
 起点课堂会员权益
起点课堂会员权益产品经理如何有效避开数据分析常见的坑?
对产品经理来说,以各项指标为对象展开数据分析,并做出对应应对策略是家常便饭的一件事。不过,在数据分析的时候,我们总会遇到数据异常或者数据对不上的问题,而本文就分享了如何从源头规避这些坑的方法。

做数据统计和分析,是一项严密和逻辑性很强的工作。如果平时不多加注意,就会出现一些不好解释的问题。
比如发现报表数据对不上或者有些数据涨跌的原因无从解释,这时不仅需要耗费很多精力去排查,还有可能会误导我们后续的迭代,作出一些不正确的决策。
下面我就重点讲讲,怎么从源头来有效规避这些坑。
01 数据埋点的坑:埋点不全面和上报逻辑不一致
1. 数据埋点不全面、范围错误或上报逻辑不准确
(1)数据埋点不全面
就是有遗漏的埋点,这个可能直接导致重要的数据没有办法采集,是需要尽快排查并完成补救的,否则会对数据分析影响较大。
埋点不全通常包括两方面:
1)点位缺失
比如某个页面、某个按钮的点击位没有加等,这个会造成数据缺失,必须重新打点才能补救;
2)参数遗漏
比如少加一个渠道的参数,这个只是对数据的对维度分析有影响;
(2)取数据范围错误
比如统计活动页面的发帖,如果无法区分内容是来自活动页面那就没法做后续的分析。
(3)上报逻辑不准确或不一致
比如发布按钮是点击就上报,还是发布成功时再计数?点赞是生效才计算,还是只要点击都算?这些上报逻辑的确定对后续的数据分析有很大影响,一旦不一致就会出现数据对不上的问题。
2. 如何规避埋点问题,确保打点完整和上报统一
这块需要建立完整的埋点实施流程和打点模版。
(1)确立埋点实施的流程和规范化操作
在产品需求方案完成后必须开始设计埋点方案,而不能拖到开发阶段,具体流程和事项包括:
- 明确当前版本的核心数据指标,做好指标定义,并梳理对应的核心页面和功能点;
- 埋点事件设计,明确事件类型(访问、曝光、点击),事件点位以及细分维度(来源、用户设备)等;
- 前端或服务端打点拉通和实施,确定相应规范;
- 测试排查机制和上线验证;
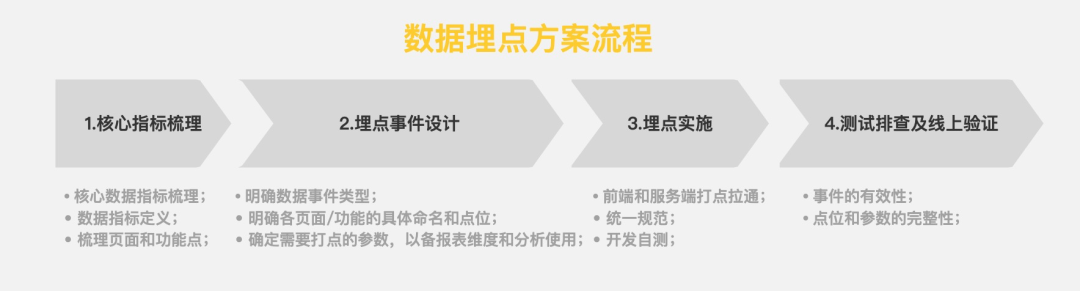
数据埋点流程
(2)建立打点模板,做好聚类、参数命名和规则定义等
进行具体的埋点设计,需要建立项目匹配的埋点模板,做好规范化管理。
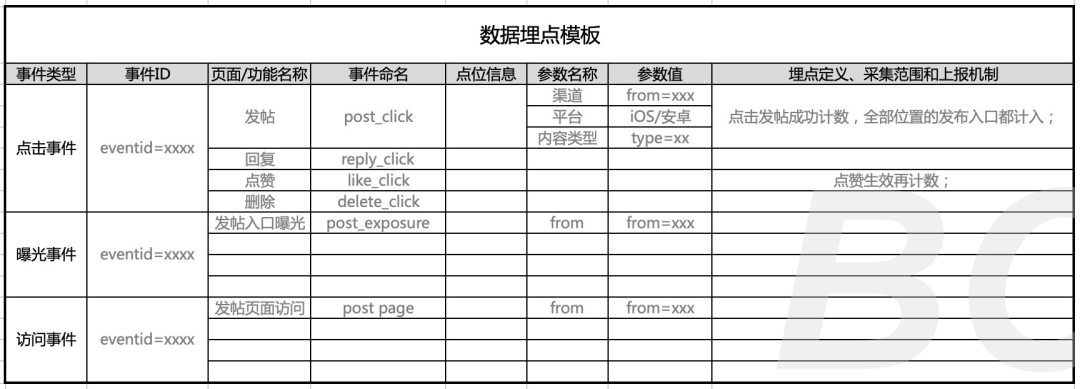
数据埋点模板
02 建报表的坑:数据统计口径错误或者不一致
1. 数据统计口径不一致通常表现为:数据来源不一致、数据指标定义和公式拆解不准确
1)首先,口径不一致最普遍的坑,就是取数据的来源不一致
这点很好理解,通常我们建报表都要和BI同学沟通数据是从哪里取,是从前端的打点取还是服务端的表里取。如果前期没有明确出来,后面很可能造成数据上来源不一致的问题。
比如社区的发帖数据,发帖UV和发帖率,如果取前端数据可能会不准确,而服务端更精准一些。
如果现有报表存在不一致,需要立即修改。
2)其次,是数据指标定义不对
比如内容社区,拿对内容生产这个指标的定义来说,是否应该包含评论内容必须明确好。不能说内容生产包含评论,互动指标里也有评论,那就有点自欺欺人了。
比如对业务新用户的定义,很多非app的业务很难以注册和激活app来定义新用户的,这个时候就需要明确的定义,是从来没有使用过,还是某个时期内,如一年内新访问业务的用户;
再比如流失用户,我们通常定义可能是1个月甚至更短时间没有启动app就算了,但是对于低频的应用,或者像教育类app存在寒暑假,你很难这么去定义;
3)还有可能,是数据指标公式拆解不对
比如人均发帖究竟应该是发帖量比上整体的UV还是应该比上发帖UV?如果你比上前者你就发现人均发帖量很小,你就会很困惑,困惑就是因为我们的公式错了。我们其实要的是发帖这些人,平均会发多少条。
通常我们的数据指标公式,比如:
- 访问渗透率=当前页面的访问UV/上一页面的访问UV;
- 点击渗透率=当前位置的点击UV/当前页面的访问UV;
- 参与率=活动参与的UV/当前页面的访问UV;
- 人均访问=访问PV/访问UV
- 人均发布=发布PV/发布UV
2. 如何规避?确定数据来源,明确数据指标的定义以及换算公式
针对数据统计口径容易出现的问题,我的解法是:
1)在前期建报表需求的时候,一定要梳理好指标项,并对指标做好明确的定义,明确数据来源,和对应的换算公式。
2)建数据报表前期一定做好统计口径的沟通,明确哪一部分的数据从哪里取?是取前端的打点还是取服务端的数据;
通常的原则是:页面展现、点击、本地播放或者停留时长等数据可以取前端数据,数据上报依赖网络,且用户删除自己操作记录时也会有数据丢失的情况,所以前端打点存在延迟和不准确、不完整的缺点;
而安装数据、内容生产、互动数据可以使用服务端数据,更为精准;实时性好,不存在延时上报。
3)做好公示拆解和定义。如果公式错误,在数据分析时就会出现归因错误,所以一定要在前期规避。
这里我提供一份建表的需求模板,通常这样完整提供给BI最保险。
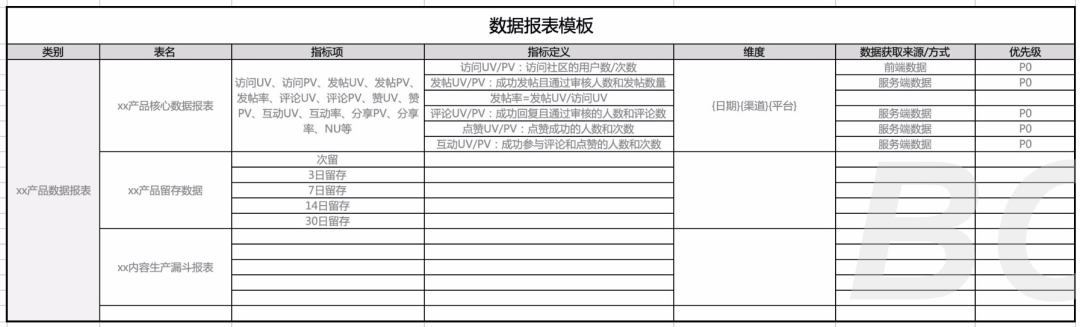
数据报表需求模板
03 数据分析的坑:数据指标看绝对值,忽略链路和技术因素
坑1:数据指标看绝对值,对比也看绝对差值
看绝对值的坑主要表现为:指标观察看绝对值和数据间对比看绝对差值。这块应该改为指标优先侧重比率指标。另外,做数据对比,一方面要使用比率指标来看产品的效果。
比如内容社区的发帖数,如果要看这个指标的情况,不论是前后数据对比还是设立分桶做同步对比,因为漏斗的上一层(访问UV)肯定存在不一致的情况,所以此时使用发帖率来评估效果才是更准确的。
并且,看发帖率的涨跌对比,也要看相对比值,而不是看绝对差值。
比如之前的发帖率2.4%,现在的发帖率是1.2%,从绝对值来看不多啊,才降了1.2个百分点,但是实际降了100%;
坑2:只针对单一指标进行分析
这里的坑是将指标分开单一看,忽略多环节或者链路指标的分析,这时候其实根本不明白数据是因为哪里才发生了变化。
还是以内容社区产品为例,比如我们要看回复框的发帖成功率,你会发现在评论详情页的回复框的发布成功率比帖子详情页回复框的发布成功率要高。
但其实这并不能证明后面的回复框就好,其实回复框样式通常是一样的,只是因为进入评论详情页且要评论的用户忠诚度更高,且真有评论的需求。
并且有时所说总指标看是涨的,但漏斗某一指标却跌了,所以数据分析时整体链路上的指标都是需要我们关注的。
可以说只通过对单一数据指标的对比,通常是无效的。我们需要兼顾多种因素以及评估整个功能链路或者漏斗模型的数据指标情况。
坑3:没有考虑技术因素带来的波动等
有些数据波动可能是由于网络或数据接口等技术原因,对打点造成的影响,这块需要考虑并作出优化实验;
比如我之前做ab实验时,发现新版的留存就是比旧版要低,但是低的幅度很小,都是在1%以内。
按理说新版的体验比旧版要好很多,从用户定性反馈和访问、生产、消费等定量数据指标都能看出来。但唯独留存略低,经过排查发现,新版的首页的接口数量增加了,请求时长变长,页面打开成功率降低,造成新版留存略低。
所以整体上,对于微小的波动如果确实找不到原因可以忽略,但是对于大的波动一定要考虑技术等因素。
04 小结

数据统计和分析的避坑卡片
总之,在数据统计和分析时,我们只有有效避开这些常见的坑,才能更好得出我们想要的分析结果,指导我们的后续迭代。
#专栏作家#
阿外,微信公众号:波悟馆,人人都是产品经理专栏作家。10年互联网产品经历,关注社交/教育和新消费领域,聚焦行业分析和产品力建设。
本文原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


