
 起点课堂会员权益
起点课堂会员权益互联网法诉业务数据体系建立
编辑导语:在实际工作中,数据分析师会遇到多种类型的数据体系,而不单单是业务数据的监控体系。作者就其目前的部门体系的搭建,分享互联网法诉业务数据体系该如何建立,一起来看看吧。

今年从零开始参与了部门整体体系的搭建,一直忙到9月份才有喘息的机会,也想分享一下在业务数据体系搭建的经验。
之前看到的很多数据体系搭建的分享都是业务数据监控体系搭建,其实在部门实际操作中会涉及多类型的数据体系,而不仅仅是业务数据监控体系。以我们部门现在在做的逾期资产处置来看,很多数据的收集是线下数据汇总以及清洗,和能够通过线上的用户日志的数据收集清洗逻辑完全不同。
在通常的业务部门中,有大量的数据是在线下通过EXCEL报表的形式交互的,这种业务形式下整体数据的体系会因为人为、操作的因素导致体系相对不是那么清晰,加上大部分公司的模式都是业务追着数据跑,跑着跑着数据工作的压力就特别大,慢慢的数据组就全成了工具人了。
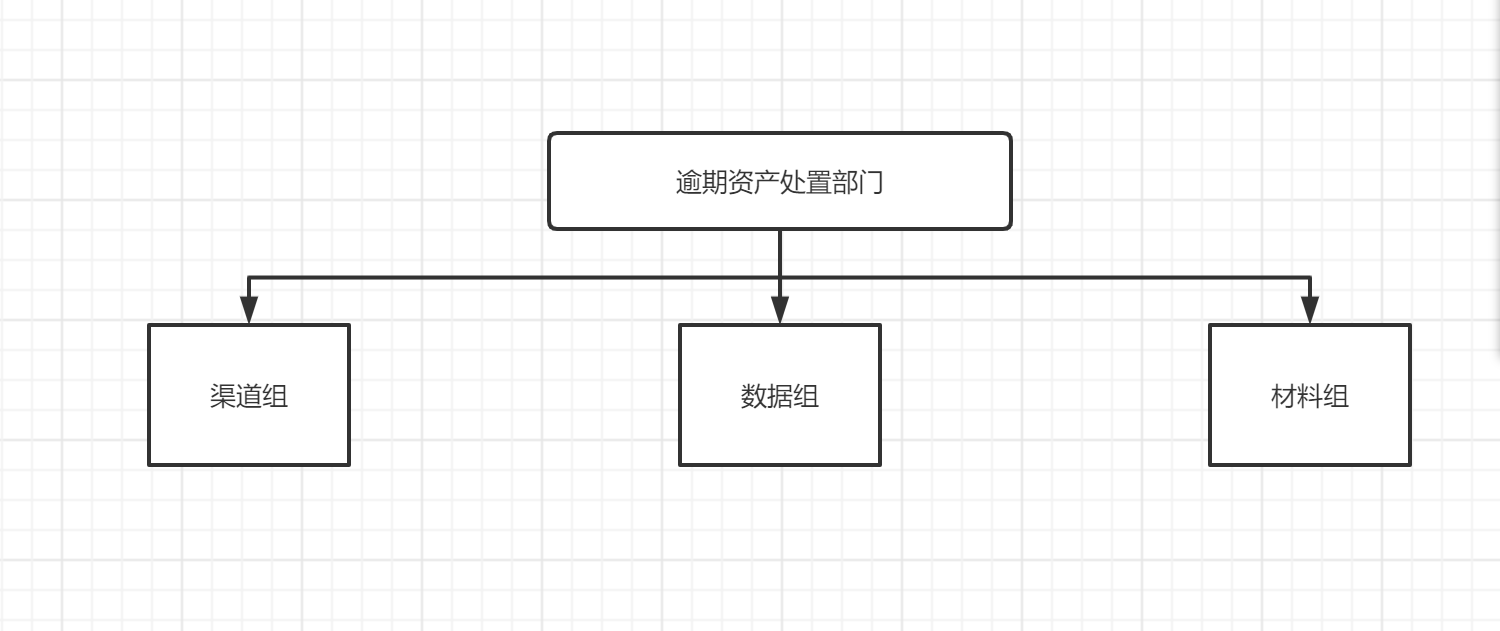
目前我们部门的架构简单分为三个组别,材料组是对目前现有的可诉讼证据材料进行甄别、组织全量诉讼材料,渠道组主要对接外部可委托在各地法院进行诉讼的渠道。
因为所有的数据都是在线下交互的,且完全没有系统支持,所有的数据逻辑只能靠人工在线下进行整理。
以实际业务及工作需求为核心拆分现有的数据需求:
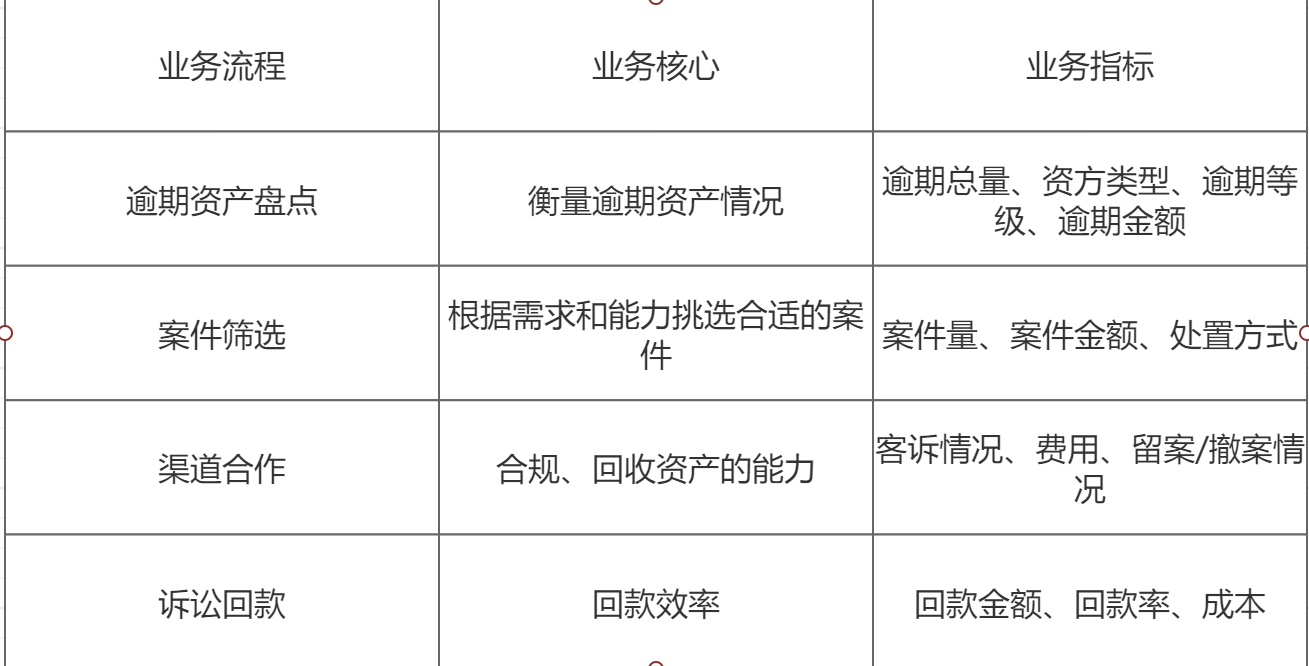
每一个工作业务步骤下都存在大量记录的数据,因此就需要内部将所有的数据体系按数据的统一维度进行计算,也需要确定每个工作节点的数据回传时间和数据回传质量以及数据检查项
根据业务的流程,可以大致推导数据的流转方向:
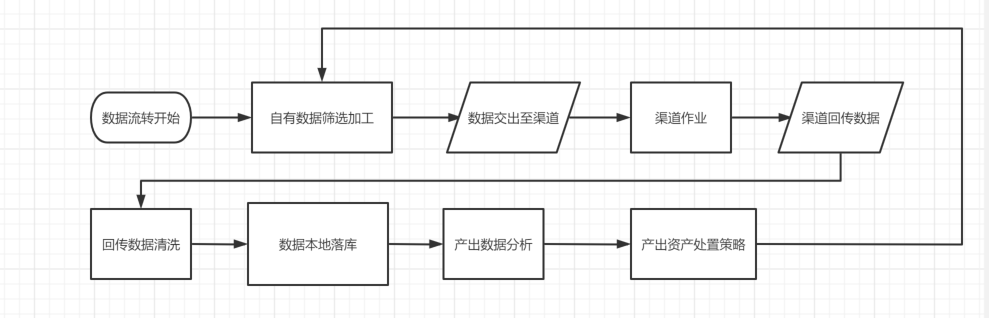
由于数据交互的节点下有多人、多渠道参与,不同的同事在数据传递和数据回收的处理方式不尽相同,就需要建立标准的数据较验处理规定和模板。
为了让每个数据环节的数据处理情况一致,确保实际操作的数据和分析的数据按统一的维度拆分,就需要从一个整体的角度出发去核准数据的处理标准和时间:
以分案为例,案件筛选目前有几个需要严格核准的标准,如用户有多笔欠款,则以合计欠款金额为实际欠款金额,该用户下的所有订单合并,以实际用户案件的维度去考虑诉讼范围。
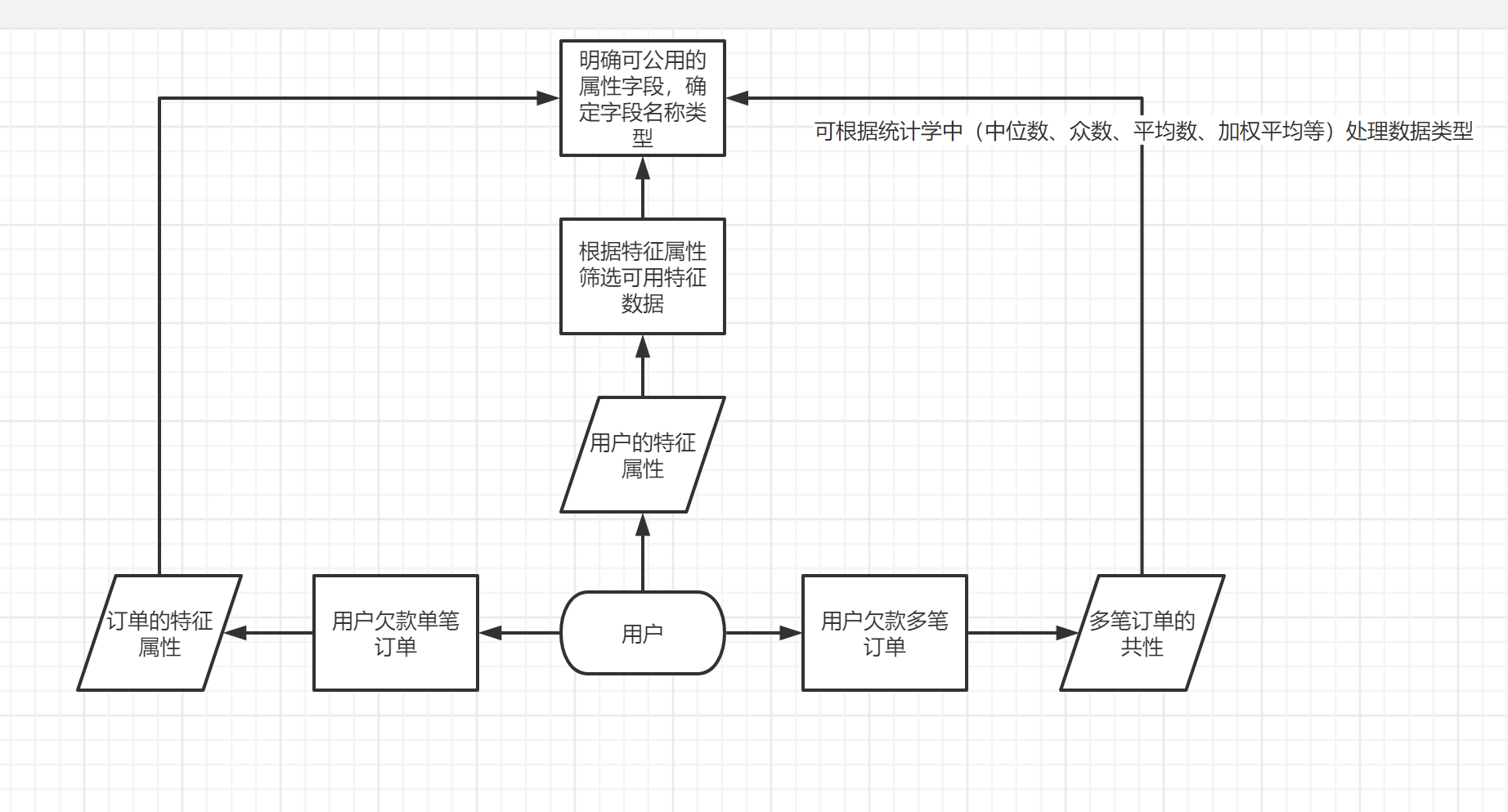
如上图所展示的,就算是同个用户在不同的订单下借款的金额、借款时间、借款用途与逾期天数等数据是不完全一致的,需要根据用户的不同订单下的订单特征归纳出完善且可用的用户特征。
但由于实际起诉后用户还款不一定能完成按照起诉的总额归还,由于公司数仓底层仍是按照订单作为主键的维度建库,部分归还的情况下会需要将用户的还款按不同的订单和不同的金额填充规则(具体根据借款合同约定。
例如按最早一期欠款的罚息、利息、本金的顺序进行冲账)因此会在推出案件的前期明确同个用户下多笔订单的主次关系。
此外,需要对所有后期需要分析的字段的当前状态进行留存,这就需要对系统内所有业务相关字段的含义和更新逻辑有所了解,数仓通常会保留订单的当前状态,举个例子,用户目前的逾期状态是全部逾期(即所有账期均未还满),当执行院强制执行后有部分还款,但不足以抵扣全部欠款,用户该笔订单的逾期状态会从全部逾期转变为部分逾期。
同样地,因为有部分还款,逾期等级会下跌,这就需要本地留存部分的静态数据,结合线上的动态数据去看,这就需要建立线下数据和线上数据的交互,将留存在线下的静态数据在每一段周期内需要按一定的逻辑更新到线上数据库内作为静态数据留存下来;
这时候就需要建立一定的数据交互逻辑,本地数据按什么模板上传,上传的时间点,上传的频次,什么时候能够在线上系统看到这部分静态数据,这部分逻辑就需要和管理数仓的同事们沟通明确;
在完成分案之后,会对整体业务的进展进行跟进,这部分一般就由渠道运营的同事去推动;因为各个渠道对待案件的模式可能不尽相同,数据的处理方式也更不一致,举个例子,有的渠道有自己的失联修复的手段,有的渠道通过线下送达律师函的方式,有的由于合作法院的模式不一样。
由于渠道特点和运营模式的特殊性,回传的数据同样具有特征性,这样的数据是较难按统一的维度清洗的,需要给渠道设定合理的字段转化代码。
以渠道统计的可联失联数据为例,有部分渠道的失联定义是联系方式能正常接通但无法联系到本人,还有一部分渠道将失联界定为用户的联系方式已经完全失效,所有的这些非统一性的字段都需要整理归纳为统一字段含义。
因为所有有人为参与的过程一定会出现部分数据转化存在问题的情况,最好能够通过固定的字典表去核准:
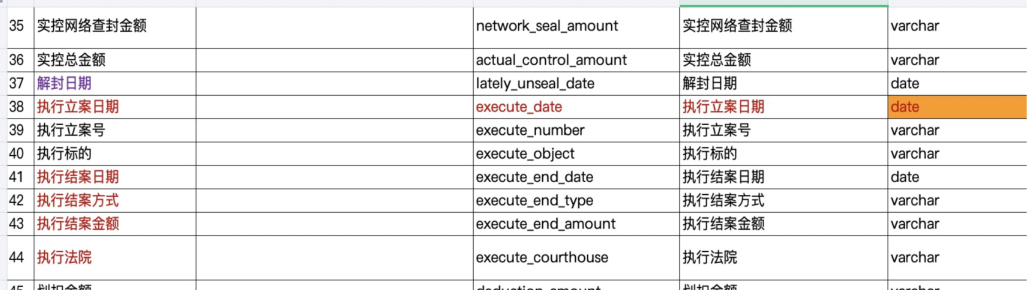
以上的字段类型为目前部门部分业务字段名称和类型展示,因为各类型字段需要渠道、业务方和数仓方面完全对齐字段含义,这样才能减少数据工作人员在数据清洗方面的重复劳动,尽量简化工作流程和数据清洗步骤;
当然,并不是所有的数据在收集的时刻就会完全与系统数据的类型和字段名称完全一致,或者编码形式完全统一(例如编码形式为GBK/UTF-8)这就需要进行一步转化,将收集的标准化字段利用字典表转化为系统/数据库可以读取的数据统一留存,如果在这个步骤下是用数据组自己操作的话人为错误是一定无法避免的,最好是通过自动化的工具去完成数据的转化。
可以通过Python利用pandas和EXCEL、CSV的包完成自动化的处理,之后导入本地数据库通过表连接查询用代码的形式替换业务数据,完成转化之后录入系统;
不过,也不是所有的业务数据都能通过自动化工具去清洗,还有大量的业务数据空值由于不能简单的根据特征数据填充,只能寻找历史的情况去尝试补充,这个情况是无法避免的;
数据清洗之后就可以慢慢增添分析的需求,分析指标建设这个已经有太多大佬分享过见解,我就不多说了。
在分析盘点体系的建设过程中一定会出现分析体系开始落后于业务进展的情况(尤其是从0-1的业务部门,业务的进展速度一定是超出实际工作流程建立速度的)。
这种情况下需要留出一定时间去梳理数据在业务流动过程,至于实际策略的产出,仍需要依托分析结果进行深入挖掘,这个以后找时间再分享吧~
作者:Logan_RRRC;公众号: Logan的运营学习日记
本文由 @Logan_RRRC 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于 CC0 协议






- 目前还没评论,等你发挥!


