
 起点课堂会员权益
起点课堂会员权益产品分析之统计学悖论
在做产品分析时,统计结果截然相反,是何种原因引起的呢?这种情况该如何应对呢?

近期面试聊到了产品分析时统计结果截然相反时,分析人员变成了热锅上的蚂蚁,手足无措。这到底是什么引起的呢?早在1951年性别歧视的案子中就发现了这种相悖的统计结果。
最典型的例子: 1973年加利福尼亚大学伯克利分校性别歧视案的例子:
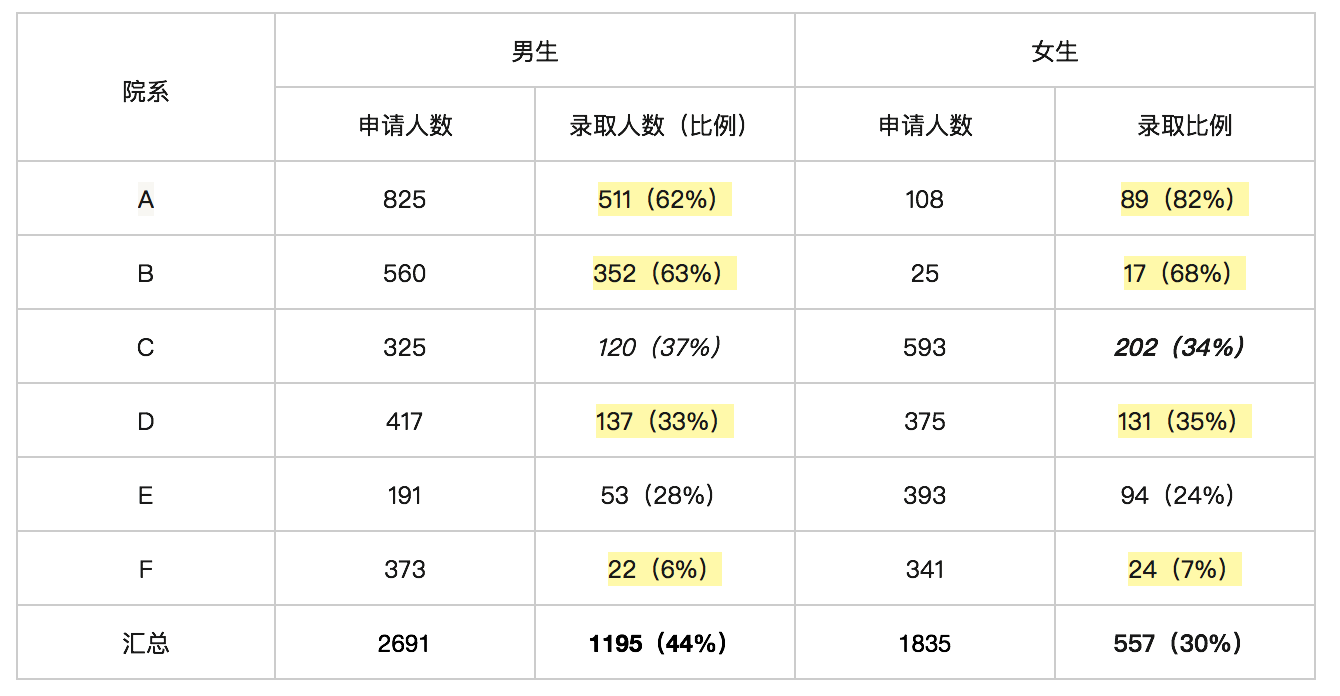
大家从表格里可以看到,如果只看整体录取率,那么男生的录取率是44%,女生的是30%。
但加利福尼亚大学伯克利分校的统计学教授 Peter Bickel 后来发现,如果按照院系分类,女生实际上比男生的录取率还高一些。
一、细节和整体趋势完全不同
辛普森悖论(Simpson’s paradox):当你把数据拆开细看的时候,细节和整体趋势完全不同的现象。
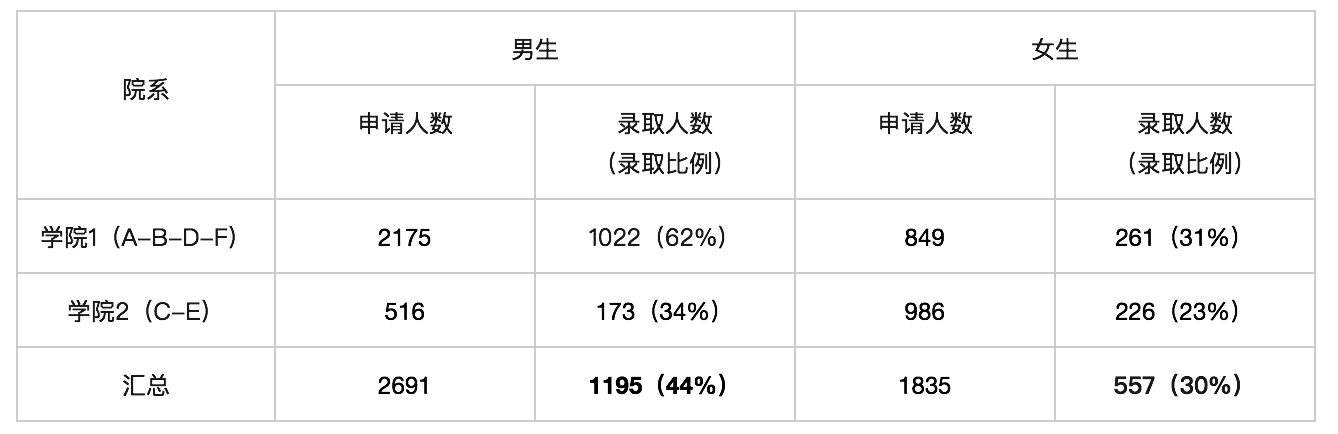
我们简化上述表格,发现悖论是由于基数产生的影响——男生在学院1和学院2的分布和女生的分布截然相反引起的。
在日常分析工作也经常存在这样的现象,经常在两端分析时,大都以为两端作为拆分对比,如iOS、Android投放广告的转化率分析中,通过两端的转化率可以得到结论1,但将iOS、Android按照网页版本、移动版本拆分后会得到完全相反的结论:
结论1: iOS的总体转化率低于Android。
- 基于此可以得到的结论是该批次广告不适合iOS平台;
- iOS平台需要做在转化过程中需要做进一步的漏斗分析以便优化。
结论2: 网页版本iOS的转换率高于Android,且移动端iOS的 转化率也高于Android。
- 基于此可以得到的结论是该批次广告不适合Android平台;
- Android平台需要做在转化过程中需要做进一步的漏斗分析以便优化。
如果没有辩证的结合多个维度分析该数据表现,则会被误导,在错误的方向上投入更多的精力,甚至是完全相反的决策。
二、相关分析中,整体相关性和组间相关性相反。
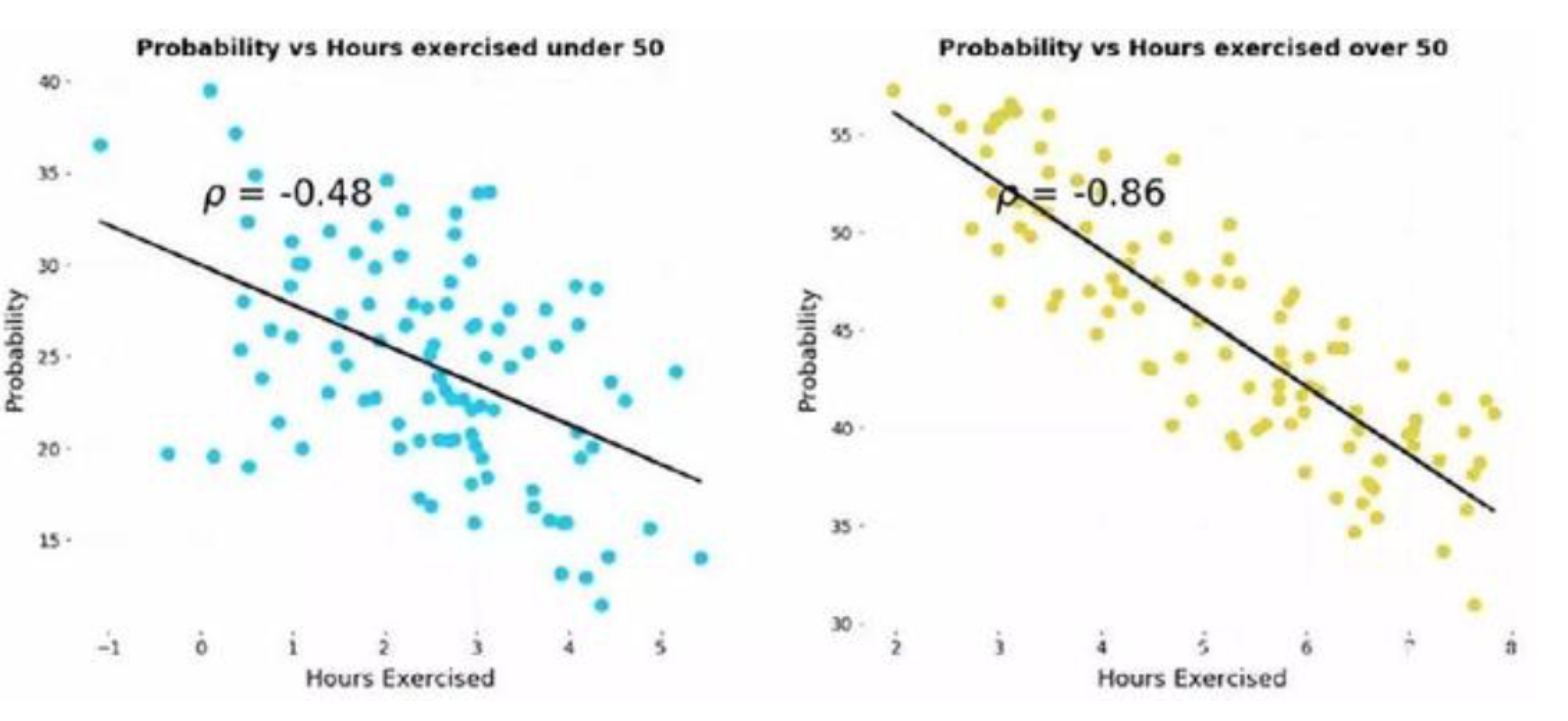
假设我们有每周运动小时属于两组患者(50岁以下、50岁以上的患者)患病风险的对比数据。以下为两组患者患病可能性的散点图:
由下图(x轴是运动小时数、y轴是风险)可以得到的结论是:患病风险与运动小时数呈负相关。
将2组数据合并后,得到的结论是:患病风险与运动小时数呈正相关。与分组结论皆然相反。
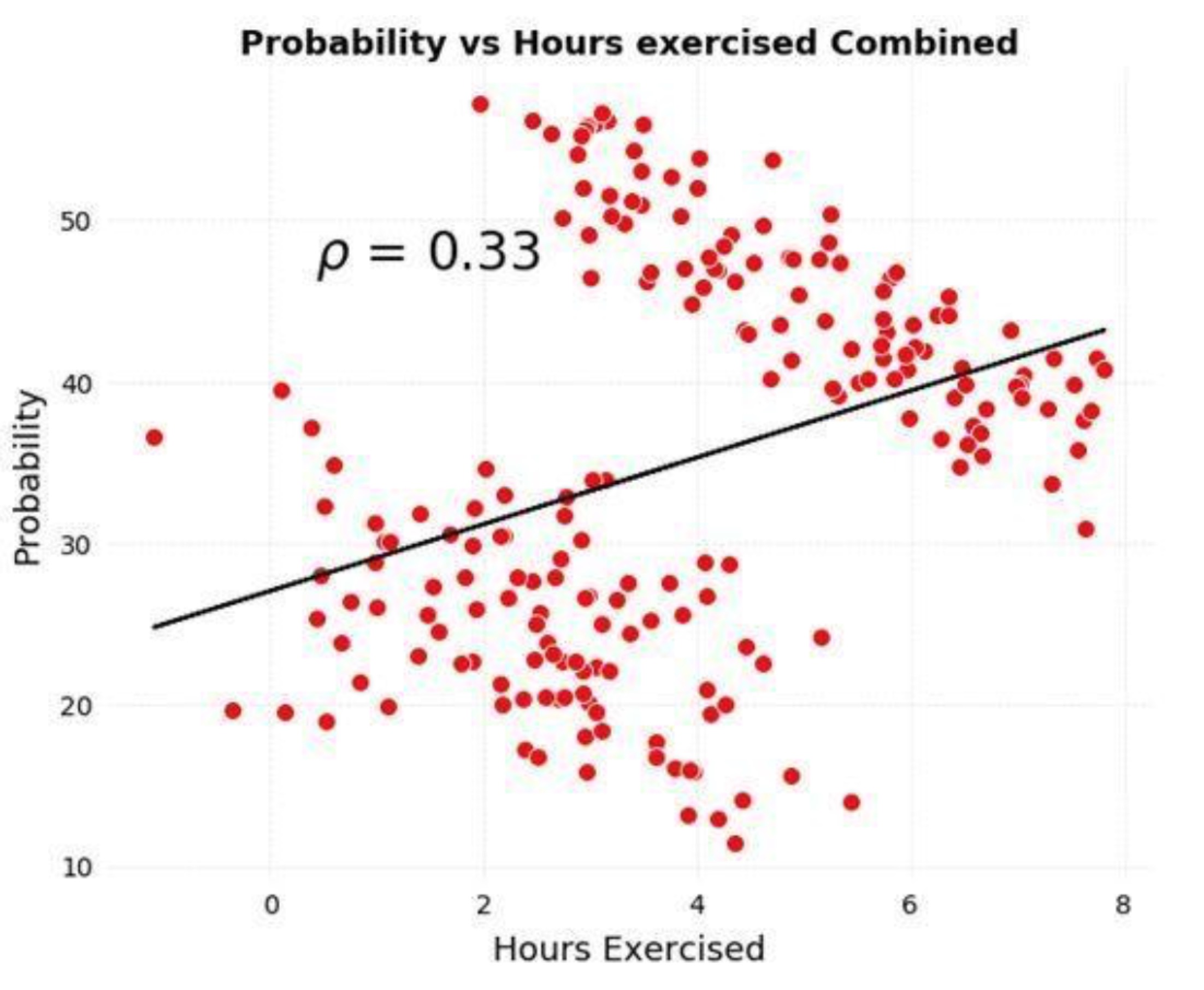
原因是:患病几率是由多种因素引起的,年龄比运动时间的影响程度更大。在分析运动时间与发病几率时,忽略了年龄等其他因素——而进一步拆分后,会得到完全不同的结论。
先前恰巧有通过相关性分析来探讨变量与留存、回访间的关系。
不同停留时长的用户在留存上面的表现,发现停留时长越长的用户留存以及回访现象越不好,这和app使用基本认知相反;
而结合用户用户行为深度分析发现,用户行为越深留存以及回访现象越好。相比笼统的停留时长(包括app使用时长、后台时长),用户行为深度对用户留存以及回访影响更大,其相关表现也更符合真实的现象。
数据分析相比数据挖掘、深度学习,最大的优势就是可解释性,得到的结论需要多结合场景、用户属性思考,是否看到了数据的全貌。
三、AB测试中细分结果和整体结果相悖
AB测试中细分结果和整体结果相悖则要小心了……来看下面这个例子:
通过A、B两种疗法结石的治愈率来看哪一种疗法更好。
基于大结石、小结石,A疗法都比B疗法要好;但汇总结果却是B疗法比A疗法要好。无法判断那个疗法更好。
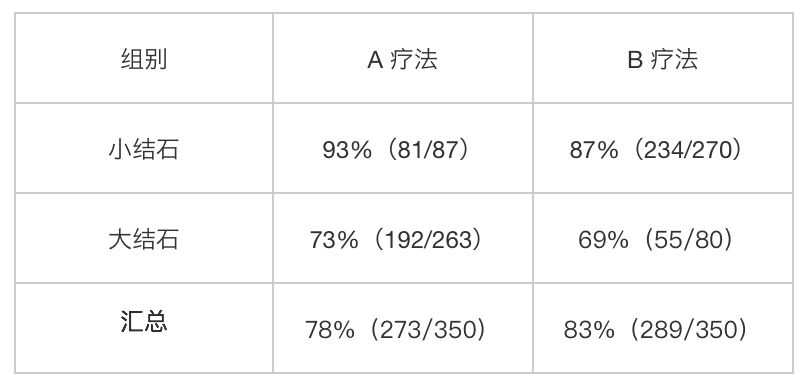
你应该看了本文的第一个例子,可以发现A、B疗法在不同类型的结石中基数差异引起了问题。
在两个组内不同类型的结石中基数差异可能是由第三中因素引起的,如该例子因为医生似乎觉得病情较重的患者更适合 A 疗法,病情较轻的患者更适合 B 疗法,所以下意识的在随机分配患者的时候,让 A 组里面大结石病历要多,而 B 组里面小结石病历要多。
更重要的问题是,很有可能影响患者康复率的最重要因素并不是疗法的选择,而是病情的轻重!换句话说,A 疗法之所以看上去不如 B 疗法,主要是因为 A 组病人里重病患者多,并不是因为 A 组病人采用 A 疗法。
如果将A疗法都比B疗法可以等价为ab测试的对照组和实验组,则会发现这个case就是活生生的ab测试结果数据,并且汇总结果中两组存在明显差异,欣喜若狂的上线实验,但上线后整体数据结果表现并不理想。
所以,这一组不成功的 A/B 测试,问题出在试验流量分割的不科学,主要是因为流量分割忽略了一个重要的“隐藏因素”,也就是病情轻重。正确的试验实施方案,两组试验患者里,重病患者的比例应该保持一致。
理想的ab测试实质是控制变量分析法,不同组(实验组、对照组)之间,仅在实验方案上存在差异,在其他的表征上(包括用户属性、行为属性上都不存在差异)。
四、如何避免辛普森悖论
当前权威的统计学家没有给出一个确切有效的解决方式,因为悖论往往涉及到了业务层面的分类,告诉我们不能仅以统计数字来推导准确的因果关系。总体分析时需要结合多维度、属性、场景来分析,仔细地研究分析各种影响因素,不要笼统概括地、浅尝辄止地看问题。
在做数据分析的时,一定要遵循数据分析的目的——通过数据分析的手段来解释问题、现象,且勿唯“数据”论。
附录:
总结悖论的时候,参考了很多文章,非常感谢每一篇文章的讲解:
《辛普森悖论》
《浅谈A/B测试里常见的辛普森悖论,企业决策者必看》
《数据分析必须警惕的坑:辛普森悖论》
《辛普森悖论?如何解?一招搞定!》
本文由 @cecil 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议









之前看到一句话说的是,数据分析是最大的谎言,我感觉其实就是对数据分析不到位导致的,如何才能确保自己的分析是对的呢
这么好的文章居然收藏点赞不多,估计能看懂的人估计不多。多数人还是只喜欢看不需要动脑子的流水账。
你这也要动脑子?
话题挺好的,但是确定里面有些数字没写错么还有正负相关性。。
第二组的相关性应该是正相关,看得仔细。晚上修改更新