
 起点课堂会员权益
起点课堂会员权益当toB产品经理遇到数据分析
编辑导语:toB产品经理不仅需要与设计师打交道,还需要和数据分析打交道。当你在业务方面遭受到了瓶颈,这时候就需要用分析自己的产品的数据变化,因此toB产品经理该如何做好数据分析呢?

对于我来讲,我本身是学的软件工程,后来从事产品经理,作为toB端的产品经理,可能最爽的点在于设计软件的过程中,能把业务吃透,面对庞大的业务体系和复杂的逻辑,很难让自己在专业方面没有提升。
但是在经历面向的大多数是大客户和领导层面的人之后,难免会产生枯燥的感觉和到达瓶颈的挫败感,因为大多数情况下,toB产品不需要创新,不需要美感,更不需要突然爆发的灵感,需要的是对客户业务场景的深入调研和理解,强调的是客户的价值。
在toC端数据分析一片红海的情况下,toB在此领域倒是显得有些呆萌,说到底,toB的产品对于数据分析这项技能用的很少甚至不会用到。
但是,在经历了上述心路历程之后,也会有新的发现,那就是在toB端工作久了,越来越发现对于政策的把控和对于民生发展的趋势的把握显得十分重要,然而在公司的背景下,对于有些东西是现成的,直接拿来上手去做就可以,这就导致了对自身思维的禁锢。
但是哪怕假设假如以后会创业(每一个产品都有一颗创业的心),对于数据分析来讲也是写好计划书的一小部分不可忽视的技能,所以当toB遇到数据分析未尝不能擦出一些火花。
后续会更新更加详细的步骤包括用到的工具。
以下内容均来自一个初步认知数据分析的toB产品的总结:
数据分析大致可以分为以下几个步骤:
- 问题工程:得到什么结果
- 信源工程:数据从哪来
- 数据工程:也可以叫数据处理(为了格式一致就叫那个名字吧),目的是得到“好”数据
- 特征工程:从哪些维度入手
- 模型工程:标签应该怎么分析
- 展示工程:结果怎么呈现
最后,讲好一个故事,一个可以将上述步骤都包含进去的故事。
一、问题工程
问题工程简单来讲就是想要得到什么结果。什么样的曲调决定了歌词情感动向,如果在一开始就没有想清楚到底研究的是什么问题,或者没有一个明确地主旨的话,那么后面所做的东西都用不上(简称:垃圾)。所以第一步虽然是最简单的,却也是最重要的。
二、信源工程
1. 信源划分
可以将信源划分为信息发布者、行业类型、所属地域和网站类型这几个维度。
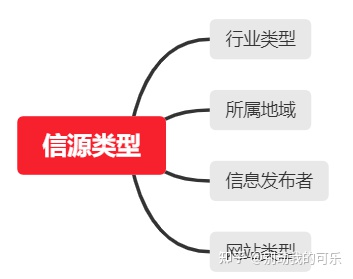 (1)信源类型
(1)信源类型
①信息发布者
可以分为UGC(个人)、PGC(专业生产内容)、OGC(职业生产内容)。

信息发布者类型:
行业类型:
- 保险业
- 能源
- 餐饮
- 电讯业
- 房地产
- 服务业
- 服装业
- 公益组织
- 广告业
- 航空航天
- 化学
- 健康
- 保健
- 建筑业
- 教育
- 培训
- 计算机
- 农业
- 旅游业
- 律师
- 体育运动
- 演艺
- 医疗服务
- 设计
- 金融
- 交通运输业
- 咨询等等行业
所属地域:
可以按省市划分,按国家划分等。
网站类型:
例如咨询、社交、百科、视频、百度经验、企业类。
再细化一点比如电商的分类:
- 综合类:淘宝、天猫、京东、苏宁
- 饮食类:美团、饿了么
- 锻炼类:keep、薄荷健康
- 旅游类:大众点评、携程、去哪儿
2. 数据类型的划分
还是举个例子,对于电商来讲,包括但不限于:产品名称、任务数据、动态数据(评论数、转发数)、转发数据、收藏量。
3. 定位有价值的信源基本步骤
第一步:读题,解析命题
第二步:拓开思路,列出信源可能的来源
第三步:按照第二步的列表去筛选需采集的信源和数据
第四步:在已采集的数据中再次精加工,得到有价值的基础数据
*商品类的分析一定会需要商品售卖的数据、商品的描述、商品的口碑、品牌的口碑等等,所以电商数据、评论数据、口碑数据、微博数据这些不可或缺。
*事件类的分析一定会有官媒数据、民众讨论的数据等等,所以,资讯数据、微博、贴吧、论坛这些数据不可或缺。
*行业类的分析一定会有行业专业网站、国家政策、行业论坛等等,所以,需要找的就是专业性论坛、专业网站、官方站点、可能还需要toB站点的相关数据。
4. 从信源得到数据
收集信源我一般会用火狐,因为会有好用的插件。 注:在用Python爬虫时可以根据可以根据网址的规律提取连接。

火狐的插件
信源可以根据列表页和正文页获取,信源的获取过程中有以下情形:
- 正常的信源页,我们从源码中就可以看到可以采集的正文页链接,非常好提取。
- 有嵌套的信源页,这种直接看源码是看不到正文页的,需要我们找到正确的列表页,比如下图的某政府网站,需要点开真正的列表。
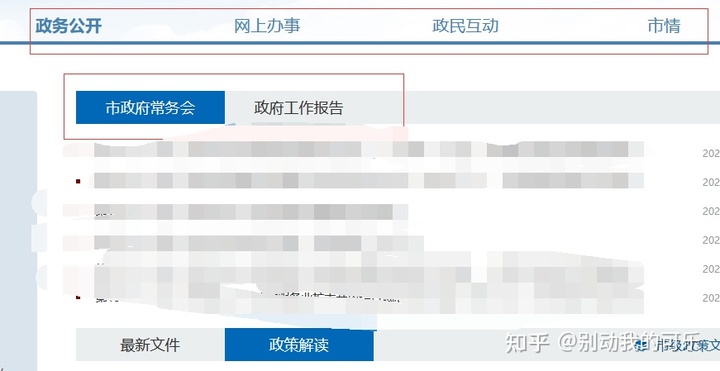
- 信源页中的正文页链接是需要拼接的
- 信源页中有多条信息,需要从中直接提取每条数据的字段的(例如:搜索引擎页面)
- 需要登录的
- 其他一些做特殊配置的
其实可以思考一下,按照网站类型可以将以下情景的信源划分为哪些维度,并给出合适的数据(网站)来源。
- 分析天津市针对人工智能专业博士的需求情况
- 分析互联网上针对综艺节目《乘风破浪的姐姐》节目评价及该节目的受众人群
以下只是简单提供一种思路:
第一个场景按照网站类型可以将信源划分为判决文书、电商类、资讯类、行政处罚、企业工商注册数据、百度经验、企业类、法院类、百科等这些维度。
第一个情景分析天津市针对人工智能专业博士的需求情况:
首先组合几个维度分析,所属地域限定在北京,行业类型限定为人工智能,信息发布者为PGC内容,网站类型为行业专业网站、国家政策和行业论坛,进一步定位有价值的信源,就要从专业性论坛、专业网站、官方站点、toB站点获取相关数据
第二个情景分析互联网上针对综艺节目《乘风破浪的姐姐》节目评价及该节目的受众人群:
首先组合几个维度分析,行业类型定位在娱乐和影视,信息发布者UGC和PGC都要分析,因为属于事件类的分析,主要分析节目评价及该节目的受众人群。
所以就要有官媒数据、民众讨论的数据、民众自身年龄的数据等,所以网站类型要从资讯和社交两个方面分析,例如从《乘风破浪的姐姐》官方微博、贴吧、论坛找出这些数据。
三、数据工程(数据处理)
1. 数据结构化
将数据整理成能看的结构:

数据结构化:
- 传播力分析:标题、出处、发布时间
- 人物画像:微博人物字段
- 消费者人物画像:评论字段
- 汽车指标:汽车网站字段
- 电商人物画像:消费习惯
2. 数据处理
其实上学的时候也学过很多数据处理的知识,有各种插值法,回归,聚类等方式处理数据,但凡有一点在脑子里,我也不至于重新学。不过基本的我还是印象深刻的:
(1)数据清洗
主要是删除原始数据集中的无关数据、重复数据,平滑噪声数据,处理缺失值、异常值等,让数据变得“干净”。
(2)缺失值处理
处理缺失值的方法可分为三类:删除记录、数据插补和不处理。其中常用的数据插补方法见下表:

其中,插值有两个比较重要的是拉格朗日插值和牛顿插值。
(3)异常值处理

(4)数据变换
主要是对数据进行规范化的操作,将数据转换成“适当的”格式,以适用于挖掘任务及算法的需要。会涉及到归一化处理、属性构造、小波变换等方式,从而达到数据使用的标准。
(5)数据规约
数据规约是将海量数据进行规约,规约之后的数据仍接近于保持原数据的完整性,但数据量小得多。通过数据规约,可以达到:
- 降低无效、错误数据对建模的影响,提高建模的准确性
- 少量且具代表性的数据将大幅缩减数据挖掘所需的时间
- 降低储存数据的成本
数据规约会对属性和数值两个方面进行(具体的我也忘得差不多了),但是讲真,简单的数据分析(给自己看的数据分析)不会进行到这一步的。
3. 数据建模
这块到后面会详细说一下,因为一旦展开就真的太多了。大概会有聚类、分类、关联、回归、时序模式、离群点检测等。
四、特征工程/数据分析
分析可以从以下几个方面入手:
- 关注点:分析用户使用情境中的核心诉求,用户在产品购买使用中最关注什么?影响用户选择的关键要素
- 用户场景:产品问题是在什么情况下发生的
- 产品抱怨:用户集中反馈的产品缺陷,用户对产品的主要抱怨是什么?
- 竞品分析:与竞品对比的主要差距,产品哪些地方不如竞品?
选择对用户体验和销售最有价值的产品改进方向,实现产品有效优化。
1. 关注点
聚焦资源,主动让顾客选择,不让顾客思考。
- 关注点提及分析
- 判断用户关注点(四象限图)
用户产品需求分析:分析用户对本品类产品使用的最主要功能性能要求。
用户购买因素分析:监测本品类产品用户认知度对比关系。

2. 用户抱怨
(1)类型
非投诉型抱怨:不会直接抱怨但是会向其他人传递不好
投诉型抱怨:产品的不好会直接反馈回来
(2)用户抱怨分析
- 用户对产品的主要抱怨是什么?
- 用户集中反馈的产品缺陷有哪些?
- 这些言论在哪些媒体出现?
①不同维度的PSR和NSR
- PSR=正面/(正+负)
- NSR=负面/(正+负)
②用户抱怨实时监测分析(四象限图)
3. 应用场景
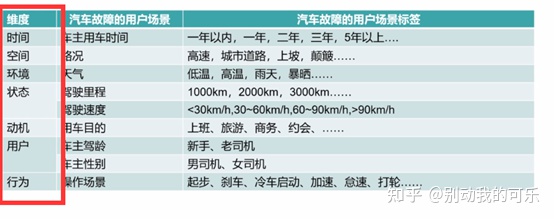
什么人在什么时间、地点,带着什么样的情绪、动机,通过什么行为来满足什么要求。
这里有四个因素:用户(用户所属的群体、所带有的角色标签)、需求(核心)、行为(用户采取什么行为满足需求)、情景。
要时刻思考应用的意义,其实慢慢的又回归到了产品经理的思路上来了,所以数据分析有时离不开产品思维,比如要思考:
- 谁是产品的目标用户?他们的核心需求是什么?
- 在特定场景下,是什么让他们决定使用或者放弃使用一款产品?
toB只在乎用着顺不顺手:

toC在乎多方面:

每个环节都要有场景:
用户场景梳理方法:

4. 竞品分析
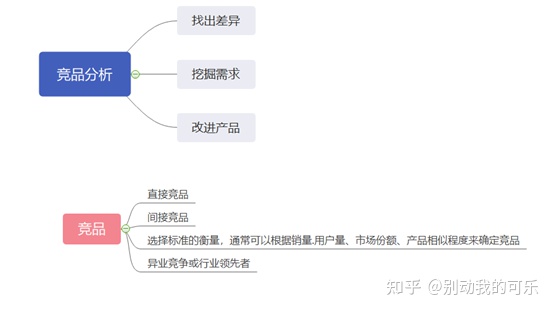
(1)找到竞品top3-5,核心1-2个

(2)排除非竞品:关联词相似度,话题讨论
(3)判断竞争强度 各维度提及次数
(4)案头研究:价格
(5)舆情指数分析:消费者情感偏好和讨论声量判断优劣势构建四象限图 横坐标讨论声量,纵坐标PSR,四个维度分别是基本产品、优势产品、小众产品、劣势产品。
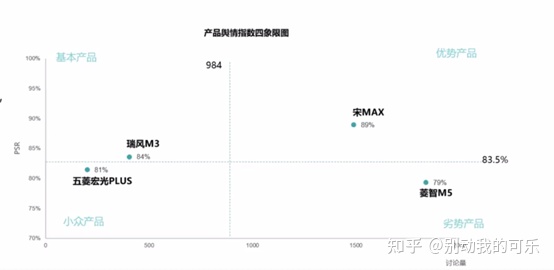
(6)各维度进行抱怨度NSR分析
五、模型工程
根据RFM模型和NSR、PSR模型进行分析,这一点我也会单独拎出来做出一个文章详细写一下。
六、展示工程/数据可视化
工具可以用PowerBI,也可以用Python,Python还是很万能的,而且python有很多现成的包,直接导入直接用,各种好看的分析图都有,我将单独写一章介绍python的可视化分析。
1. 数据标签可视化
2. 例子(PowerBI)
(1)进行数据的拆分(年月日、性别等等)
(2)数据分组
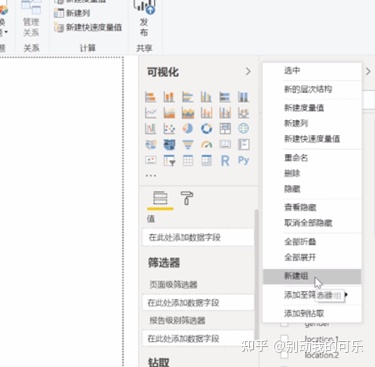
(3)数据的筛选
例如:性别统计。
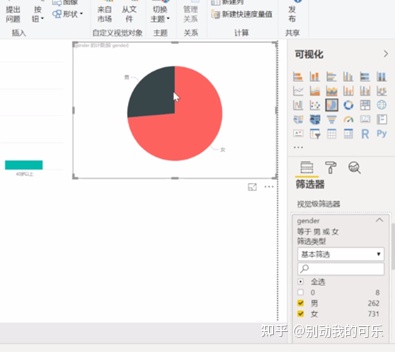
3. 地域统计、自我认知词云

4. 页面大小的调整

5. 标签数据的可视化
四级标签的可视化,设置二级标签的筛选器,词云图可以设置不显示某些词。
七、最重要的就是讲故事
具体怎么讲,我打算放在后面的文章去说明,因为这篇文章就是一个小概括而已,也是大概梳理了一下近期学习的思路。
作为toB端的产品经理有些人觉得着实是没必要研究这些,我一开始也是这样觉得,但是我越学习就会越发现数据分析的思路其实是离不开产品的思维,产品的思维也能从数据分析的思路中得到灵感加以开阔,因为我们的目标不是一直做产品经理,而是去到更大的平台更高的地方去看这个世界。
没有人一拿起来这件东西马上就能上手去做的,除非天赋异禀,但是大多数人都是在一步步泥泞中摸爬滚打过来的,我是想说,接受自己平凡,并不断向前,就已经赢过绝大多数的人了,因为总是会有人自命不凡。
本文由 @别动我的可乐 原创发布于人人都是产品经理,未经许可,禁止转载。
题图来自 Unsplash,基于CC0协议









写的很好!👏👏👏