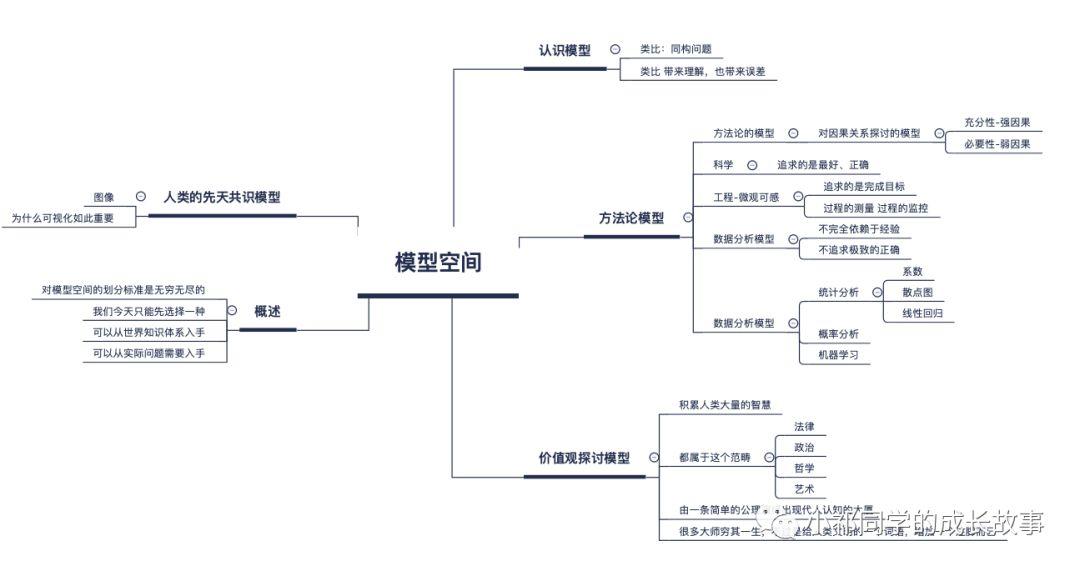
接下进入正题,我们来看一下模型空间的具体内容:
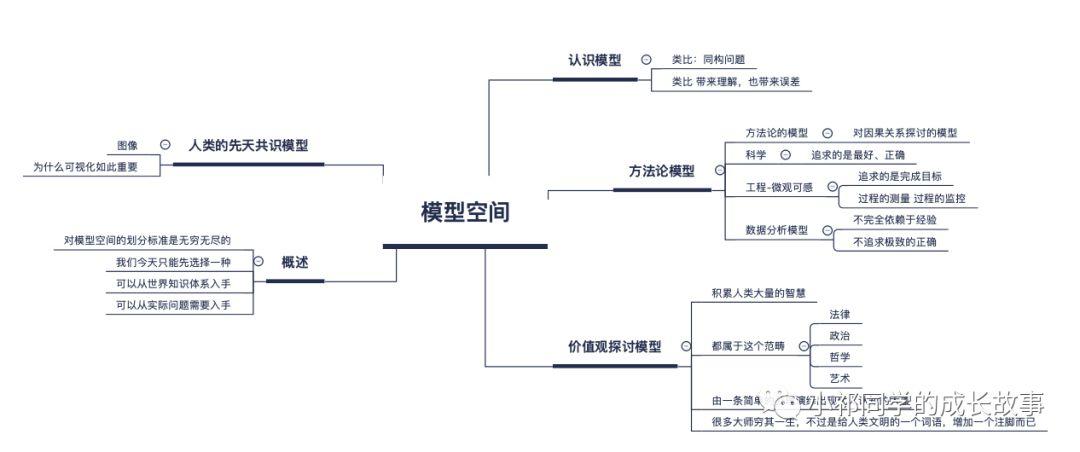
需要说明的是对模型空间的分类,是非常有主观色彩的,我也是斟酌再三之后选取了这样的角度,以期望不遗漏人类在大多数方面积累的智慧成果。
关于人类先天共识模型——图像
在生活场景中,我们可以很容易被一幅生动的图像打动,却很难(也不愿意)被逻辑说服。
这个模型空间内重要是最新的心理学和认知科学的一些研究成果,所以我们在表达我们的成果的时候,往往还要进行一次映射,将抽象成果 映射为 图形样式,方便模型的传播和理解。
从这个角度来看,关于可视化探索的一些工作也是格外有意义的。
关于有助于认识对象的模型
这个模型空间内部主要是各种我们已知的系统和定义的概念,以生物学和物理学为主要内容。
这部分本质为了方便我们寻找同构问题,例如:我们用生物的进化论类比的去理解人类社会的竞争,我们用漏斗这个图形,类比商品转化的过程。
但是需要注意的是寻找同构对象,一方面方便了我们理解对象,也会引导我们忽略对象的一部分特征。比如:我们拿人类社会的发展 类比进化论的时候,忽略了一个重要事实,我们可以基因编辑,从而大大影响自然选择。
关于价值探讨的模型
这个类别里也沉淀了,人类的大量的思辨智慧,从柏拉图到奥古斯丁,从阿圭那到康德,从笛卡尔到休谟,从加缪到沃格林等等,这些伟大如斯的人终其一生都一直在探索一个永恒的问题——人何以为人,这部分也很值得我们去学习,但不是今天的重点,以后有机会可以给大家做一个简单介绍。
关于方法论模型
这部分本质上可以概括为对因果关系的探索、分类问题和标记问题,也可以理解为“果”单一的因果问题。
对因果关系的探索存在两个极端:
- 科学:对正确/稳定可复现的极致追求
- 工程::以完成目标为核心,重视经验的积累。
这个时候出现了一种调和方案——数据分析,我们既不能全靠经验,这样太依赖个人和运气.我们也不能什么事情都做个科学实验,等做完了黄花菜都凉了。
接下来主要给大家介绍数据分析对于探索因果关系的一些方式,这也是我们做数据分析主要进行的工作。
对因果关系的探索分为充分性和必要性两个方向:
- 充分性:就是如果A,那么一定B;
- 必要性:是说我们知道了B的很多特征C,有多大可能性认为A可以推断出B。
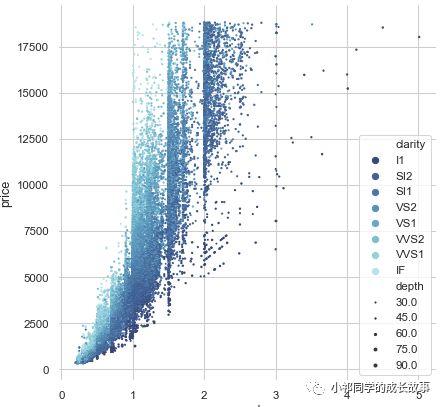
主要通过几种方式:计算各种系数、画散点图、画散点图矩阵、做线性回归、概率估计 (关于相关性和因果性关系又可以写7篇文章了,现实世界中,可以近似的认为 相关性约等于因果关系,或者相关性至少可以为我们寻找因果关系提供一点启发)。
用Python进行相关性分析
画散点图,方法如下:
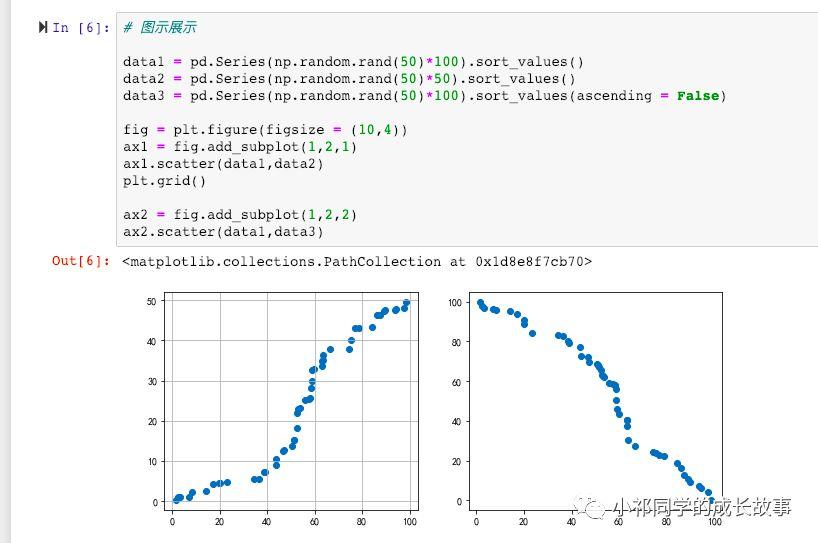
画散点图矩阵的方法,如下:
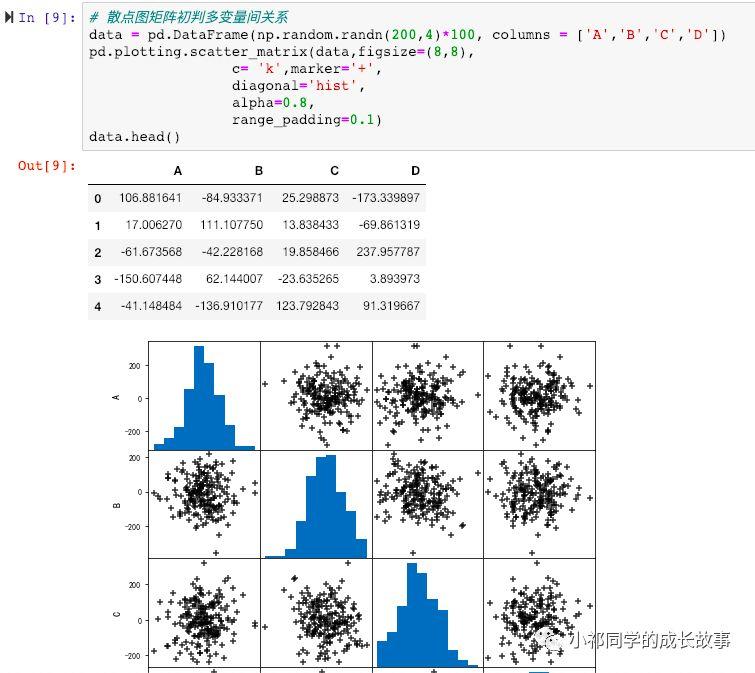
计算系数
pearson(皮尔逊)相关系数要求样本满足正态分布。
两个变量之间的皮尔逊相关系数定义为两个变量之间的协方差和标准差的商,其值介于-1与1之间。

Sperman秩相关系数,皮尔森相关系数主要用于服从正太分布的连续变量,对于不服从正太分布的变量,分类关联性可采用Sperman秩相关系数,也称等级相关系数。

通过机器学习的方式探索因果模型
这部分我们会介绍一些最流行的机器学习模型类型,这也是我们发现相关性的一种武器。监督学习:监督学习算法是基于一组标记数据进行预测的。
比如:历史销售数据可以来预测未来的销售价格。应用监督学习算法,我们需要一个包含标签的训练数据集。我们可以使用这个训练数据集去训练我们的模型,从而得到一个从输入数据到输出期望数据之间的映射函数。
这个模型的推断作用是从一个数据集中学习出一种模式,可以让这个模型适应新的数据,也就是说去预测一些没有看到过的数据。
分类:当数据被用于预测一个分类时,监督学习算法也可以称为是一种分类算法。比如:我们的一张图片可以被分类标记为狗或者猫。如果我们的分类标签只有两个类别,那么我们也把这个分类称之为二分类问题。当我们需要分类的东西超过两个类别的时候,这个模型就是一个多分类模型了。
回归:当我们预测的值是一个连续值时,这个问题就变成了一个回归问题。
预测:这是根据过去和现在的一些历史数据,来预测将来的数据。最常用的一个领域就是趋势分析。比如:我们可以根现在和过去几年的销售额来预测下一年的销售额。
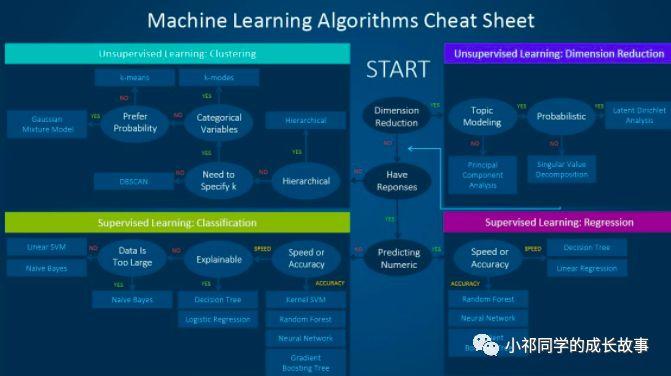
关于机器学习的模型
监督学习主要包括用于分类和用于回归的模型:
- 分类:线性分类器(如LR)、支持向量机(SVM)、朴素贝叶斯(NB)、K近邻(KNN)、决策树(DT)、集成模型(RF/GDBT等)
- 回归:线性回归、支持向量机(SVM)、K近邻(KNN)、回归树(DT)、集成模型(ExtraTrees/RF/GDBT)
关于各个模型的关系和选取原则可以参考下面图片:
最后总结一下
对模型空间做了一个综述,着重介绍了因果关系探索的一些数学模型:
讲个小故事,关于测量,一米等于多少?
1791年,著名科学家拉格朗日,当选为法国度量衡委员会主席。在他全力推动下,一项影响了全世界的长度单位——米浮出水面。
法国相关当局规定:把经过巴黎的地球子午线,也就是经线长的四千万分之一定义为1米。通俗地说,l米是从地球北极到赤道距离的一千万分之一,1791年3月25日(距今227年),法国国民议会决定采纳了只基于一个长度基本单位“米”的计量制度。现在全球通用的国际长度单位米,则由此规定而来。
剩下的问题是如何测量地球子午线的长度了?
那可是200年前,没有飞机,没有核动力航母,于是拿破仑真的派了俩队人一队去北极,一队去秘鲁……开始了测赤道……7年之后俩队人返回测得了结果是57422toise(法国当时长度单位)。
人类为了量化一个对象,有多努力……
作者:小祁爱数据,公众号:小祁同学的成长故事
本文由 @小祁爱数据 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


