
 起点课堂会员权益
起点课堂会员权益
如何用数据分析,搞定新媒体运营的定位和内容初始化?
 产品经理的不可取代的价值是能够准确发现和满足用户需求,把需求转化为产品,并协调资源推动产品落地,创造商业价值。
产品经理的不可取代的价值是能够准确发现和满足用户需求,把需求转化为产品,并协调资源推动产品落地,创造商业价值。
最近,很多运营微信公众号、微博或头条号的小伙伴都被这样一个问题困扰着:
为啥我新媒体账号有时推送的阅读量很高,有时却是极低,甚至最高值和最低值之间相差达数十倍之多。如此不稳定,这究竟是为什么呢?
其实,原因很简单—因为运营者们没有很好地给自己运营的新媒体账号进行定位,也不了解他们的粉丝需要什么样的内容,只知道每天推送内容,而不知道什么样的内容是与我们公众号的自身定位相符的,只要是自己觉得好的内容就推-推-推。
这是典型的代替用户去思考其阅读喜好,而不是带有“同理心”的站在用户的立场上去思考问题。
要解决上述问题,就需要我们在新媒体账号建设之初,做好定位工作,避免后续运营中缺乏“同理心”的操作。
下面以微信公众号为例,其他类型的新媒体账号的定位原理差不多,可“依葫芦画瓢”进行迁移复用。
一般来说,对公众号进行定位具有如下重要意义:
- 有利于选择公众号名称
- 有利于生产内容,便于我们围绕一个主题去创造或寻找每天推送的素材
- 便于我们根据主题积累目标粉丝,也就是发展精准用户
- 便于后期的盈利(大部分公众号的运营都是为了获得盈利),经定位获取的大量精准粉丝可作为广告投放的“筹码”
- 有利建立清晰的账号形象 ,打造独一无二的公众号品牌
既然微信公众号的定位如此重要,那么我们该如何定位呢?
淡定,笔者这次将抛弃原先“先理论后实操”的写作套路,直接以某个青春文学类微信公众账号的定位作为实操案例,聊聊如何利用数据分析,从0到1的对公众号名称、栏目规划及内容初始化等方面来讲述公众号的定位。
以下是本文的行文脉络,从账号设定背景讲起,关键部分是用户画像信息及阅读偏好的提取,这是后续公众号定位及其内容初始化的根据,大家可以寻找自己感兴趣的部分进行阅读。

本文的行文脉络
1 账号设定背景:做一个青春文学类的微信公众账号
不知道小伙伴们有没有注意,最近这(十)几年青春题材的小说或是电影渐渐多了起来,比如《三重门》、《幻城》、《何以笙萧默》、《微微一笑很倾城》、《匆匆那年》、《致我们终将逝去的青春》等,这些作品的背后是以韩寒、郭敬明、顾漫、九夜茴和辛夷坞为代表的新生代80后作家,他们创作的作品一改之前严肃、深邃的文学之风,代之以浪漫、痛楚、穿越和奇幻。
这些张扬着青春与活力的文学作品不仅长期霸占着小说、文学排行榜,还被改编为各种影视剧,让万千少男少女(下至10来岁的小学生,上至“奔四”的青年白领)沉醉其中,不能自拔,正所谓“引无数青少年男女竞折腰”。

市面上广受好评的青春文学(影视剧)作品
鉴于青春文学如此火热的市场,作为文艺青年的笔者,就以一个青春文学类微信公众账号的创建为例,内容方向上以青春文学类短篇美文、小说连载为主,采用内容原创和作者签约机制相结合的内容生产机制。
根据上面对青春文学的简单描述及笔者个人倾向,笔者可以得到一个关于该微信自媒体的大致规划方向:
- 公众号内容风格:类似新生代青年作家(如韩寒、郭敬明和李尚龙等8090后作家的写作风格)的行文风格。
- 目标人群:爱好青春文学的青年学生群体、年轻白领。
值得注意的是,上述规划是基于常识和直观性的判断,还是比较模糊,不够细致的,但这一步很重要—它确定的是公众号定位的“大政方针”,后续的数据分析是在其基础上逐渐缩小定位的“包围圈”。
接下来,笔者将通过数据分析使公众号的定位逐渐明晰,使其能为接下来的公众号名称、栏目规划和内容初始化提供参考。
2 获取目标人群的基本信息
2.1 选择合适的用户信息获取渠道
由于公众号还未建立,因此用户相关数据不能通过直接获取,这里可以通过第三方渠道间接得到。这种第三方渠道要符合2个条件:
- 目标用户量/粉丝量基本相同,包括年龄、性别、兴趣爱好等;
- 拥有的用户量/粉丝量足够多,具有代表性。
- 活跃度较高,所获得的信息具有时效性。
基于此,笔者想到的是自媒体。由于微信的很多数据被腾讯微信团队所垄断,从对微信公众号的分析中得不到有价值的信息,而微博用户活跃度相当高,且数据相对公开。
因此,笔者选择在微博上选取公众号相关性较高的一些微博大号进行分析,选择的依据除了上述3条,还有其他选择标准,如下图所示:
选择合适的微博账号进行用户信息提取
2.2 从微博上间接获取粉丝信息
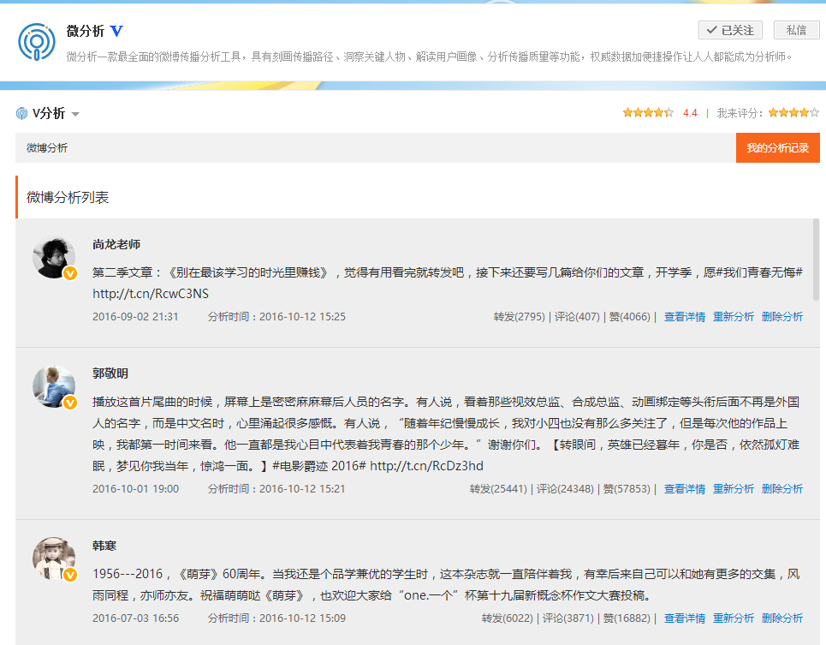
依据上述筛选条件,笔者选取了新生代8090后作家中的几位具有代表性的作家—韩寒、郭敬明和李尚龙,有人会问了:
他们的文风和调性,有的略显深沉,有的肆意青春,有的是鸡汤喝得醍醐灌顶,看起来文风迥然,综合起来合适吗?
笔者认为,他们的作品广受好评是因为其中的元素(张扬不羁、疼痛温暖和热血励志等元素)很受市场欢迎,将其杂糅在一起,可以以一种新的青春文学派别呈现,算是微创新。同时,青春文学的阅读细分人群较多,不可能一种风格吃透整个粉丝群体,需要使本公众号具有“反脆弱”的自适应能力,需要在建立之初就拥有多种风格的基因。
选取他们微博上近期发布的单条微博进行分析,单条微博选取条件及操作参见《当数据分析遭遇心理动力学:用户深层次的情感需求浮出水面》。如下图所示:
对李尚龙、郭敬明和韩寒发布的单条微博进行分析
分析结果中的粉丝性别、粉丝年龄、粉丝地域和粉丝兴趣标签,是我们需要重点“照顾”几个分析维度。具体的分析结果如下:
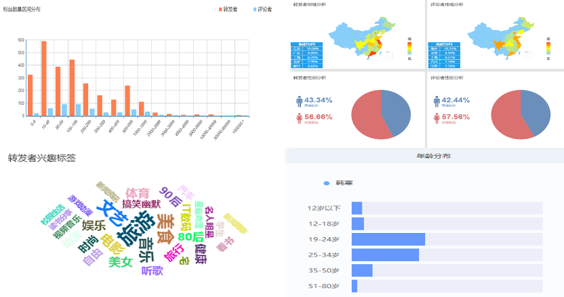
对韩寒单条微博分析的结果
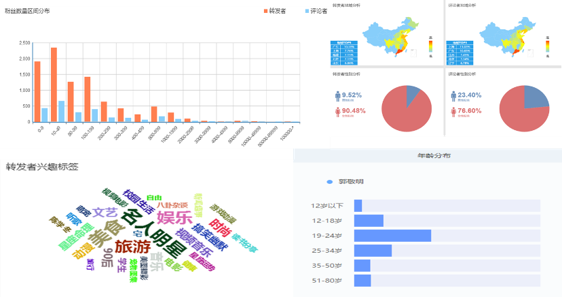
对郭敬明单条微博分析的结果
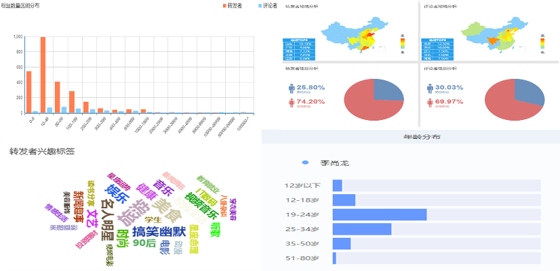
对李尚龙单条微博分析的结果
2.3 目标人群的“画像”信息提取
(1)目标人群的年龄分析
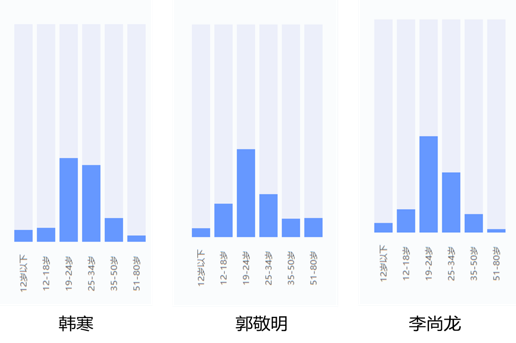
3位作家单条微博对应粉丝年龄分布
从上图可以看出,韩寒、郭敬明和李尚龙的微博粉丝的年龄段主要集中在“19-24岁”这个区间,这是“第一集团“,而“第二集团”是“25-34岁”这个年龄段区间,而韩寒的粉丝年龄段“第一集团“和”第二集团“人群相差无几,不过这也好解释,他的文风犀利但有深度,有自己的人生哲学(对比《后会无期》与《小时代》系列、《你只是看起来很努力》即可知)俘获广大80后粉丝有关。
综上所述,该公众号主要面向人群是19-24岁这个年龄段的人群,次要人群为25-34岁,据一般常识判断,粉丝群体应涵盖学生群体(高中生、大学生)、白领群体。
(2)目标人群的性别分析
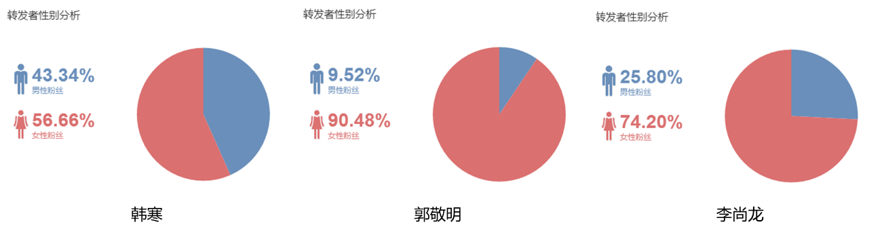
3位作家单条微博对应的粉丝性别分布
据上图可知,几位作家对应的粉丝群体的性别主要以女性为主,尤其是郭敬明和李尚龙的粉丝群体女性占比极大,分别达到90%和75%上下,造成这种情况的原因如上分析。
综上所述,该公众号面向的人群主要是女性群体,加上年龄特征,即女青年。
(3)目标人群的地域分析
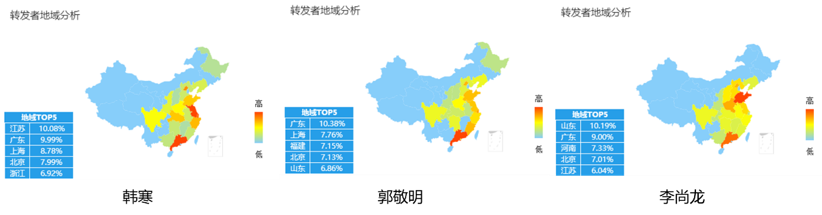
3位作家单条微博对应的粉丝地域分布
关于粉丝地域分布,笔者是想找出几位作家人群的共性分布区域,缩小地域范围,在几个区域进行集中发力,到时可以着力找当地的畅销文学、事件、人物等内容素材信息,打造粉丝群体喜闻乐见的文章;抑或找到当地有影响力的自媒体进行推广和互推;后期盈利变现也能有的放矢。
上面可以看出,上海、北京、广东三地的粉丝较多(当然也不排除这里的互联网发达,网民较多…),这里可以作为主攻区域。
(4)粉丝的兴趣图谱及情感需求分析
这部分需要对上述3条微博的互动粉丝的兴趣标签进行整理,并利用censydiam模型进行分析,详细步骤可以参考《当数据分析遭遇心理动力学:用户深层次的情感需求浮出水面(万字长文,附实例分析)》。
将三条微博的粉丝兴趣标签进行优先级赋值和归并计算,找出得分较高的前10个兴趣标签:
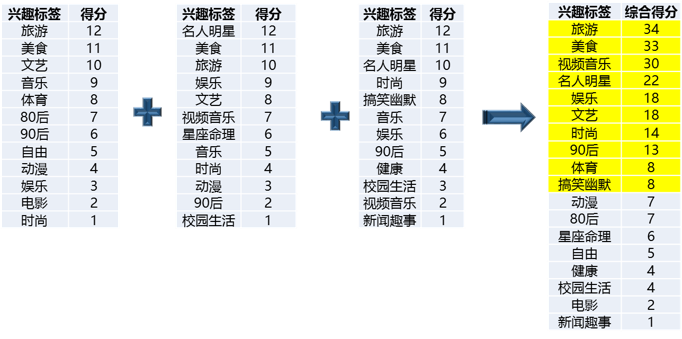
对粉丝兴趣标签进行处理
由此,我们可以得到公众号目标人群的10个最重要的特征,关于它的用户,笔者将在后面提到。
再经处理,得到如下“兴趣-行为动机”对应表和最终的3类主要情感需求象限。
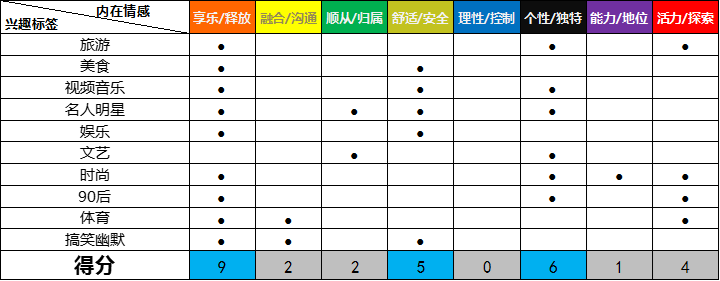
3条微博粉丝的“兴趣-行为动机”对应表
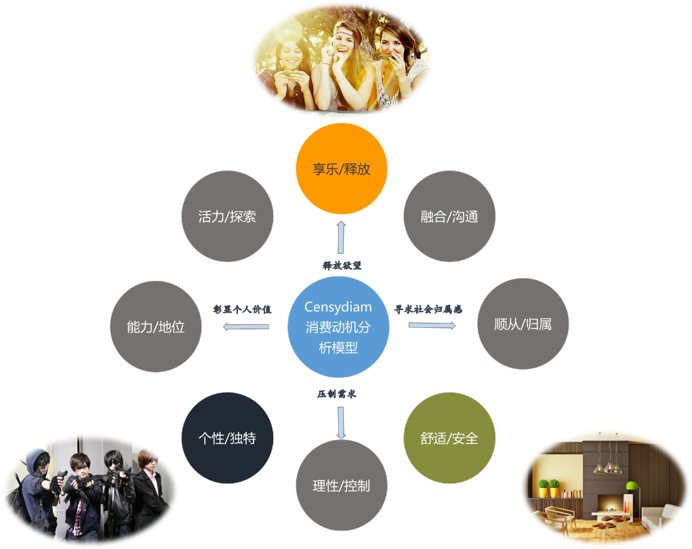
目标人群的情感需求在Censydiam动机分析模型中的反映
由上述分析可知,公众号的粉丝的情感需求在Censydiam消费动机分析模型主要对应模型中的3个象限,即“享乐/释放”、“舒适/安全”和“个性/独特”。这三类情感需求象限其实对应的是三类不同的粉丝群体,所以在后续的公众号定位及栏目规划时需要兼顾三者的差异性需求。
好了,通过间接手段,我们获取了目标人群的用户画像,了解了他们的基本特征,这对我们进行公众号的内容规划、风格调性和粉丝获取渠道都很有帮助。
然而,对于微信公众号的定位来说,仅有上述信息是不够的,因为我们还需要确认目标人群的阅读偏好,知道哪些内容是他们喜闻乐见的,据此可以“投其所好”。
3 获取粉丝的阅读偏好信息
该部分的目的在于获取目标人群的阅读喜好,了解他们喜好什么风格的文章,里面包含哪些意象/元素(帅哥、虐恋还是各种关于青春的东西),涉及到哪些关键词,这样便于栏目规划、菜单设置及后续的内容(伪)原创和采集。
总之,这一步是为内容输出奠定框架和找准发力方向。
为此,我们需要进行文本挖掘,笔者采用了网络内容分析法进行分析,从中提取粉丝的阅读偏好相关信息,对应的工具是Tagxedo和Netdraw。
3.1 语料提取
进行网络内容分析的第一步是采集精准、高质量的文本分析语料,需要找到符合上述用户特征的文本数据。
为此,笔者采用大数据文本采集及分析工具(新浪微舆情)进行文本数据采集和部分数据的分析。采集时间段是2016-6-1~2016-10-13,数据来源为全网。
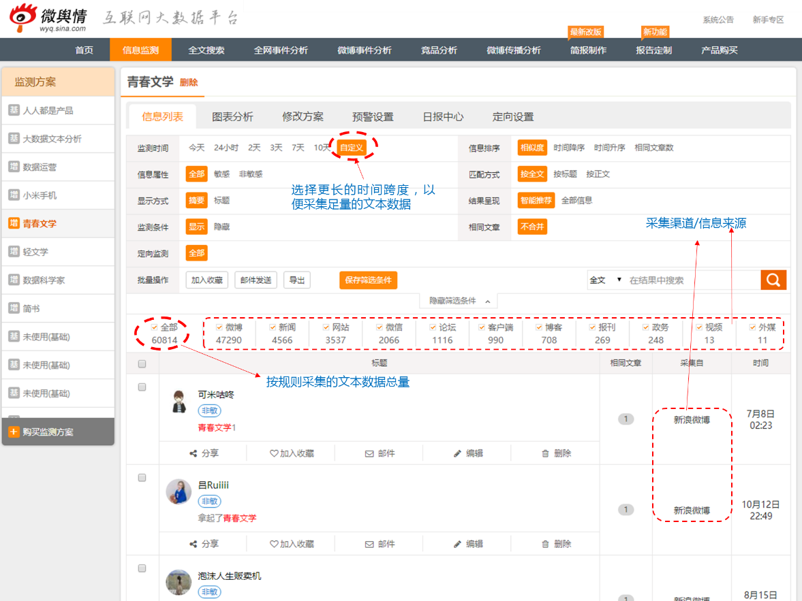
输入“青春文学”进行全网文本数据采集和分析
这段时间全网关于“青春文学”的信息量分布情况,如下图所示:
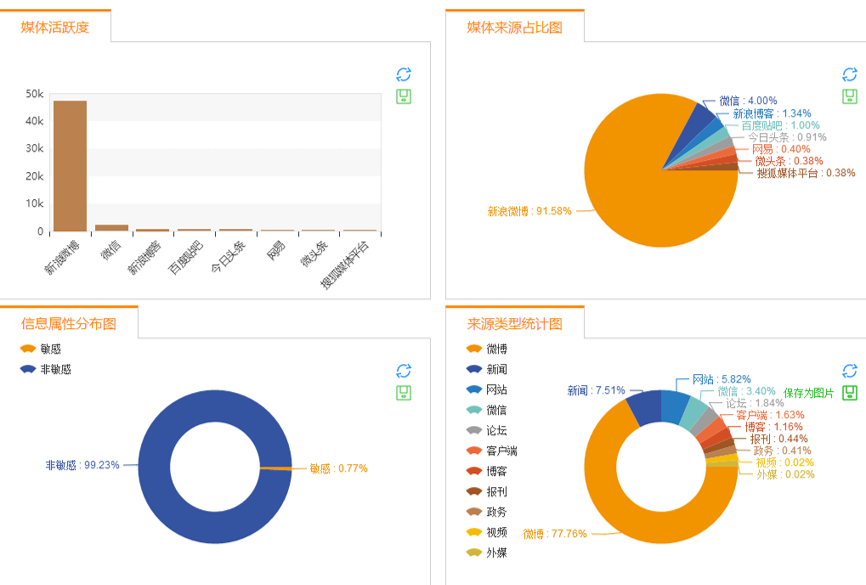
全网关于“青春文学”的信息量分布
将这些文本数据导出到本地,形成Excel格式文件,再按“青春文学”文本数据在上述传播渠道中所占的比重进行相应分层随机抽样,并进行同比例的人工随机抽样校准(看抽取的样本有没有问题,有的话及时剔除,再进行补充),最终得到1526条文本数据,如下图所示:
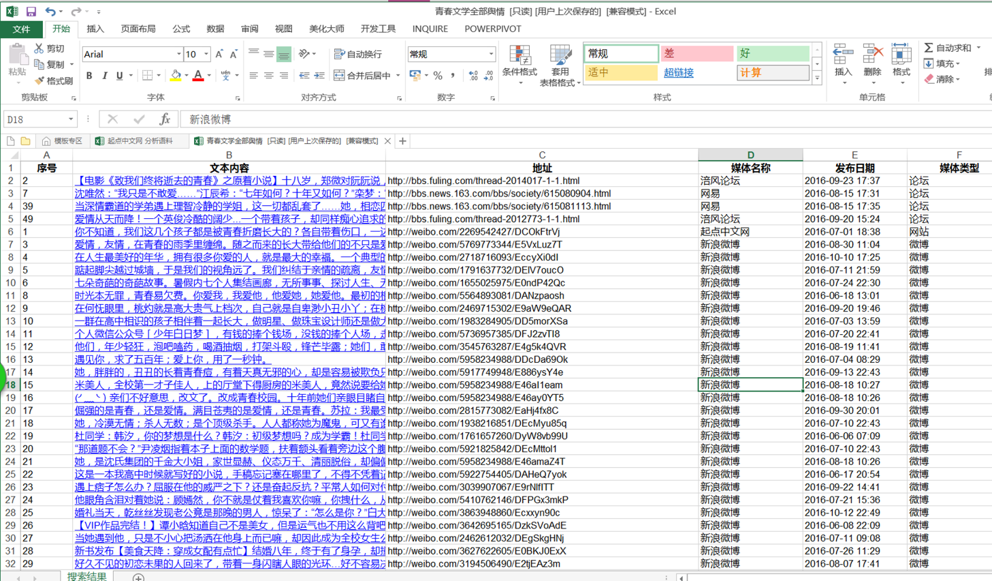
经抽样得到的最终分析文本数据
3.2 词频分析
经过系统处理,从这些定性语料中抽取出若干关键词形成词云,可以获得这些语料的初步印象,有一个直观的判断,见下图:

定性语料形成的关键词云
从上述关键词词云中,能直观的看到“爱情”、“故事”、“关系纠葛”(他们、你的、她们、她的、我们)、“青春”这些关键词,由此在直观上可以对公众号的内容运营方向有一个“朦胧”的感觉。
不过,这还不够细致,我们还需要进行更为深入的分析。
将语料中最为重要的150个关键词(按词频和权重)进行提取,下载到本地,然后基于对“青春文学”背景知识的了解,进行人工的词汇定性分类(见颜色标注),如下表显示:

从语料中提取出的150个重要关键词
从上述关键词表中,可以得出以下几类主题:
- 爱情(爱情、美好、爱上、遇见、幸福、火花、感情等)
- 校园(青春、学校、校园、高中、大学、同学、学院等)
- 美女(单纯、公主、可爱、萝莉、美丽、美女、妹妹、妹子、女生、女主角、最美等)
- 帅哥/美男(大人、高富帅、哥哥、老公、美男、帅哥、帅气、王子、阳光等)
- 拜金(千金、小姐、霸道、霸气、贵族、总裁等)
- 亲情(父亲、孩子、家族、母亲、亲情、兄弟等)
这些主题及其下辖关键词可以作为公众号的内容规划方向,或者是具体文章中需要体现的重要元素,当然笔者在进行公众号内容规划时会留其精华,对其“糟粕“内容进行剔除或重构,只生产优质内容。
接下来,笔者将对上述关键词及其主题进行语义网络分析,揭示出这些主题及其关键词之间错综复杂的关系,为将来的内容运营找到足以有吸引力的情节架构和写作套路。
3.3 语义网络分析
在对本案例进行语义网络分析之前,先科普下它的概念,因为直接进行分析的话,大家理解起来会有点困难,给大家的阅读带来障碍。
所以,暂且听笔者唠叨一下它的原理,对于下面的实例分析和今后的“迁移应用”大有裨益。
(1)语义网络分析和(词频)共现分析的原理
语义网络分析,原本是NLP(自然语言理解)及CS(认知科学领域)研究中的一个概念,用来表达复杂的概念及其之间的相互关系,是一个有向图(有起止方向),其顶点表示概念,而边则表示这些概念间的语义关系,从而形成一个由节点和连线构成的语义网络描述图。
笔者在这里提及的语义网络是基于共现分析原理。共现分析的方法论基础之一是心理学的邻近联系法则(是指曾经在一起感受过的对象往往在想象中也联系在一起,以致于想起它们中的某一个的时候,其他的对象也会以曾经同时出现时的顺序想起),因而它是一种将各种文本数据/信息中的共现信息定量化的分析方法, 以揭示信息的内容关联和特征项所隐含的寓意。
比如,在一段文本中,共同出现的特征项(以词汇的形式出现,如人名、地名、物品名、各类形容词、副词等)之间一定存在着某种关联,关联程度可用共现频次来测度。
比如,在小说中的几个人物及其相关词汇(姓名、动作和情感描述等)多次共同出现在小说的各个章节(及其段落),可以反映如下事实:
- 这几个人物存在着一定的人际关系(或好或坏);
- 共同出现的频次越高,说明这几个人物之间的人际关系的强度越高,关联程度越大;
- 文本数据中共同出现的多个关键词在内容属性上具有较强的相关性;
- 作者在写作小说时用到的关键词与作者的写作风格密切相关。
以阿耐的小说《欢乐颂》为例,摘取其中某段文本进行示例,如下图所示:

《欢乐颂》某个段落的人物共现分析
从上段文字可以看到,“五美”中的樊胜美、邱莹莹和关雎尔在这两段文字中重复出现,说明这三人存在一定强度(关系密切或打交道的频率较高)的人际关系,而邱莹莹和关雎尔一同出现的次数见多,说明她们的关系强度要强于二者同樊胜美之间的关系。
对全本小说进行语义网络分析,则可得到全本小说中的主要人物关系图谱,主要是以其中的五个女性角色为轴线来展开故事情节的,其中安迪的“戏份”最多。
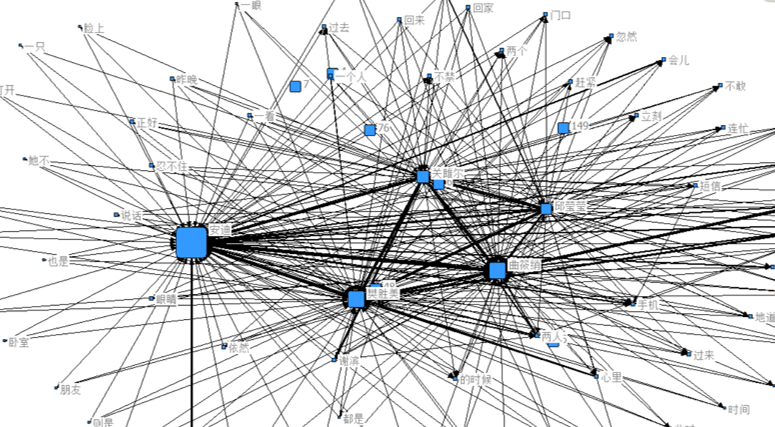
《欢乐颂》全本人物网络
在接下来的分析中,笔者希望通过对相关主题及其关键词之间的关系强度来启迪思路,找到哪些情节脉络或是写作套路比较受读者的青睐。
(2)对提取语料进行语义网络分析
对获取的语料进行语义网络分析,经调整后得到下图。
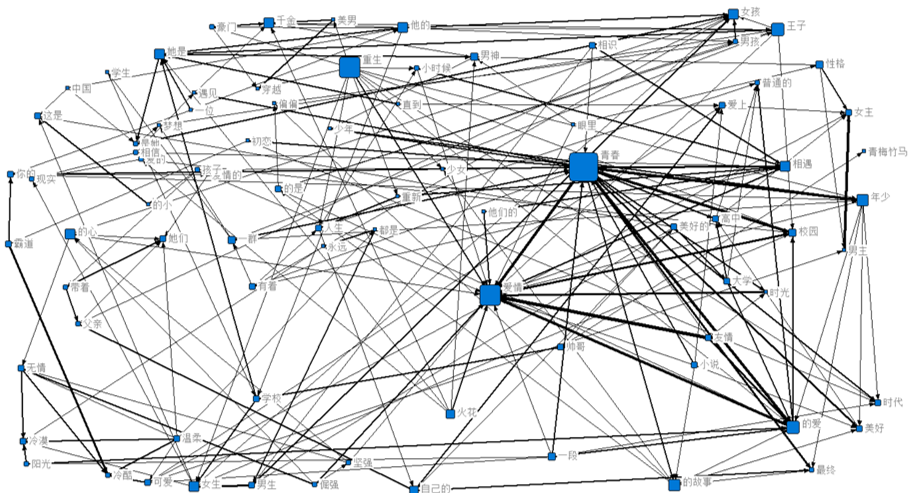
对语料中的200个关键词进行语义网络分析
上图中,根据各个词汇图标的大小及其之间的关系特征(线条粗细表示关系强弱,箭头指向“枢纽型”关键词)来找出主流线索,再结合“青春文学”的一些背景知识,分析结果如下:
- 脉络1:霸道-冷酷-无情-倔强-温柔-阳光-可爱
结合一般影视剧及小说情节,这是典型的玛丽苏遇到高冷高富帅,开始各种“傲慢与偏见”,但后来冰释前嫌、如胶似漆的套路,韩剧里上演过无数遍,具体情节请脑补,不解释。。。
- 脉络2:青春-年少-校园-相遇-相识-爱情-美好-最终-友情
主线很清晰,青春年少的男女猪脚在校园里(高中或大学)偶遇,再到相知相恋,度过美好的蜜月期,最终因为各种纠葛回归友情。。。
- 脉络3:豪门-千金-穿越-重生-小时候-相遇-美男-爱情
明眼人一看就知道是穿越题材,满身戾气的女主角穿越到过去,直接到了小时候,获得了新生,历经种种打磨和历练,和男主角终成正果…这块笔者不擅长,具体情节请脑补或者参照“千与千寻+步步惊心/穿越时空的少女”。。。
…
当然这样的思路还有很多,这些关键词及其之间的关系可以给我们的内容创作提供源源不断的思路,更重要的是,这些思路在某种程度上(大量数据积累)能反映目标人群的阅读偏好,可以作为我们内容输出时的参照系。
当然,这里是基于文本大数据得出的结构和框架,如果再结合内容创造者的妙笔生花的写作功力及真挚细腻的细节填充,相信也能“化腐朽为神奇”,写出如《步步惊心》《左耳》这样不落俗套的青春文学作品来。
4 公众号的定位与内容初始化
根据上面对目标人群的基本信息及阅读偏好进行间接获取后,综合得出下表:
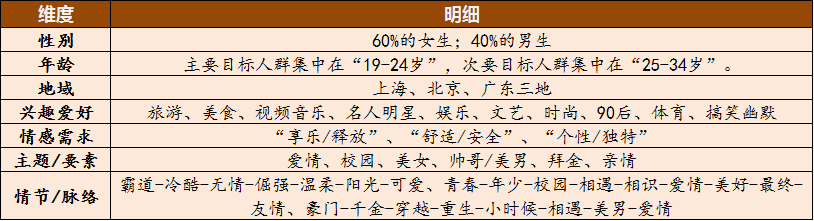
目标人群的群体画像及其阅读偏好
上表是接下来进行本公众号进行定位和内容初始化的依据,以下是其“分解”后的具体操作模块:
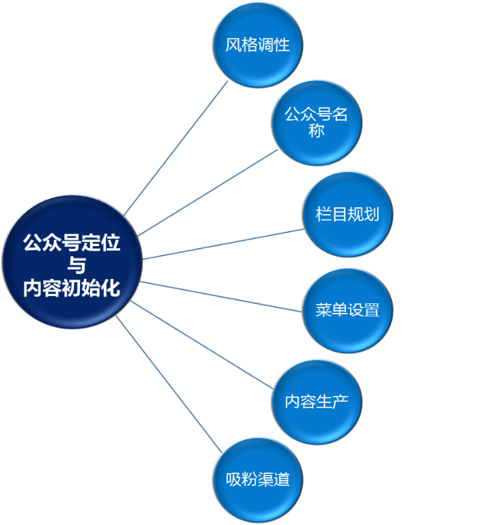
该公众号的定位和内容初始化
4.1 内容调性
(1)语言风格
公众号的语言风格,也就是“文风”,是严肃的、活泼的、文艺的,还是幽默的,直接取决去公众号所面对的目标群体是哪些。
根据上述目标人群的年龄段、性别、地域及兴趣标签分析,语言风格以广受年轻人青睐的幽默、活泼风格为好。
当然,也考虑到以韩寒、九夜茴那部分的读者,他们有很大比重是“25-34岁”这个年龄区间,相对成熟,所以还需要在行文风格上做到细腻、真诚,通过各种艺术构思成文,给予读者一种深沉、朴素的情感,使其感同身受。做到哪怕是穿越题材,也要写出《步步惊心》那样的感觉。
正如安妮宝贝在《春宴》的自序中写道:“时间有限,追索生命的诚意和真实,比什么都重要。这是我想写一个形式专注且立意单纯的小说的原因。”
(2)主题色彩
根据得到的3个情感需求区间—“享乐/释放”、“舒适/安全”、“个性/独特”,结合心理投射原理和性格色彩心理学,可以找到与之对应的人群心理适应色彩,在不同的文章或栏目中,可以搭配不同的颜色,力求在视觉上营造良好的阅读氛围,迎合读者的情感诉求。
3个情感需求区间对应的色彩如下:
- 享乐/释放:向日葵色和蜜柑色,对应着乐观/温暖、友善/欢愉的个性和品质,艳丽欢快,表征年轻人特有的活泼、奔放和乐天派。
- 舒适/安全:草绿色、灰白色,对应着平和/健康和平衡/温和的个性和品质,表征个性拘谨,惧怕改变的特质,但又渴求稳定和受保护。
- 个性/独特:菖蒲色,对应着创造/智慧的个性和品质,表征年轻人的独树一帜和标新立异。希望能“make a difference”。
本公众号的色系图谱如下图所示:

3个情感需求区间对应的色彩
(3)版式设计
公众号的内容输出很重要,但也要兼顾阅读者的阅读习惯,减少他们在阅读中的障碍,。
为此,本公众号设定的基本的排版准则为:

该公众号排版的基本准则
综合上述7个排版要求,目的是营造出一种长期稳定的总体风格:清新,很生活化。在映衬一些热烈、凸显张扬的文字时,会用很多颜色,突出生活的多彩,在表现伤逝的情感时,则会简简单单,干干净净,不显欢愉,也不见悲伤。
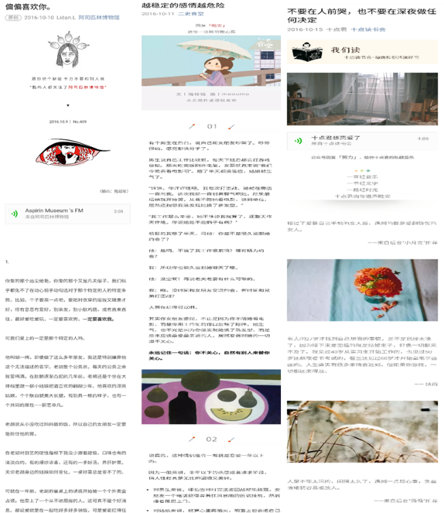
排版风格(类似阿司匹林博物馆、二更食堂和十点读书的排版)
通过语言风格、主题色彩和版式设计这三个维度,我们可以确定本公众号的定位/调性:
本公众号是一个关注青春文学的、有温度和彰显青春活力的“轻阅读”类微信公众号。
将该定位进行拆解,变为可以指导公众号内容运营的业务逻辑/铁律(需要严格遵守,不可轻易撼动):
- 青春文学:关注“校园”、“爱情”、“友情”、“成长”等青春类题材。
- 有温度:关注读者的内心世界和情感需求,体现人文关怀。
- 彰显活力:一改现有青春文学所透露出的颓废放纵和浪漫痛楚的文风,凸显青春应有的蓬勃朝气。
- 轻阅读:“轻阅读”是轻松的阅读,轻快的阅读,轻灵的阅读,‘“轻”不是没有分量,“轻阅读”是另一种重质感的阅读,它的目的在于使读者在短时间内娱目娱心,起到缓解压力、打发闲暇的作用。
做好上面的公众号定位和调性后,青春文学界的一股清流已经涌现~
4.2 公众号名称
古人云:“赐子千金,不如赐子佳名”,其缘由是一个人的名字会伴随人的一生,对其产生潜移默化和难以估量的影响。可见,起一个好的名字是多么的重要。
同理,公众号的名字(称)也是如此:
好的名字可以让人在几秒钟之内就知道公众号是做什么的,也方便目标人群的记忆,经过长时间持续的运营,逐渐形成占领粉丝心智的品牌。
尽管可以每年改一次名,但公众号的起名也要慎之又慎。
在用户画像和内容输出上的风格调性确定以后,给公众号“取名”的时机就成熟了。本公众号的名称拟定需要注意以下几个方面:
(1)关键字突出
取名要考虑关键字,它是名称的点睛之处,目的是让目标人群知道公众号的内容定位,打响自己的品牌。关键词的依据是公众号定位和目标人群阅读喜好。
(2)名称长度
名字最好是3-6个字,名字太短,公众号内名称处(大量数据显示这部分的粉丝来源居多)不容易点到;名称太短,容易搜索到其他家的号;此外,名称中不要包含各类符号,以便粉丝打字困难,中途放弃关注。
(3)取名风格
取名风格要与定位相符,主要是根据公众号定位和风格调性来确定。
由此,该公众号的名称拟定为“青葱悦读时光”(大家不要搜,这个号是虚拟不存在的哦),有着“青春”、“欢快”和“轻阅读”的寓意,符合上面谈及的公众号定位和调性。
4.3 栏目规划
这部分的设计是以目标人群的显性需求(目标人群的基本信息和讨论热点话题)和隐形需求(兴趣图谱和情感需求)为依据,且本公众号的内容输出形式采取的是短篇美文和小说连载相结合的形式。
基于上述考虑,同时掺入能带来广泛传播效应的UGC机制,形成如下具有操作性的栏目,作为今后公众号内容输出的指引:
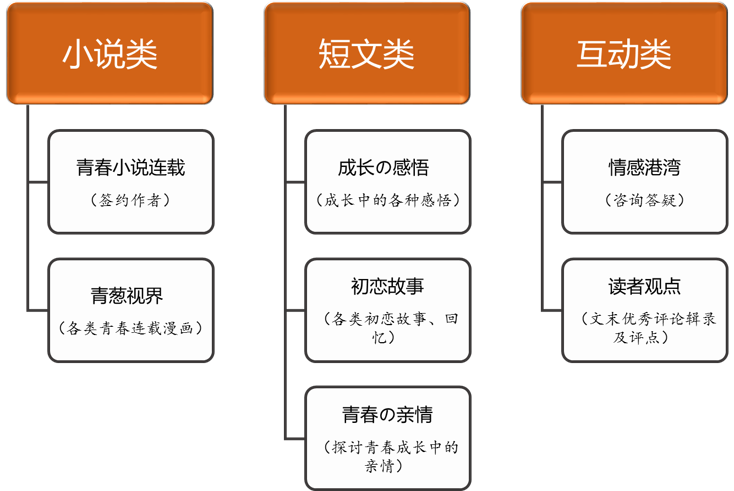
本公众号的内容规划
4.4 菜单设置
公众号的菜单设置要实现拉新、留存和促活/转化一整个内容/用户运营环节。同时,也需要结合用户画像、风格调性和栏目规划进行考虑,在初期可以将公众号的菜单栏进行如下设置:
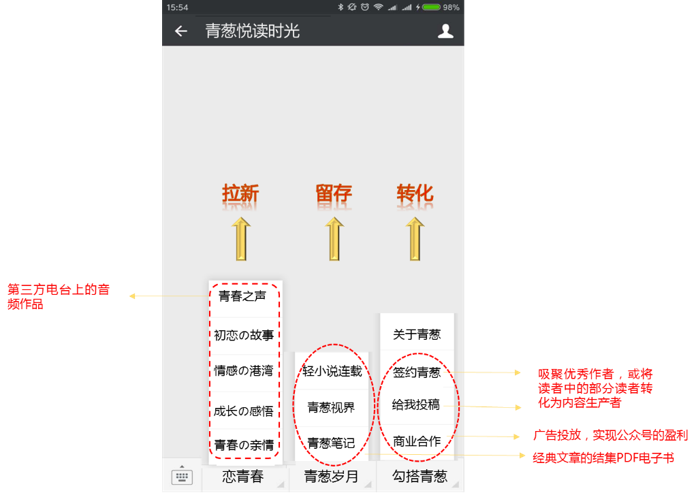
本公众号的菜单栏设置
4.5 内容生产
该公众号的内容生产需要注意两点,即内容生产方向及内容生产机制。内容生产的方向根据公众号的用户画像、定位/调性及栏目规划来确定,像经过语义网络分析得到的常用写作套路,可以用在小说创作方面,但大体原则是不偏离规划方向的。
下面着重谈谈本公众号的内容生产机制。
这里的内容生产在产生机制上分为:
- PGC(Professionally-generated Content,专业生产内容)
- UGC(User-generated Content,用户生产内容)
- OGC(Occupationally-generated Content,职业生产内容)
公众号上的PGC和UGC会有交集,因为部分专业内容生产者,可能既是该平台的用户,也会以专业身份(专家)贡献具有一定水平和质量的内容。
PGC和OGC也会有交集,因为一部分的专业内容生产者既有专业身份(具有中文专业的专业背景和学识),也以提供相应内容为职业(以写小说为业),他们以写稿为职业领取报酬。
本公众号运营初期,主要是以PGC为主,即运营人员自行生产内容(可以通过新浪微舆情这样的文本数据采集系统进行定向精准的素材采集,然后通过词频分析和语义网络分析得到思路启示,进行(伪)原创),达到一定规模之后会有部分的UGC,后期实现商业化资金充裕了就可以向OGC迈进,引入优秀且专业的写手或作家进行内容生产。
4.6 吸粉渠道
本公众号运营初期,其吸粉渠道主要靠外部拉新获取,三种方式:
(1)花钱砸广告/交换资源互推
可以有两种吸粉方式。一种是有财力的情况下,花钱砸广告,或是等积累一定粉丝后进行公众号互推,进行精准的粉丝获取,这时用户画像中的性别、年龄、地域和兴趣标签就起作用了。
有钱就砸广告进行推广
(2)定向软广发帖
如果财力不够雄厚,则需要自行到粉丝可能光顾的地方进行定向灌水发帖。这需要借助大数据工具进行定点搜寻,有点“增长黑客”的意思。找到风格一致且浏览量大的文章/帖子进行软性的公众号公关,这里的工作量较大,不过初期没钱的情况下只能如此了。。。
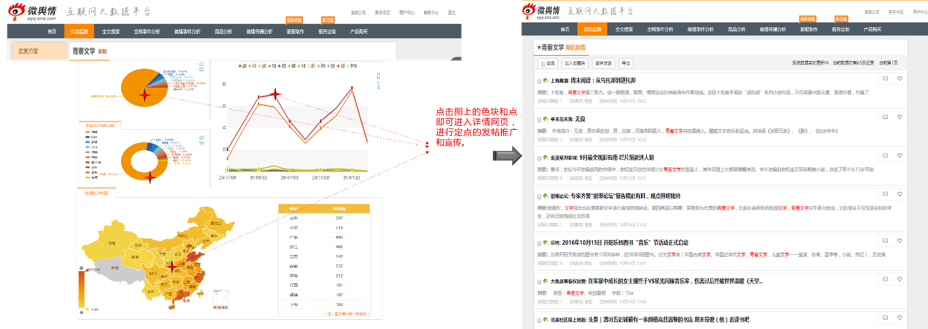
通过大数据工具找寻优质的灌水区
(3)到用户相同的垂直网站获取
如果能持续不断的生产优质的原创内容,则可以到青春文学类的垂直网站/社区进行粉丝获取。
知名且目标受众重合的文学网站/社区包括起点中文网、榕树下、豆瓣、简书等,可以到其中相应的模块发文或进行富有感召力的评论,获取方法无他,只能通过优质的内容进行粉丝集聚。
知名且目标受众重合的文学网站/社区
5 公众号定位及内容规划的校准
公众号的定位、调性和内容规划不是一成不变的,需要及时跟随外部环境和目标人群(阅读偏好)的变化而调整,这就需要我们定期做好公众号的定位和内容规划的校准,经常性的监测用户画像及阅读喜好的变化情况。
对公众号定位及内容规划的校准分为两个部分,即定量校准和定性校准。
5.1 定量校准
定量校准主要是对内容规划的校准。
根据一段时间内发布文章的阅读量、点赞量、收藏量或打赏量的情况识别出其中优质/劣质的题材,进行内容方面的优胜劣汰制。具体操作方法可参见《 运营实操|如何利用微信后台数据优化微信运营》。
5.2 定性校准
定性校准主要是对目标群体的校准。
这部分其实已经在上一篇关于用户情感需求挖掘的文章中有谈及,其操作步骤如下:
- 运营一段时间后,基于公众号现有粉丝群体,从性别、年龄或地域等维度,进行分层比例抽样(指按各个层的单位数量占调查总体单位数量的比例分配各层的样本数量的,以提高样本的代表性,避免出现简单随机抽样中的集中于某些特性或遗漏掉某些特性),抽取一定比例的粉丝,前提是使用各种方法加了这些粉丝为微信好友。
- 然后重点关注粉丝的昵称、头像、签名及近一段时间朋友圈所发内容,综合分析,给每个粉丝打不少于5个的兴趣标签,总体标签库可参照新浪微博的标签体系。
- 制作“兴趣-行为动机”对应表,最终得出粉丝的总体情感需求图谱。
经定量校准和定性校准后,需要重新绘制上述“目标人群的群体画像及其阅读偏好表”,根据实际情况调整公众号的定位及内容规划,与前面谈及的定位和内容规划不同,定位校准是基于公众号自身的数据,准确度会更高。
综上,本公众号定位法的难度在于找到合适的第三方用户画像获取渠道,及对应的阅读偏好挖掘,这需要对从事的领域有相当的了解,而这恰恰是数据分析解决不了的。
#专栏作家#
苏格兰折耳喵(微信公众号:Social Listening与文本挖掘),人人都是产品经理专栏作家,数据PM一只,擅长数据分析和可视化表达,热衷于用数据发现洞察,指导实践。
本文原创发布于人人都是产品经理。未经许可,禁止转载。




















依然是干货满满
真.读者~
我都看了你好几篇文章了,嘻嘻
希望对你有所帮助~
数据时从哪获取到的呢
上面有写的—新浪微舆情的“信息监测”模块
受益匪浅,打算按照您的方法进行实践
文章简洁有料,受益无穷。
(题外话:公众号名称建议为”青葱悦读“,念起来更舒服上口,青葱两个字可以涵盖时光变幻的意思,个人认为可以拿去时光两个字。)
哈哈,好主意
太有用了,如果有不明白的地方希望能够请教到您。
感觉智商欠费太多
何出此言?
说我自己。。最近刚好在做公众号的数据分析。看了文章觉得有很多维度要分析。特别是微舆情那块的excel导出,挺繁琐的。还在研究。其他的维度都有借鉴参考。很好的案例。人工点赞。
这个文本信息抽取和挖掘,是其中最繁琐的步骤,做好了,接下来的其他工作就好办了
我之前是做到了在微舆情上把设置好的标题名用excel表导出来。但有个问题,时间选择上只能输入最近三天的新闻,那些新闻标题名我自己手动选择了一百多条吧。并且生成excel表以后我也不大知道怎么转化成关键词词组。之前没做过这块。
厉害了word哥,目瞪口呆
不错不错,很有帮助!