
 起点课堂会员权益
起点课堂会员权益数据分析模型:会话分析
本篇主要讲解数据分析中的「会话分析」的分析方法和搭建思路,并以会话分析的目的为切入点,具体分析了它的实际运用以及出现的问题/解决方法。

一、什么是会话
会话分析分析,字面理解的意思就是以一次会话作为主体进行分析。
会话(译自 session),起源自 web 服务中的 session 机制。在、数据分析的语境中,我们可以解释为:一次有始有终,目的明确的一连串动作。
- 有始:我们需要知道用户从哪里、什么时间开始;
- 有终:我们需要知道用户从哪里、什么时间结束;
- 目的明确:我们需要知道用户做了什么、目的是什么、结果又如何……
二、为什么要做会话分析
做数据分析绝对不是单纯的分析数据做数据的可视化展示。我们搭建各种分析模型,采用不同的分析策略,最根本的目的就是——发现并解决我们遇到的问题。
首先,在数据分析行业刚兴起的时候,人们分析数据的视角站在事件发生的本身,比如:关注支付订单的金额,订单的数量。在我们进行分析时,也很自然地将事件和人关联到一起,然后得到「人 → 事件」的关系。
后来,我们发现每个人在用我们的产品的时候,使用的路径、时间长短、浏览的深度甚至启动 App 的方式,都会对用户最后的转化带来影响。所以,只有真正地还原事件发生的场景,才可以更好进行数据的分析。
由于我们的产品形态大部分都是流程化的引导,即逐步引导客户(搜索)、逐步拆解客户需求(列表),然后给出解决方案(商品购买)。那么,用户的一次完整的体验,就是「用户产生需求 → 使用产品 → 解决需求」这样一个流程。
于是,我们就依照上述的思想,设计了「会话分析」的数据模型。
三、会话分析的推演
我们的目标,是把用户「有始有终」的行为序列还原出来,作为一个整体参与分析。
思路
当我们发现我们需要分析的数据,不是一个点,而是一条线的时候,最简单粗暴的方式,就是把这些数据连在一起,变成一条线来记录就好了。
于是我们可以在 App 启动的时候,记录一些启动来源(session id),然后后续的所有事件都使用该来源作为属性一直携带。这样,我们在分析每个事件发生的时候,就知道了这个事件是在哪个场景(启动来源)下发生的了。
实现
记录启动的来源和参数,可能需要服务端辅助记录一些信息,并同步给我们的 App 或直接在数据层进行加工,最后我们需要实现:启动的方式(桌面、push、其他应用唤起..)和启动的来源(广告渠道、活动id、用户主动…)的信息记录。
应用
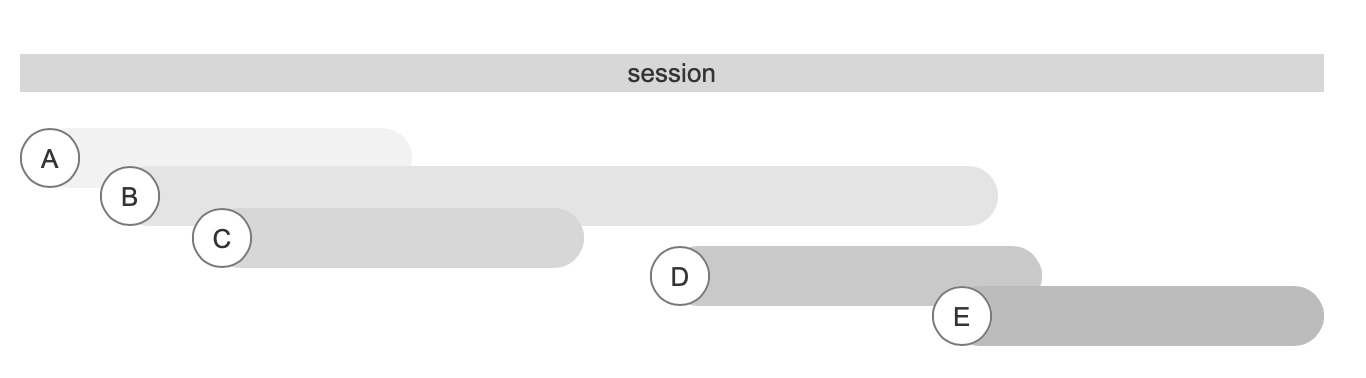
接下来,我们把有相同启动来源的事件按照时间排序,放在一起,这一步实际上我们就还原了用户的一次会话。我们有了用户一次访问的开始和结束,我们就可以做以下分析:
沉浸式体验的相关分析:
会话时长:一个会话的持续时间
会话深度:会话的层级数
使用:有了用户的使用时长和深度,我们就可以分析出用户对我们的产品投入程度。结合每个会话中的事件顺序,我们可以得到一个局部的最优价:用户按照哪个路径走,使用效果最好。当然了,这个肯定要结合自己的分析和业务,如果客户每次都是直接进入,然后立刻购买后就离开,我觉得不做沉浸式的体验似乎也没什么问题。
跳出率:用户做了某个事件后退出的占比
使用:我们把跳出率高的事件找出来,并且排除我们的目标事件,做个排序,就不难发现,用户的退出大都发生在哪些步骤,如何改进这些非正常的跳出,就是我们需要解决的事情。
事件时长:用户在某个页面或某个事件花费的事件。
使用:通过事件时长,我们可以分析出用户对哪个页面感兴趣,在哪个页面耗时比较久,从而发现问题。
同时在线人数的相关分析:
同时在线人数:同一时间有效的会话数量。
使用:由于我们将数据由点变成了线,那么理论上我们就可以统计某个时间点存在的会话数量,即业内常用的同时在线人数。与传统方式相比,使用会话计算的好处是:他的计算是灵活的,而且对数据的采集要求不高;但是缺点也很明显,会损失部分精度。
改进
建模后,在我们的会话分析过程中,逐渐暴露了几个问题,如下所示:
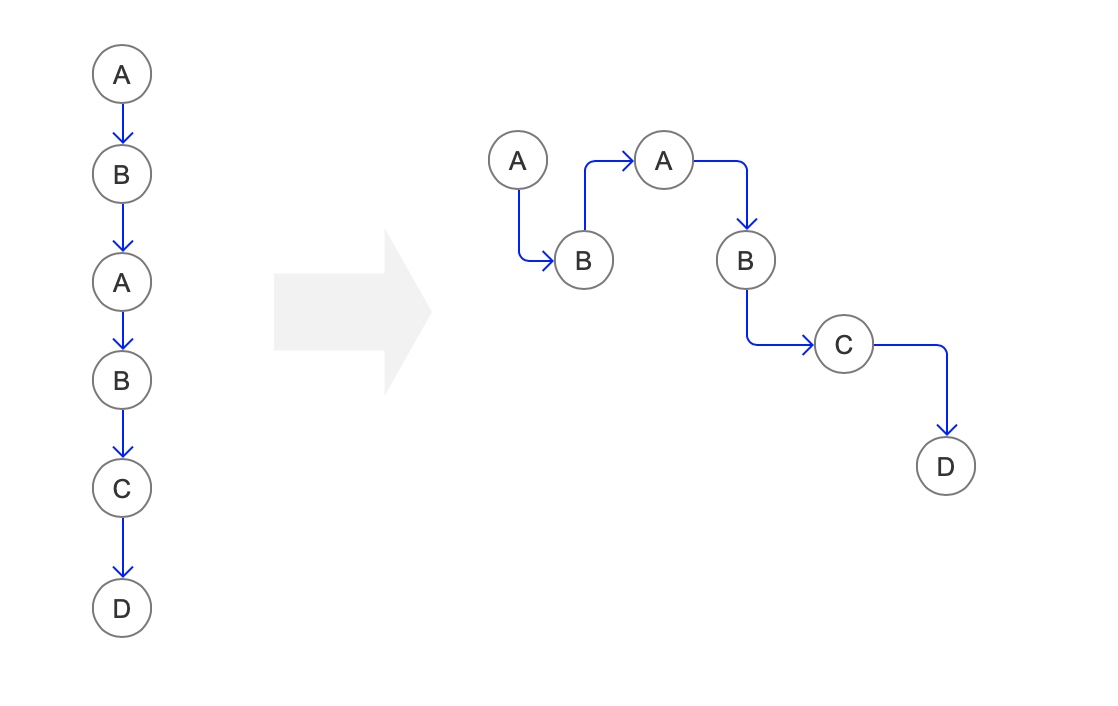
1. 如何更灵活地定义一个会话?
我们使用的是实体参数记录的方法,这种方式会引入切割不灵活的问题。但是实际上,我们可以通过定义切割事件和切割时间,加上逻辑运算来实现这种会话的拼装。
比如,我们定义「App 启动」作为起始条件,「App 退出」和「超过 5 min 进行切割」两个条件作为退出条件,我们便可以将排好序的用户行为序列切割为一个又一个会话了;同时我们使用起始事件「App 启动」的一些指定属性,虚拟的为会话中事件进行赋值。
所以我们的要做的改进是:实体记录 → 逻辑还原。
2. 如何评估会话质量?
我们采集了会话后,可以得到「时长」「深度」「包含事件」「跳出」等等一系列的会话级别的指标。
首先我们可以简单将会话分为三类:「常规型会话」「无用型会话」和「贡献型会话」
如果一个用户仅进行了开始和结束,那么就可以理解为本次会话是无用的(看起来有点残酷);做了很多事情但是却没有形成转化,这种会话应该是最普遍并占比很高,是我们分析的重心;产生会话并且发生了转化,这种属于标杆型的会话。
所以我们要做的改进是:做会话切割,并且进行类型的标记。
3. 如何解释会话深度?
目前使用会话中的事件数量来表示会话的深度,可能很多人都会觉得这个不是深度的概念,而是会话的内容数量。因为浏览的页面内容和会话的质量之间有很大的关系,针对这种通过时序还原的行为序列,解决深度层级的计算有两个比较通用的方法:
- 记录前序,然后靠计算来还原层级结构;
- 预定义,提前定义好每个页面层级的深度。
所以我们要做的改进是:引入其他维度,来更准确的记录或还原会话的深度,从而更好的评估会话的质量。
4. 如何防止因页面久留而导致的误切割问题
这是一个很经典的问题,纯计算的方式,必然会引入这种误切割的问题。那么我们看看有什么办法可以解决掉。
第一种,上传心跳,类似于视频类的网站,可以包装在视频的分段下载中判断用户是否还在记录观看视频;
第二种,自定义每个事件的切割时长。我们把每个单点事件都假象成是一条线段,这样只要线段有重叠,我们就认为会话是连续的。当然,记得添加一个退出事件来进行切割,不然你会发现你每个视频的观看时长都很久。
所以我们要做的改进是:支持每个事件的预期时间(切割时间)都是可定义的,这样来实现更贴合业务的会话构成。
四、总结
在数据分析的时候,我们是需要自上而下地进行指标和需求的梳理;再自下而上地进行数据的采集和建模。在不考虑计算性能的情况下,逻辑运算的灵活性要远高于实体的数据采集,并且维护成本也要少很多。模型的搭建都是循序渐进的,找到适合自己业务的计算模型至关重要。
会话分析这个模型,更多的价值在于体现了「从一次会话的角度,来看用户从进入到离开的这一小个生命后期的使用情况」,更多的是带来用户体验相关的反馈结果。将很多有关联的行为放在一起来进行分析,可以比较宏观地进行问题的挖掘和排查。
作者:宋宋,神策数据产品经理。
本文由@请叫我宋宋 原创发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash, 基于CC0协议









有个问题想问下,这个会话的适用场景是不是只适合feed流浏览,短视频观看等单向的用户行为
如果是双向的对话行为,如何评判深度和质量?例如与客服的沟通
虽然自己知识储备不足,但是哪怕学到一点都是宝贵的
数据大神,写的很棒,关注了!