
 起点课堂会员权益
起点课堂会员权益创业必称“大数据”?是时候重新审视大数据的价值了!

大数据到底是什么?它是一项技术、一个产业还是一种思维方式?当越来越多的人将兴趣转移到AI、VR上时,也许是时候重新审视大数据的价值了。
“大数据”这个概念大约是从2011年开始火起来的,如果从Apache Hadoop项目的正式启动算起,海量数据的分布式存储、管理和计算技术已有10年的历史。这10年里,创业圈逐渐流行起一种通病,但凡创业必称“大数据”,似乎每个创业项目都会多少与之关联。
在IT领域,一项技术的价值得以验证并实现往往需要走完四个阶段:技术原创、开源、产业化和广泛应用。在这个过程中,新技术的使用从互联网巨头企业蔓延到整个互联网领域,并随着其产业生态的日臻完善,最终应用到更广泛的社会和行业领域。“大数据”也不例外,它经历了底层技术的兴起和发展、产业生态的构建,正逐步渗透到每个企业的数据化战略之中。只有把握整条脉络,窥探“大数据”的全貌,才能理解这项技术的缘起和未来。
技术篇
移动互联网时代,数据量呈现指数级增长,其中文本、音视频等非结构数据的占比已超过85%,未来将进一步增大。Hadoop架构的分布式文件系统、分布式数据库和分布式并行计算技术解决了海量多源异构数据在存储、管理和处理上的挑战。
从2006年4月第一个Apache Hadoop版本发布至今,Hadoop作为一项实现海量数据存储、管理和计算的开源技术,已迭代到了v2.7.2稳定版,其构成组件也由传统的三驾马车HDFS、MapReduce和HBase社区发展为由60多个相关组件组成的庞大生态,包括数据存储、执行引擎、编程和数据访问框架等。其生态系统从1.0版的三层架构演变为现在的四层架构:
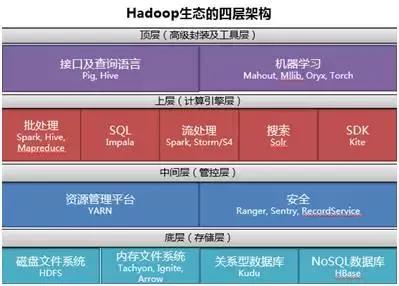
底层——存储层
现在互联网数据量达到PB级,传统的存储方式已无法满足高效的IO性能和成本要求,Hadoop的分布式数据存储和管理技术解决了这一难题。HDFS现已成为大数据磁盘存储的事实标准,其上层正在涌现越来越多的文件格式封装(如Parquent)以适应BI类数据分析、机器学习类应用等更多的应用场景。未来HDFS会继续扩展对于新兴存储介质和服务器架构的支持。另一方面,区别于常用的Tachyon或Ignite,分布式内存文件系统新贵Arrow为列式内存存储的处理和交互提供了规范,得到了众多开发者和产业巨头的支持。
区别于传统的关系型数据库,HBase适合于非结构化数据存储。而Cloudera在2015年10月公布的分布式关系型数据库Kudu有望成为下一代分析平台的重要组成,它的出现将进一步把Hadoop市场向传统数据仓库市场靠拢。
中间层——管控层
管控层对Hadoop集群进行高效可靠的资源及数据管理。脱胎于MapReduce1.0的YARN已成为Hadoop 2.0的通用资源管理平台。如何与容器技术深度融合,如何提高调度、细粒度管控和多租户支持的能力,是YARN需要进一步解决的问题。另一方面,Hortonworks的Ranger、Cloudera 的Sentry和RecordService组件实现了对数据层面的安全管控。
上层——计算引擎层
在搜索引擎时代,数据处理的实时化并不重要,大多采用批处理的方式进行计算。但在SNS、电子商务、直播等在线应用十分普及的今天,在不同场景下对各类非结构化数据进行实时处理就变得十分重要。Hadoop在底层共用一份HDFS存储,上层有很多个组件分别服务多种应用场景,具备“单一平台多种应用”的特点。
例如,Spark组件善于实时处理流数据,Impala实现诸如OLAP的确定性数据分析,Solr组件适用于搜索等探索性数据分析,Spark、MapReduce组件可以完成逻辑回归等预测性数据分析,MapReduce组件可以完成数据管道等ETL类任务。其中,最耀眼的莫过于Spark了,包括IBM、Cloudera、Hortonworks在内的产业巨头都在全力支持Spark技术,Spark必将成为未来大数据分析的核心。
顶层——高级封装及工具层
Pig、Hive等组件是基于MapReduce、Spark等计算引擎的接口及查询语言,为业务人员提供更高抽象的访问模型。Hive为方便用户使用采用SQL,但其问题域比MapReduce、Spark更窄,表达能力受限。Pig采用了脚本语言,相比于Hive SQL具备更好的表达能力。
在结构化数据主导的时代,通常使用原有模型便可以进行分析和处理,而面对如今实时变化的海量非结构化数据,传统模型已无法应对。在此背景下,机器学习技术正慢慢跨出象牙塔,进入越来越多的应用领域,实现自动化的模型构建和数据分析。
除了Mahout、MLlib、Oryx等已有项目,最近机器学习开源领域迎来了数个明星巨头的加入。Facebook开源前沿深度学习工具“Torch”和针对神经网络研究的服务器“Big Sur”;Amazon启动其机器学习平台Amazon Machine Learning;Google开源其机器学习平台TensorFlow;IBM开源SystemML并成为Apache官方孵化项目;Microsoft亚洲研究院开源分布式机器学习工具DMTK。
产业篇
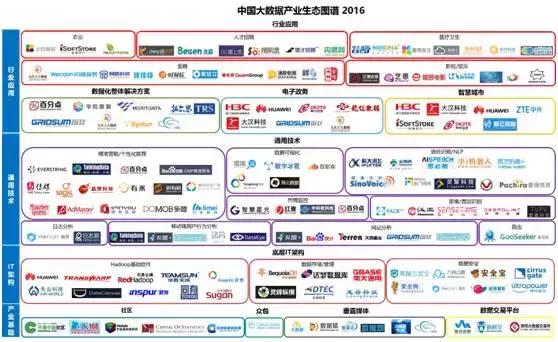
一项技术从原创到开源社区再到产业化和广泛应用往往需要若干年的时间。在原创能力和开源文化依然落后的中国,单纯地对底层技术进行创新显然难出成果。尽管如此,在经济转型升级需求的驱动下,创业者大量采用C2C(Copy to China)的创业模式快速推动着中国大数据产业的发展,产业生态已初步成型。
产业基础层
如果说数据是未来企业的核心资产,那么数据分析师便是将资产变现的关键资源。以数据流通及人才培养和流通为目标,社区、众包平台、垂直媒体、数据交易平台是数据产业发展壮大的土壤。
社区
大数据技术社区为产业建立了人才根基。社区天然具备社群和媒体属性,自然吸引了众多专业人才。正基于此,开源中国社区(新三板挂牌企业)和Bi168大数据交流社区同时开展了代码托管、测试、培训、招聘、众包等其他全产业链服务。
众包
人力资本的高效配置是产业发展的必要条件。Data Castle类似于硅谷的Kaggle,是一家数据分析师的众包平台。客户提交数据分析需求、发布竞赛,由社区内众多分析师通过竞赛的方式给予最优解决方案。
垂直媒体
36大数据、数据猿、数据观等大数据垂直媒体的出现推动了大数据技术和文化的传播。它们利用媒体的先天优势,快速积累大量专业用户,因此与社区类似,容易向产业链其他环节延伸。
数据交易平台
数据交易平台致力于实现数据资产的最优化配置,推动数据开放和自由流通。数据堂和聚合数据主要采用众包模式采集数据并在ETL之后进行交易,数据以API的形态提供服务。由于保护隐私和数据安全的特殊要求,数据的脱敏是交易前的重要工序。贵阳大数据交易所是全球范围内落户中国的第一家大数据交易所,在推动政府数据公开和行业数据流通上具有开创性的意义。
IT架构层
开源文化为Hadoop社区和生态带来了蓬勃发展,但也导致生态的复杂化和组件的碎片化、重复化,这催生了IBM、MapR、Cloudera、Hortonworks等众多提供标准化解决方案的企业。中国也诞生了一些提供基础技术服务的公司。
Hadoop基础软件
本领域的企业帮助客户搭建Hadoop基础架构。其中,星环科技TransWarp、华为FusionInsight是Hadoop发行版的提供商,对标Cloudera CDH和Hortonworks的HDP,其软件系统对Apache开源社区软件进行了功能增强,推动了Hadoop开源技术在中国的落地。星环科技更是上榜Gartner 2016数仓魔力象限的唯一一家中国公司。
数据存储
管理2013年“棱镜门”后,数据安全被上升到国家战略高度,去IOE正在成为众多企业必不可少的一步。以SequoiaDB(巨杉数据库)、达梦数据库、南大通用、龙存科技为代表的国产分布式数据库及存储系统在银行、电信、航空等国家战略关键领域具备较大的市场。
数据安全
大数据时代,数据安全至关重要。青藤云安全、安全狗等产品从系统层、应用层和网络层建立多层次防御体系,统一实施管理混合云、多公有云的安全方案,并利用大数据分析和可视化展示技术,为用户提供了分布式框架下的WAF、防CC、抗DDoS、拦病毒、防暴力破解等安全监控和防护服务,应对频繁出现的黑客攻击、网络犯罪和安全漏洞。
通用技术层
日志分析、用户行为分析、舆情监控、精准营销、可视化等大数据的通用技术在互联网企业已有相当成熟的应用。如今,越来越多的非互联网企业也在利用这些通用技术提高各环节的效率。
日志分析
大型企业的系统每天会产生海量的日志,这些非结构化的日志数据蕴含着丰富的信息。对标于美国的Splunk,日志易和瀚思对运维日志、业务日志进行采集、搜索、分析、可视化,实现运维监控、安全审计、业务数据分析等功能。
用户行为分析
移动端用户行为分析为提升产品用户体验,提高用户转化率、留存率,用户行为分析是必不可少的环节。TalkingData和友盟等企业通过在APP/手游中接入SDK,实现对用户行为数据的采集、分析与管理。大量的终端覆盖和数据沉淀使得这类企业具备了提供DMP和移动广告效果监测服务的能力。GrowingIO更是直接面向业务人员,推出了免埋点技术,这一点类似于国外的Heap Analytics。
网站分析
百度统计、CNZZ及缔元信(后两者已与友盟合并为友盟+)等产品可以帮助网站开发运营人员监测和分析用户的点击、浏览等行为,这些公司也大多提供DMP和互联网广告效果监测服务。
网页爬虫
是一种快速搜索海量网页的技术。开源的爬虫技术包括Nutch这样的分布式爬虫项目,Crawler4j、WebMagic、WebCollector等JAVA单机爬虫和scrapy这样的非JAVA单机爬虫框架。利用这些开源技术,市场上出现了很多爬虫工具,其中八爪鱼的规模和影响力最大,该公司也基于此工具推出了自己的大数据交易平台数多多。
舆情监控
智慧星光、红麦等互联网舆情公司利用网络爬虫和NPL技术,为企业用户收集和挖掘散落在互联网中的价值信息,助其完成竞争分析、公关、收集用户反馈等必要流程。
精准营销
个性化推荐以完整的用户标签为基础,精准营销、个性化推荐技术在广告业、电商、新闻媒体、应用市场等领域得到广泛应用。利用SDK植入、cookie抓取、数据采购和互换等途径,TalkingData、百分点、秒针、AdMaster等众多DSP、DMP服务商积累了大量的用户画像,并可实现用户的精准识别,通过RTB技术提高了广告投放的实时性和精准度。将用户画像及关联数据进一步挖掘,利用协同过滤等算法,TalkingData、百分点帮助应用商店和电商平台搭建了个性化推荐系统,呈现出千人千面的效果。另一家利用类似技术的典型企业Everstring则专注于B2B marketing领域,为用户寻找匹配的企业客户。
数据可视化
可视化是大数据价值释放的最后一公里。大数据魔镜、数字冰雹等公司具备丰富的可视化效果库,支持Excel、CSV、TXT文本数据以及Oracle、Microsoft SQL Server、Mysql等主流的数据库,简单拖曳即可分析出想要的结果,为企业主和业务人员提供数据可视化、分析、挖掘的整套解决方案及技术支持。
面部/图像识别
面部/图像识别技术已被广泛应用到了美艳自拍、身份识别、智能硬件和机器人等多个领域。Face++和Sensetime拥有人脸识别云计算平台,为开发者提供了人脸识别接口。汉王、格灵深瞳和图普科技则分别专注于OCR、安防和鉴黄领域。
语音识别/NLPNLP(自然语言处理)
是实现语音识别的关键技术。科大讯飞、云知声、出门问问、灵聚科技、思必驰等企业已将其语音识别组件使用在智能硬件、智能家居、机器人、语音输入法等多个领域。小i机器人和车音网则分别从智能客服和车载语控单点切入。
行业应用层
每个行业都有其特定的业务逻辑及核心痛点,这些往往不是大数据的通用技术能够解决的。因此,在市场竞争空前激烈的今天,大数据技术在具体行业的场景化应用乃至整体改造,蕴藏着巨大的商业机会。然而,受制于企业主的传统思维、行业壁垒、安全顾虑和改造成本等因素,大数据在非互联网行业的应用仍处于初期,未来将加速拓展。
数据化整体解决方案
非互联网企业的数据化转型面临着来自业务流程、成本控制及管理层面的巨大挑战,百分点、美林数据、华院数据等服务商针对金融、电信、零售、电商等数据密集型行业提供了较为完整的数据化解决方案,并将随着行业渗透的深入帮助更多的企业完成数据化转型。
电子政务政府效率的高低关系到各行各业的发展和民生福祉,电子政务系统帮助工商、财政、民政、审计、税务、园区、统计、农业等政府部门提高管理和服务效率。由于用户的特殊性,电子政务市场进入门槛高,定制性强,服务难度大。典型的服务商包括龙信数据、华三、国双、九次方等。
智慧城市
智慧城市就是运用信息和通信技术手段感测、分析、整合城市运行核心系统的各项关键信息,从而对包括民生、环保、公共安全、城市服务、工商业活动在内的各种需求做出智能响应。华三、华为、中兴、软通动力、大汉科技等公司具备强大的软硬件整合能力、丰富的市政合作经验和资源积累,是该领域的典型服务商。
金融大数据技术
在金融行业主要应用在征信、风控、反欺诈和量化投资领域。聚信立、量化派结合网络数据、授权数据和采购数据为诸多金融机构提供贷款者的信用评估报告;闪银奇异对个人信用进行在线评分;同盾科技倡导“跨行业联防联控”,提供反欺诈SaaS服务;91征信主打多重负债查询服务;数联铭品搭建第三方企业数据平台,提供针对企业的全息画像,为金融和征信决策做参考。通联数据和深圳祥云则专注于量化交易。
影视/娱乐
中国电影的市场规模已居全球第二,电影产业的投前风控、精准营销、金融服务存在巨大的市场空间。艾曼、艺恩基于影视娱乐行业的数据和资源积累,抓取全网的娱乐相关信息,提供影视投资风控、明星价值评估、广告精准分发等服务。牧星人影视采集演员档期、性别、外形、社交关系、口碑以及剧组预算等数据,为剧组招募提供精准推荐。
农业大数据
在农业主要应用在农作物估产、旱情评估、农作物长势监测等领域。由于农业信息资源分散、价值密度低、实时性差,服务商需要有专业的技术背景和行业经验。典型企业包括太谷雨田、软通动力、武汉禾讯科技等。行业整体数据化程度低、进入门槛高。
人才招聘
我国人才招聘行业缺乏对人才与职位的科学分析,没有严谨的数据体系和分析方法。E成招聘、北森、搜前途、哪上班基于全网数据获取候选人完整画像,通过机器学习算法帮助企业进行精准人岗匹配;内聘网基于文本分析,实现简历和职位描述的格式化和自动匹配。
医疗卫生
大数据在医疗行业主要应用于基因测序、医疗档案整合和分析、医患沟通、医疗机构数据化和新药研制等环节。华大基因和解码DNA提供个人全基因组测序和易感基因检测等服务。杏树林面向医生群体推出了电子病历夹、医学文献库等APP。医渡云则致力于与领先的大型医院共建“医疗大数据”平台,提高医院效率。
企业转型篇
尽管技术的日益创新和逐渐完善的产业配套创造了良好的外部环境,只有将“数据驱动”的理念根植于企业本身才能充分发挥大数据的价值。对于一家企业来说,真正的数据化转型绝不仅仅是互联网营销或舆情监控这么简单,它需要战略层面的规划、管理制度的革新和执行层面的坚决。这里提出了数据化转型的8个步骤,这些建议并没有必然的时间先后或逻辑关系,藏在背后的大数据理念,或许更加重要。
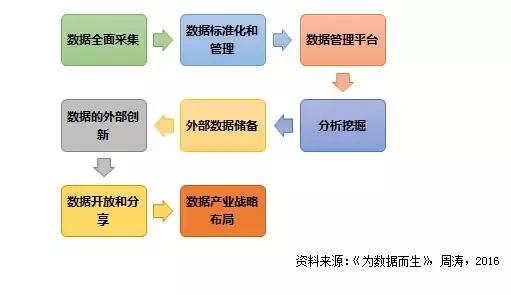
1. 数据全面采集
要求企业采集并存储企业生产经营中的一切数据,形成企业数据资产的理念。
2. 整理数据资源,建立数据标准形成管理
成立数据委员会,建立数据目录和数据标准,对数据进行分级分权限的管理,实现数据的统一管理和可追溯。随时了解哪位员工在什么时间点在哪一台设备上运用何种权限如何使用。
3. 建设数据管理平台
建设具备存储灾备功能的数据中心,以业务需要为引导,定做一套数据组织和管理的解决方案,硬件方面强调鲁棒性和可扩展性,没有必要一开始就投入大量经费。
4. 建立海量数据的深入分析挖掘能力
培养非结构化数据的分析处理能力和大数据下的机器学习的能力。
5. 建立外部数据的战略储备
外部数据对于市场拓展、趋势分析、竞品分析、人才招聘、用户画像和产品推荐等意义重大,而网站、论坛、社交媒体和电商平台上聚集了很多有重要价值的公开数据。
6. 建立数据的外部创新能力
企业通过智能终端、传感网络、物流记录、网点记录和电子商务平台等等,获得的第一手数据,很多都可以用于支持在跨领域交叉销售、环境保护、健康管理、智慧城市、精准广告和房地价预测等方面的创新型应用。
7. 推动自身数据的开放与共享
要充分借助社会的力量,尽最大可能发挥数据潜藏的价值。Netflix曾经公开了包含50多万用户和17 770部电影的在线评分数据,并悬赏100万美元奖励能够将Netflix现有评分预测准确度提高10%的团队。
8. 数据产业的战略投资布局
通过投资的方式迅速形成自己的大数据能力甚至大数据产业布局。
结语
在Gartner的炒作周期曲线上,“大数据”概念已从顶峰滑落到了谷底,产业似乎陷入停滞。但当我们沿着技术起源、产业生态和企业战略的脉络重新审视大数据时,我们发现大数据产业不仅不会停滞,反而将加速渗透到更多行业的各类场景中去,并根植在企业战略、管理和文化之中。只有当各行各业的企业运营实现数据驱动时,大数据的价值才真正落地,然而这条路还很长。
作者:星河互联
来源:http://www.36dsj.com/archives/66073
本文来源于人人都是产品经理合作媒体@36大数据,作者@星河互联









讲解的点太多,不是很明白
看不太懂