
 起点课堂会员权益
起点课堂会员权益数仓避坑-整明白懂粒度
编辑导语:在数仓中,你理解什么是粒度吗?这是一个很抽象的名词,但同时它又是数仓中重要的一个概念。作者通过五个方面总结如何把粒度整明白的方法,我们一起来看下吧。

上篇文章数仓避坑-搞懂维度模型介绍了维度建模经典的四部曲:选定业务过程、声明粒度、确定维度、确定事实。
第二步中,粒度的概念着实有点抽象,很难理解。但是,如果粒度整不明白,近乎等于数仓没入门,你将会面临一系列问题~
今天就给大家分享一下,我踩坑粒度的过程。
一、先说说粒度的概念
选定了分析的过程,紧接着就要声明粒度。看到书里这么说,我当时的反应是:为什么?粒度是什么?普通场景里,粒度可以理解为一个东西的大小。
比如,钻石要区分颗粒度,大小不同的钻石,价格不一。而在数据分析的语境里,粒度则意味着分析的范围,分析的细致程度。举两个例子。
系统的注册总人数,可以按照国家、省份来统计,这是地域层面上的不同统计粒度。系统的活跃用户数,可以按天、按周统计登录人数,这是时间层面上不同的统计粒度。
从数据表的角度来看,粒度则解释着什么情况下增加一条记录。按国家统计用户数,中国只会有一条记录,按省统计,中国则会有34条记录。
按周统计活跃用户,一年只会有 52 行记录,按天统计,一年则有 365 或 366 条记录。
二、通过实战理解粒度
好,看书搞懂了概念,实战就来了。公司出了新 APP,老板很关心新 APP 的用户活跃程度,于是,用户端产品经理希望做个面板,看每天有多少人登录。
同时,他提了另一个需求,他希望能支持统计两个日期区间内的登录人数(两个日期是变化的)。
通过例子理解:某个活动发布后,要查看不同时间区间内的累积活跃用户数,比如1-2号,3-5号,以便及时调整促活的策略。
初生牛犊不怕虎,说搞咱就搞,就按照维度建模经典套路搞。
首先,选定业务过程。这个一目了然,自然就是用户登录过程。
其次,声明粒度。这里用户方希望按照不同的日期统计累积人数,那粒度是天。
然后,是确定维度。这个例子里,因为要按照日期分析,最主要的维度是日期(为了简单,例子里就就先不考虑其他维度了),日期维度表设计如下:
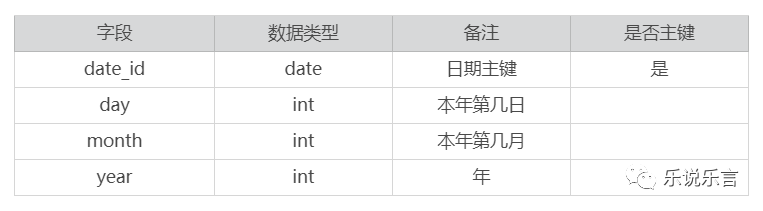
最后,设计事实表。这个也不难,用户登录事实表(fact_loign)设计如下:
三下五除二,维度模型搞定!就等写好 ETL 脚本,按周期调度啦。
三、维度模型搞不定,是粒度理解不到位
构建模型,最终都是为了查出对应的指标和结果,所以维度模型通常都会跟标准的指标系统配套来使用。对指标体系不太了解的朋友可以看这篇:
一文帮你更好地理解指标,或者看华为阿里的产品。当我们按照标准套路,进入指标设计阶段,问题就会慢慢浮出水面了。基于事实表模型,我们很容易设计原子指标【登录人数】,其计算逻辑为
count(fact_login.user_id)
进而,我们也能设计出衍生指标【日期_登录人数】,其口径为:
select distinct count(fact_login.user_id) from fact_loginleft join dim_date on date.date_key = fact_login.login_dategroup by dim_date.date_key
从衍生指标这里,就能发现问题了。你会发现,group by 后的结果,是按照每天进行去重的。
最终的结果,只能是统计每天范围内的累积登录人数。用户的期望是,统计某个时间区间内的累积登录人数,这个需求维度模型产生的指标没法满足。如果事实表的真实数据如下: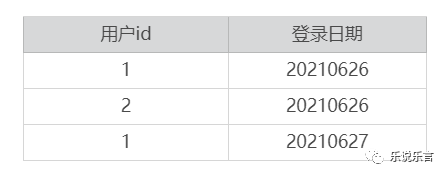
基于维度模型,系统可以生成这样的汇总表:
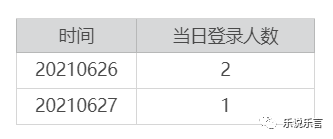
但系统无法生成如下汇总表:
需求只能搞定一般,这可怎么交差?
四、粒度是搞清问题的关键
刚开始,我很疑惑,想了各种办法也没办法解决。后来才意识到,问题根源其实是粒度。
让我们回归到真实场景里:登录成功,这个事件发生在一瞬间。常见的时间计量单位有年、月、天、小时、分钟、秒、毫秒、微秒等等。而系统记录某个操作,常见的记录粒度是秒。
比如, 2021 年 6 月 27 号 14 : 00 : 00,小明登录了系统。如果按照秒去统计登录人数,则完全不用考虑去重,因为小明在这个粒度的计量单位里,只能登录一次。但秒级别的统计粒度,太细了。
业务方希望从更加宏观的角度去统计和分析,例子里面,是以天为单位去统计。
那这个时候,统计就要升粒度了,并且,要去重。此时,系统也是可以按照天的粒度进行去重统计的。那问题又是啥呢?再看看实际需求时,统计的时间区间是不固定的。
即,业务方可能今天想统计 1 号到 2 号的登录人数,明天想统计 3 号到 5 号的登录人数。这个时候,就没法玩了,为什么呢?
粒度不固定:1-2号,间隔时间是1天,3-5号,间隔时间则是2天。维度建模中,声明粒度就是要把粒度的大小定下来。
不管是什么维度,都要提前把粒度定下来,这样才能实现累计去重。
从技术实现的角度来看,如果查询的粒度,是一个变量,而不是一个固定值,没法提前计算,只能临时用明细表算,这就叫做即系查询。
所以,这个需求中,维度建模只能解决前面部分的需求:按照天去重统计每天登录人数。而变化区间的去重统计,只能即席查询了。
五、最后,说点学习经验
维度建模工具箱这本书,一再强调粒度的重要性,大概率就是因为粒度这玩意,太抽象,不好理解。
当初,我就在这上面理解出了差错,陷在维度建模的漩涡里。
本人愚笨,看书好久,都没明白粒度的真正含义,被真实业务需求痛扁一顿后,我才体会到粒度的真正含义。
作为一个新人,接触到新的方法或者工具,我们是兴奋的。
与此同时,我们也要谨防 “捡到锤子,看什么都像钉子”,没有能解决所有问题的方法和工具,特定场景,选用特定的工具。死磕核心概念,结合实际场景去理解,搞懂了,很多问题就通了~
作者:lee;公众号:乐说乐言
本文由 @lee 原创发布于人人都是产品经理,未经许可,禁止转载
题图来自 Unsplash,基于 CC0 协议









没太理解这个需求的难度在哪里,sql改改,或者复杂点直接用spark,都很容易啊
手写SQL自然是可以随便改呀,我想强调的是,粒度不同,SQL也不同,那基于指标口径就没办法生成了。
某个方法给了一个方的模具,用这个方法,搞出来的肉丸子肯定是方的,但需求方希望肉丸子是圆的。我重点想说的是,用这个方模具搞不来圆的。然后您说,用手捏可以捏出来圆的。大概如此吧。
颗粒度还有一个重要的概念,就是大的颗粒并不是小颗粒的累加。就像2两一个的螃蟹卖10元一只,4两一个的螃蟹并不卖20元一只,有可能是40元。
数据分析的场景里面,粒度问题多数都是去重引起的。
不过您这个生活化的例子挺好,感谢补充~
2两的螃蟹和4两的螃蟹,你这不是颗粒度了,是维度了。
2个2两一个的原价必然卖20。