
 起点课堂会员权益
起点课堂会员权益基于25W+知乎数据,我挖掘出这些人群特征和内容偏好(一)
本文作者基于25W+知乎数据,挖掘出与话题相关的人群特征和内容偏好,一起来看看~

本次对话题进行分析的重点在于:
- 男、女性用户的话题关注差异
- 话题频繁项集和关联规则挖掘
- 用Word2vec量化话题之间的关联性
分析部分
1. 话题分析
在社会化媒体中,话题是指一个有影响力的事件或者活动。而在知乎上,话题是由内容(问题和回答)和人(提问者、回答者和关注者)构成的,而且话题之间存在着父子级关系。
知乎上的“话题”有别于其他社会化媒体上的“标签”,并非由用户自由创建、自由使用。如果话题被合理的添加到问题上,就意味着根据社区的共识和使用习惯,一些可能相似的内容被联系在了一起。
本质上,话题的作用是连接人和问题,它描述的是一个领域。一类有共同主题或属性的问题可以归类到一个话题下。这些基于话题的联系和分组能够帮助用户方便、快速的发现某个主题的内容。
在知乎这个社会化媒体上,话题是用户活动的基础,用户的信息创造、传播、组织必须依赖于话题。因此,对知乎上“数据分析”相关用户群体的话题偏好分析很有必要,它可以从宏观上把握用户的内容需求。
(1)男、女性用户的话题关注差异
经统计,女性关注的话题数量有28727个,男性用户关注的话题数量是 35774个,从关注话题丰富度上来看,男性用户明显要多于女性用户。
二者关注话题的交并集情况如下所示:
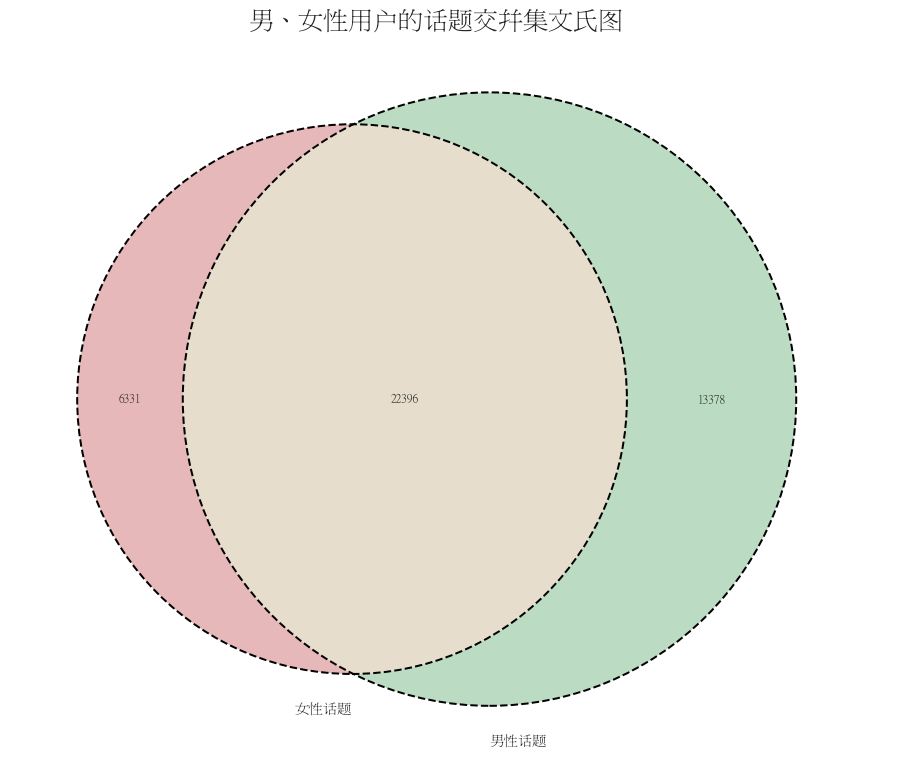
由上图可见,男女性用户共同关注的话题较多,数量为22396个,分别占到女性话题关注数的78%和男性话题关注数的63%。总体上看,这部分人群在话题偏好上有较强的相似性。
现在由表及里,从TOP 30热门话题来看男女性用户在话题关注偏好上的异同。
先看看不区分性别下的TOP30热门关注话题:
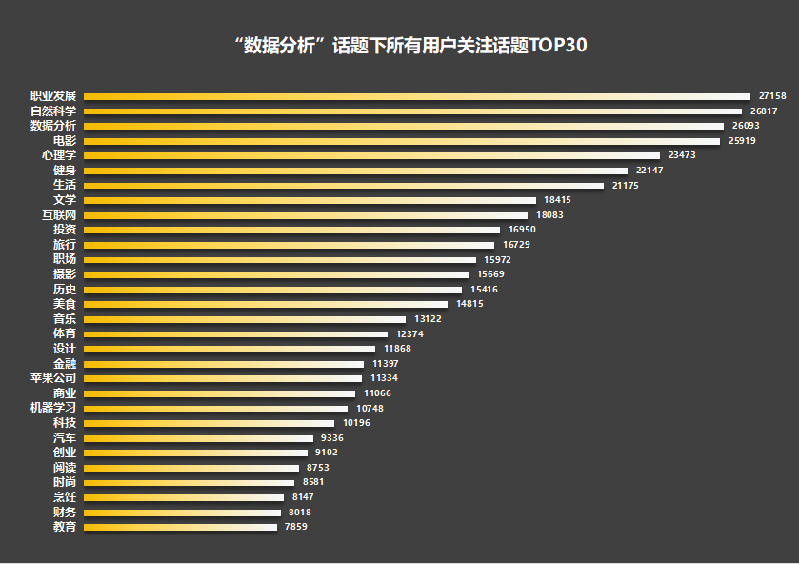
从上图可以看到,“职业发展”、“自然科学”、“数据分析”、“电影”、“心理学”、“健身”、“生活”、“文学”、“互联网”和“投资”等是总体上排名靠前的话题。
再来看看女性用户TOP 30的热门关注话题:
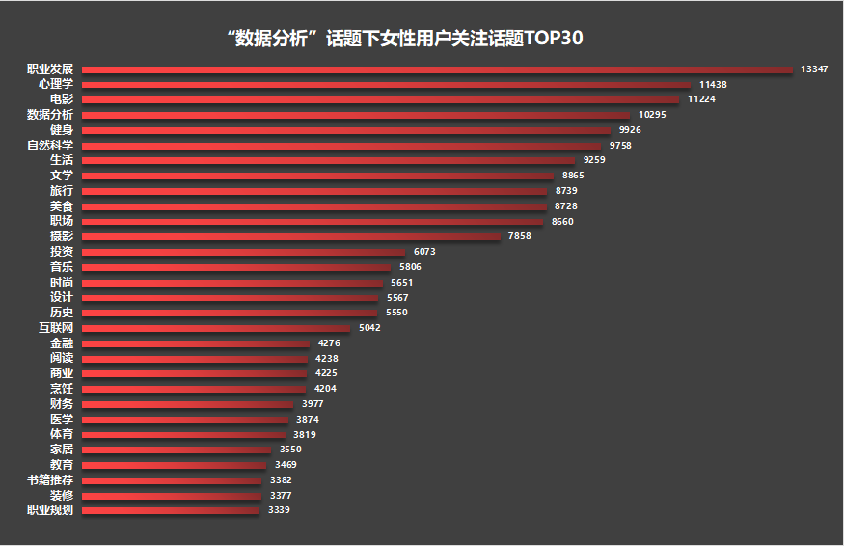
其中,“职业发展”、“心理学”、“电影”、“数据分析”、“健身”、“自然科学”、“生活”、“文学”、“旅行”和“美食”是女性群体较为关注的话题。
最后,看看男性用户较为关注的TOP 30热门话题:
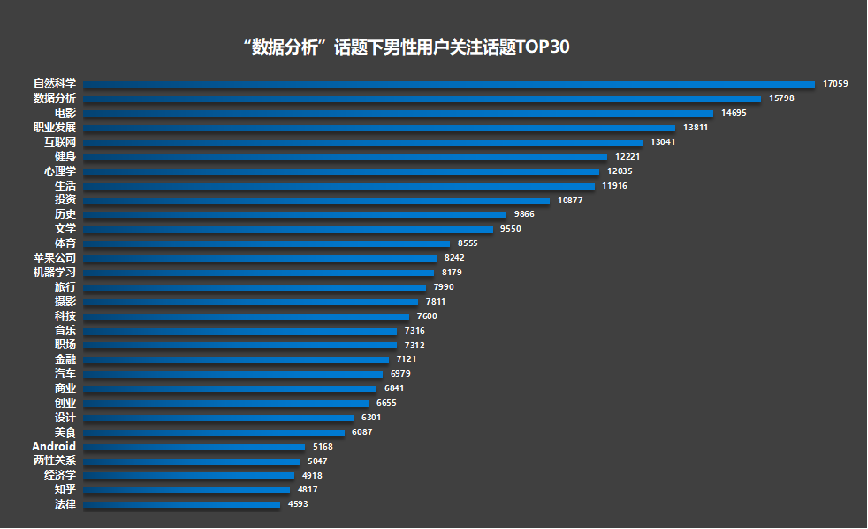
其中,“自然科学”、“数据分析”、“电影”、“职业发展”、“互联网”、“健身”、“心理学”、“生活”、“投资”、“历史”是男性用户较为关注的话题。
上面是按性别单独来分析的,但数据分析只有在“求同存异”时才能发现一些有意思的信息。现在用韦恩图展示一下男女性用户关注话题TOP30的交集和差集(男女性用户独有的关注话题):

从TOP30关注话题的差集来看,女性用户的关注话题反映出她们精致、居家的特点,而男性用户反映出他们对技术和理性的偏爱。同时,二者的交集反映出他们对于自身职业发展的重视和对生活的的热爱。
(2)话题频繁项集和关联规则挖掘
做数据分析的小伙伴几乎都听说过“啤酒与尿布”的故事 :在超市的订单记录中,啤酒和尿布总是频繁共同出现在同一条订单记录里,如果把啤酒和尿布放在一起售卖就会产生较好的收益。
那么,细想推理一下:数据分析相关的用户会关注一连串的话题,这些话题之间是否存在一定程度的关联关系?
按我们的常识来看,会的。比如,笔者关注“数据挖掘”,那么,“数据分析”、“大数据”、“机器学习”也很有可能成为笔者倾向于关注的话题,这种情况倒是显而易见。
但是,笔者还想挖掘另一类的话题关联性,比如,关注“数据分析”话题的用户还会关注哪些跨领域的话题,比如“美食”、“星座”、“哲学”等,这些话题会超出我们的意料。但对于内容运营者来说是福音,因为在数据分析相关的文章里杂糅这部分轻松愉悦的“辅料”,会增强内容的可读性和趣味性,促进内容的自发传播。
这就引出了本文的主题之一 ——话题关联度挖掘。
它分为两个方面:话题频繁项集和话题关联规则。前者是指在话题数据库中大量频繁出现的话题集合,后者比前者更进一步,除了发型大量的话题集合,还能发现其中话题出现的先后顺序。
1)频繁项集的挖掘方法和原理
主流的频繁项集挖掘算法有Apriori和FP-growth。其中,Apriori 算法需要多次扫描数据库,这就使得该算法本身不适合大数据量。由于此次分析的话题list较多,在单机上比较吃计算资源,笔者在这里采用性能较高的FP-Growth算法来挖掘话题之间的关联性。
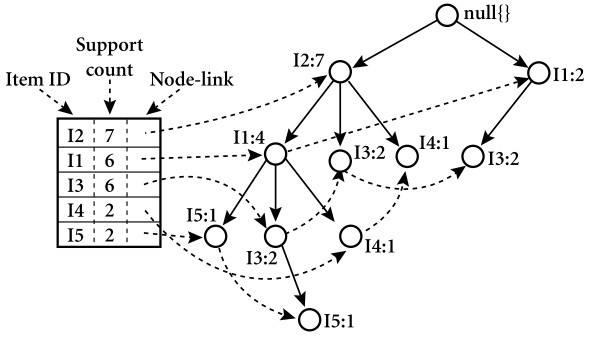
可喜的是,如果我们有了频繁项集,就能顺势挖掘出关联规则。
关联规则是在频繁项集的基础上得到的,它指由集合 A,可以在某置信度下推出集合 B。通俗来说,就是如果 A 发生了,那么 B 也很有可能会发生。
举个例子,有话题关联规则如:{‘数据分析’, ‘数据挖掘’} -> {‘机器学习’},该规则的置信度是 0.9,意味着在所有关注了’数据分析’和’数据挖掘’的用户中,有 90%的用户还关注了’机器学习’这个话题。关联规则可以用来发现很多有趣的规律。这其中需要先阐明两个概念:支持度和置信度。
- 支持度(Support):支持度指某频繁项集在整个数据集中的比例。假设数据集有 10 条记录,包含{‘数据分析’, ‘数据挖掘’}的有 5 条记录,那么{‘数据分析’, ‘数据挖掘’}的支持度就是 5/10 = 0.5。
- 置信度(Confidence):置信度是针对某个关联规则定义的。有关联规则如{‘数据分析’, ‘数据挖掘’} -> {‘机器学习’},它的置信度计算公式为{‘数据分析’, ‘数据挖掘’, ‘机器学习’}的支持度/{‘数据分析’, ‘数据挖掘’}的支持度。假设{‘数据分析’, ‘数据挖掘’, ‘机器学习’}的支持度为 0.45,{‘数据分析’, ‘数据挖掘’}的支持度为 0.5,则{‘数据分析’, ‘数据挖掘’} -> {‘机器学习’}的置信度为 0.45 / 0.5 = 0.9。
2)话题频繁项集和关联规则的挖掘结果
a. 话题频繁项集的挖掘结果
这里笔者取支持度大于等于100的话题频繁集,因返回结果太多,篇幅所限,仅展示部分结果:
首先是“数据分析“这一话题的频繁项集:
- (‘体育’, ‘数据分析’): 174
- (‘数据分析’, ‘苹果公司_(Apple_Inc.)’): 152
- (‘商业’, ‘数据分析’): 110
- (‘体育’, ‘数据分析’): 174
- (‘互联网’, ‘数据分析’): 143
- (‘数据分析’, ‘生活’): 162
- (‘数据分析’, ‘金融’): 104
- (‘数据分析’, ‘美食’): 108
- (‘投资’, ‘数据分析’): 143
- (‘健身’, ‘数据分析’): 164
- (‘数据分析’, ‘文学’): 180
- (‘数据分析’, ‘电影’): 186
- (‘摄影’, ‘数据分析’): 187
- (‘数据分析’, ‘职场’): 198
- (‘数据分析’, ‘职业发展’, ‘职场’): 149
- (‘心理学’, ‘数据分析’): 239
- (‘心理学’, ‘数据分析’, ‘职业发展’): 101
- (‘数据分析’, ‘自然科学’): 327
- (‘数据分析’, ‘职业发展’, ‘自然科学’): 163
- (‘数据分析’, ‘职业发展’): 352
- (‘体育’, ‘数据分析’, ‘自然科学’): 104
- (‘数据分析’, ‘职业发展’, ‘职场’): 149
从中可以看到,用户在关注“数据分析”这一话题的同时,还会关注其他跨领域的话题,跟工作相关的话题有职场发展、商业、心理学、金融、投资等,偏生活休闲的话题有美食、健身、生活、文学、体育等。
其他具有代表性的话题频繁项集有,感兴趣的小伙伴可以解读一下:
- (‘化学’, ‘地理学’, ‘天文学’, ‘生物学’, ‘职场’, ‘自然科学’): 118
- (‘化学’, ‘天文学’, ‘物理学’, ‘生物学’, ‘职业发展’, ‘职场’, ‘自然科学’): 119
- (‘时尚’, ‘演艺明星’, ‘电影’, ‘职业发展’, ‘职场’): 110
- (‘时尚’, ‘服饰搭配’, ‘演艺明星’, ‘职业发展’, ‘职场’): 125
- (‘化学’, ‘历史’, ‘地理学’, ‘电视剧’, ‘职业发展’, ‘职场’, ‘装修’): 120
- (‘历史’, ‘文学’, ‘电影’, ‘社会心理学’, ‘美食’, ‘职业发展’, ‘自然科学’): 129
- (‘心理学’, ‘文学’, ‘社会心理学’, ‘美食’, ‘职业发展’): 348
- (‘土木工程’, ‘工程学’, ‘投资’, ‘机械’, ‘烹饪’, ‘经济’, ‘职业发展’, ‘职场’, ‘自然科学’, ‘装修’): 443
b. 话题关联规则挖掘
关联规则用于发现 if -> then(([A,B] -> [C]))这样的规则,并可以给出这条规则的可信度。基于这些关联规则,我们就可以了解到“数据分析”相关的知乎在喜欢XXX话题的情况下,还会关注哪(个)些话题,在内容创作时可以做出预测。
返回的关联规则数以万计,笔者仅选取的置信度(confidence_threshold)阈值为1.0且具有一定趣味性的话题关联规则:
- (‘时尚’, ‘演艺明星’, ‘电影’) –> ((‘职业发展’, ‘职场’), 1.0)
- (‘地理学’, ‘天文学’, ‘生物学’, ‘职场’, ‘自然科学’) –> ((‘物理学’, ‘职业发展’), 1.0)
- (‘交通运输’, ‘建筑’, ‘电气工程’, ‘职业发展’, ‘职场’) –>((‘土木工程’, ‘工程学’, ‘航空航天’), 1.0)
- (‘数码产品’, ‘职场’, ‘高等教育’) –>((‘摄影器材’, ‘职业发展’), 1.0)
- (‘流行音乐’, ‘演艺明星’, ‘音乐’) –> ((‘职业发展’, ‘职场’), 1.0)
- (‘旅行’, ‘演艺明星’, ‘电影’, ‘音乐’) –> ((‘职业发展’, ‘职场’), 1.0)
- (‘流行音乐’, ‘演艺明星’, ‘社会心理学’, ‘音乐’) –>((‘职业发展’, ‘职场’), 1.0)
- (‘地理学’,’手机游戏’,’文学’,’流行音乐’, ‘经济’, ‘航空航天’) –>((‘健身’, ‘历史’, ‘土木工程’, ‘工程学’, ‘摄影’, ‘机械’, ‘自然科学’, ‘装修’, ‘财务’), 1.0)
结果有了,那么我们该如何解读上述结果呢?
举个例子,比如示例的最后一条,可以这样理解:在这25W+用户中,在支持度为100的前提下,所有同时关注了’地理学’、’手机游戏’、’文学’、’流行音乐’、 ‘经济’、 ‘航空航天’等话题的用户,他们有100%的可能性会同时关注’健身’、 ‘历史’、 ‘土木工程’、’工程学’、’摄影’、 ‘机械’、’自然科学’、’装修’、’财务’等话题。
那么,发现这些话题关联规律有什么实际意义呢?
3)话题关联度的意义
a. 用于发现潜在需求当我们在浏览器中输入”social listening”时,浏览器自动弹出如”social listening 社会化营销”,”social listening 文本挖掘”等备选记录,我们每每都会感叹浏览器的智能,其实这里的奥秘就是频繁项集。
也就是说,在大量的用户搜索记录中,”social listening”和”社会化营销”、”social listening”和”文本挖掘”共同出现在了大多数的搜索记录中。同理,”社会化营销”和”文本挖掘”也频繁的共同出现在搜索记录中。
无论是基于搜索的共现词还是基于话题tag的共现词,都能在一定程度上挖掘出用户的(潜在)需求。
b. 基于话题发现热点信息
大量频繁出现的话题很有可能是内涵相近的内容,因而话题频繁集挖掘在某种程度上也就是话题聚类,聚类成员数较多的类别也就是热门话题。
c. 用于制定内容营销策略
如果笔者要写数据分析相关的文章,哪怕再硬、再干的文章,如果不结合案例或者场景来写,恐怕也不会有读者愿意看,这时候就需要加入些“软”一些的ingredients了。比如笔者之前的拙作(《从3500种中西药品的说明书中发现:中药名称爱用“精、灵、宝”》、《用文本挖掘剖析近5万首<全唐诗>》、《【Social listening实操】从社交媒体传播和文本挖掘角度解读<欢乐颂2>》等),正是加入了一些“软”的元素(即趣味性的分析背景,这里就是贴近现实生活的话题),才得到了可观的阅读量和互动量。
上述话题关联度的挖掘在数量上还不够精确和直观,在本节剩下的两个部分将对关联度进行数值化度量和可视化呈现。
(3)用Word2vec量化话题之间的关联性
用户一般会关注多个话题,采集下来后,话题标签之间是半角逗号区隔,经切分后就形成了一系列的字符串list([‘交易所’,’股票’,’文学’,’张佳玮(人物)’,’伊万卡·川普(Ivanka_Trump)’,’阅读’,’京东’,’清华大学’,’经济学’]),可采用Word2vec进行挖掘。Word2ve可以挖掘话题之间的关联度、共现关系,不仅能够挖掘出深层次的词汇共现关系,而且还能量化出这种关联关系。
1)相似话题识别
出现“数据分析”这一话题的情况下,在其附近最有可能出现的其他话题按照关联度依次是:
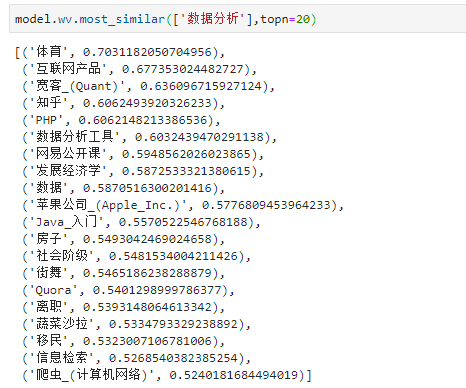
根据上述结果,还是比较符合直觉的:
- 在体育界,数据分析技术变得越来越重要,或者是从事数据分析的用户正值大好青春,爱好体育
- 互联网产品目前对数据分析这一技能的要求越高,以数据洞察驱动产品设计的理念深入人心
- 宽客是指一群靠数学模型分析金融市场的物理学家和数学家,他们相信数学的精确性是分析最复杂的人类活动的基础,还曾用分析神经系统的数学技巧来赚钱
……
给定上下文话题(头部和尾部的话题)作为输入,获得中间话题的概率分布:
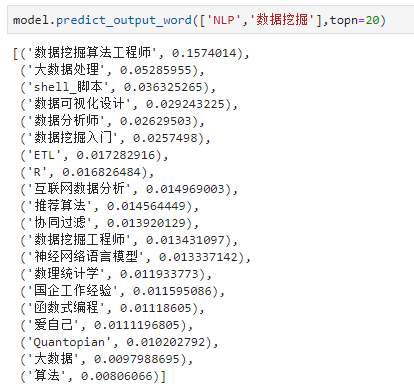
对于上述结果,可以这样理解:最开始关注“NLP”和最后关注“数据挖掘”话题的用户,在中间还最有可能关注“数据挖掘算法工程师”、“大数据处理”、“shell_脚本”等话题,不过它们的概率比较小。
下面,试着“揪出”、“舆情”、“数据挖掘 ”、“社会化营销”、“商业”、“文本挖掘”、“social_listening ”、“管理咨询” 、“NLP”等话题中的“异类”。

结果是’舆情’,笔者推测其差异大概反映在场景上 — 它主要的场景是在政务领域,很多时候是简单的数据汇总统计,缺乏对数据的深度提炼和对商业场景的贴合。
直接比较话题之间的相似度,代码和结果如下:

- ‘数据分析’和’机器学习’之间的话题相关度为:0.5158830285072327;
- ‘自然语言处理’和’文本挖掘’之间的话题相关度为:0.30275818705558777;
- ‘social_listening’和’市场营销’之间的话题相关度为:0.2506273090839386;
- ‘排球’和’管理咨询’之间的话题相关度为:0.006412103306502104。
上述结果不用做过多的解读,非常符合当下的实际。
上面谈到的是话题共现的量化,紧接着,我们再进行话题共现的可视化操作。
2)话题关联可视化呈现
笔者基于bokeh来绘制话题关联图,共现频率较高的话题将会紧挨在一起。
该可视话图可以使用鼠标进行拖动以及放大、缩小等操作。
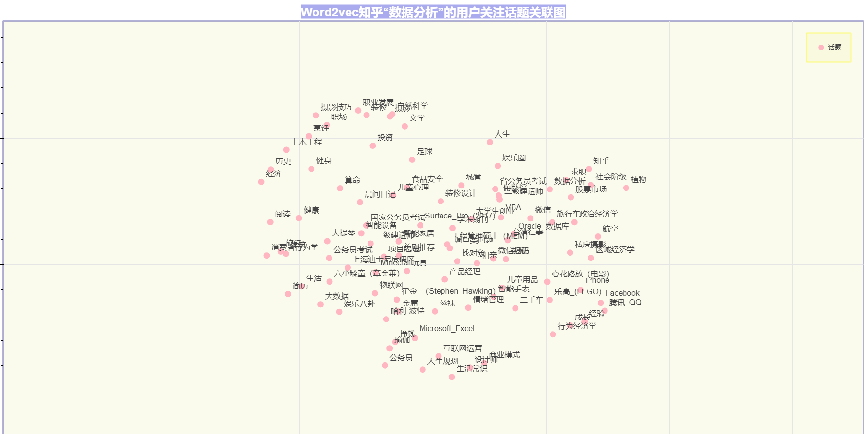
上面的图因为字体太小且紧凑,显示不清晰,试着放大展示其中部分话题区域:

上面的红圈中,“私房摄影”、“区域经济学”、“航空”、“心花路放(电影)”、“iPhone”、“乐高(LEGO)”、“Facebook”、“腾讯_QQ”、“经验”、“成长”、“行为经济学”等话题紧挨在一起,表示在这25W+数据分析相关的用户关注话题中,这些话题经常一起出现的频率较高。
对于上述结果,笔者目前还没有想到比较好的解释。在这里,笔者对“兴趣”进行深入一点的探讨:
“兴趣”是指个人从心理上对特定的“事物”、“活动”以及“人为对象”所产生的带有倾向性、选择性的态度、情绪、喜欢的想法。兴趣是以需要为基础产生的。需要有精神需要和物质需要,兴趣基于精神需要(如对科学、艺术和文化知识等)。人们若对某种事物或活动有需要,就会去接触、观察和从事这种事物的研究或参与这种活动。
笔者认为关注的话题代表了用户的阅读兴趣,而阅读兴趣这种特殊的兴趣爱好能在某种程度上反映出用户的某些心理特征。而这些看似“风马牛不相及”的关注话题,更能反映出用户比较复杂的心理特点。至于做何种分析比较恰当,留给感兴趣的热心读者,欢迎在后台给我留言~
3)话题间的“六度分隔”
下面,根据话题间的共现相关性,找出知乎“数据分析”相关用户关注话题集合中的任意两个话题之间的最短关系,也算是六度分隔理论的一种实践。
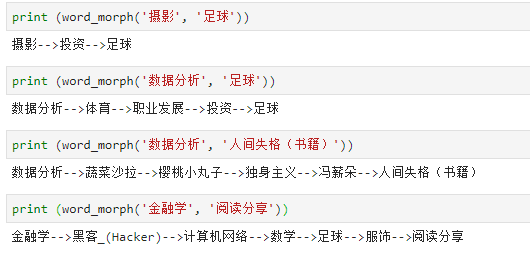
- 摄影–>投资–>足球
- 数据分析–>体育–>职业发展–>投资–>足球
- 数据分析–>蔬菜沙拉–>樱桃小丸子–>独身主义–>冯薪朵–>人间失格(书籍)
- 金融学–>黑客_(Hacker)–>计算机网络–>数学–>足球–>服饰–>阅读分享
这部分不做解释,留给读者来操作,欢迎在评论区写下你的分析,我们一起探讨~
好了,上面是话题部分的分析结果,下次分享的内容将是对16W+数据分析相关问题的内容分析,内容更精彩,敬请期待~
#专栏作家
苏格兰折耳喵(微信公众号:Social Listening与文本挖掘),人人都是产品经理专栏作家,数据PM一只,擅长数据分析和可视化表达,热衷于用数据发现洞察,指导实践。
本文原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自Unsplash,基于CC0协议















大哥,能给原码和数据集吗
写得好啊