
 起点课堂会员权益
起点课堂会员权益数据产品指北:数据平台
数据平台其实是个概括的词,泛指企业中的数据环境、数据形态和数据架构等内容。而本文就跟大家详细介绍这些内容。

数据环境与数据形态
数据环境指的是数据存储、处理、转换所处的物理环境,例如生产环境、分析环境和测试环境等。
生产环境是生产应用和系统实时运行所处的环境,其中的数据是会实时变化的。
分析环境是与生产环境解耦的一个数据环境,在数据环境中对数据进行分析,不会影响生产环境的正常运行。分析环境中的数据来源于生产环境中的“快照”,因此本质上是离线的数据。
为保证分析环境的作业不对生产环境造成影响,我们应该避免数据直连的方式,即将原始数据直接从生产系统导入分析系统的紧耦合方式。这种方式在数据量较小时可能不会出现问题,但当数据量增大后,数据直连的弊端便会逐渐展现。主要体现在双方环境的互相影响、安全上的隐患、平台扩展性差等方面。因此更合理的办法是在生产环境和分析环境之间设置数据缓冲区,作为中转从各个系统接收原始数据并暂存,经过ETL后导入分析环境。
至此,根据数据所处环境,可将数据定义为3种基本形态:生产数据、原始数据和分析数据。数据和其所处环境之间的联系如下图所示。
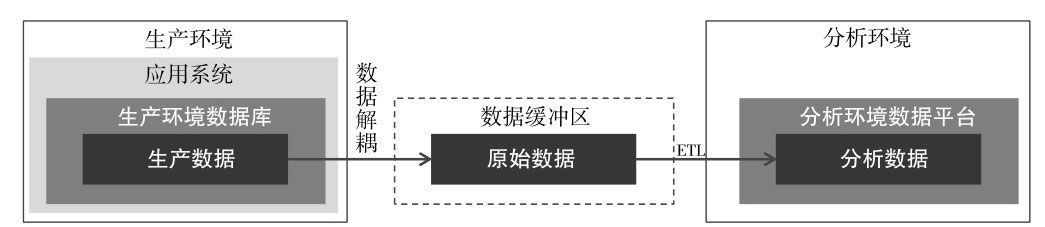
数据形态及所处环境之间关系
1. 生产数据
生产数据是动态的,会随着业务的变化而变化,例如用户订单状态会因为用户、商户、物流等相关方的行为而发生变化。数据分析工作通常不会直接接触生产数据,相反,分析数据可能会转化成生产数据。例如用户标签数据,是通过分析数据构建的,但可能会形成画像、推荐等应用,从而转化为生产数据为业务提供服务。
2. 原始数据
原始数据由生产系统中的数据解耦而得到。解耦过程通常包括了数据脱敏、筛选、批量导出等。原始数据的存放应独立于生产环境和分析环境,以避免不同环境间的互相影响,也就是前面提到的数据缓冲区。
3. 分析数据
分析数据由原始数据经过ETL后得到。ETL(Extract-Transform-Load)是抽取-转换-加载的缩写,该过程会对原始数据进行清洗、转换,按照统一的标准将数据存储在分析环境中。例如去掉一些无效字段,对空值、异常值进行插补,对日期格式进行统一等操作,都会在ETL过程中完成。ETL过程还可能包含对数据的优化存储,以提升存储和读取效率,比如创建索引、分区、分表等。
对分析数据的存储、使用,需要依赖于数据平台,数据平台的性能对处理分析数据有决定性的影响。不同规模、类型的分析数据,也可能适用于不同的数据平台。
具体的数据流转方式可参考下图,数据缓冲区作为中转,一端连接了生产环境中的各类应用系统,另一端连接了分析环境中的各类数据平台。
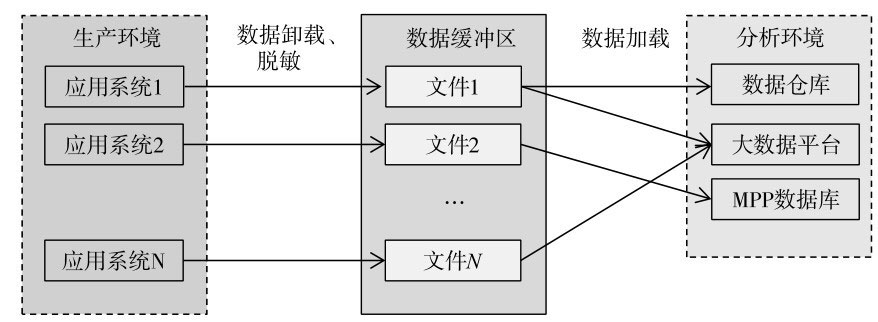
数据流转示例
数据平台
数据平台是存放分析数据的平台,也是支持数据分析和挖掘的底层平台。数据平台包括了我们最为熟悉的传统数据仓库,以及一些“现代化”的多种数据库产品。简化的数据平台架构图如下。
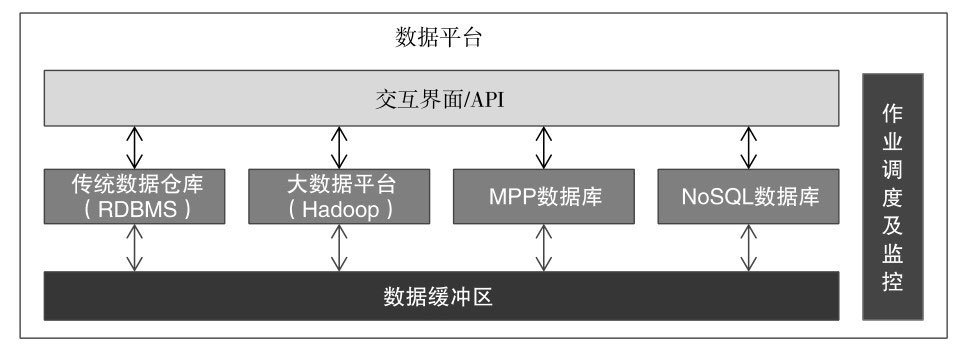
数据平台架构图
现代的数据平台融合了传统的数据仓库、大数据平台、MPP数据库、NoSQL数据库等多种数据产品。
从平台架构视角来看,数据缓冲区属于原始数据层,也叫ODS(Operational Data Store)层或贴源层。ODS层的数据粒度更细,能从微观反映细节的关键数据,例如用户订单交易数据。在数据仓库(Data Warehouse,DW)中又分为基础层、主题层和数据集市层。
1. 基础层
也有称DWD(Data Warehouse Detail)层,基础层对ODS层数据进行了清洗、转换(即前面提到的ETL过程),和轻度汇总。产出为数据明细、维度表、事实表等基础数据。例如订单表、商品列表以及一些日志表等。
2. 主题层
也有称DWS(Data Warehouse Service)层,主题层对数据按照一定维度或业务逻辑进行高度聚合,生成不同主题下的表。主题层一般已不存在具体的明细数据,所有数据按照主题进行了归集。例如零售行业,可能会根据业务分成用户主题、商品主题、销售主题等。
3. 数据集市
数据集市(Data Mart)也有称ADS(Application Data Store),数据集市将主题层和基础层的数据按照各业务的实际需求进行聚合,形成宽表或数据立方体(Cube),可直接供业务部门和数据分析团队使用。
数据集市中主要存在的是事实表(fact)和维度表(dimension)。
- 事实表中存放着业务的详细数据,例如订单、销售等业务数据。
- 维度表是围绕事实表建立的,存放着一些维度属性,定义了可以从哪些角度分析事实表,例如时间、地域、操作系统等维度。
数据集市中的数据结构一般有星型结构(star)和雪花结构(snow)。
星型结构由一个事实表和一组维表组成,每个维表都有一个维作为主键,所有这些维的主键组合成事实表的主键。使得事实表与每个维度表产生关联,事实表位于中央,维度表围绕在事实表周围。
雪花结构是在星型结构上的扩展,对一些维度表进一步层次化,将维度表扩展为事实表,并建立下一层的维度表。雪花结构更加符合数据库范式,减少数据冗余,但在数据分析时,操作也可能更复杂。下方是星型结构和雪花结构的对比。
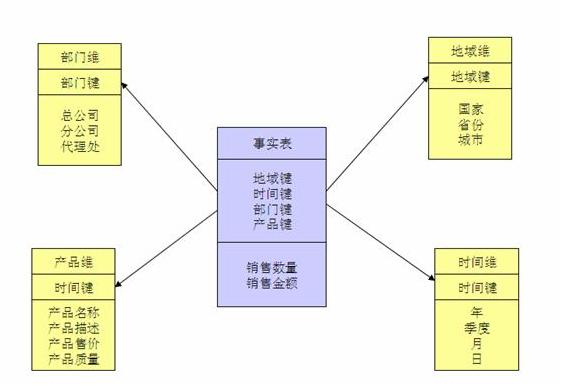
星型结构
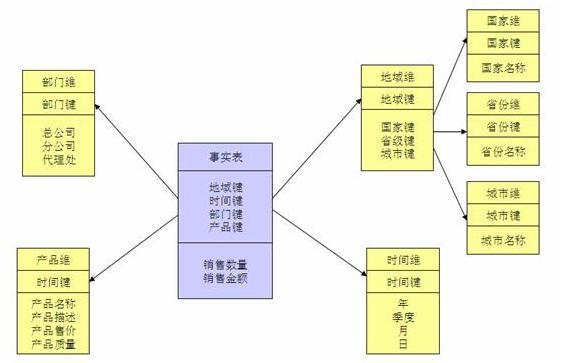
雪花结构
不同资料,以及不同企业内可能对上述内容的名称、缩写等有不同的定义,这个不用纠结,关键是理解每层所代表的具体含义和作用。
Hadoop扫盲
Hadoop作为目前被广泛应用于大数据平台开发的基础架构,有必要单独了解。Hadoop本身是用于大数据存储、计算、分析的分布式存储系统和分布式计算框架。下图是其核心组件架构。

大数据平台核心组件
Hadoop的核心模块提供的是离线、批量的计算,本身并不适合强实时环境。实时计算需要结合相关组件,如Spark、Storm等,扩展后的Hadoop平台具备一定的实时处理能力。下面简单介绍下相关核心组件。
1.HDFS
HDFS(Hadoop Distributed File System)是一套分布式的文件系统,是Hadoop平台的文件基础。HDFS适合存储大批量的数据(PB级),但不适合低延迟场景,也不适合存储大量小文件。HDFS主要解决的是文件实际存储的问题。
2.MapReduce
MapReduce是Hadoop平台的分布式计算框架,其采用“分而治之”的思想,将一个可拆解的任务分发给多个计算节点进行计算,最后合并计算结果。因此MapReduce中包含了两个部分:Map阶段和Reduce阶段(整个过程还可能包括Split、Shuffle等阶段)。参考下图,以经典的单词统计任务为例。可以看出Map阶段主要完成具体的分工和简单的计数,Reduce阶段完成最终的计算任务,即单词数累加。
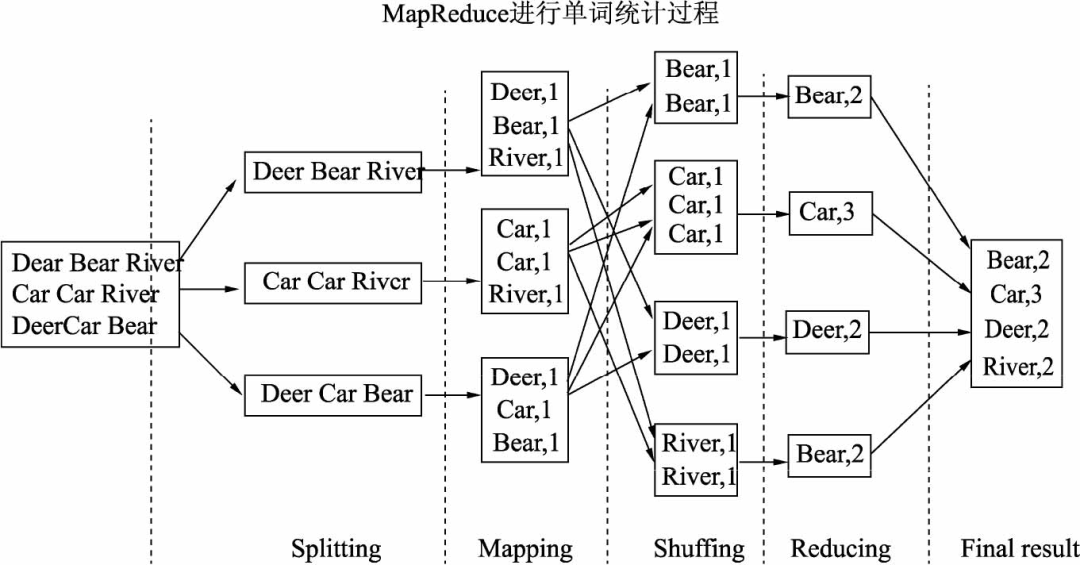
MapReduce执行过程
MapReduce主要用于离线的海量数据(PB级以上)计算工作。
3.HBase
HBase是基于HDFS的列式存储、非关系型(NoSQL)、分布式数据库,HBase具有高可用、高性能、列存储、实时读写等特点。NoSQL被解释为Not Only SQL,不仅仅是SQL,非关系型数据库不以SQL作为主要访问语言。其较关系型数据库主要在成本、查询速度、存储格式、扩展性等方面的优势。列式存储是非关系型数据库中的一类,传统的关系型数据库按照行进行存储,而列式存储数据库按照每一列单独存储,仅查询所需的列,因此查询速度大幅提高。此类预备知识,在此就不做过多延伸了。
利用HBase的特性,可以在廉价的服务器上搭建一套大规模的存储集群。
HDFS、MapReduce和HBase被称为Hadoop的三驾马车,是其最主要的构成。最后在简单介绍下其他常用组件,作为补充了解。包括了数据采集传输、数据存储、数据计算、数据分析表达和系统管理几个方面。
1. 数据采集传输类
1)Flume
针对非结构化的海量日志的采集工具,主要用于收集数据到HDFS。
2)Sqoop
针对在Hadoop和结构化数据存储(如关系型数据库)之间高效传输大批量数据的工具。主要用于从关系型数据库管理系统(如Oracle、MySQL)向Hadoop中(HDFS、Hive)导入数据,或从Hadoop中导入关系型数据库。
3)Kafk
可持久化的分布式消息队列,用于发布订阅消息的系统。可与流式框架(如Storm)组合使用,完成实时数据的传输处理。
2. 数据存储类
1)Hive
Hadoop的数据仓库框架,基于MapReduce封装。其将存储在HDFS的文件映射成我们熟悉的数据表,并提供类SQL(Hive SQL/HQL)语句进行数据表操作。是使用Hadoop平台数据仓库的必备技能。
2)Memcached
基于Key-Value的、高性能、分布式内存对象缓存系统,解决了大数据量缓存的问题,可在内存中缓存数据查询结果。
3)Redis
基于Key-Value的、可持久化的日志型内存数据库。Redis与Memcached类似,但支持更多的存储类型。另外,Redis可以将内存中的数据写入硬盘中,做持久化的保存。也可以设置key的过期时间,过期自动删除缓存。
3.数据计算类
1)Spark
不以MapReduce为执行引擎、基于内存计算的数据处理框架,用于大数据分析处理的集群计算系统。相比于MapReduce主要处理离线数据,Spark可以进行实时流式数据的分析处理。同时,其在内存中存储工作数据集的特点使其性能领先于MapReduce,对内存的消耗自然也较大。当任务对实时性要求较高时,可考虑选择Spark。
2)Storm
全内存计算的流式计算框架,定位是分布式实时计算系统。可处理源源不断流入的数据,来一条数据处理一条,是真正的纯实时。
3)Flink
针对流数据+批数据的计算框架。把批数据看作流数据的一种特例,延迟性较低(毫秒级),且能够保证消息传输不丢失不重复。
4.数据分析及可视化
1)Zeppelin
数据分析工具,包含了大数据分析和可视化功能,可以通过Web页面新建Notebook来完成数据的查询、分析和导出。
2)ELK
是ElasticSearch, Logstash, Kibana的统称,其是一套实时数据收集,存储,索引,检索,统计分析及可视化的解决方案。ElasticSearch是一个分布式存储及检索引擎,可快速实时地存储和查询数据,常用于快速检索内容。Logstash是一个收集实时流式数据(例如日志)的数据收集引擎,可用于接收、处理和转发日志。Kibana是一个数据分析和可视化的平台。可对ElasticSearch索引中存储的数据进行搜索和查询,并实现高级数据分析和可视化功能。最新版本已经改名为Elastic Stack,并加入了采集数据的Beats项目
5.系统管理
1)Zookeeper
是一个分布式协调服务,为应用提供统一命名、配置维护、域名服务、分布式同步等一致性服务。
2)YARN
是Hadoop的集群资源管理系统。可作为框架管理器,对计算框架进行管理和资源调度,例如MapReduce、Spark、Storm和Flink等。
数据平台篇对于非技术出身的产品及相关人员,阅读起来会感觉非常枯燥,学习和理解也确实有一定难度。但如果能对相关知识进行充分了解,将在未来的数据工作中起到很大帮助,在与技术同学沟通时也会更加顺畅。所以还是建议硬着头皮啃下来的。
数据平台篇到此结束。
作者:Rowan;公众号:罗老师别这样
本文由 @Rowan 原创发布于人人都是产品经理,未经许可,禁止转载
题图来自Unsplash,基于CC0协议









数据产品好难,好多关键词记得头晕脑胀
一ilskalkkallapmasjskdi
赞!
数据集市(ADS)层里面放的不是事实表和维度表吧,这里放的不是具体的业务需求的数据吗?事实表和维度表不是在第二层吗?
大家期待已久的《数据产品经理实战训练营》终于在起点学院(人人都是产品经理旗下教育机构)上线啦!
本课程非常适合新手数据产品经理,或者想要转岗的产品经理、数据分析师、研发、产品运营等人群。
课程会从基础概念,到核心技能,再通过典型数据分析平台的实战,帮助大家构建完整的知识体系,掌握数据产品经理的基本功。
学完后你会掌握怎么建指标体系、指标字典,如何设计数据埋点、保证数据质量,规划大数据分析平台等实际工作技能~
现在就添加空空老师(微信id:anne012520),咨询课程详情并领取福利优惠吧!