
 起点课堂会员权益
起点课堂会员权益清晰易懂!用5W2H方法进行维度建模,一篇搞定!
编辑导语:数据模型是数据组织和存储的方法,模型的好坏,决定了数仓能支撑企业业务多久。而维度建模是数据仓库建设中的一种数据建模方法。这篇文章详细地为大家讲解数仓界的泰斗Kimball的维度建模,这种建模方式被广泛应用在阿里滴滴等公司。感兴趣的朋友一起来看看吧。

一、维度模型介绍
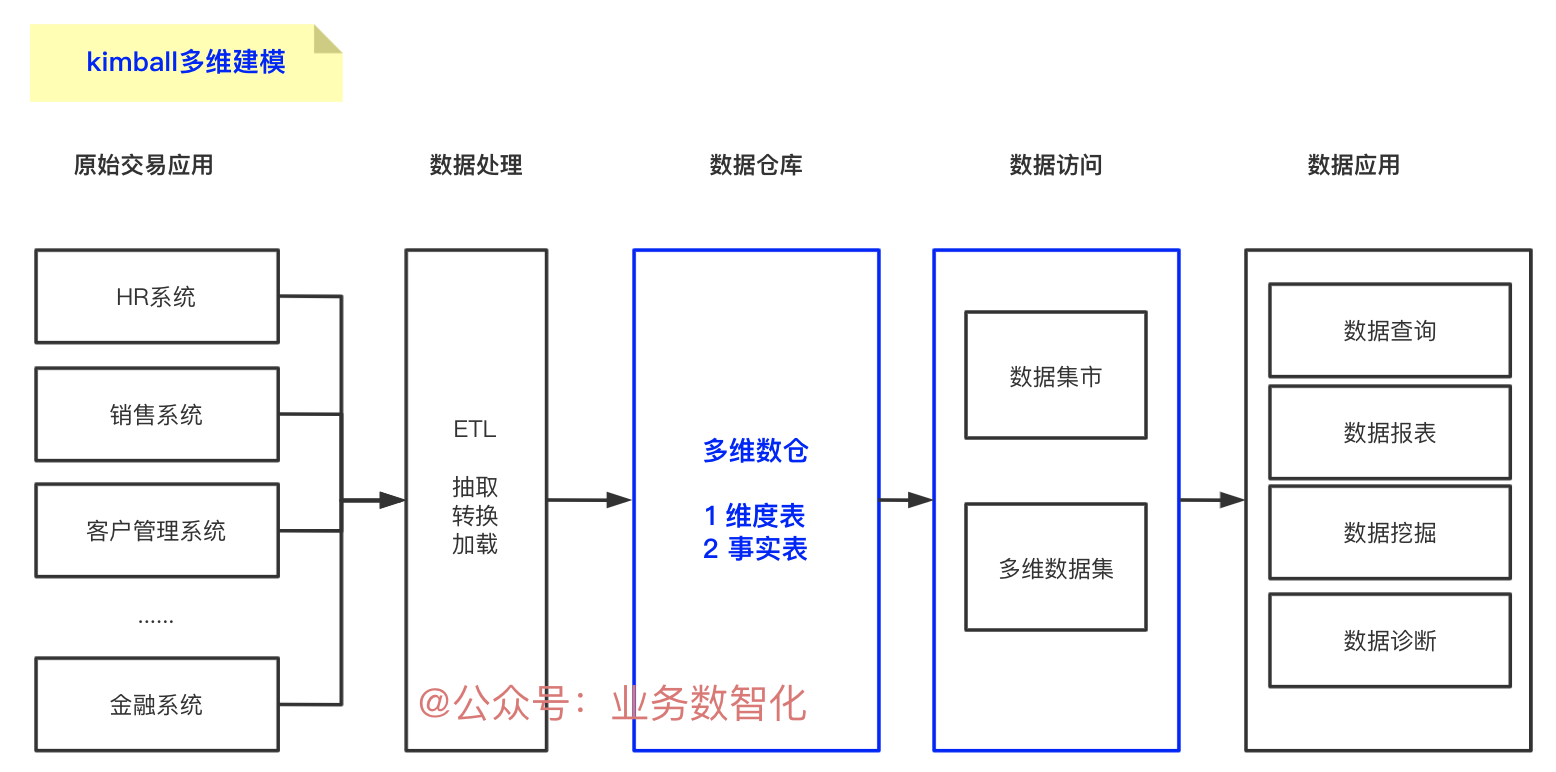
Kimball大师的模型流程是:从需求→模型→数据,且整个流程是自下而上的。
这种结构也被成为数据集市总线架构( Data Mart Bus Architecture )或者数据仓库总线架构 (DataWarehouse Bus Architecture)。
Kimball模型最核心的部分在于维度建模,理解好这部分,对Kimball模型的理解基本上可以事半功倍。本文重点来介绍下维度建模。
二、应用环境
1. 定义
维度建模是一种数据结构技术,主要目的为了帮助用户进行大规模且高效的数据查询。
2. 适用
上边的定义说明了维度建模的目的是优化数据库以更快地查询数据。
维度模型旨在读取、汇总、分析数据仓库中的数值信息,例如:想看汇总值、分位值等等,这种特性更加适合数仓环境。而事务数据库(OLTP)中,不适合这种设计方式,因为事务数据库有如下特点:
- 适合快速更新和插入数据
- 锁定一定需要被最小化
- 只适合一小部分数据查询
- 需要被标准化
我们再来看下数仓环境的特点:
- 适合更加快速的查询数据
- 锁定操作是非必须的
- 适合大量数据的查询
- 插入和更新是非必要的
所以维度建模需要在数仓环境中被应用。
三、名词解释
在介绍整体建模流程之前,有些名词需要给大家详细介绍下,这样下面的内容阅读起来会更加通畅一点:
1. 关于事实
经常也被成为度量,事实是可以体现业务流程中真实表现的数据。
例如:对于销售业务流程,最核心的体现是季度销售金额;对于招聘流程,最核心的体现是招聘人数;对于技术团队,最核心的体现是开发了多少功能。
特性:不同的事实反映出不同的业务性质;事实之间相互独立;事实是业务量化的表示。通常情况下维度要比事实更多。
2. 关于维度
维度是经常被大家说道的一个词,其实维度更多的是一个视角,是从不同的角度去观察和分析事实的一个方法。谁在那干啥?
例如:以销售流程为例,需要分析的维度有:
- 谁买了商品——客户名称
- 在哪买了商品——售卖地点
- 买了啥商品——商品名称
3. 关于属性
属性就是维度建模中维度的特征,我们以地理位置维度为例,他的属性就是:省份、城市、区域等等。
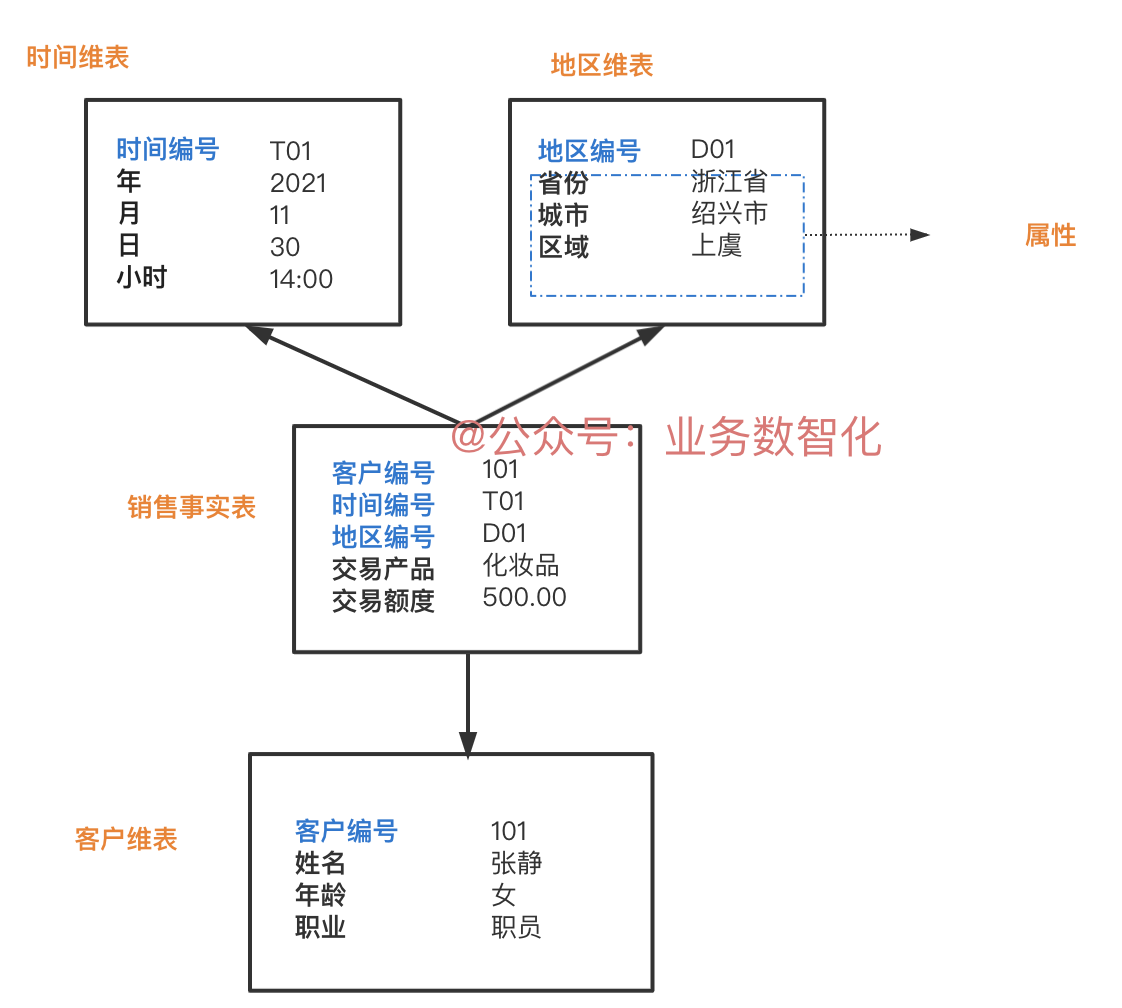
4. 关于事实表
维度建模中的核心表,星型结构中的中心位置表,该表包含了以下因素:
- 事实表
- 维度表的主键(事实表的外键)
5. 关于维度表
包含事实的维度,通过外键和事实表进行关联。
特点:维度表可以为事实表进行特征描述,维度表可以包含一个或多个层次关系。
 四、建模流程
四、建模流程

 1. 描述业务过程(为啥做Why)
1. 描述业务过程(为啥做Why)
从实际的业务过程中提取分析维度,并且把业务过程转化为事实。
确定所需覆盖的实际业务流程。
根据组织的数据分析需求,可能是营销、销售、人力资源等组织的诉求。
业务流程的选择还取决于该流程可被应用的质量尚可的数据。这是数据建模过程中最重要的一步,如果在这一步出错,整个维度建模必将以失败告终,所以第一步一定要谨慎且细致的对业务进行描绘。
要描述业务流程,可以通过语言进行描述,也可以使用基本的业务流程建模符号 (BPMN) 或统一建模语言 (UML)进行业务描述。
比如商城业务,整个商城流程分为商家端,用户端,平台端,运营需求是总订单量,订单人数,及用户的购买情况等。
2. 声明粒度(做到啥程度How much)
粒度可以用来确定事实表中行表示什么。
例如:一个用户有一个身份证、一个籍贯、多个手机号、多个银行卡,此时与用户粒度相同的粒度属性为身份证粒度、籍贯粒度,因为用户和身份证、籍贯都是一一对应的。而对于手机粒度、银行卡粒度是比用户更加细致的粒度,因为存在一对多的关系。
同一事实表中,必须有相同的粒度。原子粒度是最低级别的数据粒度,原子粒度能够承受无法预期的用户查询。通过原子粒度进行上卷,可以满足各类需求。
在此阶段设计之前,你需要思考下几个问题:
- 是按月、每周、每天还是每小时存储产品销售信息?这个问题取决于高管要求的报告的性质。
- 上个问题中的选择将对数据库大小有什么影响?
3. 标识维度(是啥在哪何时What Where When)
维度是事实表的基础,维度是通过不同的视角去看数据,把一堆数据进行分类,从而进行细分对比。例如:时间维度中可分天、周、月、年这样的维度。用户也可以分新生期、成熟期、衰退期、流失期各个生命周期这样的维度。
细化一下这个例子: 管理者希望每天了解不同地点各类产品的销售额,此时维度、属性、层次结构可以进行如下分解:
- 维度:产品、地点和时间
- 属性:(以产品为例)产品编号(外键)、名称、类型、规格
- 层次:(以位置为例)区域、省份、城市、区县、街道
4. 标识事实(解释是啥What)
事实表示用来度量的,基本上都以数值来表示,这一步骤是用来标识事实表中的每一行。此步骤与系统的业务用户相关联,因为这是他们访问存储在数据仓库中,大多数事实表行都是数值,如价格等等等。
举个例子:管理者希望每天了解不同地点特定产品的销售额。
这里的事实表示通过产品分类、销售时间、销售位置等得到的销售额总和。
一般的维度模型讲解在这里会划上尾声,但其实维度建模还隐藏了第五步:
5. 构建架构
在此步骤中,只有这一步完成其实才真正的实现了维度建模。模式只不过是数据库结构(表的排列)。有两种流较为通用的架构:
(1)星型架构
星型架构很容易设计。称为星型模式是因为构建的形状图类似于星形,点从中心向外辐射。星的中心是事实表,星的点是维度表(样图可见本文第3部分)。
这里要特别说明以下星型模式中的事实表是第三范式,而维度表是非规范化的。
(2)雪花架构
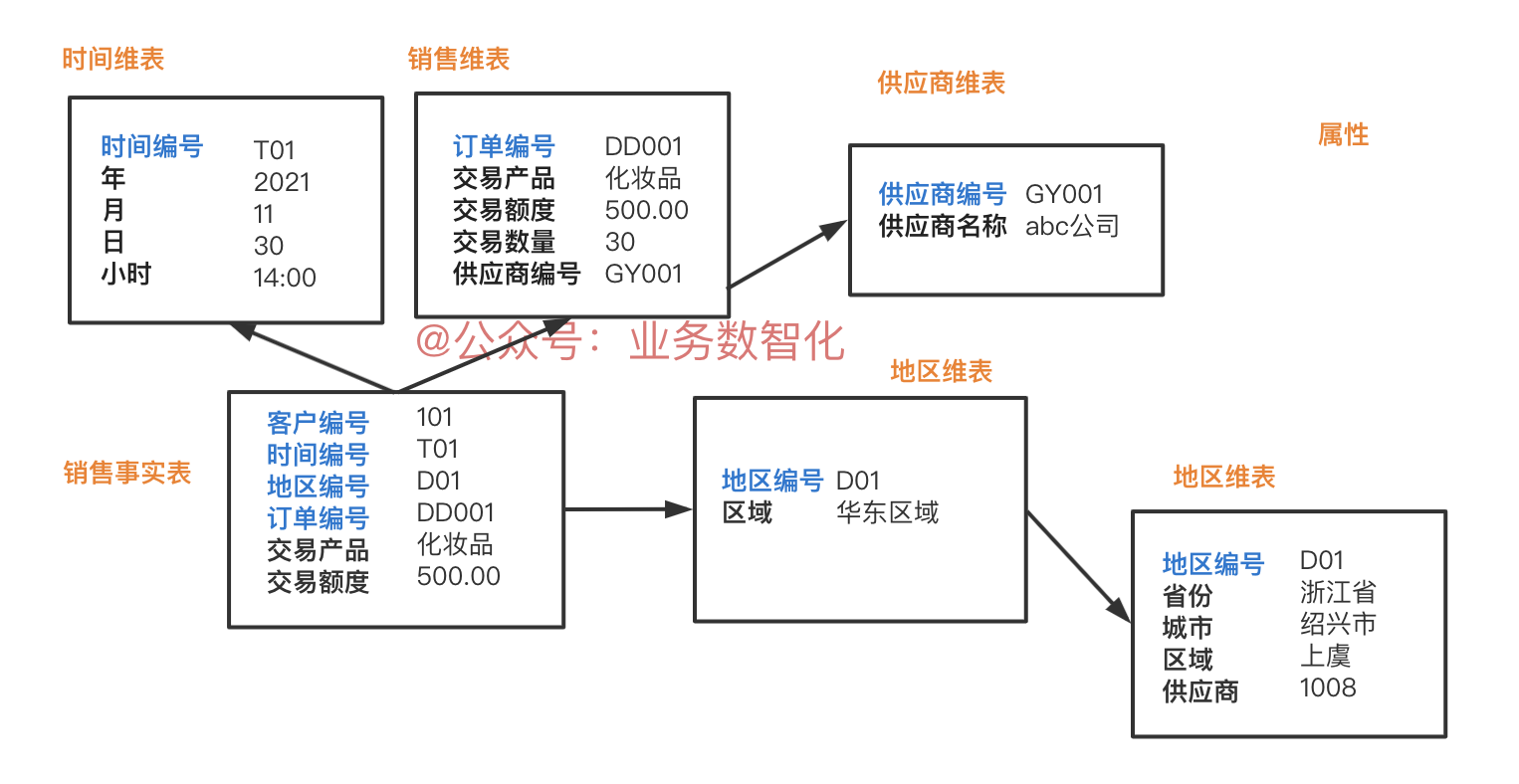
雪花模式是星型模式的扩展。在雪花模式中,每个维度都被规范化并连接到更多维度表。所以从结构上来看,花花模式更为复杂一点。
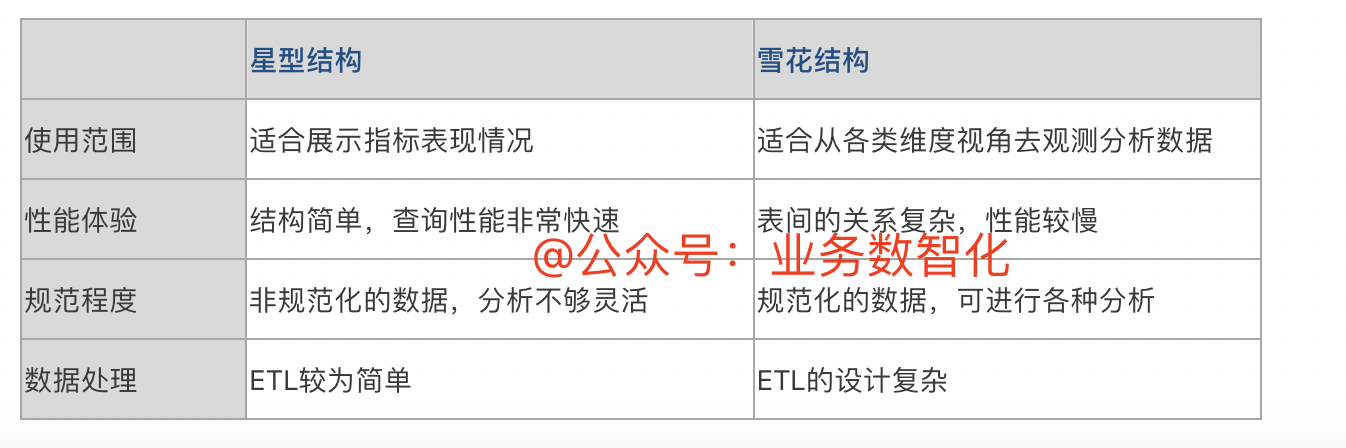
小结:星型表和雪花表的对比
五、建模实例
场景:小明在2021.11.11 晚上12点买了3件棉服。他用支付宝的方式进行支付,并且在2021.11.13收到了书。
拆解:由于最近天冷了(为啥Why),小明(谁 Who)2021.11.11 晚上12点(何时 When)花费3千(多少How much)在淘宝(在哪Where)买了3件棉服(啥 What)。他用支付宝(如何 How)的方式进行支付,并且在2021.11.13收到了书。
1. 描述业务过程(为啥做Why)
由于天冷,需要保暖。
2. 声明粒度(做到啥程度How much)
花费3k买。
3. 标识维度(是啥在哪何时What Where When)
在淘宝上于2021.11.11 晚上12点买了3件棉服。
4. 标识事实(解释是啥how)
用支付宝进行购买。
六、维度改变
当维度改变时,将会发生啥?
举个场景来说,上海的ABC商店将会从华东区域划分为华南区域,如果管理者想看划分前后的对比情况应该如何看呢?
1. 改变维度的方式一
- 用新的信息去重写已知维度;
- 优点:方便实施;
- 缺点:无法去看之前的表现;
- 实施之后,所有历史的数据信息将看不到。
2. 改变维度的方式二
- 保留所有历史的维度信息;
- 有点:更加方便的看出历史的情况;
- 缺点:实施起来复杂性较高;
- 实施之后,更容易看到在华东区域的历史数据。
3. 改变维度的方式三
- 保留所有历史的信息,并且新增一个值;
- 有点:同时提供历史数据和新的数据情况;
- 缺点:历史数据表现将会受限制;
- 实施之后,变化前后的数据都将可以看到,但是查看历史数据的情况将会受限制。
本文由 @业务数智化 原创发布于人人都是产品经理,未经许可,禁止转载
题图来自 pexels,基于CC0协议






- 目前还没评论,等你发挥!


