
 起点课堂会员权益
起点课堂会员权益这篇文章把数据讲透了(三):数据清洗
编辑导读:随着“数智化”时代的到来,我们生活中的方方面面都离不开数据,而你真的了解数据吗?本文将为你重新解读数据的概念和价值,以及数据的价值是如何在“数智化”时代下一步一步得到运用与升华的;因内容颇多,笔者将分几期为大家进行讲解。

一、前言
上两期文章中,我们已经了解到“数据”是一个庞大的体系(如下图所示);并用了菜市场的例子,为大家讲解数据来源的含义,用买菜的例子,为大家讲解数据采集的步骤;而今天小陈主要给讲解,我们“买完菜”以后,怎样进行择菜、洗菜,即数据清洗的过程。
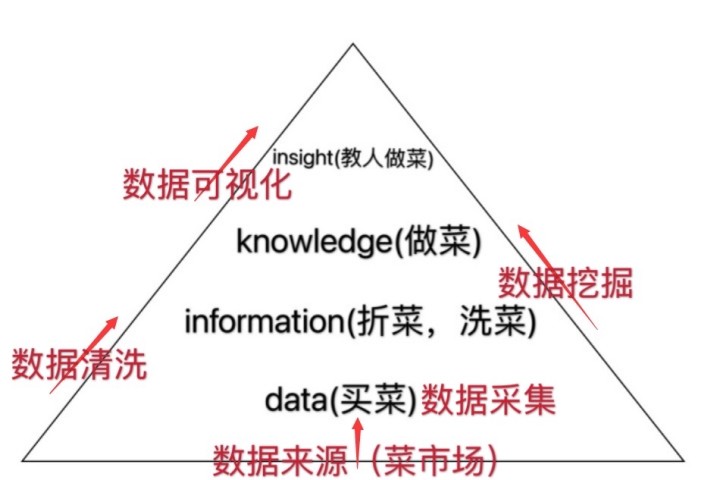
二、数据清洗(择菜、洗菜)
想一步步了解数据清洗究竟是怎样如何运作的,首先我们需要明确数据清洗的概念是什么?
1. 数据清洗的基本概念与重要性
数据清洗——重新检查和验证数据的过程,旨在删除重复信息,纠正现有错误并提供数据一致性。
以上,是百度百科对数据清洗的概念定义。以我个人的理解来看,数据清洗就是一个将“脏数据”替换成“高质量可用数据“的过程。
毕竟,数据清洗作为数据预处理中至关重要的环节,清洗后数据的质量很大程度上决定了后续研究型数据分析的结果准确性。
2. 数据清洗的对象与方法实操
以上陈述了数据清洗的重要性,下面我们来进一步确定,需要被清洗的对象。
数据清洗的对象我个人将其大致分两类,下面我们逐一进行介绍。
1)可避免型脏数据
可避免型脏数据,顾名思义,这类脏数据可以直接通过简单处理成为有效数据或人为修改避免的。
这类脏数据在日常生活中,其实是十分常见的,例如命名不规范导致的错误、拼写错误、输入错误、空值等等。
举个例子,下面是某二手车平台的相关数据(文件名:car-data.xlsx),可以看到,图中4年转售价栏中存在明显的脏数据(该栏数据形式应为阿拉伯数字,单位为万),这就是输入错误导致的可避免型脏数据。
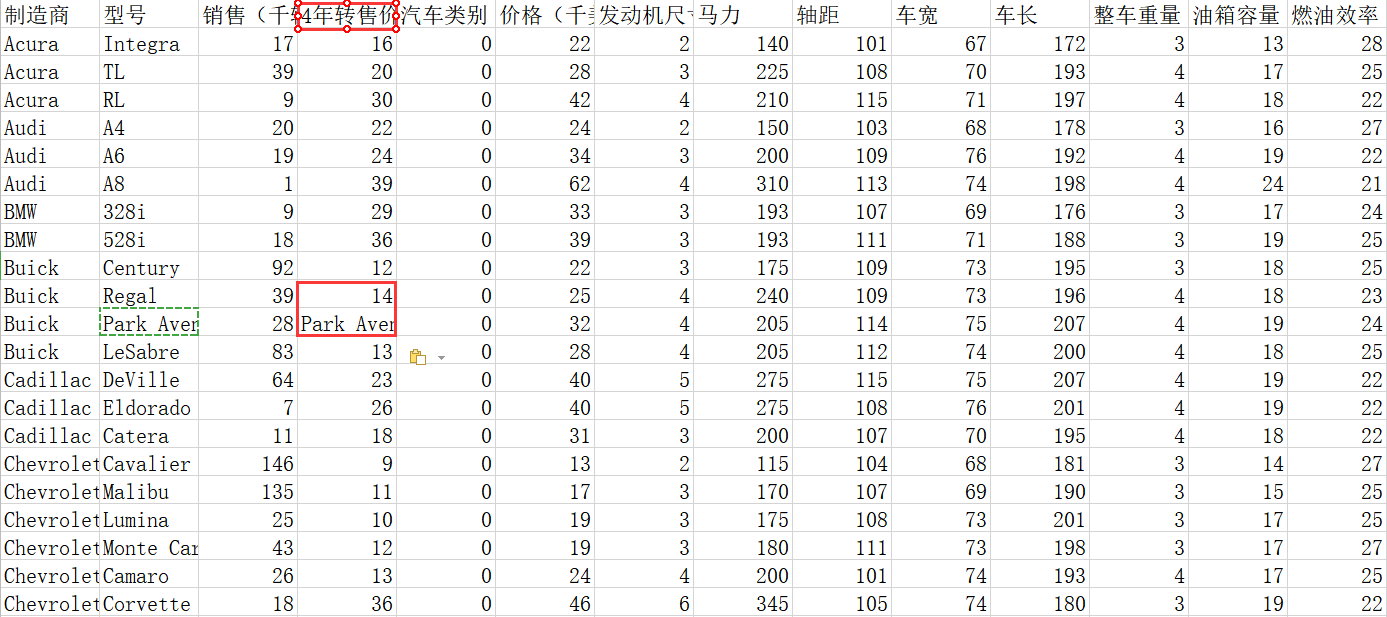
认识了此类脏数据的类型,那么我们在拿到数据后,如何及时的对此类“可修正”的数据错误进行侦察订正呢?此处我们分别以excel、python为例,数据集还是上面二手车数据。
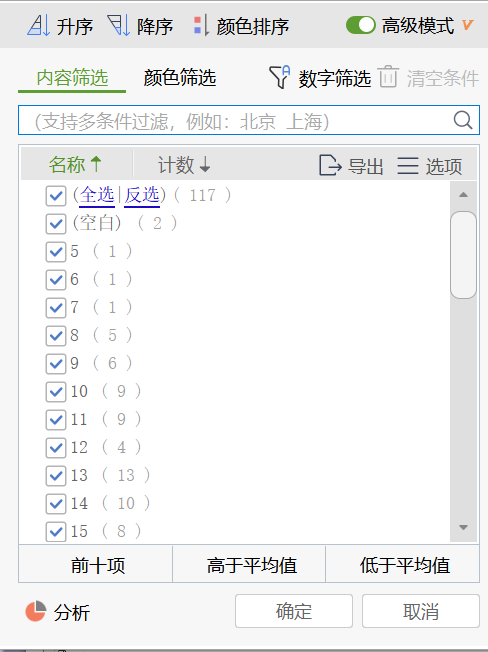
excel中,对“可避免型”脏数据的侦察,可以通过筛选功能进行查看,如下,选中“4年转售价”维度的数据,并对其进行筛选,可以侦察到nan(空)值2个,输入错误值2个。
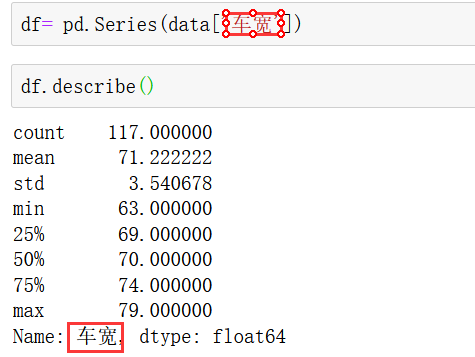
python语言中,则可以试用data.describe()查看目标列的基本统计信息:
查看对应信息后,若确定由错别字,英语大小写不统一的情况可以使用:data[‘car-data’].str.upper() ;输入了额外的空格:data[‘car-data’].str.strip()。
2)不可避免型脏数据
不可避免型脏数据,主要形式包括异常值、重复值、空值等;此类脏数据的处理,就需要联系一些统计学知识进行侦察与填补,下面还是举一些具体例子进行阐述。
异常值:
常用侦察手段3σ定律检验(假设一组检测数据只含有随机误差,对其进行计算处理得到标准偏差,按一定概率确定一个区间,认为凡超过这个区间的误差,就不属于随机误差而是粗大误差,含有该误差的数据应予以剔除,一般而言这个区间是平均值正负三个标准差,因此称3σ定律)。
如下所示,二手车数据中需要对“车宽”的异常值进行检验:
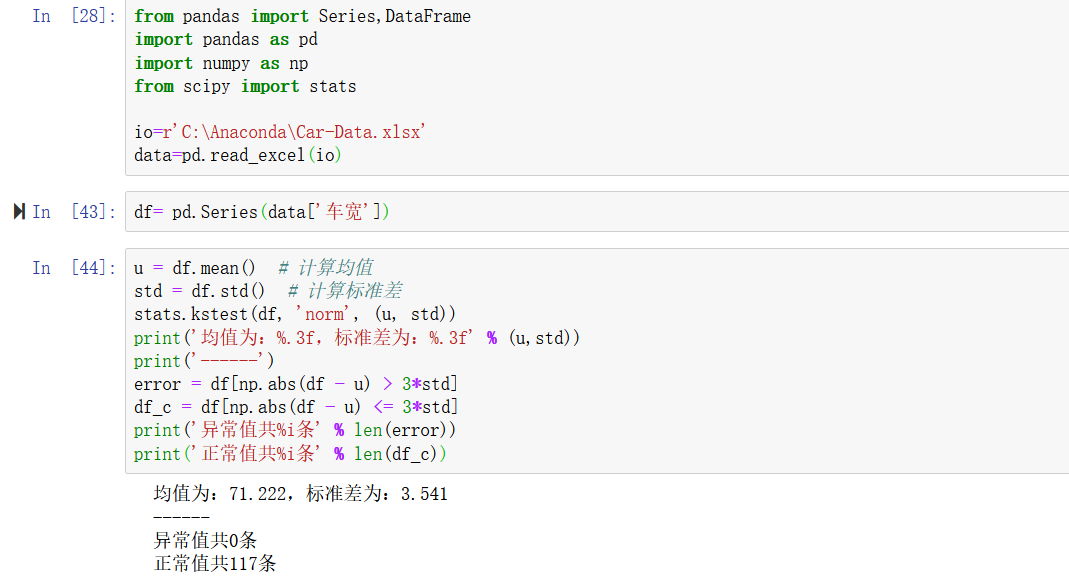
重复值:
如下所示,拿到数据后,我们先要校验一下是否存在重复记录;如果存在重复记录,python中可以使用 drop_duplicates() 来删除重复数据,以免重复计入,导致数据准确性下降。
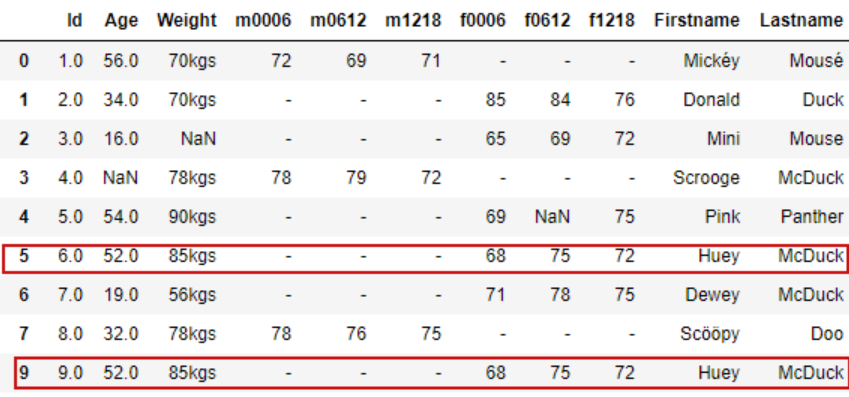
如上所示,第5和第9条数据,除id信息外,其余信息均相同,对此类数据我们需要根据它们的数据特征进行删除;而观察下方数据,有FIRST NAME和LAST NAME作为独一无二的标识,我们就能根据数据特征利用下方代码对重复值进行剔除。
df.drop_duplicates([‘first_name’,’last_name’],inplace=True)
空值:
针对空值而言,python语言有多种方式对空值进行侦察返回,下面我们逐一介绍。
data.is null()、data.not null(),会返回true or false,我们就能得知对应指标的空值情况,还能用sum()函数,对空值的总体个数进行把控。

面对以上各类空值,我们应该怎么做呢?删除单个?删除多个?利用平均值、中位数进行补充?
其实以上的操作方法,在应对空值时都是十分常见的,而我们需要掌握的是,在合适的场景使用对应的方式,下面为大家介绍一些常见的空值处理场景~
场景1:该维度数据,半数以上or全为为空值——从指标有效性角度出发考虑,是否删除对应指标。
命令:data.dropna(how=’all’),删除全为空值的行(无效指标)。
场景2:该维度存在空值(但空值数量不多),且总体数据样本量大——因为数据样本充足,可以考虑对存在nan值的样本进行过滤,采用无nan值样本(代码如下,涉及nan值的数据都会被剔除)。
df.dropna(axis=0,how=’any’) #drop all rows that have any NaN values。
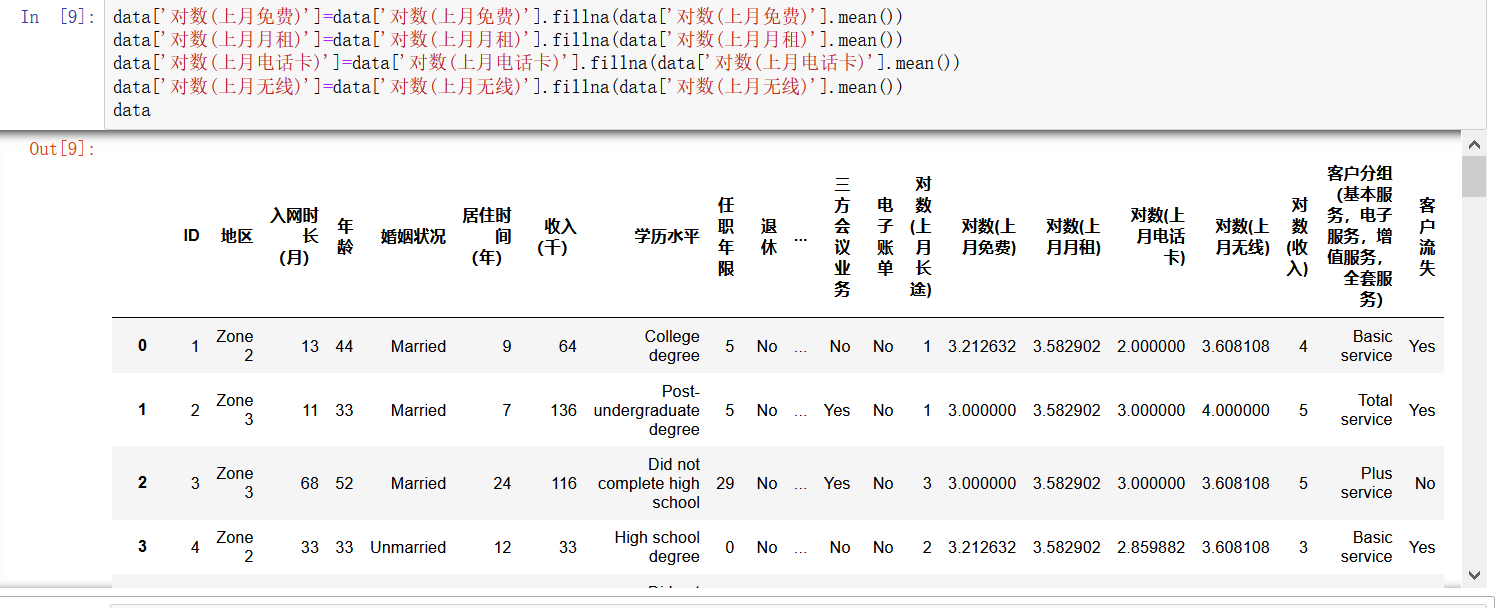
场景3:该维度存在空值(但空值数量不多),且样本总体数量有限,故而不能像场景2一样,对有nan值的数据进行抛弃,需要利用数理统计方法,选取合适值对nan值进行填充。
代码:data.fillna(我们可以看到此例中,使用均值对空值进行填充)。
三、结语
本期,笔者通过一个“洗菜、择菜”的例子,带着大家了解了数据清洗的对象与大体方法,相信大家有所收获!
下期,笔者讲在数据清洗的基础上,为大家讲解如何利用常用工具进行数据挖掘!
本文由 @小陈同学ing. 原创发布于人人都是产品经理,未经作者许可,禁止转载。
题图来自Unsplash,基于CC0协议。









这个是应该产品做的吗?