
 起点课堂会员权益
起点课堂会员权益怎样从脏乱差的医疗大数据中提取价值(二)
编辑导语:上期讲到了随着大数据时代的到来,医疗信息化建设迫切的需求与医疗大数据的溯源过程,还深入的提出了在脏乱差的医疗大数据中怎么发现价值;接下来我们再进一步探讨一下数据的价值与特征。

一、数据特征
1)数据异构
多平台,多种接口,数据类型没有一个标准,只能是点对点的对接大量数据,内容冗杂,过程繁复,速度缓慢。
2) 主题分散性
就诊信息分布在不同的平台上,不能够形成以患者为中心的所有电子化就诊信息集成,不能提供完整、全面、准确、及时的患者临床信息。
3)数据量大
在大数据背景下,行业应用的数据量通常都以亿级别计算,存储通常在TB/PB级别甚至更多。
4)数据多态
数据模型在数据出现之后才能确定,数据模型随着数据量增长不断演变。
二、数据价值
数据流通:
- 院内流通、院外流通;
- 例如:从信息科流通到临床医务人员,从医院流通到卫生管理部分,从省内医院流通到省外医院。
数据开放:
- 面向个人:如查阅报告、健康评估、健康档案等;
- 面向企业、政府:调阅病理取证、获取群体用药信息、医疗数据监管等;
数据挖掘:
- 科研:科研统计分析和深度挖掘,如疗效分析等;
- 临床:如手术风险评估、预测模型建立等;
- 其他:医院管理、趋势分析等
三、数据产品
产品的定义:
建立数仓产品需依据卫生部统计信息中心2011年发布的《基于电子病历的医院信息平台建设技术解决方案》建立标准化医院数据资产目录。
数仓需以医院基础业务活动为索引,提供HIS、LIS、EMR等多数据源业务表字段绑定规则;实现零代码绑架,业务人员即可通过页面配置绑定规则。
数仓将根据配置自动生成调度任务,并通过Hadoop生态圈sqoop技术实现对业务系统的数据抽取;提供全量数据抽取与增量数据抽取两种方式,抽取过程实现透明、可追溯。
解决的问题:
- 实现以患者为中心的医疗信息采集、清洗、存储、加载和决策辅助。保障原始数据来源追溯、主数据标准唯一、数据应用及时高效。
- 实现基于数据中心的全量数据,构建应用主题库,为医院临床辅助、精细化运营管理、科研管理提供强有力的数据支撑。
- 实现“数据湖”数据资产目录,提高数据价值。
- 实现亿级别数据量查询、统计、分析秒处理展示。
四、产品功能
数据集成:
院内分散、异构数据依据颐东数仓资产目录表字段规则映射,并通过ETL工具实现历史数据、实时数据抽取转换。业务系统或集成平台之间进行数据字典与码表的映射转换,解决系统之间的数据一致性问题。新旧系统切换或系统升级,历史数据在新编码体系和分类体系下的转换和对接。
数据稽查:
用户可以根据需求上传需要比对的数据及相应标准,通过软件对数据进行一致性和准确性稽核。
疾病稽查:
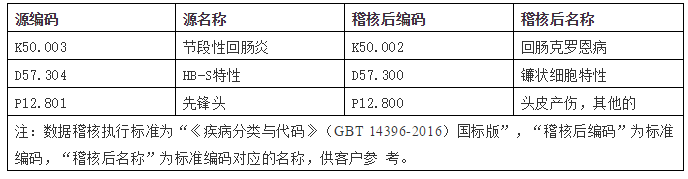
药品稽查:
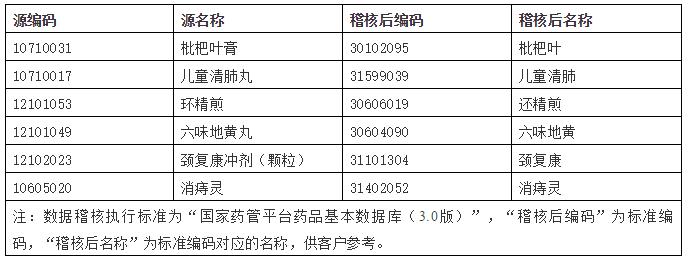
医疗知识库:主数据管理
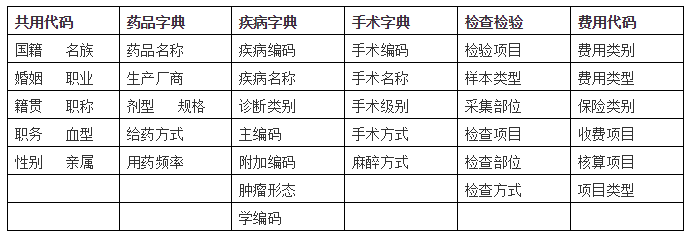
疾病、手术标准:

五、产品应用
1)数据治理
数据治理是治理多元异构的数据,治理数据资产,突出医疗价值,确保数据质量控制数据治理的过程要确保数据的完整性(事件、表单、记录、表项),一致性(主数据一致性、逻辑一致性),唯一性(无二义冗余、指标及计算口径),及时性,原始性,可溯源性及可测量性。
解决的问题:数据重复、一码多病、数据杂乱、脏数据多
治理的方案:通过数仓产品建立院内数据资产目录索引大数据中心
2)大数据中心
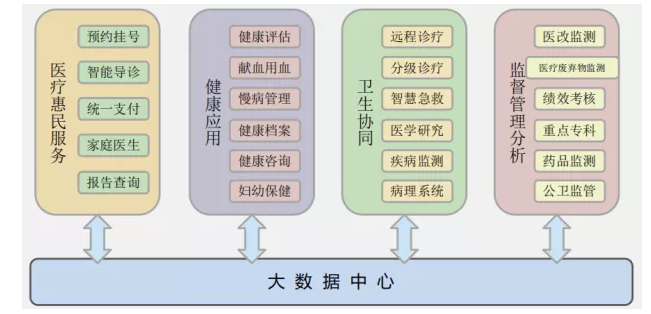
3)数据集市
根据临床科室构建应用主题库,为医院临床辅助、精细化运营管理、科研管理提供强有力的数据支撑。
4)数据上报
解决针对卫计委统计信息中心以《江苏省健康信息平台共享数据集》为基准上传的数据的数据稽核与表结构转换。
5)精准治理
单病种科研知识库,辅助治理。
六、产品特性
1)多种数据源
支持多种数据源,一键接入,无需繁琐配置。
2)零代码
简单易用的用户体验,零代码建立传输任务,降低企业用户使用门槛。
3)实时融合
实时的数据融合与集成,不让延迟成为瓶颈,保证数据的时效性。
4)开箱即用
简单快速的安装流程,高效部署生产环境,即装即用。
5)错误队列预警
群集监控、故障排除、扩容扩展、应急处理,完善纠错与预警机制。
6)安全审计
数据审计、数据盘点、权限认证、隐私处理。
7)全程质量管控
高质量体系保障数据传输的安全性与准确性,真正实现数据无忧。
8)数据服务
开放接口,开放数据,开放服务,支持第三方嫁接服务。
9)大数据生态系统
Hadoop生态系统中集成了大量的工具和组件来满足不同计算和存储需求,比如HDFS分布式文件系统、HBase列式数据库、Hive数据仓库、Kafka服务编排、MapReduce服务调度、impala类SQL数据仓库等,可以方便地进行数据存储和分析计算。
产品技术架构:
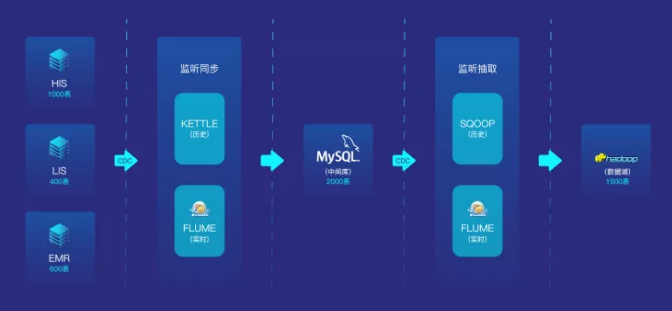
数据仓库(ETL) + 自然语言处理(NPL)+大数据技术(Hadoop)+安全通信(OAuth2.0、密码学、CAS)
七、名词解释
CDC又称变更数据捕获(Change Data Capture),开启cdc的源表在插入INSERT、更新UPDATE和删除DELETE活动时会插入数据到日志表中;CDC通过捕获进程将变更数据捕获到变更表中,通过cdc提供的查询函数,我们可以捕获这部分数据。
ETL数据仓库技术(Extract-Transform-Load),它是将数据从源系统加载到数据仓库的过程。用来描述将数据从来源端经过萃取(extract)、转置(transform)、加载(load)至目的端的过程。使用到的工具包含(kettle、flume、sqoop)。
Kettle基于JAVA的ETL工具,支持图形化的GUI设计界面,然后可以以工作流的形式流转,在做一些简单或复杂的数据抽取、质量检测、数据清洗、数据转换、数据过滤等方面有着比较稳定的表现。
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
Sqoop是Apache开源软件,主要用于在HADOOP(Hive)与传统的数据库(mysql、postgresql…)间进行数据的传递;适用于能与大数据集群直接通信的关系数据库间的大批量数据传输。
本文由 @CTO老王 原创发布于人人都是产品经理,未经许可,禁止转载
题图来自 Unsplash,基于 CC0 协议






- 目前还没评论,等你发挥!


