
 起点课堂会员权益
起点课堂会员权益数据分析经典模型——朴素贝叶斯
编辑导语:做过数据分析的人,想必对贝叶斯模型都不会陌生。贝叶斯预测模型是运用贝叶斯统计进行的一种预测,不同于一般的统计方法,其不仅利用模型信息和数据信息,而且充分利用先验信息。通过实证分析的方法,将贝叶斯预测模型与普通回归预测模型的预测结果进行比较,结果表明贝叶斯预测模型具有明显的优越性。

说到贝叶斯模型,就算是不搞数据分析的都会有所耳闻,因为它的应用范围实在是太广泛了。
大数据、机器学习、数据挖掘、数据分析等领域几乎都能找到贝叶斯模型的影子,在疾病诊断、金融投资、日常生活中也都会用到。
贝叶斯公式不仅可以帮助人们确定导致某一事件发生的最可能的原因,而且在数量上刻画了随着新信息的加入,人们对一个事物的认识如何从先验概率过渡到后验概率。
要了解贝叶斯,我们先来看看条件概率。
一、条件概率
条件概率是指事件A在事件B发生的条件下发生的概率,条件概率表示为:P(A|B)。
来看下面这个例子:
假设现在有一个装了7个石块的罐子,其中4块是红色的,3块是白色的,如图:

问题1:如果从罐子中随机取出一块石头,那么是白色的可能性是多少?
回答1:由于取石头有7种可能,其中3块是白色,所以取出白色石头的概率为3/7。
问题2:取出红色的概率是多少?
回答2:很显然,答案是4/7。
我们用P(white)来表示取到白色石头的概率,用P(red)来表示取到红色石头的概率,那么:P(white)=3/7,P(red)=4/7。
很简单,对吧?
问题来了:现在,我们把这7块石头放到两个桶中,上述概率该如何计算呢?

问题分析:要计算P(white)或者P(red),事先得知道石头所在桶的信息会不会改变结果?
假定计算的是从B桶取到白色石头的概率,这个概率可以记作P(white|B),我们称之为“在已知石头出自B桶的条件下,取出白色石头的概率”,这就是条件概率。
从上图可以看出P(white|A)=2/4,P(white|B)=1/3,依然很简单。
条件概率的计算公式如下:
P(white|B)=P(white and B)/P(B)
我们来验证下上述公式:
- P(white and B)=球是白色且球是从B桶中取到的=1/7;
- P(B)=从B桶中取到球的概率=3/7;
- P(white|B)=P(white and B)/P(B)=(1/7)/(3/7)=1/3;
为了方便起见,我们将white替换为A,条件概率可以表示为P(A|B)=P(A and B)/P(B)。
二、贝叶斯公式
知道了条件概率,现在,我们来推算贝叶斯公式:
1. 第一步
条件概率公式两边都乘以P(B),可以得到:
P(A and B)=P(A|B)*P(B)
这个公式表示,条件A 和 B同时发生的概率等于B条件下A事件发生的概率乘以B事件发生的概率。
2. 第二步
顺序调换。假设条件A 和条件B是两个独立的事件,所以我们可以将上述公式顺序调换,即:
P(A and B)=P(B and A)=P(B|A)*P(A)
这个公式表示,条件A 和 B同时发生的概率等于B条件下A事件发生的概率乘以B事件发生的概率。
3. 第三步
重新代入条件概率公式:
P(A|B)=P(A and B)/P(B)
代入第二步的公式:
P(A and B)=P(B|A)P(A)
可以得到:
P(A|B)=P(B|A)P(A)/P(B)
贝叶斯公式告诉我们如何交换条件概率的条件与结果,即如果已知P(B|A),要求P(A|B),那么可以使用上述计算方法。
上述公式中,每个概率又有不同的说法:
- P(A)被称为先验概率;
- P(B|A)被称为后验概率;
- P(B)被称为全概率。
三、贝叶斯公式的应用
以下摘一段 wikipedia 上对贝叶斯的简介:
所谓的贝叶斯方法源于他生前为解决一个“逆概”问题写的一篇文章,而这篇文章是在他死后才由他的一位朋友发表出来的。
在贝叶斯写这篇文章之前,人们已经能够计算“正向概率”,如“假设袋子里面有N个白球,M个黑球,你伸手进去摸一把,摸出黑球的概率是多大”。
而一个自然而然的问题是反过来:“如果我们事先并不知道袋子里面黑白球的比例,而是闭着眼睛摸出一个(或好几个)球,观察这些取出来的球的颜色之后,那么我们可以就此对袋子里面的黑白球的比例作出什么样的推测”。
这个问题,就是所谓的逆概问题。
贝叶斯是机器学习的核心方法之一。
这背后的深刻原因在于,现实世界本身就是不确定的,人类的观察能力是有局限性的。
沿用刚才那个袋子里面取球的比方,我们往往只能知道从里面取出来的球是什么颜色,而并不能直接看到袋子里面实际的情况。
这个时候,我们就需要提供一个猜测(hypothesis)。所谓猜测,当然就是不确定的,但也绝对不是两眼一抹黑瞎蒙——具体地说,我们需要做两件事情:
- 算出各种不同猜测的可能性大小。
- 算出最靠谱的猜测是什么。
以病人的分类为例,某个医院早上收了六个门诊病人,如下表:

现在又来了第七个病人,是一个打喷嚏的建筑工人,请问他患上感冒的概率有多大?
根据贝叶斯定理:
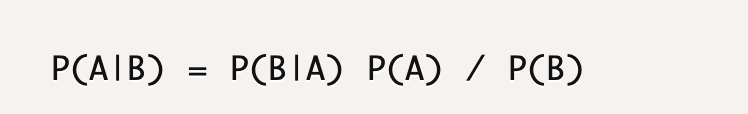
可得:

假定”打喷嚏”和”建筑工人”这两个特征是独立的,因此,上面的等式就变成了:

这是可以计算的。
因此,这个打喷嚏的建筑工人,有66%的概率是得了感冒;同理,可以计算这个病人患上过敏或脑震荡的概率,比较这几个概率,就可以知道他最可能得什么病。
这就是贝叶斯分类器的基本方法:在统计资料的基础上,依据某些特征,计算各个类别的概率,从而实现分类。
本文由 @CARRIE 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议









如何结合业务使用呢?
让我想起了大学被高数支配的恐惧
有点不太明白最后一个,打喷嚏的建筑工人为什么是0.33*0.5,请赐教,谢谢
感冒是3/6,就是0.5,感冒中有2个打喷嚏,所以是2/3,就是0.66,感冒中有1个建筑工人,所以是1/3,也就是0.33;因为打喷嚏和建筑工人是独立的,所以P(打喷嚏*建筑工人|感冒) = P(打喷嚏|感冒)*P(建筑工人|感冒)
因为打喷嚏和建筑工人是独立的,所以p(打喷嚏*建筑工人)=p(打喷嚏)*p(建筑工人)=3/6*2/6=0.5*0.33
感谢赐教,已懂