
 起点课堂会员权益
起点课堂会员权益定目的、观数据、断样本、选公式、缩误差,五步估算你的样本有多准
如何快速准确地计算出置信区间?五步法:定目的、观数据、断样本、选公式、缩误差。

在产品的可用性研究中,我们几乎从来不会覆盖整个用户总体。取而代之的是我们会依赖取样,通过样本来估算未知总体的值。
当我们缺少用户总体数据的情况下进行估算的时候,即便是最好的估算结果也只能接近,但并不能得到真实的结果。而且样本量越小,结果的准确性越差。
我们需要一种方法来判断估算我们到底有多准确才行。
于是我们将在一定概率下包含未知参数的这部分数值区间提取出来,这个范围就叫做置信区间。
如何快速准确的计算出置信区间,本人在工作总结了几个方法步骤,快速估算出我们选取的样本到底有多准。
第一步:定目标
1. 研究的目的;
首先我们要清楚的知道我们做这个研究是要达到什么样的目的,公司的资源是有限的,如何用最低的成本去测试出最高价值版本的产品上线,这对一个产品经理来或者用户研究人员说是至关重要的。
研究主要分为两种,一种是叫做“行成式可用性研究”主要用在产品发布之前,一种是“总结式可用性研究”主要在产品发布之后发现相关的产品问题;清楚的知道研究产品的哪个阶段,该阶段的具体问题,对可用性研究来说是至关重要的第一步。
例如:我们想验证新版本的产品的动线设计对引导用户加入购物车这个动作完成率是否有提高,提高了多少?是否可以上线去做测试?这是产品发布前,属于“形成式研究”;我们想知道新上线的签到得积分奖励这个功能对用户的留存是否有提升,属于产品功能发布之后,属于“总结式”可用性研究。
2. 确定测试的度量;
确定好研究的目的之后,我们要细分到我们需要具体测试哪个维度来度量,不同用户研究的目的对应着不同的场景,不同的场景有不同的研究度量;很多时候一个场景是需要多个度量指标来组合来得出产品的相关结论的。
例如:例如研究“完成一个业务”来说,需要测量“任务成功率”、“效率”、“基于任务的度量”、“自我报告式度量”等等;在研究“导航栏或者信息架构的效果来说”需要度量“指定任务的成功率”、“发生的错误率”等等度量的指标。
3. 明确改版之后的效果目标。
新版本的置信区间最低的值是否达到目标的比例呢,从而判断这次改版是否要上线。
例如:我们的目标是新的消息提醒策略让用户的打开推荐消息率提高到3%,我们选100个用户做研究时,7个人打开;发现打开率的置信区间在3.2%~13.8%,误差的最低范围是3.2%>3%,于是可以上线。
建议:按照1、2、3的步骤来,层层深入,有利于目标的精准定位;第一步“定目标”的目的是要知道我们的做这个研究的目的,通过怎样的度量去做研究,明确该研究实验要达到目标,才能上线。
第二步:观数据
不同的度量维度,所收集到的数据和数据类型是不同的,主要分为“二项式数据”和“连续性数据”两类。
二项式数据的特点是编码成一个二选一的答案,1表示成功,0表示失败,它计算平均值是没有意义的;而连续性数据的平均值是有一定意义的,它的平局值是符合正态分布,但是存在一定的“变异性”和“偏移性”。
不同的数据类型计算的公式也会有所不同,后面会阐述公式的选用。平时在测试任务成功率,和任务错误率的时候,这些收集到的数据大多数是二项式数据,在收集任务时间、评估得分的时候则多收集到的是连续性数据。
数据的获取是根据“测量的目标”来确定的,收集到的数据具体是哪类型的数据,对于选择置信区间的计算公式来说至关重要。
第三步:断样本
“断样本”关键是两个环节:“评估样本的大小”和“筛选样本的群体”。
样本的数量的其实是受多方面的影响和选择的(在接下来的文章中我会接着介绍样本数量的计算)。
但是大多数情况下,我们是根据公司的具体情况来定样本的大小,如果是线下邀请用户来测试,我们需要考虑到很多成本问题;如果是线上的的分流测试,我们需要考虑用户所处环境的场域影响问题,最大程度上减少数据的噪音干扰,对样本数量的大小和样本群体筛选来说是非常重要的。
然而最关键我们要知道在现有条件下获得的样本数量属于大样本还是小样本,样本的是否具有对研究目标有一定的代表性。
第四步:选公式
置信区间公式的选取;主要受两个因素影响:一个是数据的类型,一个是样本的大小。接下来我就以上两个来做一些分类:
1. 对于二项式数据
(1)Wald置信区间计算方法:

Wald区间的问题在于,应用小样本(小于100)或者比例接近0或1的时候非常不准确。如果100次中实际应该有95次都包含真实比例,Wald区间的值要小得多,通常会低至50%~60%;换句话说,当你根据Wald公式报告95%的置信区间的时候,它实际上只有70%。应为这个只发生在小样本或者比例大于0.5的情况下。
(2)精准置信区间计算方法:
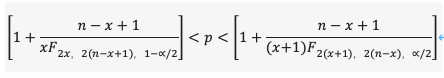
优点:对于任何样本数量和比例范围都适用;
缺点:过于保守,计算量大。
精准区间建立在保证置信区间能够提供至少95%覆盖率的基础上,为了达到这个目标,精准区间往往过于保守和严谨,其包含用户比例接近于100人取99人次(和普通置信区间的100人去95人次相比)。
换句话说,当你在使用精准方法报告一个95%的置信区间时,其结果可能来自99%的区间。结果会得到过宽的区间,特别是在样本数量不是很大的情况下经常会出现这种情况。
(3)Wald矫正区间计算方法:
Wald校正区间法对大多数的样本完成率来说通Willon区间法一样有较好的覆盖率,在完成率接近0或1时通常有较好的结果。“增加两次成功与两次失败”(或者分子加2,分母加4)是从95%区间的正态分布的临界值(1.96,大约为2,平方后既为4)推导而来的:
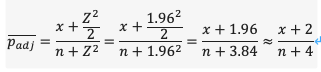
x是成功完成任务的次数;n是尝试任务的次数(样本量)。
标准的Wald公式调整后是:
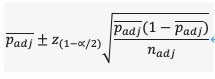
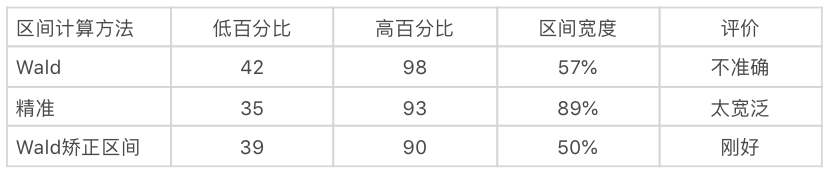
例:如果有10个用户7位成功地完成了任务,我们可以有95%的信心说真实的完成率。分别用上面的三种方法计算。
2. 对于连续性数据
(1)连续性数据的置信区间

该计算计算的方法无论样本大小的时候都比较适用,当样本小的时候,会增加置信区间宽度;当样本量大的时候,t置信度又会收敛于z区间;所有无论样本大小都适用。
(2)几何平均数计算置信区间

在样本量小于25时,几何平均数比中位数和平均值有更少的错误误差。由于中位数具有“变异性”,对极端数值的影响力和抵抗力弱;而平均数具有“偏移性”样本的平均值可能高估或者低估看样本总体平均值。其中的关键点是要对数值先进行对数转化再来计算。
(3)围绕中位数的的置信区间

对于特定类型的数据(例如,任务时长、反应时长或薪资数据)会有偏移性,它们的中位数通常比平均值更适合作为中间值来估算。
对于小样本数据来说,几何平均数对总体中位数的估算比样本中位数要好。样本尺寸越大(特别是超过25后),中位数越倾向成为中间值得最佳估算值。
第五步:缩误差
“缩误差”是指“缩小误差幅度”,“置信区间=误差幅度的两倍”。知道如何缩误小误差幅度的之前,我们先要了解影响置信区间的主要因素,分别是:“置信度”、“变异性”、“样本量”
置信度:举个例子来说,95%的置信度就是在一个95%的置信区间中的覆盖度。置信度为95%(通常使用的值)意味着如果同一个样本中采样100次,区间中将会有95次会包含真实的平均数和比例。
变异性:如果一个总体中总有较多的变异量,每一次的取样都会对结果产生较大波动进而的一个较大的置信区间。总体中的变异是通过计算样本的偏差来估计的
样本量:在不降低置信度的前提下,样本量是一个产品经理可以主动调整并影响置信度区间的因素。置信区间宽度和样本量之间是一个逆平方根的关系。这意味着如果你想将误差幅度j降低一半,需要将样本量翻两翻。例如如果你的误差幅度在样本量为20的时候是正负20%,那么你需要在样本量达到80时才能将误差幅度为正负10%。
如果置信区间太大,我们会觉得这个样本的估算太不靠谱,尤其置信区间大于50%的时候。所有在计算出置信区间之后一般在条件允许的情况下,都会先通过样本的数量来调节,再调节置信度,最后看看样本的质量是否存在变异性。
本文由 @平遥抒雪 原创发布于人人都是产品经理。未经许可,禁止转载






- 目前还没评论,等你发挥!


