
 起点课堂会员权益
起点课堂会员权益基于Python的搜索引擎检索日志数据分析
网络数据是沙地,数据分析的作用就是在一堆冗杂无序的沙地中找出产品有用的“金子”。

01 前言
数据——可以简单理解为人们动作行为的符号表示。信息技术的发展,使得计算机每时每刻记录着人们的数据,人们在计算机面前,早已经是“透明人”。
万物皆在运动,对于数据来说,也是一直在变化的。我们对数据进行分析,就是希望可以从不断变化的数据中发现规律、发现趋势,提炼有价值的内容。
好的数据是一座未被发掘的金矿,而好的数据分析报告,可以帮助经营管理者明确战略,不断优化和调整策略,也可以帮助产品经理更好地掌握产品运行情况,不断有针对性的升级优化产品,提升客户体验,增强用户粘性,确保产品用户和效益持续增长。
02 分析目的
不同领域有不同领域的分析目的。例如基金公司的数据分析,更多的是来对所投资股票的价值分析。电商公司的数据分析,会很关注漏斗的转化率。结合本文的实际案例分析,我们数据分析的目的,主要有以下几点:
- 验证我们的判断。例如:我们根据经验,判断一般晚上探索某个领域的知识会比较多,我们来验证自己的判断是否正确。
- 用户兴趣发现以及商机发现。例如:某个关键词检索很频繁,说明极有可能成为热点,提早进行针对于热点的准备,从而获得流量优势。
- 防范风险。例如:某个关键词在某个地区短时间内频率很高,那极有可能会存在区域风险。相关部门或企业,提早进行介入处置,化解风险,从而尽可能减少损失。
03 数据准备
既然是实践,就需要对真实的数据进行分析。
本文数据来自于搜狗实验室《搜索引擎用户查询日志(SogouQ)》(数据地址:http://www.sogou.com/labs/resource/q.php)。使用的搜狗实验室所提供的精简版数据,此数据包包含一天的检索数据,数据压缩包小为63MB,解压后数据包大小为144MB。
数据格式为:访问时间\t用户ID\t[查询词]\t该URL在返回结果中的排名\t用户点击的顺序号\t用户点击的URL。
其中,用户ID是根据用户使用浏览器访问搜索引擎时的Cookie信息自动赋值,即同一次使用浏览器输入的不同查询对应同一个用户ID。
数据样例如下:
00:00:00 2982199073774412 [360安全卫士] 8 3 download.it.com.cn/softweb/software/firewall/antivirus/20067/17938.html
在此主要是给大家形象地展示一下数据格式,更为详细的数据大家可以去搜狗实验室官网获得。
04 分析过程
1. 不同时段的检索情况
我们以小时为单位,共分24小时,来查看全天时段的用户检索情况。首先在Python程序中导入CSV文件,这个太基础了,就不在此多讲了。
由于源数据时间格式是“时:分:秒”格式,而我们是准备以每一小时为时段进行分析。为了便于操作,我们将源数据“时:分:秒”处理为仅保留小时。之后我们将数据格式化成DataFrame数据格式。使用groupby函数,对时间进行操作。使用size()对分组数据进行归集显示。
由于本文主要讲解思路,在此仅展示部分源代码。如果需要操作指点,可以关注我的微信公众号:佳佳原创。在公众号中留言,我看到后,第一时间会回复大家。部分源代码如下:
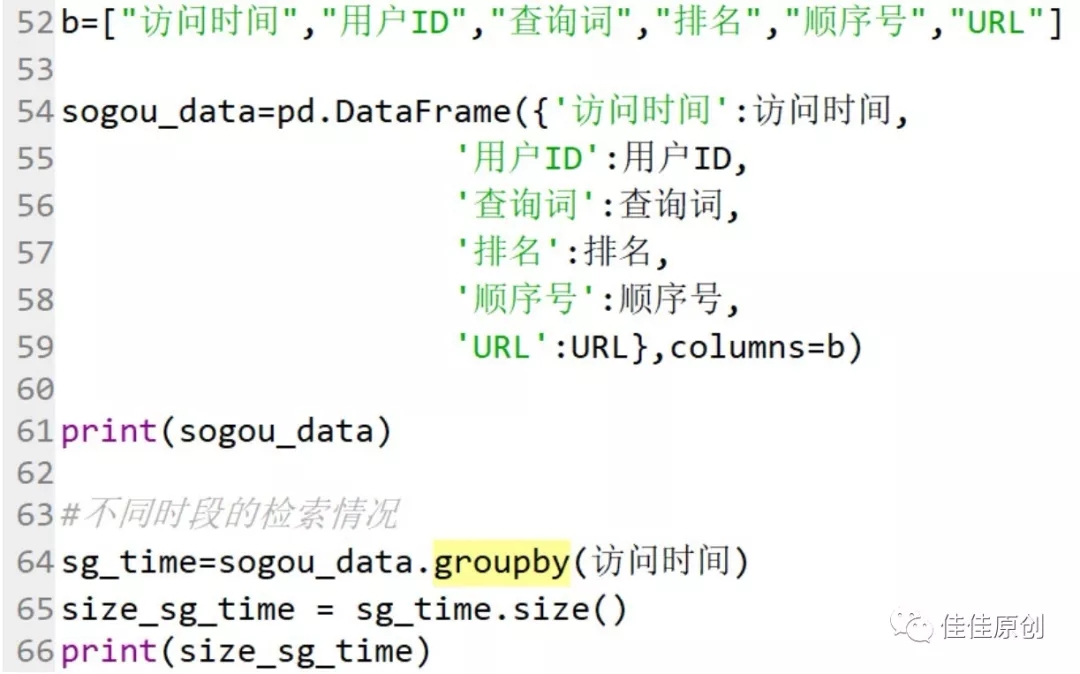
上图中的print( )函数主要用来看生成的数据。注释掉也可以。根据操作,生成相应数据,并根据数据生成分析折线图如下图所示:
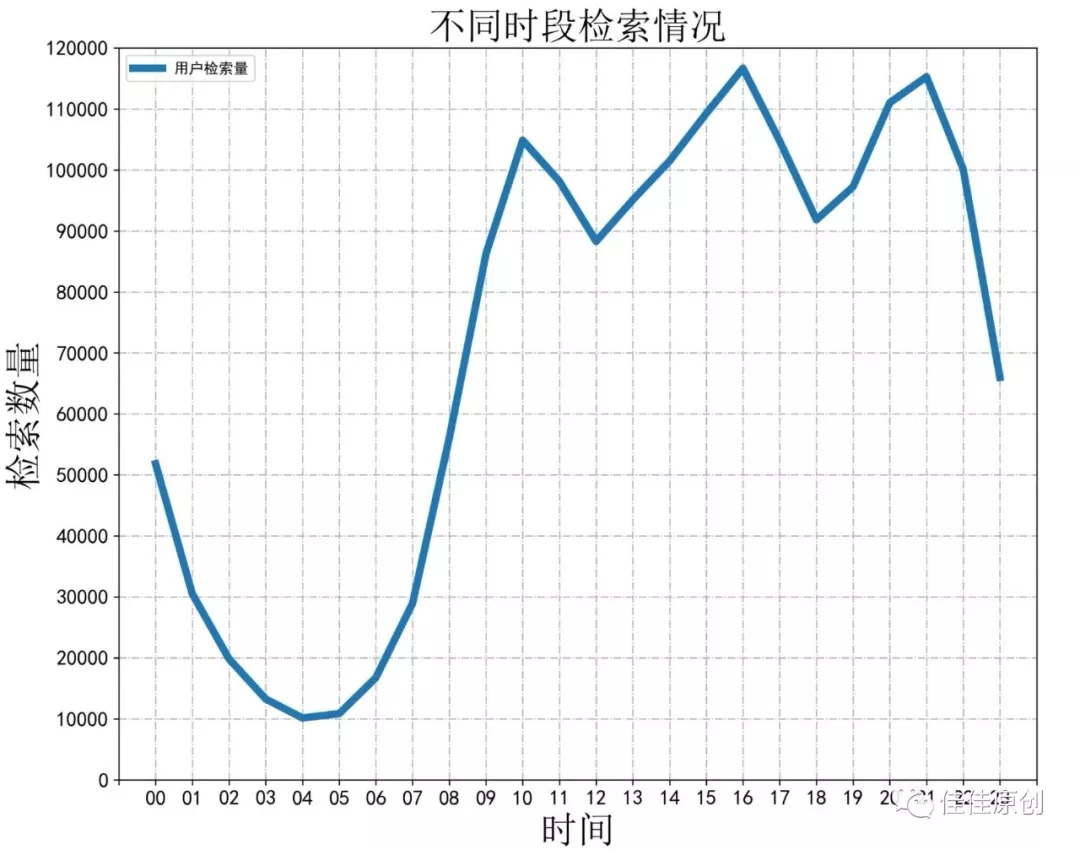
如果对于生成折线图有时需要不断微调,而每次生成数据运算时间较长,其实可以将生成的数据先保存起来,之后调整折线图元素的时候,直接使用结果数据就可以,不需要再重新计算数据,这样可以节约很多时间。
经过我们将数据图示化后,原本密密麻麻的数据显得更为清晰,我们可以方便直观地看出,用户在凌晨4点左右检索频次是最少的,而在下午16点左右检索频次最多,也侧面反应出了网民的上网习惯。
如果我们是广告商家,我们可以针对这种情况,对不同时段的广告进行有针对性的定价。而我们如果是需要进行广告投放,也知道哪个时段投放,广告的曝光率相对最高。
2. 不同用户的检索情况
接下来,我们再分析一下不同用户的检索情况,看一看哪些用户检索量比较大。
这个分析需要用到Python DataFrame中的count()操作,即:groupby(用户ID).count()。之后我们将新生成的数据再构建一个DataFrame,取排名前50的用户数据,做降序操作。部分源代码如下图所示:
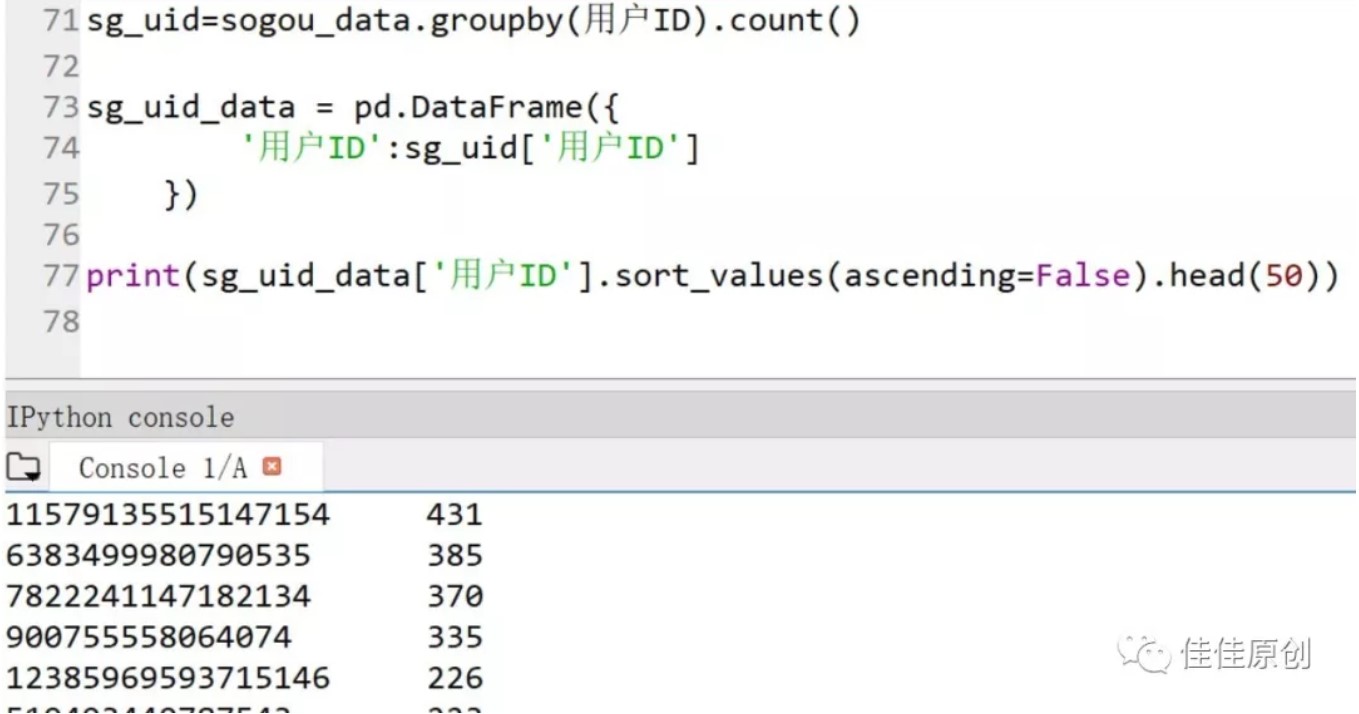
上图中Console中显示的数据就是当天检索量排名前50的用户。有兴趣的同学,可以到搜狗实验室官网上下载一下这个数据,查看一下检索量431的那位客户当天究竟检索了什么内容。一定是一位重度依赖网络的朋友。
具体访问了什么,我们稍后再看。经过数据分析,我们决定取排名前20的用户,用柱状图显示出他们的检索情况。选取20名用户主要原因是,一是为了图示美观,另一个是为了缩小数据范围,集中于几个用户进行分析,节约分析成本。排名前20的用户检索情况如下图所示:
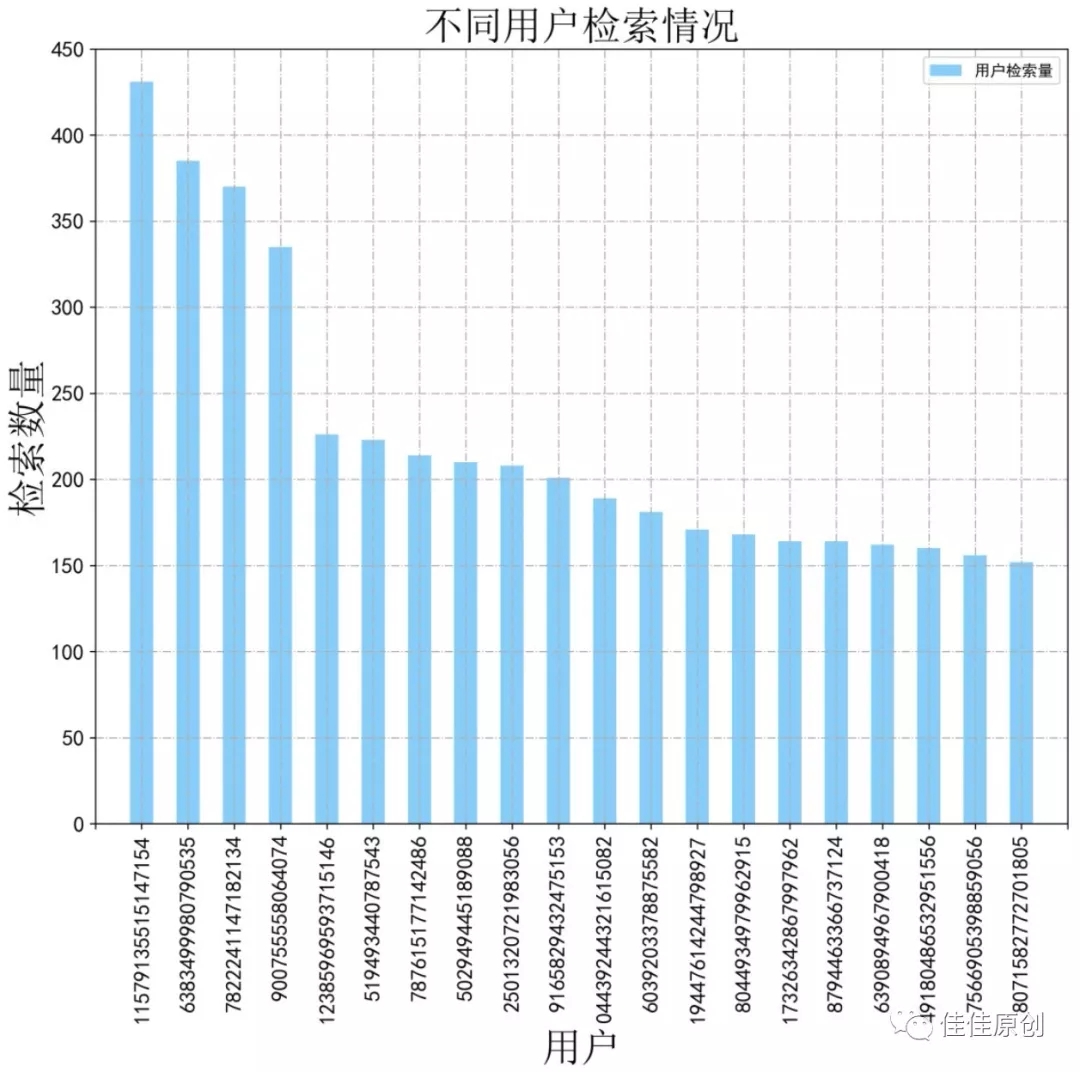
由于数据比较多,时间关系,我们接下来选取其中一个用户分析一下其检索数据。接下来进入下一环节。
3. 用户检索数据析
我们选取检索量最大的一个用户“11579135515147154”,分析一下他一天的检索情况。我们先看一下这个用户不同时段的检索量。
08 2
09 64
20 57
21 218
22 90
左侧是时间数据,右侧是检索量。
看来这个用户晚上21点的时候,检索的比较频繁。
我们再分析一下这个用户都检索了哪些内容。同时将此用户的检索词的检索量进行了倒序排列。如下所示:

由于数据据有限,我们也不知道这个用户的年龄、职业、性别。但感觉检索的内容倒是挺令人惊讶的。也客观的说明,每一个看似正常的人,都有不为人知的一面。
大家如果想深入分析,可以在搜狗实验室下载这个数据,结合本文提供的分析量排名前20的用户ID,直接在数据中检索一下这20名用户的搜索情况。
4. 不同关键词的检索情况
接下来我们以全天的视角,分析一下当天不同关键词的检索情况。基本分析思路是提取出当天所有关键词的数量,然后通过词频云图进行直观展示。
根据数据,我们生成词频信息,同样,为了便于观测,我们按词频数进行倒序排列。由于数据比较多,我们仅作部分展示。如下图所示:

为了词频云图的展示,我们需要引入“import collections”和“import wordcloud”这两个库。具体用法可以查阅相关资料,就不在此过多讲述了。
如果大家在使用过程中,有任何疑问,也可以随时咨询我。我看到了,会第一时间回复大家。由于大部分检索词还是挺“奇怪”的,所以就大家不要看的那么清晰了,知道大体分析思路就可以。根据词频,生成词频云图,如下图所示:

05 分析总结
有时候对方提供的数据或多或少导入的时候,会有一些问题,例如:和我们的处理格式有些差异,编码问题。这就需要我们在数据分析前,先要整理数据,把数据导入时的异常处理掉,同时把可能存在的一些影响分析的垃圾数据解决掉。
俗话说”Rubbish in, rubbish out”。所以在数据分析前,确保数据的真实、可靠、有效,是非常有必要而且非常重要的一个步骤。
对于数据分析而言,不同领域、不同场景、不同目标,数据分析的方式方法有所不同,这就需要我们对症下药。互联网企业、电商网站,更多的是分析用户留存,转化率,访问轨迹。而金融行业的企业,像基金公司,更多的是做时序分析,趋势分析。本文的分析,更多的是通过数据提取,可视化,发现一些潜在的情况。
而通过我们本次对用户检索数据的分析,给人最直观的一种感觉就是网络平台就像是一个浓缩的社会,虽然大家在网上检索,谁也不认识谁,但在某种程度上却有一些联系。而在这个平台上,有好人,也有坏人,侧面也在反应的人们在日常生活中的千姿百态。也正是因为网络检索的匿名性,反而个人行为没有伪装,也体现了更为真实的个人。从这个角度上讲,网络数据分析结果的效果,往往比线下数据分析要好。
虽然现在注重隐私保护,但如果出于公共安全的目的,其实可以进行相关数据的分析与预警,提早发现可能发生的违法犯罪情况。例如:如果一个人频繁的检索如何绑架等恶性词汇,从一定程度上也客观反应了其心理状态,再结合其行动轨迹、购物记录,结合评分卡,综合判断此人发生违法犯罪的概率,提早进行预防,减少对公共安全损害的发生风险。
科技是一把双刃剑,要想真正发挥科技的价值,需要我们更为合理科学的掌握和使用科技,从而使科技真正为人们服务。企业或是个人价值观的好与坏,也就决定了对数据分析结果价值的好与坏。不论怎样,如果每个企业、每个人都能将“不作恶”作为其行为准则的底线,这个世界便会美好许多。
原创不易,如果大家觉得本文对您有帮助,请多多转发,或者点击作者进行打赏。感谢大家阅读~
作者:王佳亮,中国计算机学会(CCF)会员。微信公众号:佳佳原创
本文由 @佳佳原创 原创发布于人人都是产品经理,未经许可,禁止转载
题图来自Unspalsh, 基于CC0协议









你做的是什么类型的PM呢,数据PM吗?我想问下,数据PM日常工作要打代码吗?我一个非程序员经验,想通过自学python转数据pm的非计算机专业的理科生,这种路径可行吗~
路径可行~学些代码会强化逻辑思维,可以为你的工作锦上添花~
我的评论没展示出来吗~