
 起点课堂会员权益
起点课堂会员权益以英国某电商平台的年销售数据为例,讲讲从数据清洗到可视化的整个流程怎么做
本文选取了英国某电商平台的年销售数据,从7个方面进行拆解和分析,完成了从数据清洗到可视化的一整套流程。

数据对于互联网+的商业模式存在巨大的价值,在业务中我们遇到的瓶颈往往通过数据分析,可以发现问题以及解决问题的对策。
本文对英国某电商平台的年销售数据进行分析:
一、报告梗概
1. 报告背景及目的
报告对在取数区间内的某电商平台内的所有交易记录进行了分析,平台主要销售独特的全时礼品,公司的许多客户都是批发商。为了更好地了解平台的经营状况,对销售数据进行分析,提出优化平台运营的策略,从而为平台创造更多价值。
1. 数据来源及说明
数据来源于UCI加州大学欧文分校机器学习库,是一个跨国数据集,其中包含2010年12月1日至2011年12月9日之间在英国注册的非商店在线零售的所有交易。
数据集含有8个字段,其含义如下:
- InvoiceNo: 6位的发票号,系统为每笔交易自动分配的6为不同的数字序列,如果是以c开头则表明该订单被取消。
- StockCode: 产品编号,每一种不同类别的商品对应不同的编号。
- Description: 对产品类别的描述。
- Quantity: 每次交易的某种产品的购买数量。
- InvoiceDate: 每笔交易产生时的日期时间。
- UnitPrice: 产品的单价,单位是英镑。
- CustomerID: 5位编码的客户id,每个客户的id都不相同。
- Country: 客户来源的国家。
二、数据预处理情况
1. 重复值处理
整个数据集有541909条数据,其中完全重复的数据有5268条,剔除后剩下536641条交易数据。
2. 缺失值处理
Description和CustomerID两个字段即商品描述和客户ID有缺失值,其中Descriptio缺失1454条,占总数据量的0.27%;CustomerID缺失135037行,占总数据量的25.2%。
因为商品描述是文本类型数据、对于本分析的结果不重要且缺失值占比非常小,所以不对其进行充填。
对于CustomerID,缺失量占到了总数居的四分之一且其本身对分析结果有重要意义,必须对其填充。在已验证当前CustomerID中没有0值的前提下,充填方式选择为用0代替缺失的CustomerID值。至此,缺失值处理完毕。
3. 异常值处理
基于业务常识,商品单价和商品数量应为正数,查看数据时发现这两种类型的异常值。
取出来查看后,发现由两种原因造成:
- 订单被取消即发票号以C开头的记录(共11761条);
- 坏账数据即发票号以A开头的记录(共2条)。
对于被取消的订单:由于没有发生实质交易,对平台的交易数据不存在影响故直接删除,但后续可以针对这部分数据可以尝试分析挖掘取消背后的原因;
对于坏账:数据量极小,且坏账金额也极其微小,在此也选择直接删除。
处理完异常值后,总的有效数据量为524878条。
4. 新增字段
为方便后续的时间序列分析,新增交易时间date字段(具体到日)和交易月份month字段;为方便后续的金额分析,新增交易金额SumCost字段(交易金额等于商品数量乘以商品单价)。
至此,数据预处理完成,截取部分有效数据如下所示:
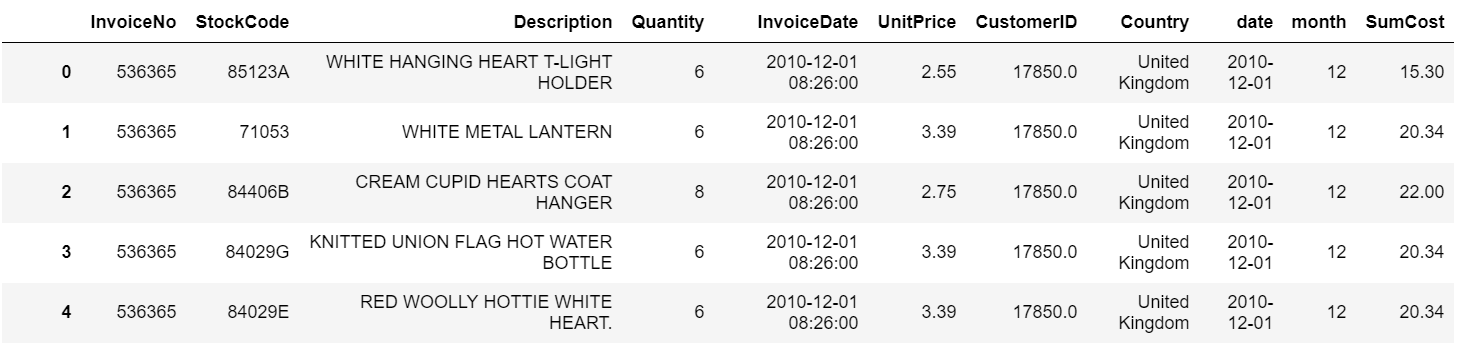
三、订单分析
1. 描述性分析
在订单层面,描述性的统计信息如下图:
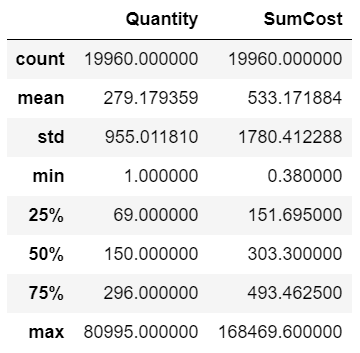
平台在此期间总共有19960笔有效订单,每笔平均购买279件商品,笔均消费533英镑,这两者都超过了各自的中位数水平。
说明订单总体差异很大,尤其是笔均消费超过了Q3分位数。
最大的一笔订单中购买了将近81000件商品,最大的单笔消费也高达168469——说明平台用户以批发商为主且存在购买力极强的客户。
2. 订单商品数量分布
剔除离群值,筛选出购买商品件数小于2000的订单绘制商品数量分布图如下:
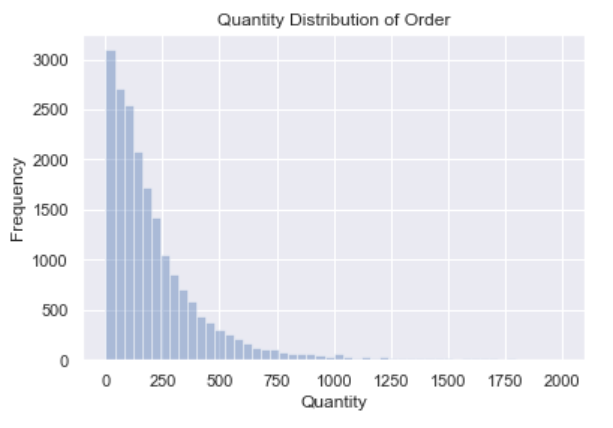
分布图呈现典型的长尾分布,大部分订单内的商品数量在250以内,大额数量订单稀少。
3. 订单金额分布
剔除离群值,筛选出单笔金额小于1000英镑的订单绘制金额分布图如下:
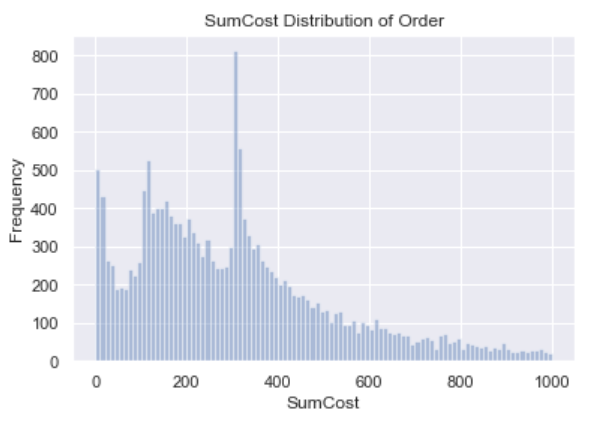
分布图有长尾趋势,金额主要分布在400英镑以内,说明绝大部分客户在该平台上的消费金额预算为400英镑以内,在350英镑左右出现了最多的订单数。
4. 分析小结
平台在2010年12月1日至2011年12月9日一年多的时间中产生有效交易19960笔,总销售额为8,887,209英镑,平均每日交易54笔,笔均购买量279件商品,笔均消费533英镑。
存在少数重要价值客户,此类用户购买力极强。作为批发型平台,要着重保持此类用户,用户维护、运营营销资源要向这些客户倾斜。
四、客户分析
在缺失值处理时,对于客户id缺失的数据,直接用0填充了空值,因此在客户层面分析的时候剔除了这部分数据。
1. 描述性分析
在客户层面,描述性统计信息如下:
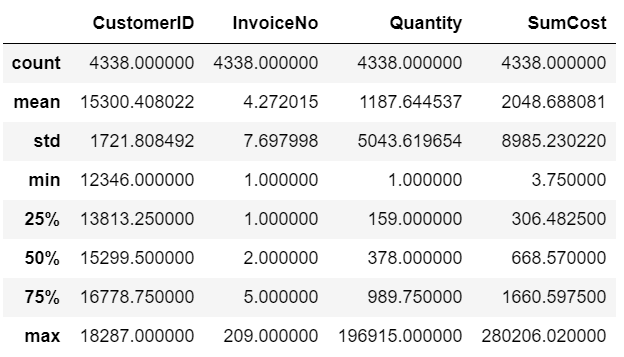
在4338个有效客户ID中:
- 平均每个客户消费4次,超过中位数,至少有25%的客户消费1次之后就流失了;
- 客均购买1187件商品,超过Q3分位数,最大的客户购买量达到了近197000件;
- 客均消费2048英镑,超过Q3分位数,最大的客户消费额达到280206。
2. 客户消费金额分布
剔除离群值,筛选出消费金额在6000英镑以下的客户绘制消费额分布图如下:
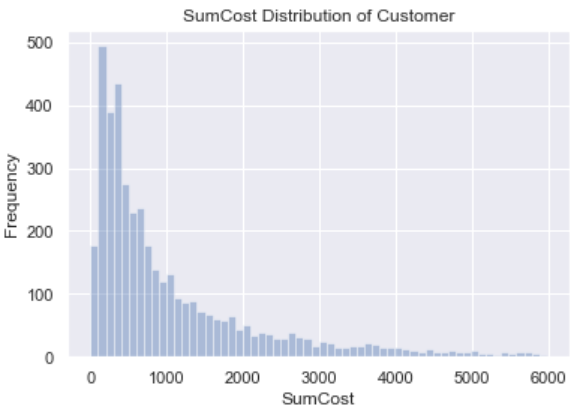
分布图呈现明显的长尾状,大部分客户的消费额在1000英镑以内,消费200英镑左右的客户最多。
3. 客户贡献程度
二八定律普遍存在于销售市场,因此绘制出每个客户的消费额占总销售额的占比图如下:
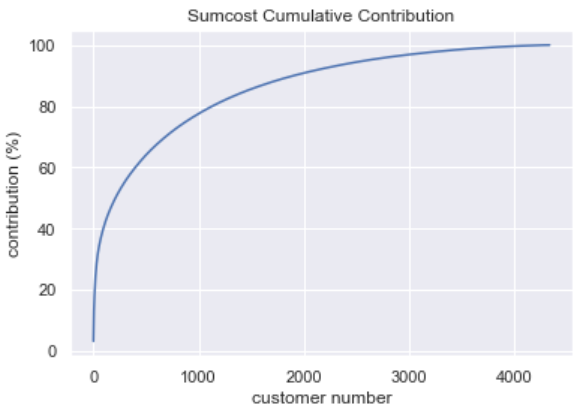
可以看出消费额前1000名的客户贡献了80%的销售额,也就是说平台所有客户中前20%的客户提供了80%的销售总额。
4. 消费额与购买量的关系
客户的消费额与购买量的关系可以对平台促销策略进行指导,左图绘制了所有的数据(包含离群值),右图为筛选出消费额5000英镑以下的数据:
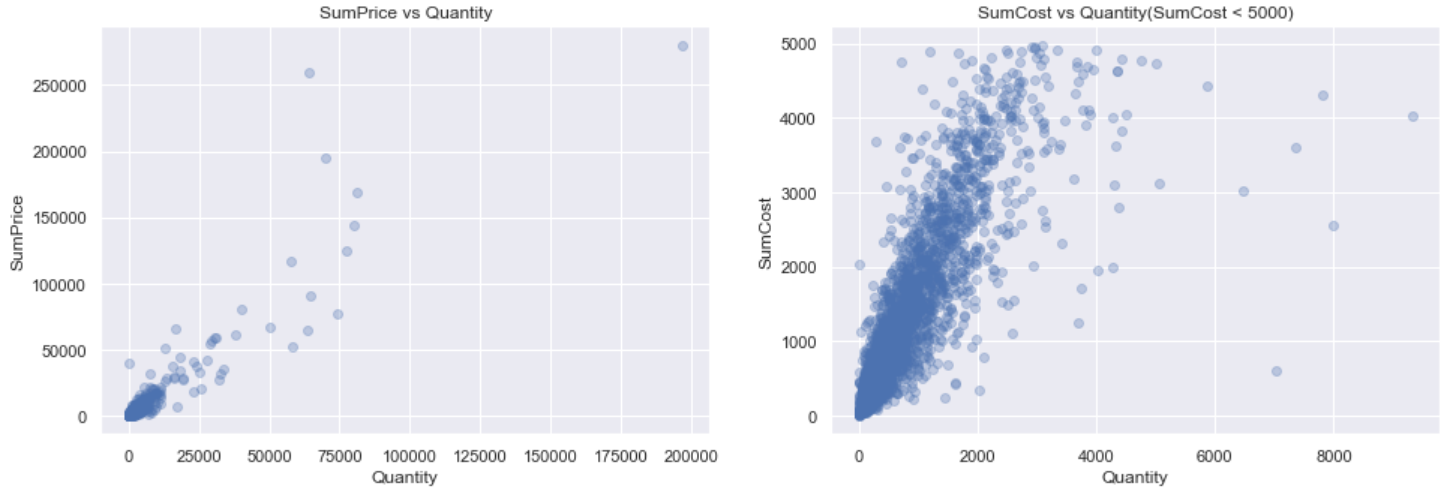
由图可知:消费额与客户的购买量成正比关系,且存在少数购买量和消费额数目都很巨大的客户。
在消费额小于5000英镑以内的客户,其消费额与购买量呈强正比关系;在3000件商品范围内,每向客户多销售1000件商品,销售额大概可以增加一倍。
5. 分析小结
平台的客户在这一年中平均会消费4次,客均购买1187件商品,客均消费2048英镑。
但是值得注意的是有四分之一以上的客户只消费了一次就直接流失掉了,如果能够保持这些客户,保守估计年销售额可以增加2,400,000到3,000,000英镑,接近全年销售额的三分之一。
平台的经营要注重新客的留存率,对于长时间没有复购的客户要积极联系,采取相应的唤回措施。
五、商品分析
平台对每个客户的报价并不一样。在处理时,采取平均的方法,即:该件商品的销售总额除以该件商品的销售数量来定义每件商品的单价。
1. 价格分布
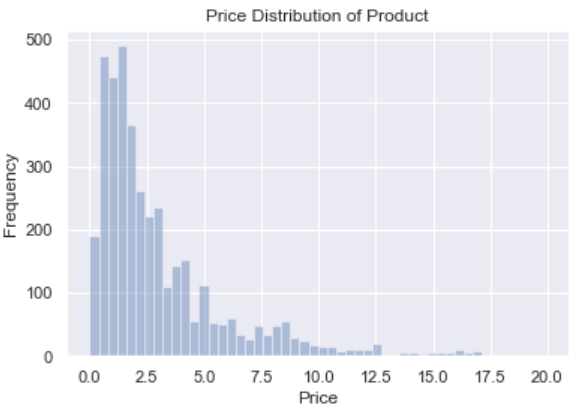
剔除离群值后,发现平台商品价格大部分低于3英镑。
2. 价格-销量关系
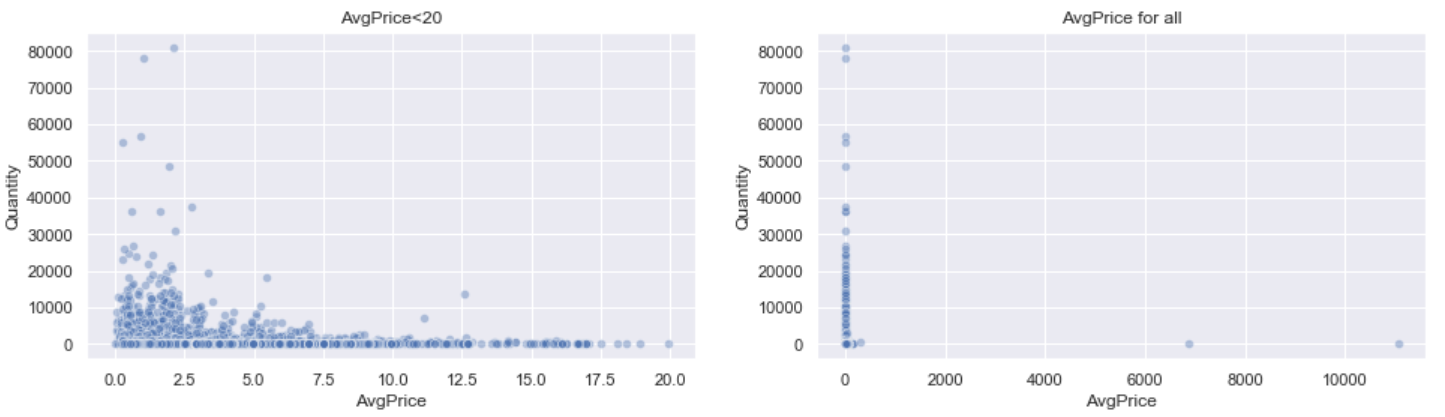
在价格方面符合价格越低,销量越大的规律。
价格低于3英镑的商品的销量明显高于别的商品,在5英镑的价格内出现了万级别的销量,验证了平台低价走量的批发商式销售模式。
此外,存在两件单价超过6000英镑的商品,分别是价格为6880英镑的AMAZONFEE商品和价格为11062英镑的B商品,这两者的销量分别为2件和1件,说明平台在高价商品上没有竞争优势。
而高价商品所需的运维成本往往高于其他商品很多,建议平台专注单价20英镑以内的商品,继续提高低价商品的销量来获取更多收益。
3. 词云分析
对商品的描述一栏做词云分析,从可视化结果中发现:平台销售的商品属于小礼品类,其中闹钟类商品居多。
4. 分析小结
平台当前的定位是低价走量批发商式平台,这个销售模式得到了验证,应该继续坚持这个模式。对于超高价商品,平台的销售额贡献甚微,却要花费较高的销售成本,因此平台的利益点可以专注在低价商品的高销量上。
六、时间序列分析
1. 销售额-时间关系
统计各月的交易量、销量以及销售额如图所示:
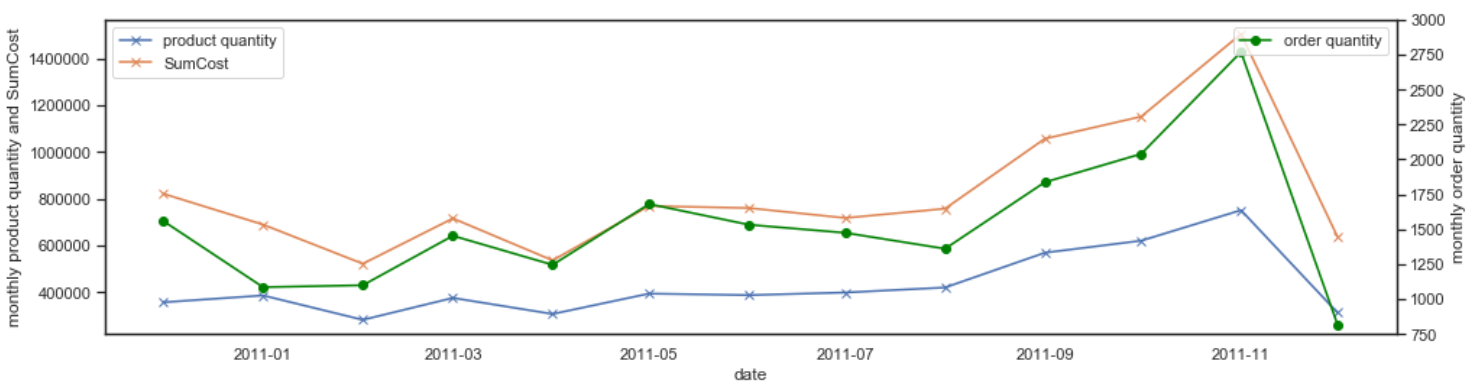
显然:11月和12月的成交量最多,两者超过了全年交易量的四分之一,商品的出货量和销售额也是这两个月最多。
纵观全年:销量、销售额、订单量呈现出相同趋势,从1月起销售额缓慢上升,至4月出现一个骤降后,从5月开始又缓慢下跌,随后至年底期间销量上升趋势明显。
2. 分析小结
11月销售的骤增与万圣节、双十一全球购的促销活动紧密相关,12月的销售在万圣节的余温以及圣诞节的氛围中随较之11月有所降低但仍高于全年平均水平。
年初销量骤降的原因是前面两个月的促销极大地释放了客户的购买欲望,且年初的节日少,批发商的采购意愿并不强烈。4月份出现骤降,而后销售额稳定在600,000到800,000之间。从8月开始,批发商们开始备货准备年底的倾销,成稳定上升趋势。
因此,平台在9月和10月应该为后续的节日活动造势,加大营销成本的投入,同时增加库存,为后续促销销量做保证。
11月和12月要注意加大运维力度,防止线上销售渠道的崩溃而造成损失;年后1月和2月可以借情人节相关话题再次激发用户的购买欲望,促进淡季的销售。
七、地区分析
1. 用户来源分布
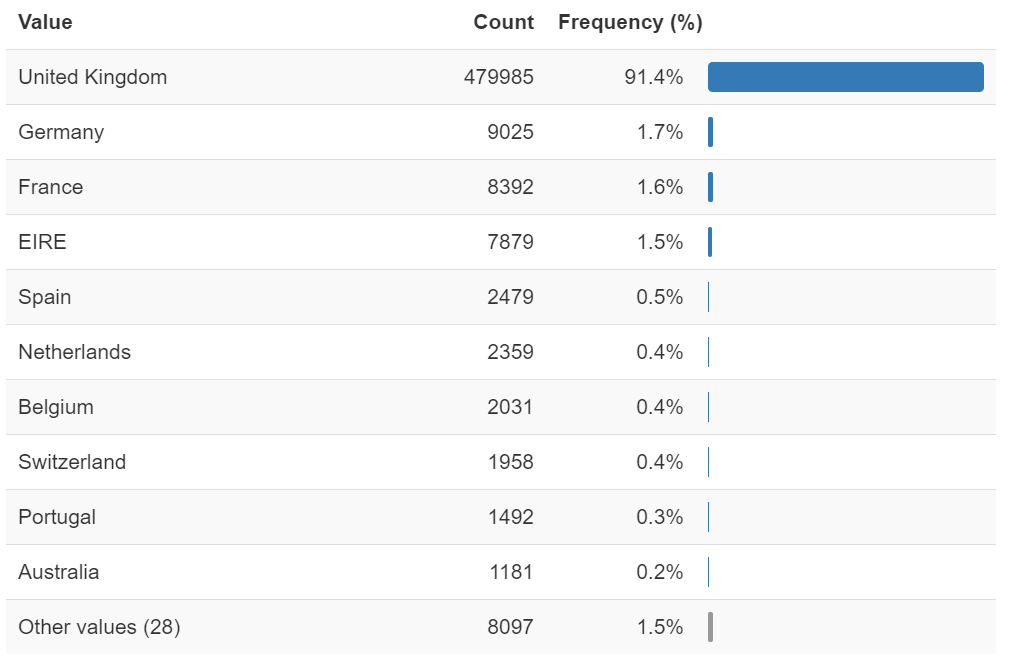
作为英国的电商平台,其用户九成以上是本土用户。排在后面的三个地区也都属于欧洲,分别是:德国、法国、爱尔兰。
2. 销售额-地区分布
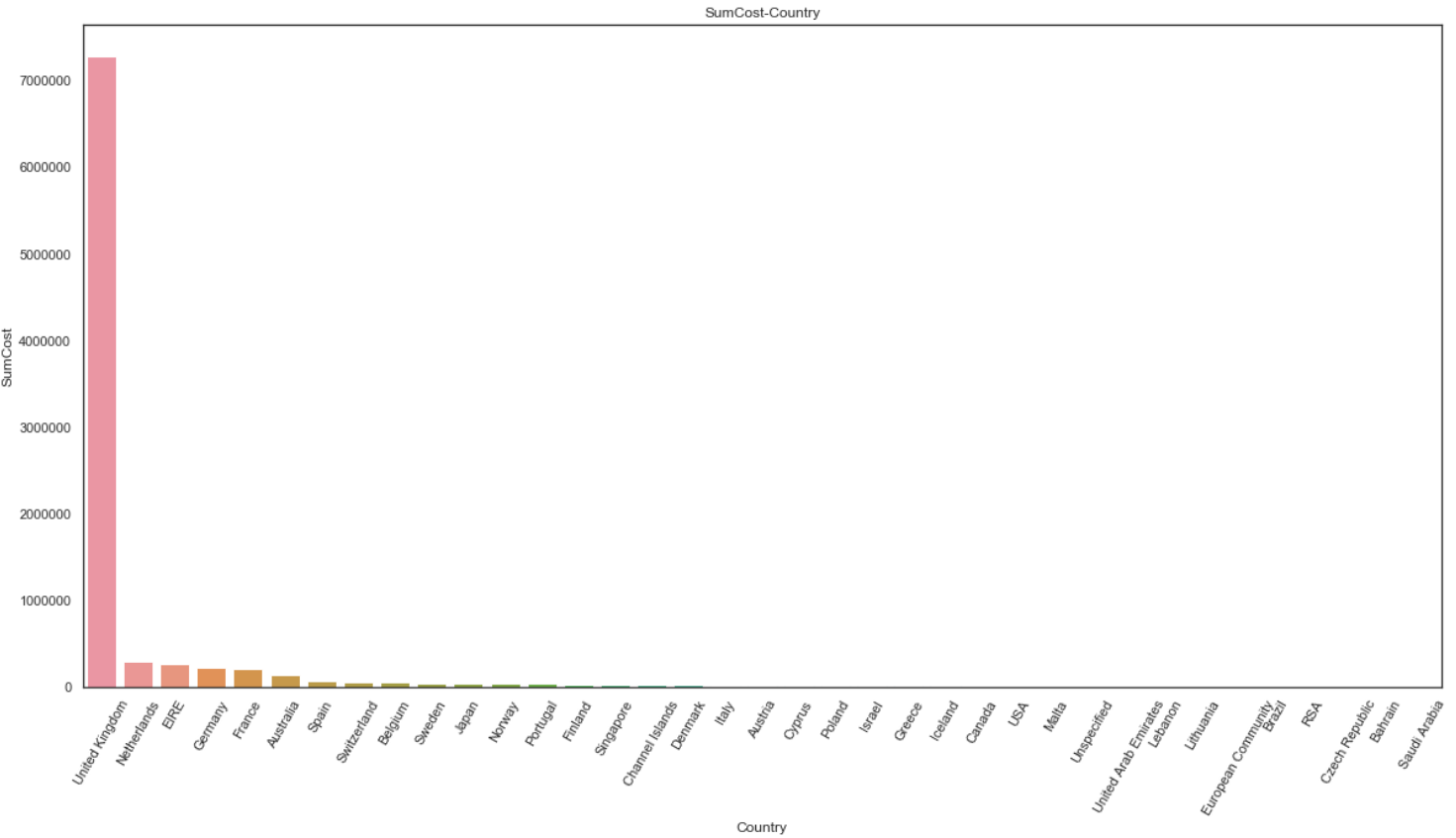
因为庞大的本土用户基数,平台的销售额九成以上是来自于本土市场,随后是欧洲的荷兰、爱尔兰、德国和法国。在欧洲市场以外,澳大利亚市场占据销售额第一名。
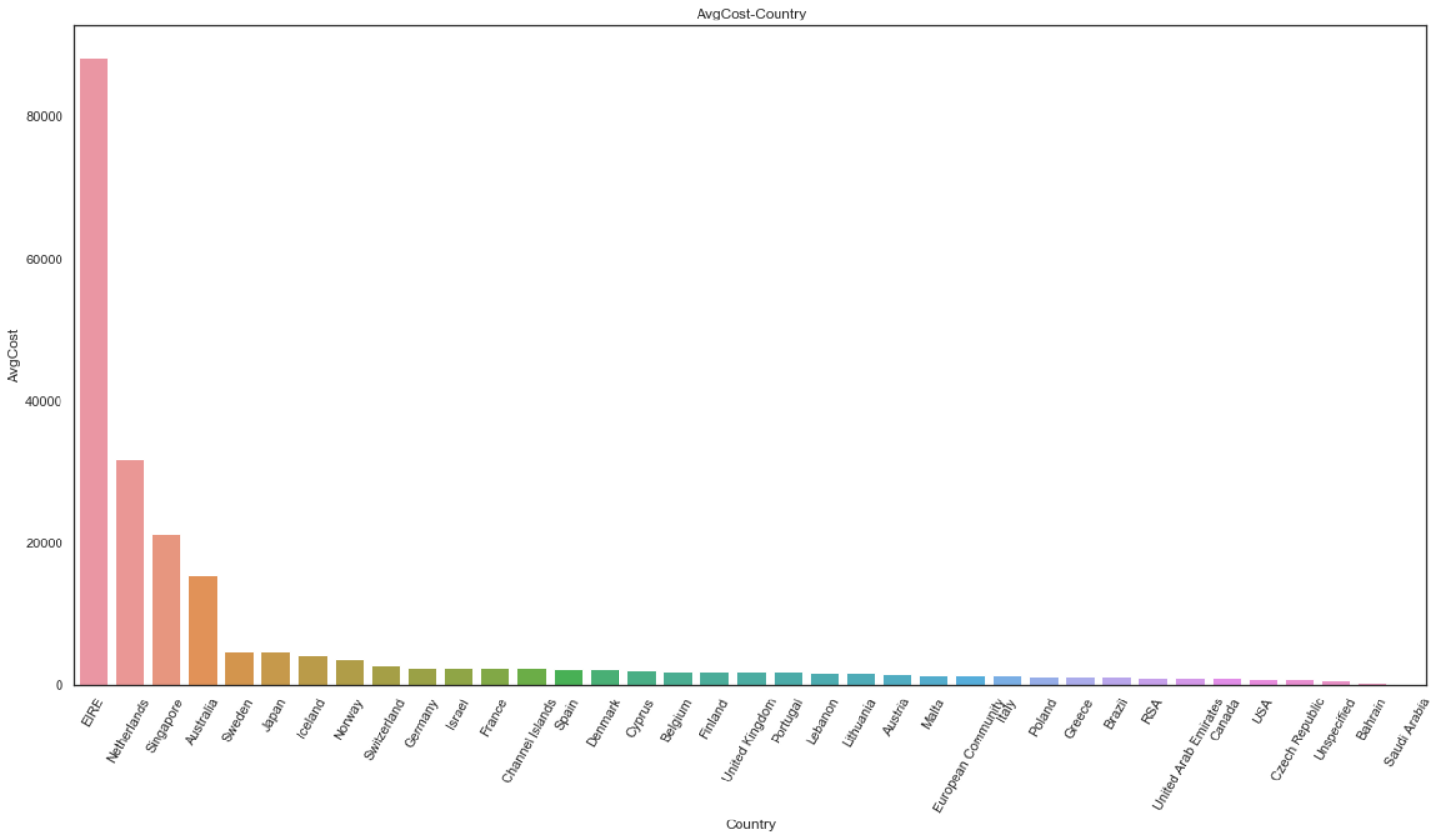
虽然英国的销售额占据了九成以上,但客均消费上英国只算中等水平。而海外市场中,爱尔兰的客均消费表现十分抢眼——达到80000英镑以上。达到10000英镑以上的国家还有荷兰、新加坡和澳大利亚。
3. 分析小结
- 从销售总额来看:得力于本土优势,英国的本土用户贡献了平台90%以上的销售额;因为地理位置方便,英国随后的销售额也主要来源于欧洲国家。
- 从客均消费额来看:爱尔兰表现抢眼,购买力极强,随后是表现优秀的荷兰、新加坡、澳大利亚——这些国家都是高福利国家,客户资金充沛,消费意愿强烈。
- 从大方向上来看:平台要关注欧洲市场尤其是本土市场的动向,紧跟市场动态。
- 从客均购买力上来看,平台应与上述购买力强的客户主动保持联系,提供销售经理专人服务或优惠政策等。在这些地区也可以适时地做一些宣传推广,多吸收优质客户来提高海外市场的收益。
八、客户分类
1. 生命周期
计算客户从第一次消费到最后一次消费的天数,即为客户的生命周期,其描述性统计信息和分布如下:
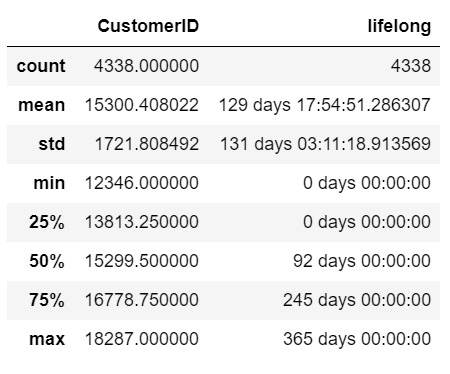
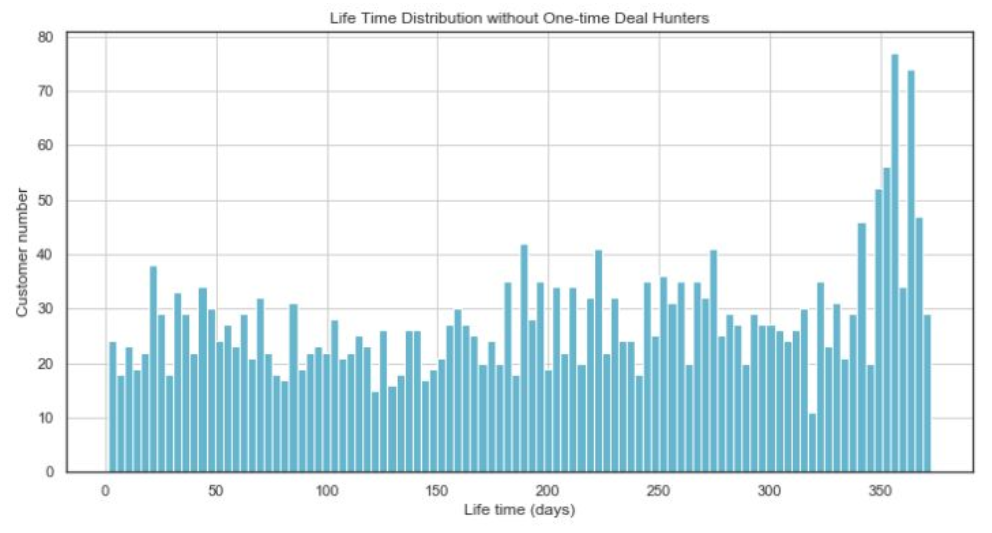
根据以上信息可以看出:至少有四分之一的客户没有留存,但也有四分之一的客户生命周期达到8个月,两极分化严重。
2. RFM模型客户分类
Recency代表最近一次消费,Frequency代表消费频次,Monetary代表消费金额。
这个用户划分模型十分经典,但具体的划分准则往往不能很好的把握,在此用K-means聚类方法自动将客户群体按RFM准则分为八大类,即如下图所示:
在聚类之前首先观察F和M的关系,剔除掉明显的离群值,在数据集中区域进行聚类,因此画出F-M散点关系图如下:
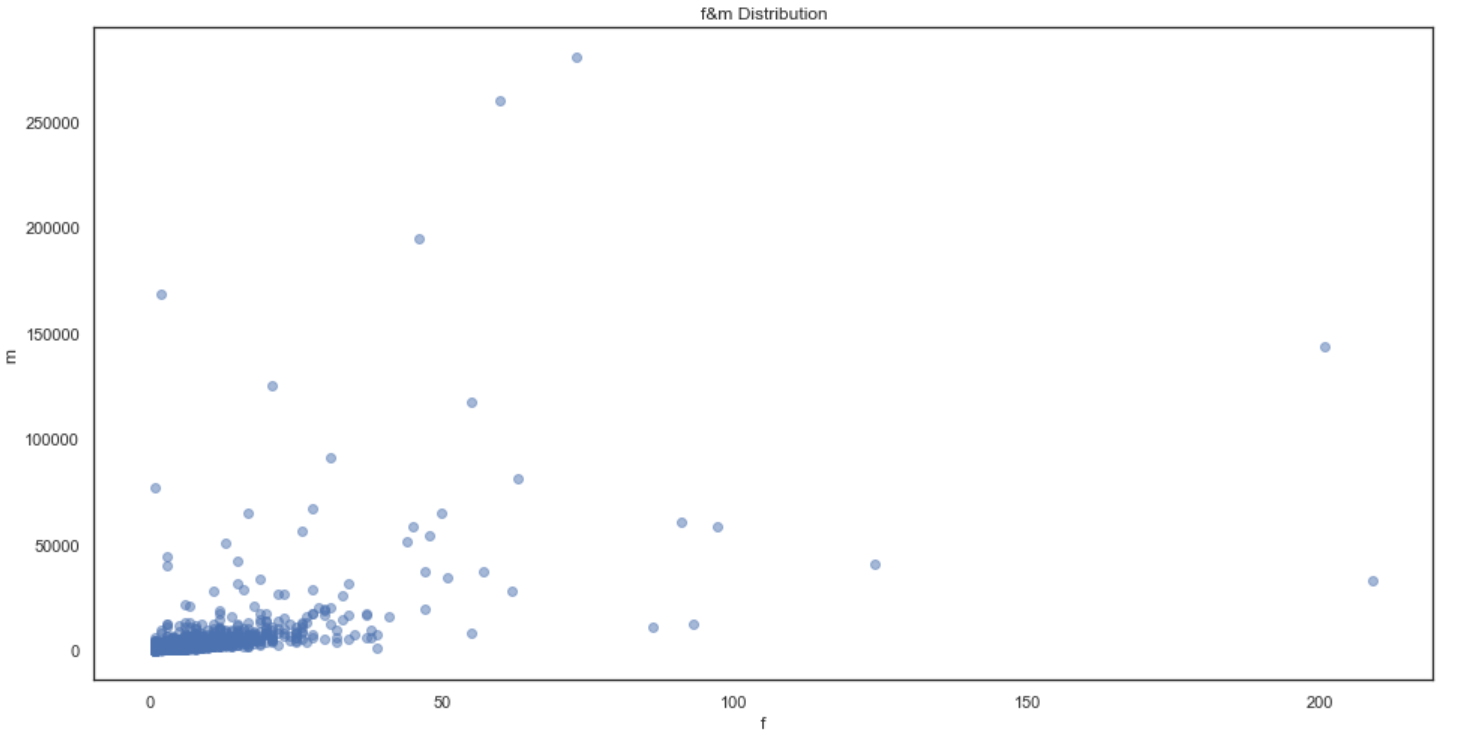
可以看出:数据主要集中在左下角f<50和m<20000的区域,因此聚类模型所选择的数据为此区域的数据。
在聚类时有必要结合业务知识手动设置初始中心,否则算法得出的结果偏差会比较大。
在此,选定数据集中估计的八个中心为初始中心点,对数据进行归一化,多次调试后得出RFM模型聚类图如下:
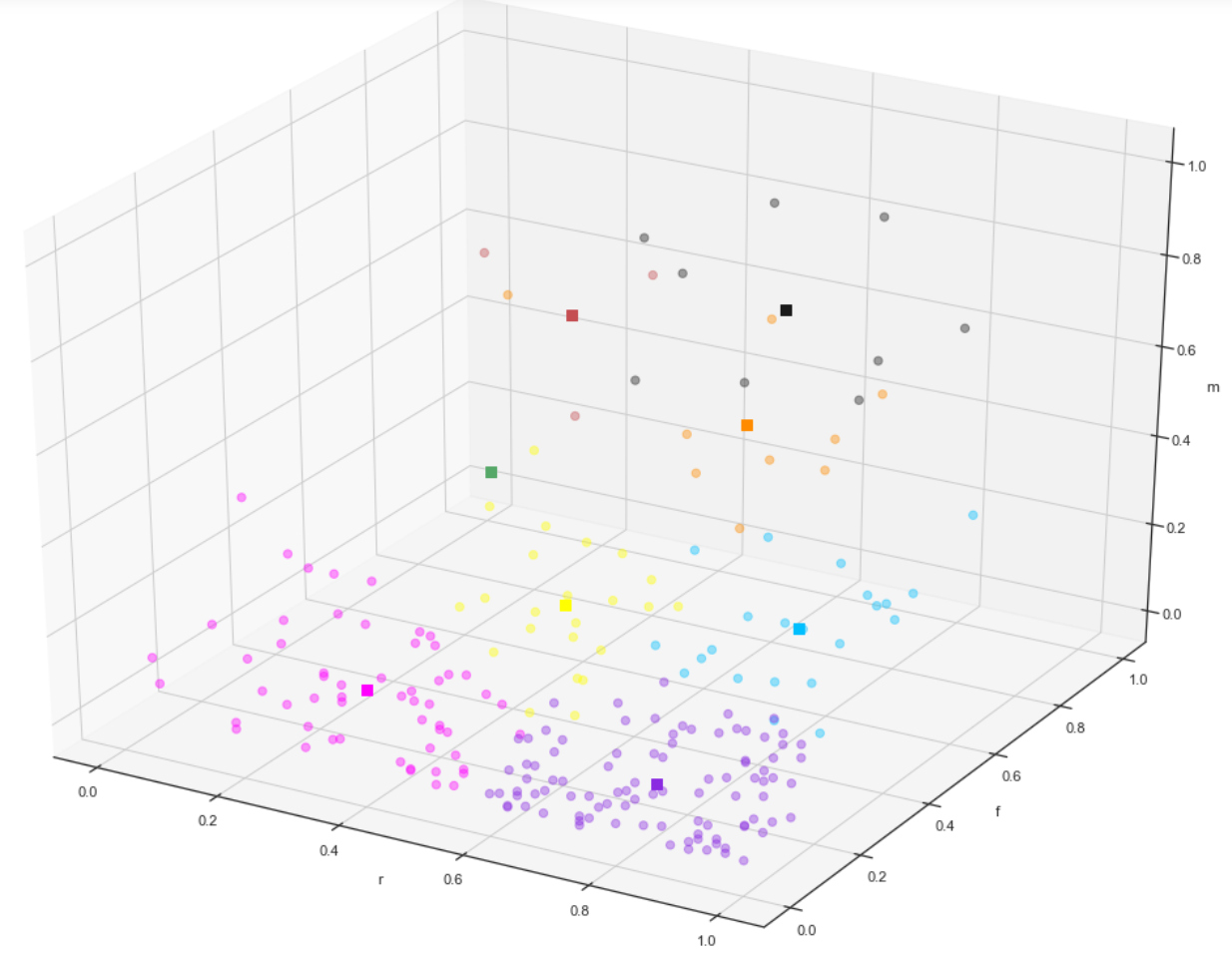
其中每一种颜色代表一类用户,方形数据标记代表每一类的数据中心。
上图为聚类效果还不错的一个调试后的模型,可以看到每类数据的中心分布在整个空间里比较均匀,即:每一类的中心分别属于三维空间坐标里的每一个象限。——这是判断一个RFM模型效果好坏的重要标准。
得出八类客户的RFM均值如下:
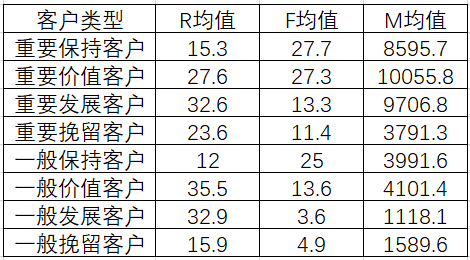
通过无监督学习算法K-means可以自动挖掘客户数据之间的关系,划分出客户类型,比传统的简单均值法划分更有依据。
但往往真实的客户数据并不规整,需要结合业务知识手动调参,即使调试多次,模型也可能仍然不能完美适配,这时要根据经验进行取舍。
模型建立完成后,再回去看离群值,发现离群值客户通常都是对销售额贡献度很大的群体,所以一定不能忽略这类客户群。
对于已经划分好的客户群体,对每一类采取不同的营销策略,可以实现精准营销,将本增益的效果。
九、分析总结
1)电商平台在2010年12月1日至2011年12月9日期间发生有效订单19960笔,笔单价533.17英镑,笔均购买商品279件,用户群体以批发商为主。订单交易额和商品数量的均值都超过Q3分位数,说明订单差异大,存在购买力极强的客户对销售额做出了巨大贡献。
2)客均购买商品1187件,客单价4338英镑,均超过Q3分位数。但客户群体中流失了至少25%的新客,客户平均生命周期为130天,一半的客户生命周期低于93天,25%的客户生命周期超过250天。
客户的生命周期分化严重,流失客户和忠诚客户都占到四分之一以上。平台可以把忠诚客户维持的经验应用到新客中,提高初次购买体验来增加新客留存率。按客均消费计算,这部分新客留存带来的收益可以增加约30%。
3)平台售卖的商品价格基本在20英镑以内,且呈现价格越低销量越高的趋势。销售量最多的产品是闹钟类的礼品,在5英镑左右的商品出现万级别的销量。对于平台出售的2种特高价商品(6000英镑以上)销量仅为3件,且购买高价商品的客户没有留存,建议下架特高价商品以减少高价商品的运维成本。
4)基于本土优势,90%以上的客户来源与英国本土,其次是欧洲国家。但从客均消费来看:英国只算中等水平,而海外市场中,爱尔兰的客均消费表现十分抢眼,达到80000英镑以上。
达到10000英镑以上的国家还有荷兰、新加坡和澳大利亚。对于这些购买力极强的海外客户,应积极保持联系,在该地区做宣传推广,获取更多优质客户;予以国际物流支持,增加优质客户粘性。
5)根据RFM模型,建立了客户分类标准,销售情况符合二八定律:25%的客户贡献了80%的销售额。因此建议用户运营部门根据模型划分结果,对客户进行差异化运营和营销,将资源更多地投入到重要客户中去。
本文由 @欧泡Paul 原创发布于人人都是产品经理,未经许可,禁止转载。
题图来自 Unsplash,基于CC0协议








答主,我在文章开头翻遍了也没找到链接和源代码,本人跪求回复分享下代码和源数据/(ㄒoㄒ)/~~
RFM模型划分为8大类的标准是啥
入职了一家数据科学公司,公司的底层数据量太大,正在熟悉业务中。所以,之前自动化的代码编写到一半也没时间继续完善咯,有兴趣的同学可以私我(Ou-Paul),对数据分析、商业分析感兴趣的同学也可以一起讨论~
您好~ 请问一下为什么我describe()的count是52万多,可是你的是19960呢? 刚开始学用python作分析~
我是在订单层面进行了describe,指我先对df进行列groupby(‘InvoiceNo’)后再进行的describe,你应该是对原始的数据进行了描述,所以得出的是原始数据的行数。上班后工作比较忙,回复滞后还望理解,若有探讨之处可以加我wx:Ou-Paul
大神,代码和数据源有空整理出来了吗?百度网盘分享一下,谢谢了~
数据集在文中开头部分提到过有链接,可以自行下载,代码我最近整在实现自动化整理中,整理好了之后我会分享出来,感谢关注。
您好! 请问RFM模型的三维散点图是如何用代码写出来的? 另外可以分享一下源数据吗?在自学数据分析 想操作做一下,十分感谢~~
数据集在文中开头部分提到过有链接,可以自行下载,代码我最近整在实现自动化整理中,整理好了之后我会分享出来,感谢关注。
您好!请问可以分享一下脚本代码和爬下来的数据吗?不胜感谢
数据集在文中开头部分提到过有链接,可以自行下载,代码我最近整在实现自动化整理中,整理好了之后我会分享出来,感谢关注。
沙发
谢谢关注
您好!请问可以分享一下源数据和代码吗?初学者想手把手操作一下
好的,等我空闲了稍后整理一下,共享出来。
嗯嗯,期待
学习了,感觉和平时用Excel分析并 没有太大的差别 😐
承让。可能报告看上去差别不大,但这份数据的量级在50万级别,用excel会崩溃。由于能力有限,python数据分析的很多潜能在这份报告中还没有得到充分的发挥,我也仍在继续学习!
佩服,只是不了解,所以之前把数据清洗相当太神秘,以为是从无序的数据中抽取有意义的数据呢
对的,我在接触之前也觉得有些名词听起来很神秘,但其实有时候这些名词只是纸老虎,就如我的另一篇文章里说到数学建模一样,有兴趣可以去看看。有一个理论是:人们总是深奥化简单的知识,简单化深奥的知识。所以,奥里给!
之前一直用sql跑来看。。。